On the Generalization Properties of Selective State-Space Models for Filtering Tasks for Unknown Systems
Pith reviewed 2026-05-08 05:19 UTC · model grok-4.3
The pith
Selective state-space models generalize to filter and predict outputs from unknown systems drawn from a trained class, supported by derived bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under appropriate assumptions, selective state-space models trained on trajectory samples from a set of systems generalize to perform online output prediction for an unknown system from the same set, as established by the derived generalization bounds.
What carries the argument
Generalization bounds for selective state-space models in the in-context filtering setting for unknown dynamical systems.
If this is right
- SSMs can be trained once on a family of systems and then deployed for online filtering of new members without explicit parameter identification.
- The bounds imply that prediction accuracy improves when training trajectories cover more of the system class.
- Structured SSMs may replace attention-based models for filtering tasks where linear scaling with sequence length is required.
- Empirical demonstrations confirm that the theoretical guarantees align with observed performance on concrete examples.
Where Pith is reading between the lines
- Similar bounds could be derived when the test system lies slightly outside the convex hull of the training distribution, testing robustness of the in-context mechanism.
- The comparison between SSMs and transformers could be sharpened by measuring sample complexity needed to reach a target filtering error on the same system class.
- The framework might be extended to derive bounds for tasks that combine filtering with control inputs generated by the model itself.
Load-bearing premise
The appropriate assumptions on the system family, model structure, and data distribution that make the generalization bounds hold.
What would settle it
An experiment in which the online prediction error for a new system stays above the rate guaranteed by the bound even after the number of training trajectories from the system class is increased.
Figures
read the original abstract
Selective State-Space Models (SSMs) such as Mamba have emerged as an alternative architecture to self-attention based transformers in sequence modeling tasks. Recent works have demonstrated the use of transformers in some filtering and output prediction tasks via in-context learning. In this paper, we analyze whether structured SSMs can work equally well for filtering of unknown systems. In particular, we train the SSM on trajectory samples from a set of systems. At run-time, the SSM is given the outputs of an unknown system from the same set and is expected to predict the next output online. Theoretically, under appropriate assumptions, we derive generalization bounds as to why SSMs succeed in such tasks. Empirically, we demonstrate the performance via several numerical examples. We also discuss the advantages and disadvantages of SSMs versus transformers for this task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that selective state-space models (SSMs) can perform online output prediction and filtering for unknown systems drawn from a fixed class by training on trajectory samples. Under assumptions of stable LTI systems with bounded parameters and Lipschitz dynamics, with the SSM trained near-optimally and the selective mechanism preserving contraction, generalization bounds are derived via a covering-number argument on the induced function class. Numerical examples demonstrate performance, and advantages/disadvantages versus transformers are discussed.
Significance. If the bounds hold, the work supplies a rigorous, non-circular explanation for SSM success in filtering tasks on unknown dynamical systems, using standard covering-number techniques and explicit assumptions. This strengthens the case for SSMs as efficient alternatives to transformers in systems applications, with the numerical examples providing concrete empirical support.
minor comments (3)
- [Abstract] The abstract refers to 'appropriate assumptions' without enumeration; while the theory section states them explicitly (stable LTI, bounded parameters, Lipschitz, near-optimal training, contraction preservation), a one-sentence summary in the abstract would aid readers.
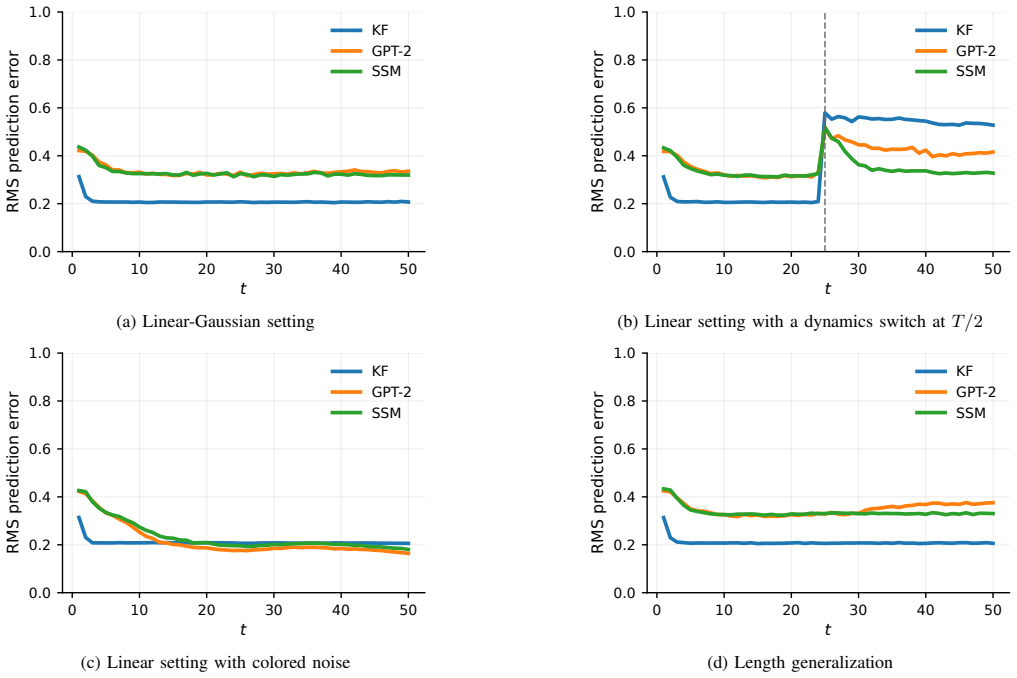
- [Numerical examples] In the numerical examples section, the performance plots lack error bars or multiple random seeds; reporting variability would strengthen the empirical claims of generalization.
- [Discussion] The discussion of SSM vs. transformer advantages would benefit from a brief complexity table (e.g., inference cost per step) to make the comparison more quantitative.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work on the generalization properties of selective state-space models for filtering unknown systems. The summary accurately captures the main contributions, including the derivation of bounds under stability and Lipschitz assumptions, the covering-number argument, and the empirical demonstrations. We appreciate the recognition of the potential implications for SSMs versus transformers in systems applications. As no specific major comments were provided in the report, we have no points to rebut or revise at this stage, though we will carefully incorporate any minor suggestions during the revision process.
Circularity Check
No significant circularity in generalization bound derivation
full rationale
The paper derives generalization bounds for selective SSMs on filtering tasks for unknown LTI systems via a standard covering-number argument applied to the function class induced by the SSM recurrence. This proceeds from explicitly stated assumptions (stable systems with bounded parameters, Lipschitz dynamics, near-optimal training on sufficient trajectories, and preservation of contraction properties by the selective mechanism) without any reduction of the bounds to fitted quantities, self-definitions, or load-bearing self-citations by construction. The central theoretical claim retains independent content from the proof technique and external statistical learning tools.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A new approach to recursive filtering and prediction problems,
R. E. Kalman, “A new approach to recursive filtering and prediction problems,”Trans. of the ASME, vol. 82, no. 1, pp. 35–45, 1960
1960
-
[2]
B. D. Anderson and J. B. Moore,Optimal Filtering. Courier Corporation, 2012
2012
-
[3]
Nonlinear filtering: Interacting particle resolution,
P. del Moral, “Nonlinear filtering: Interacting particle resolution,” Comptes Rendus de l’Acad ´emie des Sciences — Series I — Mathe- matics, vol. 325, no. 6, pp. 653–658, 1997
1997
-
[4]
From system models to class models: An in-context learning paradigm,
M. Forgione, F. Pura, and D. Piga, “From system models to class models: An in-context learning paradigm,”IEEE Control Systems Letters, vol. 7, pp. 3513–3518, 2023
2023
-
[5]
Transformers as implicit state estimators: In-context learning in dynamical systems,
U. Akram and H. Vikalo, “Transformers as implicit state estimators: In-context learning in dynamical systems,” 2026. [Online]. Available: https://arxiv.org/abs/2410.16546
-
[6]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,”31st Int’l Conf. on Neural Information Processing Systems, p. 6000–6010, 2017
2017
-
[7]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[8]
Can transformers learn optimal filtering for unknown systems?
Z. Du, H. Balim, S. Oymak, and N. Ozay, “Can transformers learn optimal filtering for unknown systems?”IEEE Control Systems Letters, vol. 7, pp. 3525–3530, 2023
2023
-
[9]
State space models as foundation models: A control theoretic overview,
C. A. Alonso, J. Sieber, and M. Zeilinger, “State space models as foundation models: A control theoretic overview,”American Control Conference, pp. 146–153, 2025
2025
-
[10]
Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Linear-time sequence modeling with selective state spaces,”1st Conf. on Language Modelling, 2024
2024
-
[11]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long-document transformer,” 2020, preprint. [Online]. Available: https://doi.org/10.48550/arXiv.2004.05150
work page internal anchor Pith review doi:10.48550/arxiv.2004.05150 2020
-
[12]
Transformers as algorithms: Generalization and stability in in-context learning,
Y . Li, M. E. Ildiz, D. Papailiopoulos, and S. Oymak, “Transformers as algorithms: Generalization and stability in in-context learning,”40th Int’l Conf. on Machine Learning, no. 809, 2023
2023
-
[13]
Z. Liu, H. Walker, and R. Jain, “Model-free neural state estimation in nonlinear dynamical systems: Comparing neural and classical filters,” 2026, preprint. [Online]. Available: https: //doi.org/10.48550/arXiv.2601.21266
work page internal anchor Pith review doi:10.48550/arxiv.2601.21266 2026
-
[14]
On the parameterization and initialization of diagonal state space models,
A. Gu, K. Goel, A. Gupta, and C. R ´e, “On the parameterization and initialization of diagonal state space models,”Advances in neural information processing systems, vol. 35, pp. 35 971–35 983, 2022
2022
-
[15]
Generaliza- tion error analysis for selective state-space models through the lens of attention,
A. Honarpisheh, M. Bozdag, O. Camps, and M. Sznaier, “Generaliza- tion error analysis for selective state-space models through the lens of attention,”39th Int’l Conf. on Neural Information Processing Systems, 2025
2025
-
[16]
Can mamba learn how to learn? a comparative study on in-context learning tasks,
J. Park, J. Park, Z. Xiong, N. Lee, J. Cho, S. Oymak, K. Lee, and D. Papailiopoulos, “Can mamba learn how to learn? a comparative study on in-context learning tasks,”41st Int’l Conf. on Machine Learning, no. 1612, 2024
2024
-
[17]
Language models are unsuper- vised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsuper- vised multitask learners,”OpenAI Blog, 2019. [Online]. Available: https://cdn.openai.com/better-language-models/language models are unsupervised multitask learners.pdf
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.