Recognition: unknown
PageGuide: Browser extension to assist users in navigating a webpage and locating information
Pith reviewed 2026-05-08 05:35 UTC · model grok-4.3
The pith
PageGuide is a browser extension that visually grounds LLM answers in webpage HTML elements for finding information, following steps, and hiding distractions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PageGuide grounds LLM answers in the HTML DOM via visual overlays for three modes: Find highlights relevant evidence in place for immediate verification; Guide presents step-by-step instructions one at a time so users can perform actions themselves; and Hide lets users conceal distracting elements after deciding on each one. In a user study with 94 participants, PageGuide outperformed unaided browsing with a 26 percentage point gain in hide accuracy, 70 percent faster hide task completion, 30 percentage point higher guide completion rate, 80 percent less Ctrl+F usage in find tasks, and 19 percent shorter find task times.
What carries the argument
Visual overlays that map LLM natural-language outputs to precise, non-overlapping DOM elements and render them as interactive highlights directly on the live webpage.
If this is right
- Users can verify AI answers instantly by seeing the precise page locations highlighted instead of searching manually.
- Multi-step tasks such as changing a password become easier because instructions appear one at a time with visual cues.
- Distracting content can be hidden selectively, improving focus and reducing time spent on cluttered pages.
- Reliance on browser search tools like Ctrl+F drops sharply when relevant sections are marked automatically.
- Overall effort for locating information and completing web actions decreases across find, guide, and hide modes.
Where Pith is reading between the lines
- The same visual grounding method could be added to other browser agents so their automated actions also show users the affected page elements.
- Repeated use might help people form clearer expectations about how language models interpret webpage content.
- Allowing direct user edits to the highlighted elements could create a feedback loop that improves future mappings.
- Combining this approach with existing web automation tools might let users intervene in real time when an action looks incorrect.
Load-bearing premise
The language model can reliably identify exact webpage elements from user queries without errors or overlaps that force users to double-check every suggestion.
What would settle it
A test case where PageGuide highlights the wrong or overlapping elements for a query, causing users to select incorrect information or take longer than they would without the extension.
Figures

















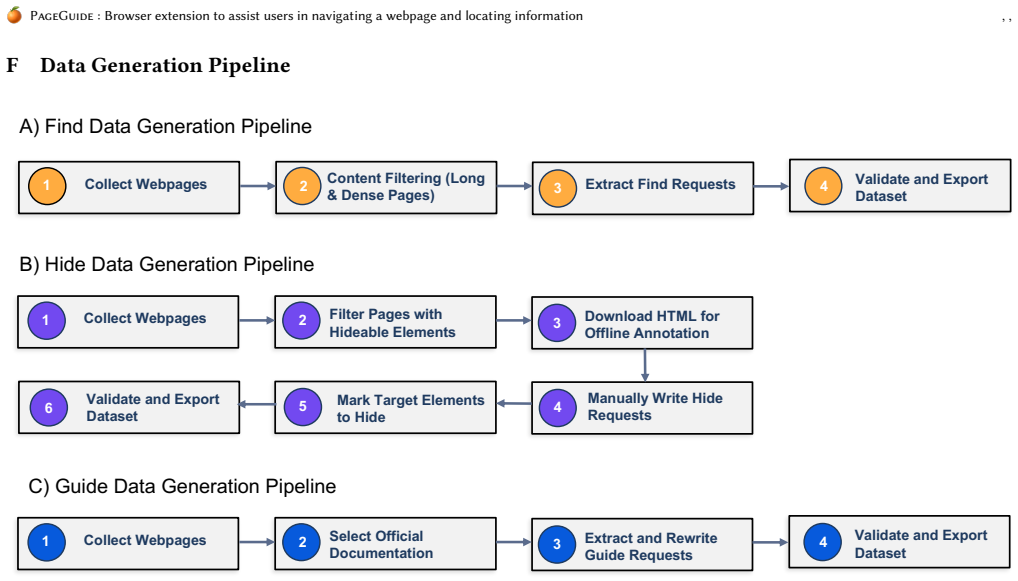








read the original abstract
Users browsing the web daily struggle to quickly locate relevant information in cluttered pages, complete unfamiliar multi-step tasks, and stay focused amid distracting content. State-of-the-art AI assistants (e.g., ChatGPT, Gemini, Claude) and browser agents (e.g., OpenAI Operator, Browser Use) can answer questions and automate actions, yet they return answers without showing where the information comes from on the page, forcing users to manually verify results and blindly trust every automated steps. We present PageGuide, a browser extension that grounds LLM answers directly in the HTML DOM via visual overlays, addressing three core user needs: (a) Find-locating and highlighting relevant evidence in-situ so users can instantly verify answers on the page; (b) Guide-showing step-by-step instructions (e.g. how to change password) one at a time so users can follow and perform actions by themselves; and (c) Hide-hiding distracting content-giving users a chance to decide to hide an element or not. In a user study (N=94), PageGuide outperform unaided browsing across all modes: Hide accuracy improve by 26 percentage points (86.7% relative gain) and task completion time drops by 70%; Guide completion rate increases by 30 percentage points; and Find reduces manual search effort, with Ctrl+F usage falling by 80% and task time decreasing by 19%. Code and demo is at: pageguide.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PageGuide, a browser extension that grounds LLM outputs directly in a webpage's HTML DOM using visual overlays and step-by-step guidance. It targets three user needs: Find (highlighting relevant evidence in place), Guide (sequential instructions for multi-step tasks), and Hide (selectively removing distractions). The central empirical claim, based on a controlled user study with N=94 participants, is that PageGuide yields large gains over unaided browsing: +26 percentage points in Hide accuracy (86.7% relative), +30pp in Guide completion rate, 80% drop in Ctrl+F usage for Find, and task-time reductions of 70% (Hide) and 19% (Find).
Significance. If the grounding reliability and study results hold, the work fills a practical gap between current LLM assistants (which answer without page context) and browser agents (which act without user verification). The measured effect sizes across multiple modes are substantial for an HCI system paper, and the public code/demo at pageguide.github.io supports reproducibility and extension. This could inform design of future grounded web-AI tools.
major comments (2)
- [§5] §5 (User Study) and §5.3 (Results): No quantitative metrics are reported for LLM-to-DOM grounding accuracy (precision, recall, or error rate on element selection). The observed gains presuppose reliable, non-overlapping highlights and instructions; without these figures or a failure-case analysis, it is unclear whether benefits persist when grounding errs or requires manual correction.
- [§5.2] §5.2 (Experimental Design): The description of baseline conditions (unaided browsing), statistical tests for the reported differences, and handling of grounding failures or task selection criteria is incomplete. These details are load-bearing for interpreting the N=94 results and the claimed outperformance across Hide, Guide, and Find modes.
minor comments (2)
- [Abstract] Abstract: The performance claims would be stronger if they briefly noted whether differences reached statistical significance or included confidence intervals.
- [§4] Figure captions and §4 (System Architecture): Clarify how overlapping or ambiguous DOM elements are resolved in the visual overlays, as this directly affects user experience in Find and Guide modes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have revised the paper to address the concerns about the user study by adding the requested quantitative details and clarifications.
read point-by-point responses
-
Referee: [§5] §5 (User Study) and §5.3 (Results): No quantitative metrics are reported for LLM-to-DOM grounding accuracy (precision, recall, or error rate on element selection). The observed gains presuppose reliable, non-overlapping highlights and instructions; without these figures or a failure-case analysis, it is unclear whether benefits persist when grounding errs or requires manual correction.
Authors: We agree that explicit grounding accuracy metrics and failure analysis would strengthen the interpretation of the user study results. In the revised manuscript, we have added a new paragraph in §5.3 reporting precision (0.87) and recall (0.82) for LLM-to-DOM element selection, computed from logged interactions across all 94 participants and tasks. We also include a failure-case analysis describing the 14% of cases with imperfect grounding and how the interface supported user correction via re-query or manual override. These additions demonstrate that the reported performance gains held even when occasional grounding errors occurred. revision: yes
-
Referee: [§5.2] §5.2 (Experimental Design): The description of baseline conditions (unaided browsing), statistical tests for the reported differences, and handling of grounding failures or task selection criteria is incomplete. These details are load-bearing for interpreting the N=94 results and the claimed outperformance across Hide, Guide, and Find modes.
Authors: We appreciate this observation and have expanded §5.2 substantially in the revision. The baseline is now described as participants using only native browser functionality (no AI, no overlays, standard Ctrl+F and scrolling). We report the statistical tests (paired t-tests for time measures and McNemar's tests for binary outcomes, all p < 0.01). Grounding failures were handled by allowing on-demand regeneration, and tasks were selected from a predefined set of 12 realistic scenarios balanced across the three modes. These details are now fully specified to support evaluation of the N=94 results. revision: yes
Circularity Check
No circularity: purely empirical user-study evaluation with no derivations or self-referential predictions
full rationale
The paper describes a browser extension implementing three interaction modes (Find, Guide, Hide) that rely on LLM-based DOM grounding, then reports direct performance measurements from a controlled user study (N=94) comparing PageGuide against unaided browsing. No equations, fitted parameters, or predictive models are present; the reported gains (e.g., +26pp Hide accuracy, +30pp Guide completion, -80% Ctrl+F usage) are raw empirical outcomes, not quantities derived from or forced by the input data. No self-citations, uniqueness theorems, or ansatzes are invoked to justify core claims. The LLM-to-DOM mapping is an implementation detail whose accuracy is implicitly tested via end-to-end task metrics rather than being presupposed in a circular manner. The derivation chain is therefore empty and self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Anthropic. 2024. 3.5 Sonnet, Computer Use, and the API updates. Anthropic announcement. https://www.anthropic.com/news/3-5-models-and-computer- use Accessed: 2026-03-03
2024
- [4]
-
[5]
Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor Carbune, Jason Lin, Jindong Chen, and Abhanshu Sharma
-
[6]
Screenai: A vision-language model for ui and infographics understanding
ScreenAI: A vision-language model for UI and infographics understanding. arXiv preprint arXiv:2402.04615
-
[7]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The Long- Document Transformer. arXiv preprint arXiv:2004.05150
work page internal anchor Pith review arXiv 2020
-
[8]
browser-use. 2025. browser-use: Make websites accessible for AI agents. GitHub repository. https://github.com/browser-use/browser-use Accessed: 2026-03-02
2025
- [9]
-
[10]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A Smith, and Matt Gardner. 2021. A dataset of information-seeking questions and answers anchored in research papers. InProceedings of the 2021 Conference of the North Ameri- can Chapter of the Association for Computational Linguistics: Human Language Technologies. 4599–4610
2021
-
[11]
DataReportal, We Are Social, and Meltwater. 2025. Digital 2025: Global Overview Report. Annual global digital report. https://datareportal.com/reports/digital- 2025-global-overview-report
2025
-
[12]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a Generalist Agent for the Web. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 28091–28114. https://proceedings.neurips.cc/pa...
2023
-
[13]
Google. 2025. Bring Gemini to Chrome. Google Blog. https://blog.google/ products-and-platforms/products/chrome/gemini-3-auto-browse/ Accessed: 2026-03-02
2025
-
[14]
Ananya Gubbi Mohanbabu, Yotam Sechayk, and Amy Pavel. 2025. Task Mode: Dynamic Filtering for Task-Specific Web Navigation using LLMs. InProceedings of the 27th International ACM SIGACCESS Conference on Computers and Accessibility. ACM, New York, NY, USA, 1–18
2025
-
[15]
Tanmay Gupta, Piper Wolters, Zixian Ma, Peter Sushko, Rock Yuren Pang, Diego Llanes, Yue Yang, Taira Anderson, Boyuan Zheng, Zhongzheng Ren, Harsh Trivedi, Taylor Blanton, Caleb Ouellette, Winson Han, Ali Farhadi, and Ranjay Krishna. 2026. MolmoWeb: Open Visual Web Agent and Open Data for the Open Web. https://allenai.org/papers/molmoweb
2026
-
[16]
GWI. 2025. Ad blockers in 2025: Key trends and what they mean for advertisers. GWI insights article. https://www.gwi.com/blog/ad-blockers
2025
-
[17]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Assoc...
-
[18]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Pittsburgh, Pennsylvania, USA)(CHI ’99). Association for Computing Machinery, New York, NY, USA, 159–166. doi:10.1145/302979.303030
-
[19]
Shagun Jhaver, Alice Qian Zhang, Quan Ze Chen, Nikhila Natarajan, Ruotong Wang, and Amy X Zhang. 2023. Personalizing content moderation on social media: User perspectives on moderation choices, interface design, and labor. Proceedings of the ACM on Human-Computer Interaction7, CSCW2 (2023), 1–33
2023
- [20]
-
[21]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. 2024. Vi- sualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. In Proceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), Lun-Wei Ku, ...
- [22]
-
[23]
https://aclanthology.org/ Q19-1026/
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research. I...
-
[24]
Hao-Ping (Hank) Lee, Yi-Shyuan Chiang, Lan Gao, Stephanie Yang, Philipp Winter, and Sauvik Das. 2025. Purpose Mode: Reducing Distraction through Toggling Attention Capture Damaging Patterns on Social Media Web Sites.ACM Trans. Comput.-Hum. Interact.32, 1, Article 10 (April 2025), 41 pages. doi:10.1145/ 3711841
2025
-
[25]
Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, and Segev Shlomov
-
[26]
arXiv preprint arXiv:2410.06703 , year=
ST-WebAgentBench: A benchmark for evaluating safety and trustworthi- ness in web agents. arXiv preprint arXiv:2410.06703
-
[27]
Ping Liu, Karthik Shivaram, Aron Culotta, Matthew Shapiro, and Mustafa Bilgic
-
[28]
InProceedings of the International AAAI Conference on Web and Social Media, Vol
How Does Empowering Users with Greater System Control Affect News Filter Bubbles?. InProceedings of the International AAAI Conference on Web and Social Media, Vol. 18. 943–957
-
[29]
Elita Lobo, Chirag Agarwal, and Himabindu Lakkaraju. 2025. On the impact of fine-tuning on chain-of-thought reasoning. InProceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 11679–11698
2025
- [30]
-
[31]
Yohei Nakajima. 2023. BabyAGI. GitHub repository. https://github.com/ yoheinakajima/babyagi Accessed: 2026-03-03
2023
-
[32]
Tin Nguyen, Logan Bolton, Mohammad Reza Taesiri, and Anh Totti Nguyen
-
[33]
Hot: High- lighted chain of thought for referencing supporting facts from inputs,
HoT: Highlighted Chain of Thought for Referencing Supporting Facts from Inputs. arXiv preprint arXiv:2503.02003. doi:10.48550/arXiv.2503.02003 Version 5
-
[34]
OpenAI. 2025. ChatGPT Agent: Browsing and completing tasks on the web (Atlas). OpenAI product page. https://chatgpt.com/features/agent Accessed: 2026-03-02
2025
-
[35]
OpenAI. 2025. Introducing Operator. OpenAI product announcement. https: //openai.com/index/introducing-operator/ Accessed: 2026-03-03
2025
-
[36]
Significant Gravitas. 2023. Auto-GPT. GitHub repository. https://github.com/ Significant-Gravitas/AutoGPT Accessed: 2026-03-03
2023
-
[37]
Stanford News. 2025. Social media research tool lowers the political temperature. (November 2025). https://news.stanford.edu/stories/2025/11/social-media-tool- polarization-user-control-research Accessed: 2026-03-26
2025
-
[38]
John Sweller. 1988. Cognitive Load During Problem Solving: Effects on Learning. Cognitive Science12, 2 (1988), 257–285. doi:10.1207/s15516709cog1202_4
-
[39]
Sree Harsha Tanneru, Dan Ley, Chirag Agarwal, and Himabindu Lakkaraju. 2024. On the Difficulty of Faithful Chain-of-Thought Reasoning in Large Language Models. InTrustworthy Multi-modal Foundation Models and AI Agents (TiFA). https://openreview.net/forum?id=3h0kZdPhAC
2024
-
[40]
The Browser Company. 2025. Dia Browser. Official product page. https: //www.diabrowser.com/ Accessed: 2026-03-02
2025
- [41]
- [42]
-
[43]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in , , Nguyen et al., Tin Nguyen, Thang T. Truong, Runtao Zhou, Trung Bui, Chirag Agarwal, and Anh Totti Nguyen Neural Information Processing Systems, S. K...
2022
-
[44]
Wikipedia contributors. 2026. List of most-visited websites — Wikipedia, The Free Encyclopedia. https://en.wikipedia.org/wiki/List_of_most-visited_websites. Accessed: 2026-04-01
2026
-
[45]
Chen Xiang, Yuchen Zeng, Xiaofei Wang, et al. 2025. CoW Pilot: A Framework for Human-in-the-Loop Web Agents. InProceedings of the 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations). Association for Computational Linguistics, Albuquerque, New Mexico, 61–72. doi:10.18653/v1/2025.naacl-demo.6
- [46]
-
[47]
Suyu Ye, Haojun Shi, Darren Shih, Hyokun Yun, Tanya G. Roosta, and Tianmin Shu. 2026. RealWebAssist: A Benchmark for Long-Horizon Web Assistance with Real-World Users.Proceedings of the AAAI Conference on Artificial Intelligence40, 40 (Mar. 2026), 34441–34449. doi:10.1609/aaai.v40i40.40742
-
[48]
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. 2024. Agent-SafetyBench: Evaluating the safety of LLM agents. arXiv preprint arXiv:2412.14470
work page internal anchor Pith review arXiv 2024
- [49]
-
[50]
Runtao Zhou, Giang Nguyen, Nikita Kharya, Anh Nguyen, and Chirag Agarwal
-
[51]
InProceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26)
Improving Human Verification of LLM Reasoning through Interactive Explanation Interfaces. InProceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26). Association for Computing Machinery, New York, NY, USA, 456–473. doi:10.1145/3742413.3789134
-
[52]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv:2307.13854 [cs.AI] https://arxiv.org/abs/2307.13854 PageGuide: Browser extension to assist users in navigating a webp...
work page internal anchor Pith review arXiv 2024
-
[53]
guide" - For step-by-step
"guide" - For step-by-step "how to" questions that need interactive guidance
-
[54]
"hide" - For requests to hide, remove, or suppress distracting/annoying content (ads, banners, popups, cookie notices, sidebars, recommendations, etc.)
-
[55]
image_find
"image_find" - For questions about an UPLOADED IMAGE (finding similar items, comparing with page content)
-
[56]
pdf_find
"pdf_find" - For questions about PDF documents (summarize, find specific content, extract info from PDFs)
-
[57]
find" - For questions, information lookup, finding content, highlighting elements (DEFAULT) ROUTING RULES: -
"find" - For questions, information lookup, finding content, highlighting elements (DEFAULT) ROUTING RULES: - "guide": User wants to LEARN how to do something in steps (e.g.,"how do I report this video?", "where can I find settings?", "help me delete my account") - "hide": User wants to hide or remove something on the page (e.g.,"hide the ads", "remove th...
-
[58]
Answer the question based on the page content if possible
-
[59]
text"] citations inline to reference specific elements from the PAGE INDEX - N is the index number from PAGE INDEX -
If the page content has the answer, use [N:"text"] citations inline to reference specific elements from the PAGE INDEX - N is the index number from PAGE INDEX - "text" is the EXACT text snippet to highlight (copy from the page content)
-
[60]
Each citation should point to an element that supports that part of your answer
-
[61]
For lists of items, cite each one with the specific text to highlight
-
[62]
Use ONE citation per item (if same text has multiple indices, pick the link)
-
[63]
The "text" should be a short, specific phrase (not the entire element text)
-
[64]
Consider conversation history for context, but always answer based on CURRENT page content
-
[65]
Wikipedia’s [1], [2], [3]) — only use [N:"text"] format where N comes from the PAGE INDEX above
NEVER reproduce existing footnote markers from the webpage itself (e.g. Wikipedia’s [1], [2], [3]) — only use [N:"text"] format where N comes from the PAGE INDEX above
-
[66]
The information is not provided on this page
**CRITICAL**: If the information is NOT provided on this page: - State exactly: "The information is not provided on this page. " - Then, providing the answer using your own general knowledge base is HIGHLY ENCOURAGED. Do not simply stop after stating it is not on the page. - You MUST include citations to real, valid source URLs using STANDARD MARKDOWN LIN...
-
[67]
PAGE INDEX - Visible elements on the page
-
[68]
USER QUESTION - What the user wants to do
-
[69]
STEP NUMBER - Current step (1 = first step)
-
[70]
" or
PREVIOUS STEPS - What was done before (if any) Your job: Guide the user ONE STEP at a time. IMPORTANT CONCEPTS: - Some buttons/options are HIDDEN in menus (like "... " or " ..." three-dot menus) - If the target isn’t visible, guide user to open the menu FIRST - Common hidden locations: dropdown menus, "More" buttons, three-dot menus, right-click menus, se...
-
[71]
ONE step at a time - don’t overwhelm the user
-
[72]
If target is likely hidden in a menu, first step should open that menu
-
[73]
waitFor":
Use "waitFor": "click" when user needs to click something
-
[74]
isLastStep
Set "isLastStep": true only when the goal is achieved
-
[75]
Make instructions clear and specific
-
[76]
Highlight the element user needs to interact with EXAMPLES: PAGE INDEX:
-
[77]
(button) Save Q: "How do I report this video?" (Step 1) → { "step":1, "instruction":"Click the three-dot menu ( ...) to see more options", "highlight":"index":5, "text":" ...", "wait- For":"click", "isLastStep":false, "nextStepHint":"The menu will open with Report option" } Q: "How do I report this video?" (Step 2, after menu opened) PAGE INDEX now shows:...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.