LaissezCloud: Continuous Resource Renegotiation for the Public Cloud
Pith reviewed 2026-05-08 09:44 UTC · model grok-4.3
The pith
LaissezCloud keeps cloud resource allocations continuously contestable through online bids so tenants retain them only while outbidding others.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LaissezCloud enables continuous re-negotiation of running allocations by having tenants and operators update bids online during execution. A tenant retains a resource only as long as its bid exceeds competing demand. The pricing mechanism serves as a narrow waist that aligns incentives between untrusted parties: tenants signal utility via bids, operators encode constraints like power or carbon without exposing telemetry. Across accelerator workloads the approach reduces performance degradation under contention by 8-23 percent versus on-demand and spot baselines and scales to clusters of at least 10,000 nodes.
What carries the argument
Continuous online bidding with pricing as the narrow waist for incentive alignment between tenants and operators.
Load-bearing premise
Continuous online bid updates can be performed efficiently and the pricing mechanism aligns incentives between untrusted tenants and operators without exposing internal states.
What would settle it
An experiment on a contended multi-tenant cluster showing either that bid-update overhead exceeds 5 percent of runtime or that performance degradation does not drop below the on-demand and spot baselines.
Figures





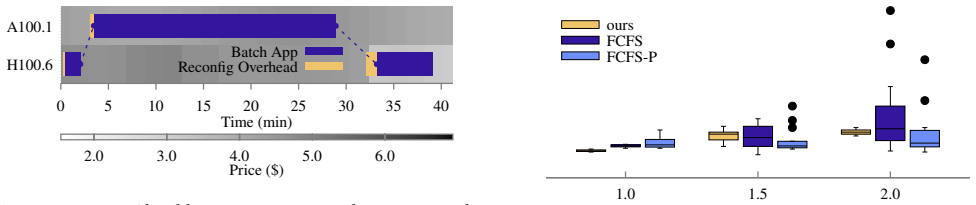





read the original abstract
Public clouds increasingly expose heterogeneous hardware, but their allocation interface remains built around rigid on-demand and spot service classes. This makes it hard to satisfy time-varying tenant objectives and operator constraints in oversubscribed, heterogeneous clusters without exposing internal application or infrastructure state. We present LaissezCloud, a cloud resource management platform for continuous re-negotiation of running allocations. Unlike spot instances, which use launch-time bids and unilateral preemption, LaissezCloud keeps allocations continuously contestable during execution: tenants and operators update bids online, and a running tenant keeps a resource only as long as its bid exceeds competing demand. Pricing serves both as a narrow waist and as an incentive-alignment mechanism between mutually untrusted participants: tenants express utility through bids, while operators price in power, cooling, or carbon constraints without exposing internal telemetry. Across a diverse set of accelerator workloads, LaissezCloud reduces performance degradation under contention by 8-23% versus on-demand and spot baselines, and scales to clusters of at least 10,000 nodes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LaissezCloud, a cloud resource management platform enabling continuous renegotiation of running allocations via online bid updates from tenants and operators. Pricing functions as a narrow waist for allocation decisions and incentive alignment between untrusted parties without exposing internal application or infrastructure state. The central empirical claims are an 8-23% reduction in performance degradation under contention versus on-demand and spot baselines across diverse accelerator workloads, together with demonstrated scaling to clusters of at least 10,000 nodes.
Significance. If the reported gains prove robust once bid-update overhead is quantified and the evaluation methodology is fully documented, the work would offer a substantive contribution to distributed systems and cloud computing by replacing rigid service classes with a continuously contestable, incentive-compatible allocation model. The empirical evaluation across workloads and the scaling result to 10k nodes are strengths that, if substantiated, would support broader adoption of pricing-mediated renegotiation.
major comments (2)
- [Abstract] Abstract: the performance claims (8-23% reduction in degradation and scaling to 10,000 nodes) are presented without any description of the evaluation methodology, workload characteristics, contention levels, measurement of bid-update frequency/latency, or per-node overhead. This absence directly undermines assessment of whether the data support the headline results, especially since continuous bidding traffic could offset the reported gains.
- [Abstract] Abstract: the central assumption that repeated online bid updates incur negligible cost relative to the workloads is load-bearing for both the performance improvement and the 10k-node scaling claim, yet the manuscript provides no measurements of message size, auction latency, consensus cost, or aggregate communication overhead in the contended regime.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires more context on methodology and overhead to substantiate the claims, and we have revised it accordingly while adding explicit overhead measurements to the evaluation section.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (8-23% reduction in degradation and scaling to 10,000 nodes) are presented without any description of the evaluation methodology, workload characteristics, contention levels, measurement of bid-update frequency/latency, or per-node overhead. This absence directly undermines assessment of whether the data support the headline results, especially since continuous bidding traffic could offset the reported gains.
Authors: We agree that the abstract is too terse and should briefly outline the evaluation to allow assessment of the claims. In the revised manuscript we have expanded the abstract to note the diverse accelerator workloads, contention scenarios, and that bid-update overhead was measured and remains low relative to gains (with pointers to Sections 4-6 for full methodology). revision: yes
-
Referee: [Abstract] Abstract: the central assumption that repeated online bid updates incur negligible cost relative to the workloads is load-bearing for both the performance improvement and the 10k-node scaling claim, yet the manuscript provides no measurements of message size, auction latency, consensus cost, or aggregate communication overhead in the contended regime.
Authors: We accept that dedicated measurements of bid-update overhead were insufficiently documented. While the scaling experiments implicitly incorporate communication costs, we have added an explicit subsection (5.3) with measurements of message sizes, auction latency, consensus costs, and aggregate overhead under contention. These confirm the overhead is small enough not to offset the reported gains or the 10k-node scaling. revision: yes
Circularity Check
No circularity: empirical system claims rest on evaluation, not self-referential derivations
full rationale
The paper describes a systems platform for continuous bid-based renegotiation and reports measured improvements (8-23% lower degradation, scaling to 10k nodes) from workload experiments. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Performance numbers are presented as direct experimental outcomes rather than outputs derived from the inputs by construction. The design uses pricing as an incentive mechanism, but this is an architectural choice justified by stated goals, not a tautological reduction. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Participants are mutually untrusted and will not expose internal state.
- domain assumption Bids can be updated online without disrupting running allocations.
invented entities (1)
-
LaissezCloud platform
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AIConfigurator: Offline optimization of your disaggregated dynamo graph, 2025
ai-dynamo contributors. AIConfigurator: Offline optimization of your disaggregated dynamo graph, 2025
work page 2025
-
[2]
Praneet Arshi and Joel Miller. Our approach to carbon- aware data centers: Central data center fleet manage- ment.https://cloud.google.com/blog/topics/sustainability/ googles-approach-to-carbon-aware-data-center, September
-
[3]
Google Cloud Blog post
-
[4]
scalable-hw-agnostic-inference.https://github.com/ aws-samples/scalable-hw-agnostic-inference
AWS Samples. scalable-hw-agnostic-inference.https://github.com/ aws-samples/scalable-hw-agnostic-inference. GitHub repository for hardware-agnostic inference on mixed accelerators
-
[5]
Hamid Hajabdolali Bazzaz, Yingjie Bi, Weiwu Pang, Minlan Yu, Ramesh Govindan, Neal Cardwell, Nandita Dukkipati, Meng-Jung Tsai, Chris DeForeest, Yuxue Jin, Charles Carver, Jan Kopański, Liqun Cheng, and Amin Vahdat. Preventing network bottlenecks: Accelerat- ing datacenter services with Hotspot-Aware placement for compute and storage. In22nd USENIX Sympos...
-
[6]
Cilantro: Performance-Aware resource allocation for general objectives via online feedback
Romil Bhardwaj, Kirthevasan Kandasamy, Asim Biswal, Wenshuo Guo, Benjamin Hindman, Joseph Gonzalez, Michael Jordan, and Ion Stoica. Cilantro: Performance-Aware resource allocation for general objectives via online feedback. In17th USENIX Symposium on Oper- ating Systems Design and Implementation (OSDI 23), pages 623–643, Boston, MA, July 2023. USENIX Association
work page 2023
-
[7]
Eva: Cost-efficient cloud- based cluster scheduling
Tzu-Tao Chang and Shivaram Venkataraman. Eva: Cost-efficient cloud- based cluster scheduling. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1399–1416, New York, NY, USA, 2025. Association for Computing Machinery
work page 2025
-
[8]
Balancing efficiency and fair- ness in heterogeneous gpu clusters for deep learning
Shubham Chaudhary, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwatra, and Srinidhi Viswanatha. Balancing efficiency and fair- ness in heterogeneous gpu clusters for deep learning. InProceedings of the Fifteenth European Conference on Computer Systems, EuroSys ’20, New York, NY, USA, 2020. Association for Computing Machinery
work page 2020
-
[9]
Parabricks Benchmarks: Benchmarking guide and scripts for NVIDIA Parabricks workflows,
clara-parabricks-workflows contributors. Parabricks Benchmarks: Benchmarking guide and scripts for NVIDIA Parabricks workflows,
-
[10]
README notes cloud instance prices as of July 2024
work page 2024
-
[11]
Sf compute documentation.https://docs.sfcompute.com/ docs/on-demand-and-spot
Company. Sf compute documentation.https://docs.sfcompute.com/ docs/on-demand-and-spot. Accessed: 2025-02-14
work page 2025
-
[12]
Parcae: proactive, liveput-optimized dnn training on preemptible instances
Jiangfei Duan, Ziang Song, Xupeng Miao, Xiaoli Xi, Dahua Lin, Harry Xu, Minjia Zhang, and Zhihao Jia. Parcae: proactive, liveput-optimized dnn training on preemptible instances. InProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation, NSDI’24, USA, 2024. USENIX Association
work page 2024
-
[13]
Financial Industry Regulatory Authority (FINRA).Plan to Address Extraordinary Market Volatility, April 2016. Pursuant to Rule 608 of Regulation NMS under the Securities Exchange Act of 1934; effective April 21, 2016. PDF
work page 2016
-
[14]
ServerlessLLM: Low-Latency serverless inference for large language models
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. ServerlessLLM: Low-Latency serverless inference for large language models. In18th USENIX Sym- posium on Operating Systems Design and Implementation (OSDI 24), pages 135–153, Santa Clara, CA, July 2024. USENIX Association
work page 2024
-
[15]
Dominant resource fairness: fair allocation of multiple resource types
Ali Ghodsi, Matei Zaharia, Benjamin Hindman, Andy Konwinski, Scott Shenker, and Ion Stoica. Dominant resource fairness: fair allocation of multiple resource types. InProceedings of the 8th USENIX Conference on Networked Systems Design and Implementation, NSDI’11, page 323–336, USA, 2011. USENIX Association
work page 2011
-
[16]
Altruistic scheduling in Multi-Resource clusters
Robert Grandl, Mosharaf Chowdhury, Aditya Akella, and Ganesh Ananthanarayanan. Altruistic scheduling in Multi-Resource clusters. In12th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI 16), pages 65–80, Savannah, GA, November 2016. USENIX Association
work page 2016
-
[17]
Hacc: extreme scaling and performance across diverse architectures
Salman Habib, Vitali Morozov, Nicholas Frontiere, Hal Finkel, Adrian Pope, and Katrin Heitmann. Hacc: extreme scaling and performance across diverse architectures. InProceedings of the International Confer- ence on High Performance Computing, Networking, Storage and Analysis, SC ’13, New York, NY, USA, 2013. Association for Computing Machin- ery
work page 2013
-
[18]
Aaron Harlap, Alexey Tumanov, Andrew Chung, Gregory R. Ganger, and Phillip B. Gibbons. Proteus: agile ml elasticity through tiered reliability in dynamic resource markets. InProceedings of the Twelfth European Conference on Computer Systems, EuroSys ’17, page 589–604. ACM, April 2017
work page 2017
-
[19]
Joseph, Randy Katz, Scott Shenker, and Ion Stoica
Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, An- thony D. Joseph, Randy Katz, Scott Shenker, and Ion Stoica. Mesos: a platform for fine-grained resource sharing in the data center. In Proceedings of the 8th USENIX Conference on Networked Systems De- sign and Implementation, NSDI’11, page 295–308, USA, 2011. USENIX Association
work page 2011
-
[20]
Iqbal, Haley Li, Shane Bergsma, Ivan Beschastnikh, and Alan J
Syed M. Iqbal, Haley Li, Shane Bergsma, Ivan Beschastnikh, and Alan J. Hu. Cospot: a cooperative vm allocation framework for increased revenue from spot instances. InProceedings of the 13th Symposium on Cloud Computing, SoCC ’22, page 540–556, New York, NY, USA, 2022. Association for Computing Machinery
work page 2022
-
[21]
The price is (not) right: Reflec- tions on pricing for transient cloud servers
David Irwin, Prashant Shenoy, Pradeep Ambati, Prateek Sharma, Supreeth Shastri, and Ahmed Ali-Eldin. The price is (not) right: Reflec- tions on pricing for transient cloud servers. In2019 28th International Conference on Computer Communication and Networks (ICCCN), pages 1–9, 2019
work page 2019
-
[22]
Suhas Jayaram Subramanya, Daiyaan Arfeen, Shouxu Lin, Aurick Qiao, Zhihao Jia, and Gregory R. Ganger. Sia: Heterogeneity-aware, goodput-optimized ml-cluster scheduling. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 642–657, New York, NY, USA, 2023. Association for Computing Machinery
work page 2023
-
[23]
Beomyeol Jeon, Chen Wang, Diana Arroyo, Alaa Youssef, and Indranil Gupta. A house united within itself: Slo-awareness for on-premises containerized ml inference clusters via faro. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 524–540. ACM, March 2025
work page 2025
-
[24]
Lambda: The deep learning company.https://www
Lambda Labs. Lambda: The deep learning company.https://www. lambdalabs.com
-
[25]
Flux: Unifying heterogeneous infrastructure for alibaba analyticdb
Wei Li, Jiachi Zhang, Ye Yin, Yan Li, Zhanyang Zhu, Yuhao Li, Zhen- can Peng, Lan Lu, Wenchao Zhou, Liang Lin, and Feifei Li. Flux: Unifying heterogeneous infrastructure for alibaba analyticdb. InCom- panion of the 2025 International Conference on Management of Data, SIGMOD/PODS ’25, page 539–552. ACM, June 2025
work page 2025
-
[26]
Xinyu Lian, Sam Ade Jacobs, Lev Kurilenko, Masahiro Tanaka, Stas Bekman, Olatunji Ruwase, and Minjia Zhang. Universal checkpointing: a flexible and efficient distributed checkpointing system for large-scale dnn training with reconfigurable parallelism. InProceedings of the 2025 USENIX Conference on Usenix Annual Technical Conference, USENIX ATC ’25, USA, ...
work page 2025
-
[27]
Themis: Fair and efficient GPU cluster scheduling
Kshiteej Mahajan, Arjun Balasubramanian, Arjun Singhvi, Shivaram Venkataraman, Aditya Akella, Amar Phanishayee, and Shuchi Chawla. Themis: Fair and efficient GPU cluster scheduling. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), pages 289–304, Santa Clara, CA, February 2020. USENIX Associa- tion
work page 2020
-
[28]
Microsoft.Microsoft Volume Licensing Service Level Agreement for Mi- crosoft Online Services (Worldwide English, January 1, 2026). Microsoft, January 2026. PDF; filename indicates document ID SLA5280
work page 2026
-
[29]
Heet: Accelerating elastic training in heterogeneous deep learning clusters
Zizhao Mo, Huanle Xu, and Chengzhong Xu. Heet: Accelerating elastic training in heterogeneous deep learning clusters. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’24, page 499–513, New York, NY, USA, 2024. Association for Computing Machinery. 13
work page 2024
-
[30]
Ras: Continuously optimized region-wide dat- acenter resource allocation
Andrew Newell, Dimitrios Skarlatos, Jingyuan Fan, Pavan Kumar, Maxim Khutornenko, Mayank Pundir, Yirui Zhang, Mingjun Zhang, Yuanlai Liu, Linh Le, Brendon Daugherty, Apurva Samudra, Prashasti Baid, James Kneeland, Igor Kabiljo, Dmitry Shchukin, Andre Ro- drigues, Scott Michelson, Ben Christensen, Kaushik Veeraraghavan, and Chunqiang Tang. Ras: Continuousl...
work page 2021
-
[31]
Nvidia dynamo documentation.https://docs
NVIDIA Corporation. Nvidia dynamo documentation.https://docs. nvidia.com/dynamo/index.html, 2025. Accessed: 2025-12-11
work page 2025
-
[32]
NVIDIA Parabricks: GPU-accelerated genomics pipelines, 2025
NVIDIA Corporation. NVIDIA Parabricks: GPU-accelerated genomics pipelines, 2025
work page 2025
-
[33]
Spar- row: distributed, low latency scheduling
Kay Ousterhout, Patrick Wendell, Matei Zaharia, and Ion Stoica. Spar- row: distributed, low latency scheduling. InProceedings of the Twenty- Fourth ACM Symposium on Operating Systems Principles, SOSP ’13, page 69–84. ACM, November 2013
work page 2013
-
[34]
Modserve: Modality- and stage-aware resource disaggregation for scalable multimodal model serving
Haoran Qiu, Anish Biswas, Zihan Zhao, Jayashree Mohan, Alind Khare, Esha Choukse, Íñigo Goiri, Zeyu Zhang, Haiying Shen, Chetan Bansal, Ramachandran Ramjee, and Rodrigo Fonseca. Modserve: Modality- and stage-aware resource disaggregation for scalable multimodal model serving. InProceedings of the 2025 ACM Symposium on Cloud Computing (SoCC 2025), New York...
work page 2025
-
[35]
Stratus: Clouds with microar- chitectural resource management
Kaveh Razavi and Animesh Trivedi. Stratus: Clouds with microar- chitectural resource management. In12th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 20). USENIX Association, July 2020
work page 2020
-
[36]
Aws pricing calculator.https://calculator.aws/ #/, 2025
Amazon Web Services. Aws pricing calculator.https://calculator.aws/ #/, 2025. Web-based cost estimation tool for Amazon Web Services
work page 2025
-
[37]
Jeffrey Shneidman, Chaki Ng, David C. Parkes, Alvin AuYoung, Alex C. Snoeren, Amin Vahdat, and Brent Chun. Why markets could (but don’t currently) solve resource allocation problems in systems. In Proceedings of the 10th Conference on Hot Topics in Operating Systems - Volume 10, HOTOS’05, page 7, USA, 2005. USENIX Association
work page 2005
-
[38]
Ecovisor: A virtual energy sys- tem for carbon-efficient applications
Abel Souza, Noman Bashir, Jorge Murillo, Walid Hanafy, Qianlin Liang, David Irwin, and Prashant Shenoy. Ecovisor: A virtual energy sys- tem for carbon-efficient applications. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Lan- guages and Operating Systems, Volume 2, ASPLOS 2023, page 252–265, New York, NY, ...
work page 2023
-
[39]
Tapas: Thermal- and power-aware scheduling for llm inference in cloud platforms
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Esha Choukse, Haoran Qiu, Rodrigo Fonseca, Josep Torrellas, and Ricardo Bianchini. Tapas: Thermal- and power-aware scheduling for llm inference in cloud platforms. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’2...
-
[40]
Association for Computing Machinery
-
[41]
Dynamollm: Designing llm inference clusters for perfor- mance and energy efficiency, 2024
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. Dynamollm: Designing llm inference clusters for perfor- mance and energy efficiency, 2024
work page 2024
-
[42]
Orion: Interference- aware, fine-grained gpu sharing for ml applications
Foteini Strati, Xianzhe Ma, and Ana Klimovic. Orion: Interference- aware, fine-grained gpu sharing for ml applications. InProceedings of the Nineteenth European Conference on Computer Systems, EuroSys ’24, page 1075–1092, New York, NY, USA, 2024. Association for Computing Machinery
work page 2024
-
[43]
Sailor: Automating distributed training over dynamic, heterogeneous, and geo-distributed clusters
Foteini Strati, Zhendong Zhang, George Manos, Ixeia Sánchez Périz, Qinghao Hu, Tiancheng Chen, Berk Buzcu, Song Han, Pamela Del- gado, and Ana Klimovic. Sailor: Automating distributed training over dynamic, heterogeneous, and geo-distributed clusters. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP ’25, page 204–220. A...
work page 2025
- [44]
-
[45]
Twine: A unified cluster management system for shared infrastructure
Chunqiang Tang, Kenny Yu, Kaushik Veeraraghavan, Jonathan Kaldor, Scott Michelson, Thawan Kooburat, Aravind Anbudurai, Matthew Clark, Kabir Gogia, Long Cheng, Ben Christensen, Alex Gartrell, Maxim Khutornenko, Sachin Kulkarni, Marcin Pawlowski, Tuomas Pelkonen, Andre Rodrigues, Rounak Tibrewal, Vaishnavi Venkatesan, and Peter Zhang. Twine: A unified clust...
work page 2020
-
[46]
Korupolu, David Oppen- heimer, Eric Tune, and John Wilkes
Abhishek Verma, Luis Pedrosa, Madhukar R. Korupolu, David Oppen- heimer, Eric Tune, and John Wilkes. Large-scale cluster management at google with borg. InProceedings of the European Conference on Computer Systems (EuroSys), Bordeaux, France, 2015
work page 2015
-
[47]
Karma: Resource allocation for dynamic demands
Midhul Vuppalapati, Giannis Fikioris, Rachit Agarwal, Asaf Cidon, Anurag Khandelwal, and Éva Tardos. Karma: Resource allocation for dynamic demands. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23), pages 645–662, Boston, MA, July
-
[48]
Tenplex: Dynamic parallelism for deep learning using parallelizable tensor collections
Marcel Wagenländer, Guo Li, Bo Zhao, Luo Mai, and Peter Pietzuch. Tenplex: Dynamic parallelism for deep learning using parallelizable tensor collections. InProceedings of the ACM SIGOPS 30th Sympo- sium on Operating Systems Principles, SOSP ’24, page 195–210. ACM, November 2024
work page 2024
- [49]
-
[50]
Can’t be late: Optimizing spot instance savings under deadlines
Zhanghao Wu, Wei-Lin Chiang, Ziming Mao, Zongheng Yang, Eric Friedman, Scott Shenker, and Ion Stoica. Can’t be late: Optimizing spot instance savings under deadlines. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 185–203, Santa Clara, CA, April 2024. USENIX Association
work page 2024
-
[51]
Gödel: Unified large-scale resource management and scheduling at bytedance
Wu Xiang, Yakun Li, Yuquan Ren, Fan Jiang, Chaohui Xin, Varun Gupta, Chao Xiang, Xinyi Song, Meng Liu, Bing Li, Kaiyang Shao, Chen Xu, Wei Shao, Yuqi Fu, Wilson Wang, Cong Xu, Wei Xu, Caixue Lin, Rui Shi, and Yuming Liang. Gödel: Unified large-scale resource management and scheduling at bytedance. InProceedings of the 2023 ACM Symposium on Cloud Computing...
work page 2023
-
[52]
Gandiva: Introspective cluster scheduling for deep learning
Wencong Xiao, Romil Bhardwaj, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwatra, Zhenhua Han, Pratyush Patel, Xuan Peng, Hanyu Zhao, Quanlu Zhang, Fan Yang, and Lidong Zhou. Gandiva: Introspective cluster scheduling for deep learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 595–610, Carlsbad, CA, October ...
work page 2018
-
[53]
Jiali Xing, Bilge Acun, Aditya Sundarrajan, David Brooks, Manoj Chakkaravarthy, Nikky Avila, Carole-Jean Wu, and Benjamin C. Lee. Carbon responder: Coordinating demand response for the datacenter fleet, 2023
work page 2023
-
[54]
SkyPilot: An intercloud broker for sky computing
Zongheng Yang, Zhanghao Wu, Michael Luo, Wei-Lin Chiang, Romil Bhardwaj, Woosuk Kwon, Siyuan Zhuang, Frank Sifei Luan, Gautam Mittal, Scott Shenker, and Ion Stoica. SkyPilot: An intercloud broker for sky computing. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 437–455, Boston, MA, April 2023. USENIX Association
work page 2023
-
[55]
Zeus: Under- standing and optimizing GPU energy consumption of DNN training
Jie You, Jae-Won Chung, and Mosharaf Chowdhury. Zeus: Under- standing and optimizing GPU energy consumption of DNN training. In20th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 23), pages 119–139, Boston, MA, April 2023. USENIX Association
work page 2023
-
[56]
SHEP- HERD: Serving DNNs in the wild
Hong Zhang, Yupeng Tang, Anurag Khandelwal, and Ion Stoica. SHEP- HERD: Serving DNNs in the wild. In20th USENIX Symposium on Net- worked Systems Design and Implementation (NSDI 23), pages 787–808, Boston, MA, April 2023. USENIX Association
work page 2023
-
[57]
Shockwave: Fair and efficient cluster scheduling for dynamic adaptation in machine learning
Pengfei Zheng, Rui Pan, Tarannum Khan, Shivaram Venkataraman, and Aditya Akella. Shockwave: Fair and efficient cluster scheduling for dynamic adaptation in machine learning. In20th USENIX Symposium 14 on Networked Systems Design and Implementation (NSDI 23), pages 703–723, Boston, MA, April 2023. USENIX Association
work page 2023
-
[58]
Zhiheng Zhong and Rajkumar Buyya. A cost-efficient container or- chestration strategy in kubernetes-based cloud computing infrastruc- tures with heterogeneous resources.ACM Transactions on Internet Technology, 20(2):1–24, April 2020
work page 2020
-
[59]
Çınar Kilcioglu, Justin M. Rao, Aadharsh Kannan, and R. Preston McAfee. Usage patterns and the economics of the public cloud. In Proceedings of the 26th International Conference on World Wide Web (WWW ’17). International World Wide Web Conferences Steering Committee, 2017. Includes empirical analysis of utilization in public cloud systems. 15
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.