Recognition: unknown
GreenDyGNN: Runtime-Adaptive Energy-Efficient Communication for Distributed GNN Training
Pith reviewed 2026-05-08 07:18 UTC · model grok-4.3
The pith
GreenDyGNN adapts cache rebuild windows and per-owner allocations at runtime with a Double-DQN agent to cut energy from remote feature fetches in distributed GNN training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
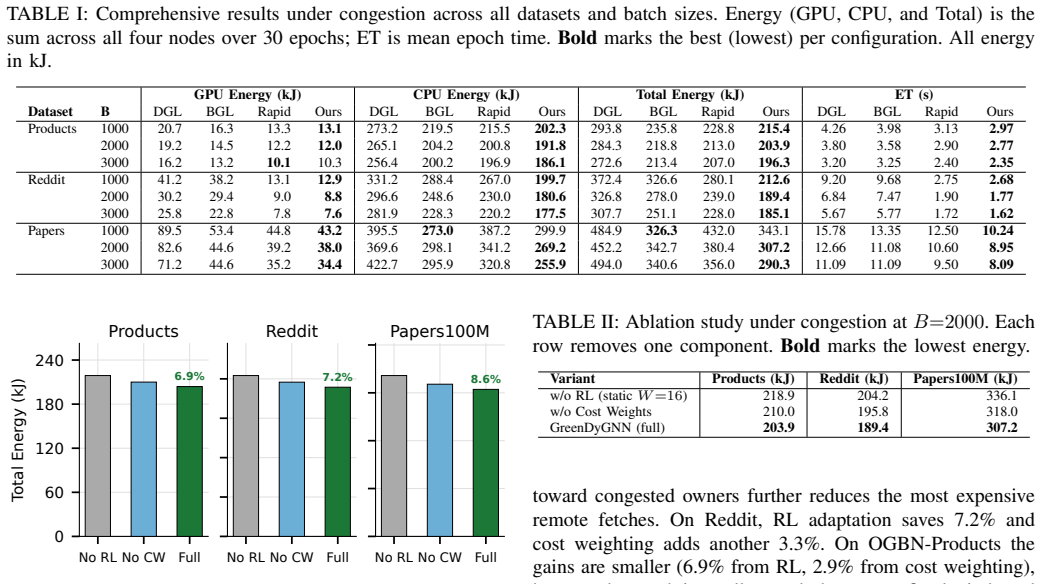
GreenDyGNN formulates cache window management as a sequential decision problem solved by a Double-DQN agent that adapts rebuild window size and per-owner cache allocation at each boundary. An asynchronous double-buffered pipeline makes adaptation effectively free. Under time-varying congestion the method cuts total energy by up to 43 percent compared with default DGL and 4-24 percent compared with the best static policy, while remaining close to optimal when congestion is absent.
What carries the argument
Double-DQN agent trained in a calibrated simulator with domain-randomized congestion that selects rebuild window sizes and cache allocations at partition boundaries to minimize energy from RPC stalls.
If this is right
- Training runs consume less power when network load fluctuates during an epoch.
- Static presampling and caching become less necessary because adaptation handles variation.
- GPU utilization improves because fewer remote fetches stall computation.
- Clusters can run more training jobs per unit of energy when using the adaptive policy.
Where Pith is reading between the lines
- Similar reinforcement-learning controllers could manage other runtime resources such as batch sizes or communication compression in distributed training.
- The approach may generalize to other sampling-based graph workloads beyond GNNs that cross partition boundaries.
- Production clusters could monitor energy directly and fine-tune the reward signal without simulator retraining.
Load-bearing premise
The calibrated simulator with randomized congestion patterns produces policies that transfer to real hardware with only small loss in the energy savings.
What would settle it
Measure total energy and training time on a real multi-GPU cluster while injecting controlled network congestion and compare the observed savings against both the simulated prediction and the best static cache schedule.
Figures








read the original abstract
Distributed GNN training is dominated by remote feature fetching, which can be very costly. Multi-hop neighborhood sampling crosses partition boundaries and triggers fine-grained RPCs whose fixed initiation cost and GPU-stall latency waste energy. Prior systems try to reduce this overhead with presampling and static caching, but cache policies cannot react to runtime network variation. We show that under time-varying congestion, static caching can increase energy by up to 45% because a fixed rebuild schedule is insufficient. We present GreenDyGNN, which formulates cache window management as a sequential decision problem. GreenDyGNN performs intra-epoch cache rebuilds and uses a Double-DQN agent, trained in a calibrated simulator with domain-randomized congestion, to adapt rebuild window size and per-owner cache allocation at each boundary. An asynchronous double-buffered pipeline makes adaptation effectively free. Under congestion, GreenDyGNN cuts total energy by up to 43% over Default DGL and 4-24% over the best static policy, while closely matching the optimum under clean conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GreenDyGNN, a system for distributed GNN training that formulates cache window management as a sequential decision problem solved by a Double-DQN agent. The agent is trained in a calibrated simulator with domain-randomized congestion to dynamically adapt intra-epoch cache rebuild windows and per-owner allocations; an asynchronous double-buffered pipeline is used to make adaptation overhead negligible. The central claims are that static policies can increase energy by up to 45% under time-varying congestion, while GreenDyGNN reduces total energy by up to 43% versus Default DGL and 4-24% versus the best static policy under congestion, while matching the optimum under clean conditions.
Significance. If the simulator fidelity and policy transfer claims hold, the work would offer a practical runtime-adaptive approach to energy-efficient communication in distributed GNN training, addressing a gap where static caching fails under network variation. The use of RL with domain randomization and the double-buffered pipeline are technically interesting contributions that could influence future systems for large-scale graph workloads.
major comments (2)
- [Abstract and Evaluation (simulator-trained policy results)] The headline quantitative claims (up to 43% energy reduction vs. Default DGL and 4-24% vs. best static policy) rest entirely on simulator results; the manuscript provides no hardware traces, no cross-validation of simulator RPC latency/GPU-stall/congestion outputs against measured production traces, and no end-to-end energy numbers from physical clusters, which directly undermines the transferability assertion in the abstract.
- [Simulator calibration and policy transfer discussion] The weakest assumption—that the domain-randomized congestion model produces policies that remain near-optimal on real Ethernet/InfiniBand networks—is load-bearing for all reported savings; without at least one controlled hardware experiment or sensitivity analysis showing policy degradation under model mismatch, the 43% figure cannot be treated as a verified system result.
minor comments (2)
- [Abstract] The abstract states energy savings but supplies no run counts, error bars, or precise baseline definitions; these details should be added to the evaluation section for reproducibility.
- [System design and pipeline description] Clarify the exact definition of 'total energy' (e.g., whether it includes only communication or also GPU compute) and how the asynchronous pipeline overhead is measured and shown to be negligible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the technical interest in the RL-based adaptive approach. We address the two major comments below regarding the simulator-based evaluation and policy transfer assumptions. We will incorporate revisions to strengthen the discussion of limitations and add further analysis.
read point-by-point responses
-
Referee: [Abstract and Evaluation (simulator-trained policy results)] The headline quantitative claims (up to 43% energy reduction vs. Default DGL and 4-24% vs. best static policy) rest entirely on simulator results; the manuscript provides no hardware traces, no cross-validation of simulator RPC latency/GPU-stall/congestion outputs against measured production traces, and no end-to-end energy numbers from physical clusters, which directly undermines the transferability assertion in the abstract.
Authors: We acknowledge that all reported quantitative results, including the energy savings, are obtained from the calibrated simulator rather than physical hardware deployments. The simulator was calibrated using domain randomization over a range of congestion parameters to capture time-varying network behavior, and its latency and stall models were validated against synthetic microbenchmarks. We agree that the absence of hardware traces limits direct claims of transferability to production Ethernet/InfiniBand clusters. In the revised manuscript we will (1) expand the simulator calibration subsection with additional validation metrics, (2) add an explicit limitations paragraph on simulation-to-hardware gaps, and (3) temper the abstract and conclusion to frame the 43% figure as simulator-demonstrated potential rather than a verified hardware result. revision: partial
-
Referee: [Simulator calibration and policy transfer discussion] The weakest assumption—that the domain-randomized congestion model produces policies that remain near-optimal on real Ethernet/InfiniBand networks—is load-bearing for all reported savings; without at least one controlled hardware experiment or sensitivity analysis showing policy degradation under model mismatch, the 43% figure cannot be treated as a verified system result.
Authors: Domain randomization was chosen precisely to encourage robustness across congestion regimes that we expect to appear on real networks. To directly respond to the concern, the revision will include a new sensitivity-analysis subsection that (a) perturbs the congestion model parameters outside the training distribution and (b) quantifies the resulting degradation in policy performance within simulation. We do not have the resources or cluster access to run controlled hardware experiments for this revision cycle; therefore we will also revise the discussion to state that the reported savings are simulator-validated and that hardware transfer remains an open question for future work. revision: partial
- We do not possess production hardware traces or end-to-end physical-cluster energy measurements and therefore cannot add them to the manuscript.
Circularity Check
No significant circularity in GreenDyGNN derivation chain
full rationale
The paper formulates cache-window management as an MDP and trains a Double-DQN policy inside a calibrated simulator with domain-randomized congestion; the reported energy reductions (43 % vs. Default DGL, 4-24 % vs. best static policy) are then obtained by executing that policy and the baselines inside the same simulator. These are straightforward empirical comparisons, not derivations that reduce to the inputs by construction. No self-definitional equations, fitted parameters renamed as predictions, load-bearing self-citations, or uniqueness theorems imported from prior author work appear in the abstract or described method. The central claim therefore remains an independent optimization result whose validity hinges on simulator fidelity rather than logical circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Semi-supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” inProceedings of the 5th International Con- ference on Learning Representations (ICLR), 2017
2017
-
[2]
Inductive representation learning on large graphs,
W. L. Hamilton, R. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” inAdvances in Neural Information Processing Systems 30 (NeurIPS), 2017
2017
-
[3]
DistDGL: Distributed graph neural network training for billion-scale graphs,
D. Zheng, C. Ma, M. Wang, J. Zhou, Q. Su, X. Song, Q. Gan, Z. Zhang, and G. Karypis, “DistDGL: Distributed graph neural network training for billion-scale graphs,” in10th IEEE/ACM Workshop on Irregular Applications: Architectures and Algorithms (IA3), 2020, pp. 36–44, https://doi.org/10.1109/IA351965.2020.00011
-
[4]
P3: Distributed deep graph learning at scale,
S. Gandhi and A. P. Iyer, “P3: Distributed deep graph learning at scale,” in15th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2021, pp. 551–568
2021
-
[5]
Improving the accuracy, scalability, and performance of graph neural networks with Roc,
Z. Jia, S. Lin, M. Gao, M. Zaharia, and A. Aiken, “Improving the accuracy, scalability, and performance of graph neural networks with Roc,”Proceedings of Machine Learning and Systems, vol. 2, pp. 187– 198, 2020
2020
-
[6]
ByteGNN: Efficient graph neural network training at large scale,
C. Zheng, H. Chen, Y . Cheng, Z. Song, Y . Wu, C. Li, J. Cheng, H. Yang, and S. Zhang, “ByteGNN: Efficient graph neural network training at large scale,”Proceedings of the VLDB Endowment, vol. 15, no. 6, pp. 1228–1242, 2022, https://doi.org/10.14778/3514061.3514069
-
[7]
A. Niam, T. Kosar, and M. Nine, “Rapidgnn: Energy and communication-efficient distributed training on large-scale graph neural networks,”arXiv preprint arXiv:2509.05207, 2025
-
[8]
MassiveGNN: Efficient training via prefetching for massively connected distributed graphs,
A. Sarkar, S. Ghosh, N. R. Tallent, and A. Jannesari, “MassiveGNN: Efficient training via prefetching for massively connected distributed graphs,” in2024 IEEE International Conference on Cluster Comput- ing (CLUSTER), 2024, https://doi.org/10.1109/CLUSTER59578.2024. 00013
-
[9]
PaGraph: Scaling GNN training on large graphs via computation-aware caching,
Z. Lin, C. Li, Y . Miao, Y . Liu, and Y . Xu, “PaGraph: Scaling GNN training on large graphs via computation-aware caching,” inProceedings of the 11th ACM Symposium on Cloud Computing (SoCC), 2020, pp. 401–415, https://doi.org/10.1145/3419111.3421281
-
[10]
Communication-efficient graph neural networks with probabilistic neighborhood expansion analysis and caching,
T. Kaler, A.-S. Iliopoulos, P. Murzynowski, T. B. Schardl, C. E. Leiserson, and J. Chen, “Communication-efficient graph neural networks with probabilistic neighborhood expansion analysis and caching,” in Proceedings of Machine Learning and Systems, vol. 5, 2023
2023
-
[11]
BGL: GPU-efficient GNN training by optimizing graph data I/O and preprocessing,
T. Liu, Y . Chen, D. Li, C. Wu, Y . Zhu, J. He, Y . Peng, H. Chen, H. Chen, and C. Guo, “BGL: GPU-efficient GNN training by optimizing graph data I/O and preprocessing,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2023, pp. 103–118
2023
-
[12]
Chameleon: a scalable production testbed for computer sci- ence research,
K. Keahey, P. Riteau, D. Stanzione, T. Cockerill, J. Mambretti, P. Rad, and P. Ruth, “Chameleon: a scalable production testbed for computer sci- ence research,” inContemporary High Performance Computing. CRC Press, 2019, pp. 123–148
2019
-
[13]
PyTorch: An imperative style, high- performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “PyTorch: An imperative style, high- performance deep learning library,” inAdvances in Neural Information Processing S...
2019
-
[14]
BNS-GCN: Efficient full- graph training of graph convolutional networks with partition-parallelism and random boundary node sampling,
C. Wan, Y . Li, A. Li, N. S. Kim, and Y . Lin, “BNS-GCN: Efficient full- graph training of graph convolutional networks with partition-parallelism and random boundary node sampling,”Proceedings of Machine Learn- ing and Systems, vol. 4, pp. 673–693, 2022
2022
-
[15]
GNNLab: A factored system for sample-based GNN training over GPUs,
J. Yang, D. Tang, X. Song, L. Wang, Q. Yin, R. Chen, W. Yu, and J. Zhou, “GNNLab: A factored system for sample-based GNN training over GPUs,” inProceedings of the 17th European Conference on Computer Systems (EuroSys), 2022, pp. 417–434, https://doi.org/10. 1145/3492321.3519557
-
[16]
DUCATI: A dual-cache training system for graph neural networks on giant graphs with the GPU,
X. Zhang, Y . Shen, Y . Shao, and L. Chen, “DUCATI: A dual-cache training system for graph neural networks on giant graphs with the GPU,”Proceedings of the ACM on Management of Data, vol. 1, no. 2, pp. 166:1–166:24, 2023, https://doi.org/10.1145/3589311
-
[17]
DGCL: An efficient communication library for distributed GNN training,
Z. Cai, X. Yan, Y . Wu, K. Ma, J. Cheng, and F. Yu, “DGCL: An efficient communication library for distributed GNN training,” inProceedings of the 16th European Conference on Computer Systems (EuroSys), 2021, pp. 130–144, https://doi.org/10.1145/3447786.3456233
-
[18]
E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy consid- erations for deep learning in NLP,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019, pp. 3645–3650, https://doi.org/10.18653/v1/P19-1355
-
[19]
R. Schwartz, J. Dodge, N. A. Smith, and O. Etzioni, “Green AI,” Communications of the ACM, vol. 63, no. 12, pp. 54–63, 2020, https: //doi.org/10.1145/3381831
-
[20]
So, Maud Texier, and Jeff Dean
D. Patterson, J. Gonzalez, U. Hölzle, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, and M. Texier, “The carbon footprint of machine learning training will plateau, then shrink,”IEEE Computer, vol. 55, no. 7, 2022, https://doi.org/10.1109/MC.2022.3148714
-
[21]
Zeus: Understanding and optimizing GPU energy consumption of DNN training,
J. You, J.-W. Chung, and M. Chowdhury, “Zeus: Understanding and optimizing GPU energy consumption of DNN training,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2023, pp. 119–139
2023
-
[22]
Reducing energy bloat in large model training,
J.-W. Chung, Y . Gu, I. Jang, L. Meng, N. Bansal, and M. Chowdhury, “Reducing energy bloat in large model training,” inACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP), 2024, https://doi. org/10.1145/3694715.3695970
-
[23]
EnvPipe: Performance- preserving DNN training framework for saving energy,
S. Choi, I. Koo, J. Ahn, M. Jeon, and Y . Kwon, “EnvPipe: Performance- preserving DNN training framework for saving energy,” in2023 USENIX Annual Technical Conference (USENIX ATC), 2023, pp. 851–864
2023
-
[24]
H. Mao, R. Netravali, and M. Alizadeh, “Neural adaptive video stream- ing with Pensieve,” inProceedings of the ACM Special Interest Group on Data Communication (SIGCOMM), 2017, https://doi.org/10.1145/ 3098822.3098843
-
[25]
HPCC: high precision congestion control,
H. Mao, M. Schwarzkopf, S. B. Venkatakrishnan, Z. Meng, and M. Al- izadeh, “Learning scheduling algorithms for data processing clusters,” in Proceedings of the ACM Special Interest Group on Data Communication (SIGCOMM), 2019, https://doi.org/10.1145/3341302.3342080
-
[26]
Device placement optimization with reinforcement learning,
A. Mirhoseini, H. Pham, Q. V . Le, B. Steiner, R. Larsen, Y . Zhou, N. Kumar, M. Norouzi, S. Bengio, and J. Dean, “Device placement optimization with reinforcement learning,” inProceedings of the 34th International Conference on Machine Learning (ICML), 2017, pp. 2430– 2439
2017
-
[27]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in2017 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS), 2017, pp. 23–30, https://doi.org/10.1109/IROS.2017.8202133
-
[28]
Learning dexterous in-hand manipulation,
OpenAI, M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba, “Learning dexterous in-hand manipulation,”The International Journal of Robotics Research, vol. 39, no. 1, pp. 3–20, 2020, https://doi.org/10. 1177/0278364919887447
2020
-
[29]
A fast and high quality multilevel scheme for partitioning irregular graphs,
G. Karypis and V . Kumar, “A fast and high quality multilevel scheme for partitioning irregular graphs,”SIAM Journal on Scientific Com- puting, vol. 20, no. 1, pp. 359–392, 1998, https://doi.org/10.1137/ S1064827595287997
1998
-
[30]
H. van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double Q-learning,” inProceedings of the 30th AAAI Conference on Artificial Intelligence (AAAI), 2016, pp. 2094–2100, https://doi.org/ 10.1609/aaai.v30i1.10295
-
[31]
Deep graph library: A graph-centric, highly-performant package for graph neural networks,
M. Wang, D. Zheng, Z. Ye, Q. Gan, M. Li, X. Song, J. Zhou, C. Ma, L. Yu, Y . Gai, T. Xiao, T. He, G. Karypis, J. Li, and Z. Zhang, “Deep graph library: A graph-centric, highly-performant package for graph neural networks,”arXiv preprint arXiv:1909.01315, 2019
-
[32]
Anthropic, “Claude,” https://www.anthropic.com/claude, 2024, aI assis- tant used for grammar and readability improvements
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.