Recognition: unknown
ASPIRE: Make Spectral Graph Collaborative Filtering Great Again via Adaptive Filter Learning
Pith reviewed 2026-05-08 10:03 UTC · model grok-4.3
The pith
Bi-level optimization disentangles filter learning to overcome low-frequency explosion bias in spectral graph collaborative filtering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
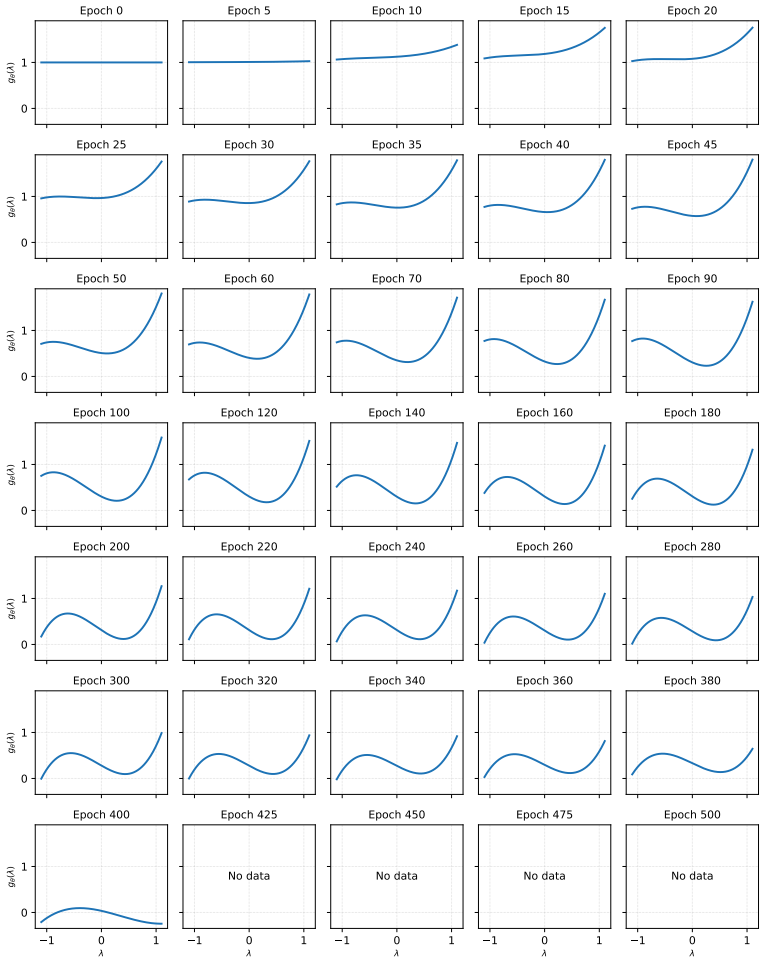
Traditional recommendation losses induce a low-frequency explosion phenomenon that fundamentally prevents effective learning of graph filters. ASPIRE formulates a bi-level optimization objective to disentangle the filter learning process, allowing the model to discover adaptive filters. The resulting framework achieves strong recommendation accuracy, spectral adaptivity across different graphs, and stable training, with learned filters matching the results of hand-engineered task-specific designs and remaining effective in LLM-powered collaborative filtering.
What carries the argument
The bi-level optimization objective that separates filter parameter learning from the recommendation loss, directly addressing the low-frequency explosion bias identified in the spectral analysis.
If this is right
- Learned filters deliver excellent recommendation performance without manual tuning.
- The approach provides spectral adaptivity to different graph structures.
- Training remains stable in practice compared to direct filter optimization.
- The same framework works effectively when applied to LLM-powered collaborative filtering.
- Graph filter learning becomes viable and generalizable for building more expressive models.
Where Pith is reading between the lines
- The bi-level disentanglement technique could be adapted to improve learnability in other graph signal processing tasks outside recommendations.
- Adaptive filters might help handle shifting user behavior in dynamic or session-based recommendation scenarios.
- Applying the method to additional graph types, such as heterogeneous or temporal graphs, would test how broadly the low-frequency bias issue appears.
Load-bearing premise
The low-frequency explosion bias is the main barrier to filter learning and bi-level optimization can disentangle and fix it reliably on real recommendation data without causing instability or overfitting.
What would settle it
Training ASPIRE on standard benchmarks such as MovieLens or Amazon review data yields filters whose performance falls short of carefully tuned baselines or shows clear instability during optimization.
Figures

























read the original abstract
Graph filter design is central to spectral collaborative filtering, yet most existing methods rely on manually tuned hyperparameters rather than fully learnable filters. We show that this challenge stems from a bias in traditional recommendation objectives, which induces a spectral phenomenon termed low-frequency explosion, thereby fundamentally hindering the effective learning of graph filters. To overcome this limitation, we propose a novel adaptive spectral graph collaborative filtering framework (ASPIRE) based on a bi-level optimization objective. Guided by our theoretical analysis, we disentangle the filter learning objective, which in turn leads to excellent recommendation performance, spectral adaptivity, and training stability in practice. Extensive experiments show our learned filters match the performance of carefully engineered task-specific designs. Furthermore, ASPIRE is equally effective in LLM-powered collaborative filtering. Our findings demonstrate that graph filter learning is viable and generalizable, paving the way for more expressive graph neural networks in collaborative filtering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that traditional recommendation objectives induce a 'low-frequency explosion' bias that fundamentally hinders learnable graph filter design in spectral collaborative filtering. The authors propose ASPIRE, a bi-level optimization framework that disentangles filter learning from the primary recommendation objective. Guided by theoretical spectral analysis, this yields adaptive filters with strong empirical performance, spectral adaptivity, and training stability. Experiments show the learned filters match hand-engineered task-specific designs and remain effective in LLM-powered collaborative filtering.
Significance. If the bi-level formulation and theoretical analysis hold, the work meaningfully advances spectral methods in collaborative filtering by removing reliance on manual filter tuning. It provides a generalizable path to more expressive GNNs in recommendation and demonstrates viability for emerging LLM-based CF. The combination of explicit bias derivation, parameter separation without circularity, and multi-dataset validation (including LLM extension) constitutes a solid contribution to the field.
minor comments (3)
- Abstract: replace the subjective phrase 'excellent recommendation performance' with concrete quantitative gains (e.g., relative NDCG@10 improvement) over the strongest baselines.
- §5 (Experiments): add a brief ablation isolating the effect of the bi-level objective versus a single-level counterpart, and report the number of random seeds together with statistical significance tests.
- Notation and §3: introduce the precise mathematical form of the bi-level objective and all filter-related symbols at the first appearance rather than deferring definitions.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work and the recommendation for minor revision. We appreciate the recognition of the bi-level optimization framework, the theoretical derivation of the low-frequency explosion bias, the empirical validation across datasets, and the extension to LLM-powered collaborative filtering as meaningful advances in spectral graph methods for recommendation.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's core derivation begins with an explicit spectral analysis of bias in standard recommendation losses (low-frequency explosion), which is presented as an independent theoretical finding rather than a redefinition of the target metric. This analysis then motivates a bi-level optimization objective that separates filter parameters from the main loss, framed as a disentanglement step with no equations shown reducing predictions back to fitted inputs by construction. No self-citation chains, ansatz smuggling, or uniqueness theorems imported from prior author work appear load-bearing in the abstract or skeptic summary; the bi-level formulation and experimental validation on multiple datasets are treated as externally falsifiable contributions. The derivation remains self-contained against the stated assumptions without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Traditional recommendation objectives induce a low-frequency explosion bias that hinders graph filter learning
Reference graph
Works this paper leans on
-
[1]
Efficient top-n recommendation for very large scale binary rated datasets
Fabio Aiolli. Efficient top-n recommendation for very large scale binary rated datasets. InACM Conference on Recommender Systems (RecSys), pages 273–280, 2013
2013
-
[2]
Bi-level optimization for generative recommendation: Bridging tokenization and generation
Yimeng Bai, Chang Liu, Yang Zhang, Dingxian Wang, Frank Yang, Andrew Rabinovich, Wenge Rong, and Fuli Feng. Bi-level optimization for generative recommendation: Bridging tokenization and generation. InACM International Conference on Research and Development in Information Retrieval (SIGIR), 2026
2026
-
[3]
Spectral Networks and Locally Connected Networks on Graphs
Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral networks and locally connected networks on graphs.arXiv preprint arXiv:1312.6203, 2013
work page Pith review arXiv 2013
-
[4]
2nd workshop on information heterogeneity and fusion in recommender systems (hetrec 2011)
Iván Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2nd workshop on information heterogeneity and fusion in recommender systems (hetrec 2011). InACM Conference on Recommender Systems (RecSys), RecSys 2011, 2011
2011
-
[5]
Cross-domain recom- mendation with behavioral importance perception
Hong Chen, Xin Wang, Ruobing Xie, Yuwei Zhou, and Wenwu Zhu. Cross-domain recom- mendation with behavioral importance perception. InACM Web Conference (WWW), pages 1294–1304, 2023
2023
-
[6]
Blurring-sharpening process models for collaborative filtering
Jeongwhan Choi, Seoyoung Hong, Noseong Park, and Sung-Bae Cho. Blurring-sharpening process models for collaborative filtering. InACM International Conference on Research and Development in Information Retrieval (SIGIR), pages 1096–1106, 2023
2023
-
[7]
An overview of bilevel optimization
Benoît Colson, Patrice Marcotte, and Gilles Savard. An overview of bilevel optimization. Annals of Operations Sesearch, 153(1):235–256, 2007. 10
2007
-
[8]
Indexing by latent semantic analysis.Journal of the American Society for Information Science, 41(6):391–407, 1990
Scott Deerwester, Susan T Dumais, George W Furnas, Thomas K Landauer, and Richard Harsh- man. Indexing by latent semantic analysis.Journal of the American Society for Information Science, 41(6):391–407, 1990
1990
-
[9]
Convolutional neural networks on graphs with fast localized spectral filtering
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. InAdvances in Neural Information Processing Systems (NeurIPS), volume 29, 2016
2016
-
[10]
Neural message passing for quantum chemistry
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. InInternational Conference on Machine Learning (ICML), pages 1263–1272. PMLR, 2017
2017
-
[11]
On manipulating signals of user-item graph: A jacobi polynomial-based graph collaborative filtering
Jiayan Guo, Lun Du, Xu Chen, Xiaojun Ma, Qiang Fu, Shi Han, Dongmei Zhang, and Yan Zhang. On manipulating signals of user-item graph: A jacobi polynomial-based graph collaborative filtering. InACM International Conference on Knowledge Discovery & Data Mining (KDD), pages 602–613, 2023
2023
-
[12]
Lgmrec: Local and global graph learning for multimodal recommendation
Zhiqiang Guo, Jianjun Li, Guohui Li, Chaoyang Wang, Si Shi, and Bin Ruan. Lgmrec: Local and global graph learning for multimodal recommendation. InAAAI Conference on Artificial Intelligence (AAAI), volume 38, pages 8454–8462, 2024
2024
-
[13]
Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering
Ruining He and Julian McAuley. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. InACM Web Conference (WWW), pages 507–517, 2016
2016
-
[14]
Lightgcn: Simplifying and powering graph convolution network for recommendation
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. Lightgcn: Simplifying and powering graph convolution network for recommendation. InACM Inter- national Conference on Research and Development in Information Retrieval (SIGIR), pages 639–648, 2020
2020
-
[15]
Collaborative filtering meets spectrum shift: Connecting user-item interaction with graph-structured side information
Yunhang He, Cong Xu, Jun Wang, and Wei Zhang. Collaborative filtering meets spectrum shift: Connecting user-item interaction with graph-structured side information. InACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), pages 920–931, 2025
2025
-
[16]
Spectral graph neural networks are incomplete on graphs with a simple spectrum
Snir Hordan, Maya Bechler-Speicher, Gur Lifshitz, and Nadav Dym. Spectral graph neural networks are incomplete on graphs with a simple spectrum. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[17]
Whiteningbert: An easy unsupervised sentence embedding approach
Junjie Huang, Duyu Tang, Wanjun Zhong, Shuai Lu, Linjun Shou, Ming Gong, Daxin Jiang, and Nan Duan. Whiteningbert: An easy unsupervised sentence embedding approach. InFindings of Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 238–244, 2021
2021
-
[18]
Challenging low homophily in social recommendation
Wei Jiang, Xinyi Gao, Guandong Xu, Tong Chen, and Hongzhi Yin. Challenging low homophily in social recommendation. InACM Web Conference (WWW), pages 3476–3484, 2024
2024
-
[19]
How does message passing improve collaborative filtering? InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 8760–8784, 2024
Clark M Ju, William Shiao, Zhichun Guo, Yanfang Ye, Yozen Liu, Neil Shah, and Tong Zhao. How does message passing improve collaborative filtering? InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 8760–8784, 2024
2024
-
[20]
Graph spectral filtering with chebyshev interpolation for recommendation
Chanwoo Kim, Jinkyu Sung, Yebonn Han, and Joonseok Lee. Graph spectral filtering with chebyshev interpolation for recommendation. InACM International Conference on Research and Development in Information Retrieval (SIGIR), pages 1964–1974, 2025
1964
-
[21]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[22]
Semi-supervised classification with graph convolutional networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations (ICLR), 2016
2016
-
[23]
Deeper insights into graph convolutional networks for semi-supervised learning
Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. InAAAI Conference on Artificial Intelligence (AAAI), 2018. 11
2018
-
[24]
Gume: Graphs and user modalities enhancement for long-tail multimodal recommendation
Guojiao Lin, Meng Zhen, Dongjie Wang, Qingqing Long, Yuanchun Zhou, and Meng Xiao. Gume: Graphs and user modalities enhancement for long-tail multimodal recommendation. In ACM International Conference on Information and Knowledge Management (CIKM), pages 1400–1409, 2024
2024
-
[25]
Improving graph collaborative filtering with neighborhood-enriched contrastive learning
Zihan Lin, Changxin Tian, Yupeng Hou, and Wayne Xin Zhao. Improving graph collaborative filtering with neighborhood-enriched contrastive learning. InACM Web Conference (WWW), pages 2320–2329, 2022
2022
-
[26]
Interest-aware message-passing gcn for recommendation
Fan Liu, Zhiyong Cheng, Lei Zhu, Zan Gao, and Liqiang Nie. Interest-aware message-passing gcn for recommendation. InACM Web Conference (WWW), pages 1296–1305, 2021
2021
-
[27]
Feng Liu, Hao Cang, Huanhuan Yuan, Jiaqing Fan, Yongjing Hao, Fuzhen Zhuang, Guanfeng Liu, and Pengpeng Zhao. How do graph signals affect recommendation: Unveiling the mystery of low and high-frequency graph signals.arXiv preprint arXiv:2512.15744, 2025
-
[28]
Personalized graph signal processing for collaborative filtering
Jiahao Liu, Dongsheng Li, Hansu Gu, Tun Lu, Peng Zhang, Li Shang, and Ning Gu. Personalized graph signal processing for collaborative filtering. InACM Web Conference (WWW), pages 1264–1272, 2023
2023
-
[29]
Revisiting graph contrastive learning from the perspective of graph spectrum
Nian Liu, Xiao Wang, Deyu Bo, Chuan Shi, and Jian Pei. Revisiting graph contrastive learning from the perspective of graph spectrum. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 2972–2983, 2022
2022
-
[30]
Optimizing millions of hyperparameters by implicit differentiation
Jonathan Lorraine, Paul Vicol, and David Duvenaud. Optimizing millions of hyperparameters by implicit differentiation. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), pages 1540–1552. PMLR, 2020
2020
-
[31]
Spectral-based graph neural networks for complementary item recommendation
Haitong Luo, Xuying Meng, Suhang Wang, Hanyun Cao, Weiyao Zhang, Yequan Wang, and Yujun Zhang. Spectral-based graph neural networks for complementary item recommendation. InAAAI Conference on Artificial Intelligence (AAAI), volume 38, pages 8868–8876, 2024
2024
-
[32]
Sfr-embedding-mistral: Enhance text retrieval with transfer learning
Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. Sfr-embedding-mistral: Enhance text retrieval with transfer learning. Salesforce AI Research Blog, 2024. URLhttps://www.salesforce.com/blog/sfr-embedding/
2024
-
[33]
Auxiliary learning by implicit differentiation
Aviv Navon, Idan Achituve, Haggai Maron, Gal Chechik, and Ethan Fetaya. Auxiliary learning by implicit differentiation. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[34]
Spectrum-based modality representation fusion graph convolutional network for multimodal recommendation
Rongqing Kenneth Ong and Andy WH Khong. Spectrum-based modality representation fusion graph convolutional network for multimodal recommendation. InACM International Conference on Web Search and Data Mining (WSDM), pages 773–781, 2025
2025
-
[35]
Svd-gcn: A simplified graph convolution paradigm for recommendation
Shaowen Peng, Kazunari Sugiyama, and Tsunenori Mine. Svd-gcn: A simplified graph convolution paradigm for recommendation. InACM International Conference on Information and Knowledge Management (CIKM), pages 1625–1634, 2022
2022
-
[36]
How powerful is graph filtering for recommendation
Shaowen Peng, Xin Liu, Kazunari Sugiyama, and Tsunenori Mine. How powerful is graph filtering for recommendation. InACM International Conference on Knowledge Discovery & Data Mining (KDD), pages 2388–2399, 2024
2024
-
[37]
Polycf: Towards optimal spectral graph filters for collaborative filtering.ACM Transactions on Information Systems, 43(4):1–28, 2025
Yifang Qin, Wei Ju, Yiyang Gu, Ziyue Qiao, Zhiping Xiao, and Ming Zhang. Polycf: Towards optimal spectral graph filters for collaborative filtering.ACM Transactions on Information Systems, 43(4):1–28, 2025
2025
-
[38]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https:// qwenlm.github.io/blog/qwen2.5/
2024
-
[39]
Ahmad Bin Rabiah and Julian McAuley. Gsprec: Temporal-aware graph spectral filtering for recommendation.arXiv preprint arXiv:2505.11552, 2025
-
[40]
Bpr: Bayesian personalized ranking from implicit feedback
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback. InUncertainty in Artificial Intelligence (UAI), 2009. 12
2009
-
[41]
A stochastic approximation method.The Annals of Mathematical Statistics, pages 400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The Annals of Mathematical Statistics, pages 400–407, 1951
1951
-
[42]
How powerful is graph convolution for recommendation? InACM International Conference on Information and Knowledge Management (CIKM), pages 1619–1629, 2021
Yifei Shen, Yongji Wu, Yao Zhang, Caihua Shan, Jun Zhang, B Khaled Letaief, and Dongsheng Li. How powerful is graph convolution for recommendation? InACM International Conference on Information and Knowledge Management (CIKM), pages 1619–1629, 2021
2021
-
[43]
Language representations can be what recommenders need: Findings and potentials
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, and Tat-Seng Chua. Language representations can be what recommenders need: Findings and potentials. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[44]
Kainan Shi, Peilin Zhou, Ge Wang, Han Ding, and Fei Wang. What matters in llm-based feature extractor for recommender? a systematic analysis of prompts, models, and adaptation.arXiv preprint arXiv:2509.14979, 2025
-
[45]
David I Shuman, Sunil K Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains.IEEE Signal Processing Magazine, 30(3):83–98, 2013
2013
-
[46]
Whitening sentence representations for better semantics and faster retrieval
Jianlin Su, Jiarun Cao, Weijie Liu, and Yangyiwen Ou. Whitening sentence representations for better semantics and faster retrieval.arXiv preprint arXiv:2103.15316, 2021
-
[47]
J. Tang, H. Gao, and H. Liu. mTrust: Discerning multi-faceted trust in a connected world. In ACM International Conference on Web Search and Data Mining (WSDM), pages 93–102. ACM, 2012
2012
-
[48]
Towards representation alignment and uniformity in collaborative filtering
Chenyang Wang, Yuanqing Yu, Weizhi Ma, Min Zhang, Chong Chen, Yiqun Liu, and Shaoping Ma. Towards representation alignment and uniformity in collaborative filtering. InACM International Conference on Knowledge Discovery & Data Mining (KDD), pages 1816–1825, 2022
2022
-
[49]
Denoised self-augmented learning for social recommendation
Tianle Wang, Lianghao Xia, and Chao Huang. Denoised self-augmented learning for social recommendation. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2023
2023
-
[50]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 5776–5788, 2020
2020
-
[51]
Neural graph collabo- rative filtering
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. Neural graph collabo- rative filtering. InACM International Conference on Research and Development in Information Retrieval (SIGIR), SIGIR ’19, 2019
2019
-
[52]
Disentangled graph collaborative filtering
Xiang Wang, Hongye Jin, An Zhang, Xiangnan He, Tong Xu, and Tat-Seng Chua. Disentangled graph collaborative filtering. InACM International Conference on Research and Development in Information Retrieval (SIGIR), pages 1001–1010, 2020
2020
-
[53]
How powerful are spectral graph neural networks
Xiyuan Wang and Muhan Zhang. How powerful are spectral graph neural networks. In International Conference on Machine Learning (ICML), pages 23341–23362. PMLR, 2022
2022
-
[54]
Efficient bi-level optimization for recommendation denoising
Zongwei Wang, Min Gao, Wentao Li, Junliang Yu, Linxin Guo, and Hongzhi Yin. Efficient bi-level optimization for recommendation denoising. InACM International Conference on Knowledge Discovery & Data Mining (KDD), pages 2502–2511, 2023
2023
-
[55]
Bi-nas: Towards effective and personalized explanation for recommender systems via bi-level neural architecture search
Longfeng Wu, Yao Zhou, Tong Zeng, Zhimin Peng, Bhanu Pratap Singh Rawat, Lecheng Zheng, Giovanni Seni, and Dawei Zhou. Bi-nas: Towards effective and personalized explanation for recommender systems via bi-level neural architecture search. In2025 IEEE International Conference on Data Mining (ICDM), pages 1642–1651. IEEE, 2025
2025
-
[56]
Afdgcf: Adaptive feature de-correlation graph collaborative filtering for recommendations
Wei Wu, Chao Wang, Dazhong Shen, Chuan Qin, Liyi Chen, and Hui Xiong. Afdgcf: Adaptive feature de-correlation graph collaborative filtering for recommendations. InACM International Conference on Research and Development in Information Retrieval (SIGIR), pages 1242–1252, 2024. 13
2024
-
[57]
Bilevel optimization with lower- level uniform convexity: Theory and algorithm
Yuman Wu, Xiaochuan Gong, Jie Hao, and Mingrui Liu. Bilevel optimization with lower- level uniform convexity: Theory and algorithm. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[58]
Stablegcn: Decoupling and reconciling information propagation for collaborative filtering.IEEE Transactions on Knowledge and Data Engineering (TKDE), 36(6):2659–2670, 2023
Cong Xu, Jun Wang, and Wei Zhang. Stablegcn: Decoupling and reconciling information propagation for collaborative filtering.IEEE Transactions on Knowledge and Data Engineering (TKDE), 36(6):2659–2670, 2023
2023
-
[59]
Stair: Manipulating collaborative and multimodal information for e-commerce recommendation
Cong Xu, Yunhang He, Jun Wang, and Wei Zhang. Stair: Manipulating collaborative and multimodal information for e-commerce recommendation. InAAAI Conference on Artificial Intelligence (AAAI), 2024
2024
-
[60]
Dataset regeneration for sequential recommendation
Mingjia Yin, Hao Wang, Wei Guo, Yong Liu, Suojuan Zhang, Sirui Zhao, Defu Lian, and Enhong Chen. Dataset regeneration for sequential recommendation. InACM International Conference on Knowledge Discovery & Data Mining (KDD), pages 3954–3965, 2024
2024
-
[61]
Mind individual information! principal graph learning for multimedia recommendation
Penghang Yu, Zhiyi Tan, Guanming Lu, and Bing-Kun Bao. Mind individual information! principal graph learning for multimedia recommendation. InAAAI Conference on Artificial Intelligence (AAAI), volume 39, pages 13096–13105, 2025
2025
-
[62]
Jiaming Zhang, Yuyuan Li, Yiqun Xu, Li Zhang, Xiaohua Feng, Zhifei Ren, and Chaochao Chen. Bifair: A fairness-aware training framework for llm-enhanced recommender systems via bi-level optimization.arXiv preprint arXiv:2507.04294, 2025
-
[63]
Mining latent structures for multimedia recommendation
Jinghao Zhang, Yanqiao Zhu, Qiang Liu, Shu Wu, Shuhui Wang, and Liang Wang. Mining latent structures for multimedia recommendation. InACM International Conference on Multimedia (MM), pages 3872–3880, 2021
2021
-
[64]
Dual-view whitening on pre-trained text embeddings for sequential recommendation
Lingzi Zhang, Xin Zhou, Zhiwei Zeng, and Zhiqi Shen. Dual-view whitening on pre-trained text embeddings for sequential recommendation. InAAAI Conference on Artificial Intelligence (AAAI), volume 38, pages 9332–9340, 2024
2024
-
[65]
Are id embeddings necessary? whitening pre-trained text embeddings for effective sequential recommendation
Lingzi Zhang, Xin Zhou, Zhiwei Zeng, and Zhiqi Shen. Are id embeddings necessary? whitening pre-trained text embeddings for effective sequential recommendation. InInternational Conference on Data Engineering (ICDE), pages 530–543. IEEE, 2024
2024
-
[66]
Llminit: A free lunch from large language models for selective initialization of recommendation
Weizhi Zhang, Liangwei Yang, Wooseong Yang, Henry Peng Zou, Yuqing Liu, Ke Xu, Sourav Medya, and Philip S Yu. Llminit: A free lunch from large language models for selective initialization of recommendation. InConference on Empirical Methods in Natural Language Processing (EMNLP), Industry Track, pages 2016–2024, 2025
2016
-
[67]
Spectral collaborative filtering
Lei Zheng, Chun-Ta Lu, Fei Jiang, Jiawei Zhang, and Philip S Yu. Spectral collaborative filtering. InACM Conference on Recommender Systems (RecSys), pages 311–319, 2018
2018
-
[68]
Mmrec: Simplifying multimodal recommendation.arXiv preprint arXiv:2302.03497, 2023
Xin Zhou. Mmrec: Simplifying multimodal recommendation.arXiv preprint arXiv:2302.03497, 2023
-
[69]
A tale of two graphs: Freezing and denoising graph structures for multimodal recommendation
Xin Zhou and Zhiqi Shen. A tale of two graphs: Freezing and denoising graph structures for multimodal recommendation. InACM International Conference on Multimedia (MM), pages 935–943, 2023
2023
-
[70]
Bootstrap latent representations for multi-modal recommendation
Xin Zhou, Hongyu Zhou, Yong Liu, Zhiwei Zeng, Chunyan Miao, Pengwei Wang, Yuan You, and Feijun Jiang. Bootstrap latent representations for multi-modal recommendation. InACM Web Conference (WWW), 2023
2023
-
[71]
Cm 3: Calibrating multimodal recommendation
Xin Zhou, Yongjie Wang, and Zhiqi Shen. Cm 3: Calibrating multimodal recommendation. arXiv preprint arXiv:2508.01226, 2025
-
[72]
(1−p +)∇+ − MX m=1 p− m∇− m # =−E
Zhangchi Zhu and Wei Zhang. Exploring feature-based knowledge distillation for recommender system: A frequency perspective. InACM International Conference on Knowledge Discovery & Data Mining (KDD), 2024. 14 Contents 1 Introduction 1 2 Preliminaries 3 2.1 Graph Collaborative Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2.2 Spectra...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.