Informed Asymmetric Dirichlet Priors for Multivariate Bernoulli Mixture Models
Pith reviewed 2026-05-09 21:50 UTC · model grok-4.3
The pith
An asymmetric Dirichlet prior on mixture weights, with hyperparameters from the Penalized Complexity framework, lets users specify an intuitive prior on the number of clusters while supporting efficient MCMC for multivariate binary data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fixing the total number of components to a large value and employing an asymmetric Dirichlet prior on the mixture weights, with hyperparameters elicited using the Penalized Complexity prior framework, induces a user-controllable distribution over the number of occupied clusters; the accompanying MCMC algorithm then produces full posterior inference on cluster membership and on the Bernoulli parameters within each cluster.
What carries the argument
The asymmetric Dirichlet prior on the mixture weights (a Dirichlet distribution whose concentration parameters differ across components), whose hyperparameters are set through the Penalized Complexity framework to shape the induced distribution on the effective number of clusters.
If this is right
- Cluster assignments and component-specific Bernoulli parameters are obtained jointly with full posterior uncertainty rather than point estimates.
- The same prior construction can be used when cluster probabilities are allowed to depend on site-level covariates, as demonstrated on the species presence-absence example.
- Performance remains competitive with existing Bayesian and heuristic methods across a range of simulation settings and can be superior when the true number of clusters is moderate.
- The computational cost scales with the fixed (large) number of components yet avoids the need to run separate models for each possible cluster count.
Where Pith is reading between the lines
- The same prior-elicitation strategy could be transferred to other mixture families, such as multinomial or Poisson mixtures, to give users direct control over effective cluster count.
- Because the model returns a full posterior over partitions, it can be embedded in larger hierarchical models that propagate cluster uncertainty into downstream scientific predictions.
- In domains with streaming binary observations the fixed-component construction may allow incremental updates without repeated model selection.
Load-bearing premise
That hyperparameters chosen via the Penalized Complexity framework produce a prior on the number of clusters that remains both intuitive to users and compatible with reliable MCMC mixing.
What would settle it
Generate replicated datasets with a known small number of clusters, fit the model, and verify whether the posterior mass on the number of occupied components concentrates near the truth while effective sample sizes for the weight parameters stay high; systematic failure on either count would falsify the claim.
Figures










read the original abstract
Clustering multivariate binary data is of interest in many scientific fields, including ecology, biomedicine, and social policy. Beyond heuristic clustering algorithms, such data can be modelled using multivariate Bernoulli mixture models. Many Bayesian implementations of these models involve a trade-off between computational efficiency and full posterior inference. We propose instead a Bayesian approach able to provide both aspects. The method fixes the total number of components to a large value and employs an asymmetric Dirichlet prior on the mixture weights. The asymmetric Dirichlet hyperparameters are elicited using the popular Penalized Complexity prior framework, which provides an intuitive way for users to inform the induced distribution of the number of clusters. An efficient MCMC algorithm is then developed to fit the model. Simulations and real-world applications demonstrate that the method is competitive with existing alternatives and can outperform them in certain settings. The proposal is illustrated using an ecological dataset about presence-absence of species across multiple sites, where cluster-specific parameters are modelled on the basis of environmental conditions. Overall, the proposed method provides a computationally efficient, fully Bayesian, and interpretable framework for clustering multivariate binary data, with potential applications across diverse scientific domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a fully Bayesian approach to clustering multivariate binary data via overfitted multivariate Bernoulli mixture models. The total number of components K is fixed at a large value, and an asymmetric Dirichlet prior is placed on the mixture weights whose hyperparameters are elicited using the Penalized Complexity (PC) prior framework to induce an intuitive distribution over the effective number of clusters. A standard Gibbs sampler is derived for posterior inference, and the method is evaluated on simulated data and an ecological presence-absence dataset in which cluster-specific parameters are further regressed on environmental covariates. The central claim is that the resulting procedure is computationally efficient, interpretable, and competitive with or superior to existing alternatives.
Significance. If the performance claims hold, the work supplies a practical, fully Bayesian alternative to heuristic or variational methods for binary-data clustering that retains full posterior uncertainty while offering an explicit, user-controllable prior on the number of clusters. The explicit derivation of the PC-prior hyperparameters for the asymmetric Dirichlet, the reproducible Gibbs sampler, and the real-data illustration with covariate-linked cluster parameters are concrete strengths that could be adopted in ecology, biomedicine, and social-science applications.
major comments (1)
- §4 (Simulation study): the reported superiority in certain settings is based on point estimates of clustering metrics without accompanying variability measures or formal statistical comparisons across the 50 replications; this weakens the claim that the method 'can outperform' existing alternatives.
minor comments (3)
- §3.2: the mapping from the PC-prior scale parameter to the asymmetric Dirichlet hyperparameters is clearly derived, but a short numerical table illustrating the induced prior on the number of clusters for the chosen scale values would improve usability.
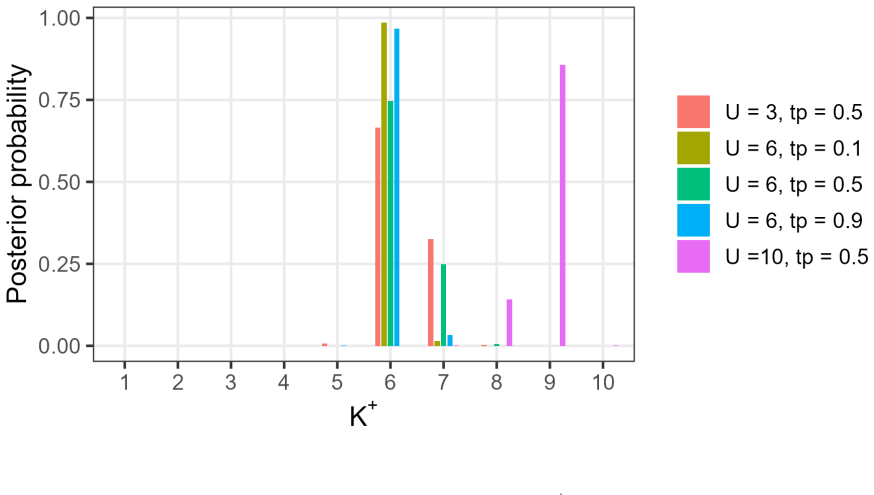
- Figure 2: axis labels and legend entries are too small for readability; increasing font size and adding a brief caption explaining the color coding would aid interpretation.
- References: several standard works on overfitted mixtures (e.g., Rousseau & Mengersen 2011) and PC priors are cited, but the manuscript would benefit from an explicit statement of how the present construction differs from the symmetric-Dirichlet case in the literature.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our manuscript and for the constructive comment on the simulation study. We address the major comment below.
read point-by-point responses
-
Referee: §4 (Simulation study): the reported superiority in certain settings is based on point estimates of clustering metrics without accompanying variability measures or formal statistical comparisons across the 50 replications; this weakens the claim that the method 'can outperform' existing alternatives.
Authors: We agree that reporting only average performance metrics across the 50 replications, without measures of variability or formal statistical tests, limits the strength of the outperformance claims. In the revised manuscript we will augment the tables and figures in Section 4 with standard deviations (or interquartile ranges) for each clustering metric and will add paired statistical comparisons (Wilcoxon signed-rank tests) between our method and the competing approaches. The text will be updated to qualify the performance statements accordingly, e.g., noting where differences reach statistical significance. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper fixes K large and applies an asymmetric Dirichlet prior whose hyperparameters are elicited via the external Penalized Complexity framework (a cited standard method, not derived from the model's own fitted values or predictions). The MCMC is described as a standard Gibbs sampler whose efficiency is demonstrated rather than assumed by construction. Simulations and the ecological application provide independent validation of performance without any step reducing a claimed prediction or uniqueness result to a self-defined input, fitted parameter, or self-citation chain. No load-bearing ansatz, renaming, or self-definitional loop appears in the central construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- PC-prior scale parameter
Reference graph
Works this paper leans on
-
[1]
Journal of Statistical Software , volume=
FlexMix: A general framework for finite mixture models and latent class regression in R , author=. Journal of Statistical Software , volume=
-
[2]
The Annals of Applied Statistics , volume=
Informed Bayesian finite mixture models via asymmetric Dirichlet priors , author=. The Annals of Applied Statistics , volume=. 2025 , publisher=
work page 2025
-
[3]
Economics & Sociology , volume=
Welfare regimes of European countries and their development in the context of membership in the European Union , author=. Economics & Sociology , volume=. 2024 , publisher=
work page 2024
-
[4]
Journal of the American Geriatrics Society , volume=
Identifying patterns of multimorbidity in older Americans: application of latent class analysis , author=. Journal of the American Geriatrics Society , volume=. 2016 , publisher=
work page 2016
-
[5]
A general model for clustering binary data , author=. Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining , pages=
-
[6]
Statistics and computing , volume=
Model-based clustering based on sparse finite Gaussian mixtures , author=. Statistics and computing , volume=. 2016 , publisher=
work page 2016
-
[7]
Prior knowledge elicitation: The past, present, and future , author=. Bayesian Analysis , volume=. 2024 , publisher=
work page 2024
-
[8]
Biodiversity and Conservation , volume=
The maintenance of extensively exploited pastures within the Alpine mountain belt: implications for dung beetle conservation (Coleoptera: Scarabaeoidea) , author=. Biodiversity and Conservation , volume=. 2009 , publisher=
work page 2009
-
[9]
Laini, Alex and Roggero, Angela and Carlin, Mario and Palestrini, Claudia and Rolando, Antonio , TITLE =. Environments , VOLUME =. 2024 , NUMBER =
work page 2024
-
[10]
Methods in ecology and evolution , volume=
Joint species distribution modelling with the R-package Hmsc , author=. Methods in ecology and evolution , volume=. 2020 , publisher=
work page 2020
-
[11]
Statistics and Computing , volume=
Markov chain Monte Carlo with the integrated nested Laplace approximation , author=. Statistics and Computing , volume=. 2018 , publisher=
work page 2018
-
[12]
Uncertainty Quantification in Bayesian Clustering , author=. 2025 , eprint=
work page 2025
-
[13]
Negro, Matteo and Claudia, Palestrini and Giraudo, Maria and Rolando, Antonio , year =. The effect of local environmental heterogeneity on species diversity of alpine dung beetles (Coleoptera: Scarabaeidae) , volume =. European Journal of Entomology , doi =
-
[14]
Journal of Computational and Graphical Statistics , volume=
Search algorithms and loss functions for Bayesian clustering , author=. Journal of Computational and Graphical Statistics , volume=. 2022 , publisher=
work page 2022
-
[15]
Conference on Uncertainty in Artificial Intelligence , pages=
Flexible prior elicitation via the prior predictive distribution , author=. Conference on Uncertainty in Artificial Intelligence , pages=. 2020 , organization=
work page 2020
-
[16]
Geir-Arne Fuglstad and Ingeborg Gullikstad Hem and Alexander Knight and H. Bayesian Analysis , number =. 2020 , doi =
work page 2020
-
[17]
Journal of multivariate analysis , volume=
Comparing clusterings—an information based distance , author=. Journal of multivariate analysis , volume=. 2007 , publisher=
work page 2007
-
[18]
Mathematics of operations research , volume=
Cooling schedules for optimal annealing , author=. Mathematics of operations research , volume=. 1988 , publisher=
work page 1988
-
[19]
Journal of the American Statistical Association , volume=
Mixture models with a prior on the number of components , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
work page 2018
-
[20]
Multivariate Bernoulli mixture models with application to postmortem tissue studies in schizophrenia , author=. Biometrics , volume=. 2007 , publisher=
work page 2007
-
[21]
American journal of human genetics , volume=
An autologistic model for the genetic analysis of familial binary data , author=. American journal of human genetics , volume=
-
[22]
Unsupervised Learning of Categorical Data With Competing Models , year=
Ilin, Roman , journal=. Unsupervised Learning of Categorical Data With Competing Models , year=
-
[23]
On the use of Bernoulli mixture models for text classification , author=. Pattern Recognition , volume=. 2002 , publisher=
work page 2002
-
[24]
Practical identifiability of finite mixtures of multivariate Bernoulli distributions , author=. Neural Computation , volume=. 2000 , publisher=
work page 2000
- [25]
- [26]
-
[27]
Environmental DNA: For biodiversity research and monitoring , author=. 2018 , publisher=
work page 2018
-
[28]
Bioinformatics Advances , volume=
VICatMix: variational Bayesian clustering and variable selection for discrete biomedical data , author=. Bioinformatics Advances , volume=. 2025 , publisher=
work page 2025
-
[29]
Daniel Simpson and H. Penalising Model Component Complexity: A Principled, Practical Approach to Constructing Priors , volume =. Statistical Science , number =
-
[30]
BayesBinMix: an R package for model based clustering of multivariate binary data , author=. The R Journal , year=
- [31]
-
[32]
Kullback, S. and Leibler, R. A. , title =. The Annals of Mathematical Statistics , year = 1951, volume=
work page 1951
-
[33]
Generalized Mixtures of Finite Mixtures and Telescoping Sampling , author=. Bayesian Analysis , year=
-
[34]
Sylvia Fr\". From Here to Infinity: Sparse Finite Versus Dirichlet Process Mixtures in Model-Based Clustering , journal=. 2019 , pages=
work page 2019
-
[35]
Australian & New Zealand Journal of Statistics , volume=
Spying on the Prior of the Number of Data Clusters and the Partition Distribution in Bayesian cluster Analysis , author=. Australian & New Zealand Journal of Statistics , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.