Nonparametric Estimation of Isotropic Covariance Function
Pith reviewed 2026-05-08 10:59 UTC · model grok-4.3
The pith
A sequence of Bernstein polynomials approximates arbitrary isotropic covariance functions valid in infinite-dimensional space, supporting consistent nonparametric estimation via sieve maximum likelihood.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A nonparametric model is constructed using a sequence of Bernstein polynomials to approximate any isotropic covariance function that is valid in R^∞. Approximation properties are established in the L∞ and L2 norms. A sieve maximum likelihood estimator is developed for the unknown function, and its consistency is proved under an increasing-domain asymptotic regime. The method is shown numerically to reduce bias from model misspecification relative to parametric models and to achieve smaller expected L∞ and L2 norms than existing nonparametric estimators.
What carries the argument
A sequence of Bernstein polynomials that approximates the covariance function while maintaining positive definiteness in infinite dimensions, paired with a sieve maximum likelihood estimator.
If this is right
- The estimator remains consistent when the observation region expands with the number of samples.
- It can be applied directly to real spatial datasets such as precipitation measurements.
- Bias from assuming an incorrect parametric form is reduced compared with standard parametric covariance models.
- Expected L∞ and L2 approximation errors are lower than those obtained from other nonparametric covariance estimators.
Where Pith is reading between the lines
- The approach could improve spatial prediction accuracy in environmental applications by avoiding errors from choosing the wrong parametric family.
- Extensions might allow estimation of non-isotropic or non-stationary covariance structures using similar polynomial sieves.
- In high-dimensional settings the method offers a way to let the data determine the decay rate of dependence without fixing a parametric form in advance.
Load-bearing premise
The unknown covariance function must be continuous, isotropic, and positive definite in every finite dimension, and the data must be collected under an increasing-domain regime in which the spatial region expands with sample size.
What would settle it
The central claim would be falsified if the sieve maximum likelihood estimator fails to converge in probability to the true covariance as the domain expands, or if repeated simulations show no consistent reduction in expected L∞ and L2 errors relative to parametric or competing nonparametric methods.
Figures






read the original abstract
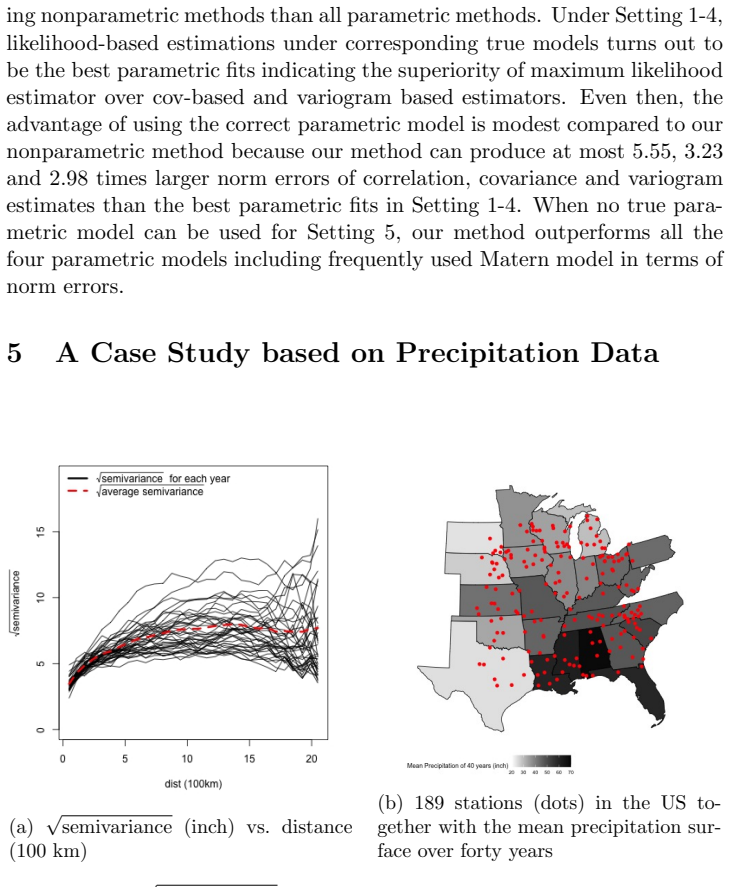
A nonparametric model using a sequence of Bernstein polynomials is constructed to approximate arbitrary isotropic covariance functions valid in $\mathbb{R}^\infty$ and related approximation properties are investigated using the popular $L_{\infty}$ norm and $L_2$ norms. A computationally efficient sieve maximum likelihood (sML) estimation is then developed to nonparametrically estimate the unknown isotropic covaraince function valid in $\mathbb{R}^\infty$. Consistency of the proposed sieve ML estimator is established under increasing domain regime. The proposed methodology is compared numerically with couple of existing nonparametric as well as with commonly used parametric methods. Numerical results based on simulated data show that our approach outperforms the parametric methods in reducing bias due to model misspecification and also the nonparametric methods in terms of having significantly lower values of expected $L_{\infty}$ and $L_2$ norms. Application to precipitation data is illustrated to showcase a real case study. Additional technical details and numerical illustrations are also made available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a sieve of Bernstein polynomials to nonparametrically approximate isotropic covariance functions that are valid in R^∞, studies the resulting L∞ and L2 approximation properties, develops a computationally efficient sieve maximum likelihood estimator, establishes its consistency under increasing-domain asymptotics, and reports numerical superiority over parametric and existing nonparametric methods in bias and expected error norms, with an application to precipitation data.
Significance. If the central claims hold, the work supplies a flexible nonparametric tool for covariance estimation that avoids parametric misspecification while targeting the strong validity condition required for infinite-dimensional isotropy. The reported numerical gains in L∞/L2 error and the consistency result under increasing domains would be useful additions to the spatial statistics literature, particularly for applications where dimension-independent positive-definiteness matters.
major comments (3)
- [§3] §3 (sieve construction): The Bernstein-polynomial sieve is defined directly on the covariance function without coefficient restrictions that enforce complete monotonicity of C(√t) on [0,∞). Schoenberg’s theorem requires this property for validity in every dimension; the paper reports only L∞/L2 approximation error and does not verify or constrain the alternating-derivative sign pattern, so the estimator can converge in the stated norms while producing functions that cease to be positive definite for large spatial dimensions.
- [§4] §4 (consistency theorem): The consistency statement for the sieve ML estimator is given without an explicit convergence rate, without conditions on the growth of the polynomial degree with sample size, and without details on how the degree is selected in practice or in the asymptotics. This leaves the result non-quantitative and makes it impossible to judge whether the sieve dimension choice is compatible with the increasing-domain regime.
- [Numerical results] Numerical results section (Tables/Figures on L∞ and L2 errors): The computation of the reported expected L∞ and L2 norms is not described (e.g., how the supremum is discretized, whether the estimated functions are projected onto the valid cone, or the precise data-exclusion rules used to avoid circularity). Without these details the claimed superiority over other nonparametric methods cannot be reproduced or assessed.
minor comments (2)
- [Abstract] Abstract: “covaraince” is misspelled; “couple of existing nonparametric” should read “a couple of existing nonparametric.”
- [§2–3] Notation: The transition from the population covariance C(h) to the sieve approximant is not clearly distinguished from the estimated version; a single symbol is used in several places, which obscures whether statements refer to approximation error or estimation error.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§3] §3 (sieve construction): The Bernstein-polynomial sieve is defined directly on the covariance function without coefficient restrictions that enforce complete monotonicity of C(√t) on [0,∞). Schoenberg’s theorem requires this property for validity in every dimension; the paper reports only L∞/L2 approximation error and does not verify or constrain the alternating-derivative sign pattern, so the estimator can converge in the stated norms while producing functions that cease to be positive definite for large spatial dimensions.
Authors: We agree that Schoenberg’s theorem requires complete monotonicity of C(√t) for the covariance to be valid in all dimensions, and that the current sieve construction does not explicitly impose the alternating-sign coefficient restrictions needed to guarantee this property. While Bernstein polynomials can approximate completely monotone functions, the lack of explicit constraints means the estimator could in principle produce non-valid functions for large dimensions. We will revise §3 to incorporate the necessary coefficient restrictions (or a post-estimation projection step) that enforce complete monotonicity, and we will verify that the resulting sieve satisfies the required sign pattern. revision: yes
-
Referee: [§4] §4 (consistency theorem): The consistency statement for the sieve ML estimator is given without an explicit convergence rate, without conditions on the growth of the polynomial degree with sample size, and without details on how the degree is selected in practice or in the asymptotics. This leaves the result non-quantitative and makes it impossible to judge whether the sieve dimension choice is compatible with the increasing-domain regime.
Authors: The consistency theorem in §4 is established under increasing-domain asymptotics, with the sieve dimension permitted to grow with sample size. However, we acknowledge that the statement lacks an explicit rate, precise growth conditions on the polynomial degree, and practical selection guidance, rendering it non-quantitative. We will revise the theorem and surrounding discussion to include these details, specifying admissible growth rates for the sieve dimension that remain compatible with the increasing-domain regime and describing the data-driven selection procedure used in the numerical studies. revision: yes
-
Referee: Numerical results section (Tables/Figures on L∞ and L2 errors): The computation of the reported expected L∞ and L2 norms is not described (e.g., how the supremum is discretized, whether the estimated functions are projected onto the valid cone, or the precise data-exclusion rules used to avoid circularity). Without these details the claimed superiority over other nonparametric methods cannot be reproduced or assessed.
Authors: We agree that the numerical section lacks sufficient detail on the computation of the expected L∞ and L2 norms. We will expand this section to describe the discretization grid used for the supremum, whether any projection onto the valid cone was performed, and the exact cross-validation or data-exclusion rules employed to prevent circularity, thereby enabling full reproducibility and assessment of the reported superiority. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines a Bernstein polynomial sieve directly on the covariance function, separately establishes its uniform and L2 approximation properties for continuous functions, then defines the sieve ML estimator via likelihood maximization over that sieve and proves consistency under increasing-domain asymptotics using standard arguments. None of these steps reduce the estimator, the consistency theorem, or the validity claim to a quantity fitted from the same data or to a self-citation whose content is the target result itself. The numerical comparisons and real-data illustration are post-derivation evaluations and do not feed back into the theoretical claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The target covariance function is continuous and isotropic on R^∞
- domain assumption Observations follow an increasing-domain asymptotic regime
Reference graph
Works this paper leans on
-
[1]
(1965), Handbook of Mathematical Functions, 9th ed., New York
Abramowitz, M., and Stegun, I. (1965), Handbook of Mathematical Functions, 9th ed., New York
work page 1965
-
[2]
(1985), Advanced Econometrics, Harvard University Press, pp
Amemiya, T. (1985), Advanced Econometrics, Harvard University Press, pp. 105--158. Asymptotic properties of extremum estimators
work page 1985
-
[3]
Anderson, T.W. (1970), Estimation of covariance matrices which are linear combinations or whose inverse are linear combinations of given matrices , Essays in Probability and Statistics, pp. 1--24
work page 1970
-
[4]
Bachoc, F. (2014), Asymptotic analysis for the role of spatial sampling for covariance parameter estimation of Gaussian processes , Journal of Multivariate Analysis, pp. 1--25
work page 2014
-
[5]
(2021), Oxford Handbook of Innovation, Springer, Cham, chap
Bachoc, F. (2021), Oxford Handbook of Innovation, Springer, Cham, chap. Asymptotic analysis of Maximum Likelihood Estimation of Covariance Parameters for Gaussian Processes: An Introduction with Proofs, pp. 283--303
work page 2021
-
[6]
Bachoc, F., and Furrer, R. (2016), On the smallest eigenvalues of covariance matrices of multivariate spatial processes , Stat, 1, 102--107
work page 2016
-
[7]
Bernstein, S. (1912), Demonstration of a theorem of Weierstrass based on the calculus of probabilities , Communications of the Kharkov Mathematical Society
work page 1912
-
[8]
Chen, X. (2007), Large Sample Sieve Estimation of Semi-Nonparametric Models , in Handbook of Econometrics, Vol. 6B, 1st ed., eds. J. Heckman and E. Leamer, chap. 76
work page 2007
-
[9]
Choi, I., Li, B., and Wang, X. (2013), Nonparametric Estimation of Spatial and Space-Time Covariance Function , Journal of Agricultural, Biological, and Environmental Statistics, 18, 611--630
work page 2013
-
[10]
Choudhuri, N., Ghosal, S., and Roy, A. (2004), Bayesian estimation of the spectral density of a time series , Journal of the American Statistical Association, 99, 1050--1059
work page 2004
-
[11]
(1993), Statistics for Spatial Data, John Wiley & Sons, New York
Cressie, N. (1993), Statistics for Spatial Data, John Wiley & Sons, New York
work page 1993
-
[12]
Cuzik, J. (1995), A Strong Law for Weighted Sums of i.i.d Random Variables , Statistics & Probability Letters, 76, 1482--1487
work page 1995
-
[13]
(2004), Least angle regression , Annals of Statistics, 32, 407--451
Efron, B., Hastie, T., Johnstone, I., and Tibshirani, R. (2004), Least angle regression , Annals of Statistics, 32, 407--451
work page 2004
-
[14]
Farouki, R.T. (2012), The Bernstein polynomial basis: a centennial retrospective , Computer Aided Geometric Design, 29, 379--419
work page 2012
-
[15]
(1981), Abstract Inference, Wiley, New York
Grenander, U. (1981), Abstract Inference, Wiley, New York
work page 1981
-
[16]
(1991), Topics in Matrix Analysis, Cambridge University Press
Horn, R., and Johnson, C. (1991), Topics in Matrix Analysis, Cambridge University Press
work page 1991
-
[17]
(2011), Nonparametric estimation of the variogram and its spectrum , Biometrika, 98, 775--789
Huang, C., Hsing, T., and Cressie, N. (2011), Nonparametric estimation of the variogram and its spectrum , Biometrika, 98, 775--789
work page 2011
-
[18]
Huang, J., and Rossini, A.J. (1997), Sieve Estimation for the Proportional-Odds Failure-Time Regression Model With Interval Censoring , Journal of the American Statistical Association, 92, 960--967
work page 1997
-
[19]
Im, H., Stein, M., and Zhu, Z. (2007), Semiparametric Estimation of Spectral Density With Irregular Observations , Journal of the American Statistical Association, 102, 726--735
work page 2007
-
[20]
Kaufman, C.G., Schervish, M.J., and Nychka, D.W. (2008), Tapering for Likelihood-Based Estimation in Large Spatial Data Sets , Journal of the American Statistical Association, pp. 1545--1555
work page 2008
-
[21]
Keshavarz, H., Scott, C., and Nguyen, X. (2016), On the consistency of inversion-free parameter estimation for Gaussian random fields , Journal of Multivariate Analysis, 150, 245--266
work page 2016
-
[22]
Newey, W.K. (1991), Uniform Convergence in Probability and Stochastic Equicontinuity , Econometrica, 59, 1161--1167
work page 1991
-
[23]
(1994), Handbook of Econometrics, Elsevier Science, chap
Newey, W.K., and McFadden, D. (1994), Handbook of Econometrics, Elsevier Science, chap. 4, pp. 2111--2245. Large sample estimation and hypothesis testing
work page 1994
-
[24]
Global Summary of The Month (GSOY) data retrieved at https://www.ncei.noaa.gov/data/gsoy/
NOAA (2020). Global Summary of The Month (GSOY) data retrieved at https://www.ncei.noaa.gov/data/gsoy/
work page 2020
-
[25]
Piotr, Z., Caroline, U., and Donald, R. (2017), Maximum likelihood estimation for linear Gaussian covariance models , Journal of Royal Statistical Society, 79, 1269--1292
work page 2017
-
[26]
Reich, B., and Fuentes, M. (2012), Nonparametric Bayesian models for a spatial covariance , Statistical Methodology, 9, 265--274
work page 2012
-
[27]
(1938), Metric spaces and completely monotone functions , Annals of Mathematics, 39, 811--841
Schoenberg, I. (1938), Metric spaces and completely monotone functions , Annals of Mathematics, 39, 811--841
work page 1938
-
[28]
Shaby, B., and Ruppert, D. (2012), Tapered Covariance: Bayesian Estimation and Asymptotics , Journal of Computational and Graphical Statistics, 21, 433--452
work page 2012
-
[29]
(1994), Convergence rate of sieve estimates , Annals of Statistics, 22
Shen, X., and Wong, W. (1994), Convergence rate of sieve estimates , Annals of Statistics, 22
work page 1994
-
[30]
(1999), Interpolation of Spatial Data: Some Theory for Kriging, Springer, New York
Stein, M. (1999), Interpolation of Spatial Data: Some Theory for Kriging, Springer, New York
work page 1999
-
[31]
(1996), Weak Convergence and Empirical Processes, Springer, New York
van der Vaart, A.W., and Wellner, J.A. (1996), Weak Convergence and Empirical Processes, Springer, New York
work page 1996
-
[32]
Xue, H., Miao, H., and Wu, H. (2010), Sieve estimation of constant and time-varying coefficients in nonlinear ordinary differential equation models by considering both numerical error and measurement error , Annals of Statistics, 38, 2351--2387
work page 2010
-
[33]
(2022), Covariance Function Estimation and Causal Inference Method, North Carolina State University
Wang, Y. (2022), Covariance Function Estimation and Causal Inference Method, North Carolina State University
work page 2022
-
[34]
Zhang, H. (2004), Inconsistent Estimation and Asymptotically Equivalent Interpolations in Model-based Geostatistics , Journal of the American Statistical Association, 99, 250--261
work page 2004
-
[35]
Zheng, Y., Zhu, J., and Roy, A. (2010), Nonparametric Bayesian Inference for the Spectral Density Function of a Random Field , Biometrika, 97, 238--245
work page 2010
-
[36]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor eid howpublished institution journal key month note number organization pages publisher school series title type url volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence...
-
[37]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in " " * FUNCTION format....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.