Quasi-Monte Carlo with a Hankel random digital net
Pith reviewed 2026-05-08 02:10 UTC · model grok-4.3
The pith
Random Hankel matrices generate digital nets that simplify randomized quasi-Monte Carlo constructions while retaining the convergence rates of fully random nets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Random Hankel matrices can serve as the generating matrices of digital nets in a randomized quasi-Monte Carlo framework; the resulting point sets possess Walsh-coefficient decay sufficient to support the same error bounds previously established for fully random digital nets when paired with either the median-of-means estimator or the greedy worst-case-error selector.
What carries the argument
Random Hankel matrices used as generating matrices of digital nets, which enforce a linear dependence among matrix entries that still permits control of Walsh coefficients and discrepancy.
If this is right
- The number of independent random bits required to randomize a digital net drops from O(s^2 log b) to O(s log b) for s-dimensional nets in base b.
- Both the median-of-means estimator and the greedy batch selector achieve the same asymptotic error bounds as with fully random nets.
- The construction extends immediately to any base b and any number of points that are powers of b.
- Worst-case error can be estimated cheaply from the same batch used for the greedy selector.
Where Pith is reading between the lines
- The reduced randomness budget may allow larger batches or higher-dimensional problems to be treated on the same hardware budget.
- Similar structured-matrix ideas could be tested for other low-discrepancy constructions such as lattice rules.
- The greedy selector offers a practical way to derandomize the method without sacrificing the proven rate.
Load-bearing premise
The Hankel structure must preserve enough of the uniformity properties of fully random digital nets for the Walsh-coefficient bounds and ensuing error estimates to hold without further restrictions on dimension or smoothness.
What would settle it
A counter-example in which the Walsh coefficients of a random Hankel digital net fail to decay at the rate required by the error analysis, or a numerical test in which the observed convergence rate for the proposed design is strictly slower than that of a comparable fully random design.
Figures






read the original abstract
This paper proposes a new randomized design of digital nets in which the generating matrices are chosen to be random Hankel matrices. Compared with previous randomized designs of digital nets, this approach simplifies the construction process and reduces the number of random variables required, while still achieving desirable convergence rates when combined with appropriate estimators. We analyze the properties of the proposed design, derive bounds for Walsh coefficients, and provide error analysis for both the median-of-means estimator and a newly proposed greedy selection estimator, i.e. the selection of the best design from a batch in terms of a worst-case error bound. Numerical experiments validate our theoretical findings and demonstrate the practical performance of the proposed methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a randomized digital net construction for quasi-Monte Carlo integration in which the generating matrices are chosen as random Hankel matrices over GF(2). This is claimed to simplify the randomization process and reduce the number of random variables relative to fully random digital nets, while still delivering desirable convergence rates. The authors derive bounds on the Walsh coefficients of the resulting point sets and provide error analyses for both the median-of-means estimator and a new greedy selection estimator (selecting the design with the smallest worst-case error bound from a batch). Numerical experiments are presented to support the theoretical claims.
Significance. If the Walsh bounds and error analyses hold without hidden dimension-dependent penalties arising from the linear dependencies in Hankel matrices, the construction would offer a practical reduction in randomness while preserving the convergence advantages of randomized digital nets. The introduction of the greedy selection estimator is a potentially useful addition to the toolkit of variance-reduction techniques in QMC. The numerical validation, if detailed, provides concrete evidence of practical performance.
major comments (2)
- [Walsh coefficient bounds] Walsh coefficient bounds section: The derivation must explicitly demonstrate that the enforced row-shift dependencies in random Hankel matrices do not degrade the decay rate of Walsh coefficients (particularly higher-order terms) relative to fully random generating matrices, and that no extra s-dependent factor appears in the final bounds. The skeptic concern that linear dependencies could inflate the worst-case error measure must be directly addressed with a comparison to the standard random digital net case.
- [Error analysis for estimators] Error analysis for the greedy selection estimator: The worst-case error bound used for selection must be shown to be independent of the selection process itself (i.e., no post-selection bias that alters the stated convergence rate), and the analysis should confirm that the overall error remains comparable to the median-of-means estimator without additional assumptions on smoothness or dimension.
minor comments (2)
- [Abstract] The abstract refers to 'desirable convergence rates' without specifying the precise rate (e.g., O(N^{-1+ε}) or similar); this should be stated explicitly for clarity.
- [Introduction] Notation for the Hankel matrix construction and the precise definition of the greedy selection criterion should be introduced earlier to aid readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading of our manuscript and the constructive comments. We address each major comment below and describe the revisions we will make to the next version.
read point-by-point responses
-
Referee: Walsh coefficient bounds section: The derivation must explicitly demonstrate that the enforced row-shift dependencies in random Hankel matrices do not degrade the decay rate of Walsh coefficients (particularly higher-order terms) relative to fully random generating matrices, and that no extra s-dependent factor appears in the final bounds. The skeptic concern that linear dependencies could inflate the worst-case error measure must be directly addressed with a comparison to the standard random digital net case.
Authors: We agree that an explicit comparison is useful for addressing potential concerns about linear dependencies. In the revised manuscript we will add a dedicated remark (or short subsection) immediately after the Walsh coefficient bound derivation. This remark will compare the probability that a random Hankel matrix produces a given Walsh coefficient magnitude with the corresponding probability for a fully random generating matrix. Because the free parameters of the Hankel matrix are still chosen uniformly at random, the tail bounds on the Walsh coefficients remain identical in order; the row-shift structure only correlates a subset of entries but does not increase the dimension-dependent factor in the final estimate. We will also verify that the resulting worst-case error bound carries no additional s-dependent penalty beyond what appears in the classical random digital net literature. revision: yes
-
Referee: Error analysis for the greedy selection estimator: The worst-case error bound used for selection must be shown to be independent of the selection process itself (i.e., no post-selection bias that alters the stated convergence rate), and the analysis should confirm that the overall error remains comparable to the median-of-means estimator without additional assumptions on smoothness or dimension.
Authors: We will clarify this point in the revised error analysis section. The worst-case error bound employed for selection is a deterministic functional of the generating matrices alone and does not depend on the integrand or on any data-dependent quantity. Consequently, the selection step introduces no post-selection bias that would alter the convergence rate derived for a single random Hankel net. We will add a short paragraph showing that the expected error of the greedy estimator is bounded by the same quantity that bounds the median-of-means estimator, up to a constant factor independent of smoothness and dimension. This comparison uses only the assumptions already stated in the manuscript. revision: yes
Circularity Check
No circularity: new Hankel construction analyzed via independent QMC bounds
full rationale
The paper introduces random Hankel generating matrices as a new design for digital nets, then derives Walsh coefficient bounds and error rates for the median-of-means and greedy estimators directly from the matrix structure and standard digital-net discrepancy theory. No step reduces a claimed prediction to a fitted parameter, self-definition, or load-bearing self-citation; the convergence claims rest on explicit mathematical analysis of the Hankel shift property rather than on the result itself. The derivation chain is therefore self-contained against external QMC results.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of digital nets and Walsh coefficients in quasi-Monte Carlo integration
Reference graph
Works this paper leans on
-
[1]
Jan Baldeaux, Josef Dick, Gunther Leobacher, Dirk Nuyens, and Friedrich Pillichshammer. Efficient calcu- lation of the worst-case error and (fast) component-by-component construction of higher order polynomial lattice rules.Numer. Algorithms, 59(3):403–431, 2012
work page 2012
-
[2]
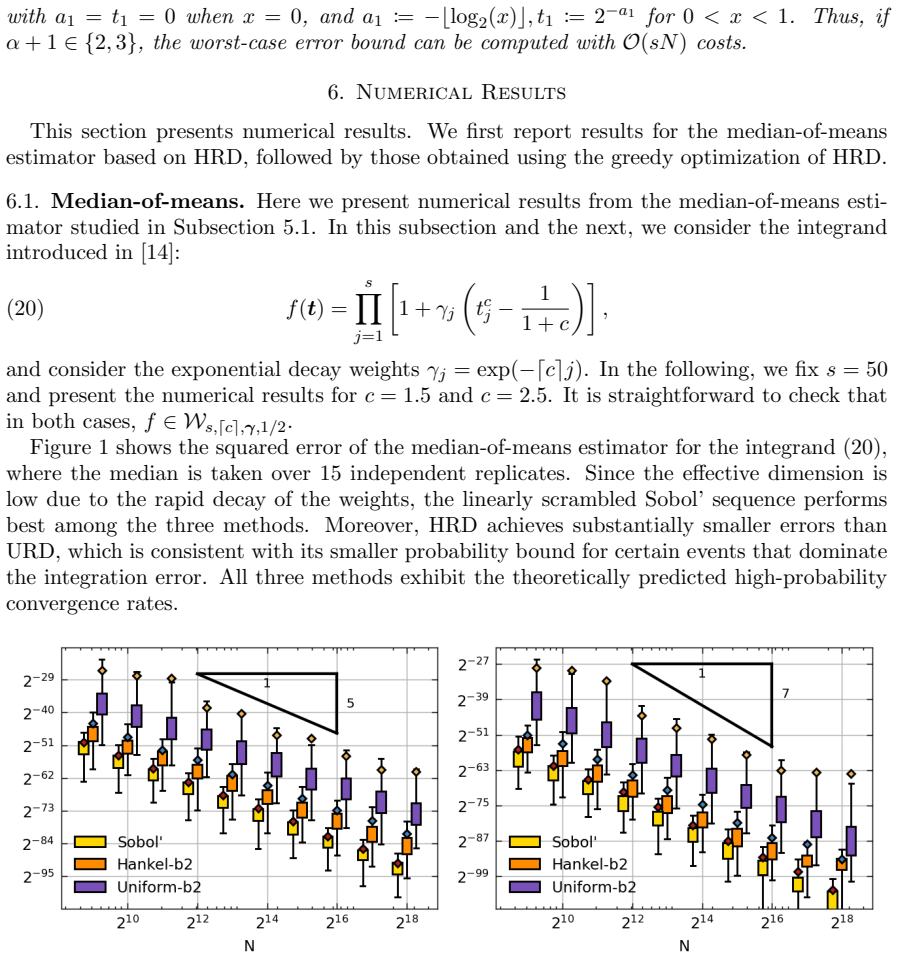
K. L. Chung and P. Erd¨ os. On the application of the Borel-Cantelli lemma.Trans. Amer. Math. Soc., 72:179–186, 1952. 32 (a)Mean, exponential weight (b)Median, exponential weight (c)Mean, equal weight (d)Median, equal weight Figure 5.Comparison between LMS+Sobol’ sequence and the optimized HRD forc= 2.5 with exponential weight. Results are shown for both ...
work page 1952
-
[3]
Walsh spaces containing smooth functions and quasi-Monte Carlo rules of arbitrary high order
Josef Dick. Walsh spaces containing smooth functions and quasi-Monte Carlo rules of arbitrary high order. SIAM J. Numer. Anal., 46(3):1519–1553, 2008
work page 2008
-
[4]
Josef Dick. Higher order scrambled digital nets achieve the optimal rate of the root mean square error for smooth integrands.Ann. Statist., 39(3):1372–1398, 2011
work page 2011
-
[5]
Josef Dick, Frances Y. Kuo, Quoc T. Le Gia, Dirk Nuyens, and Christoph Schwab. Higher order QMC Petrov-Galerkin discretization for affine parametric operator equations with random field inputs.SIAM J. Numer. Anal., 52(6):2676–2702, 2014
work page 2014
-
[6]
Josef Dick and Friedrich Pillichshammer. Strong tractability of multivariate integration of arbitrary high order using digitally shifted polynomial lattice rules.J. Complexity, 23(4-6):436–453, 2007
work page 2007
-
[7]
Cambridge University Press, Cambridge, 2010
Josef Dick and Friedrich Pillichshammer.Digital Nets and Sequences–Discrepancy Theory and Quasi- Monte Carlo Integration. Cambridge University Press, Cambridge, 2010
work page 2010
-
[8]
Good interlaced polynomial lattice rules for numerical integration in weighted Walsh spaces.J
Takashi Goda. Good interlaced polynomial lattice rules for numerical integration in weighted Walsh spaces.J. Comput. Appl. Math., 285:279–294, 2015
work page 2015
-
[9]
Quasi–Monte Carlo integration using digital nets with antithetics.J
Takashi Goda. Quasi–Monte Carlo integration using digital nets with antithetics.J. Comput. Appl. Math., 304:26–42, 2016. 33
work page 2016
-
[10]
Construction of interlaced scrambled polynomial lattice rules of arbitrary high order.Found
Takashi Goda and Josef Dick. Construction of interlaced scrambled polynomial lattice rules of arbitrary high order.Found. Comput. Math., 15(5):1245–1278, 2015
work page 2015
-
[11]
A simple universal algorithm for high-dimensional integration.Numer
Takashi Goda and David Krieg. A simple universal algorithm for high-dimensional integration.Numer. Math., 158(1):229–248, 2026
work page 2026
-
[12]
Takashi Goda and Pierre L’Ecuyer. Construction-free median quasi–Monte Carlo rules for function spaces with unspecified smoothness and general weights.SIAM J. Sci. Comput., 44(4):A2765–A2788, 2022
work page 2022
-
[13]
Improved bounds on the gain coefficients for digital nets in prime power base.J
Takashi Goda and Kosuke Suzuki. Improved bounds on the gain coefficients for digital nets in prime power base.J. Complexity, 76:Paper No. 101722, 15, 2023
work page 2023
-
[14]
A universal median quasi–Monte Carlo integra- tion.SIAM J
Takashi Goda, Kosuke Suzuki, and Makoto Matsumoto. A universal median quasi–Monte Carlo integra- tion.SIAM J. Numer. Anal., 62(1):533–566, 2024
work page 2024
-
[15]
Optimal order quadrature error bounds for infinite- dimensional higher-order digital sequences.Found
Takashi Goda, Kosuke Suzuki, and Takehito Yoshiki. Optimal order quadrature error bounds for infinite- dimensional higher-order digital sequences.Found. Comput. Math., 18(2):433–458, 2018
work page 2018
-
[16]
Digital (t, m, s)-nets and the spectral test.Acta Arith., 105(2):197–204, 2002
Peter Hellekalek. Digital (t, m, s)-nets and the spectral test.Acta Arith., 105(2):197–204, 2002
work page 2002
-
[17]
Hickernell and Harald Niederreiter
Fred J. Hickernell and Harald Niederreiter. The existence of good extensible rank-1 lattices.J. Complexity, 19(3):286–300, 2003
work page 2003
-
[18]
An upper bound for the probability of a union.J
David Hunter. An upper bound for the probability of a union.J. Appl. Probability, 13(3):597–603, 1976
work page 1976
-
[19]
Stephen Joe and Frances Y. Kuo. Constructing Sobol’ sequences with better two-dimensional projections. SIAM J. Sci. Comput., 30(5):2635–2654, 2008
work page 2008
-
[20]
Yang Liu. Integrability of weak mixed first-order derivatives and convergence rates of scrambled digital nets.J. Complexity, 89:Paper No. 101935, 8, 2025
work page 2025
-
[21]
On theL2-discrepancy for anchored boxes.J
Jiˇ r´ ı Matouˇ sek. On theL2-discrepancy for anchored boxes.J. Complexity, 14(4):527–556, 1998
work page 1998
-
[22]
Low-discrepancy point sets.Monatsh
Harald Niederreiter. Low-discrepancy point sets.Monatsh. Math., 102(2):155–167, 1986
work page 1986
-
[23]
Point sets and sequences with small discrepancy.Monatsh
Harald Niederreiter. Point sets and sequences with small discrepancy.Monatsh. Math., 104(4):273–337, 1987
work page 1987
-
[24]
Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 1992
Harald Niederreiter.Random Number Generation and Quasi-Monte Carlo Methods, volume 63 ofCBMS- NSF Regional Conference Series in Applied Mathematics. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 1992
work page 1992
-
[25]
Art B. Owen. Randomly permuted (t, m, s)-nets and (t, s)-sequences. InMonte Carlo and quasi-Monte Carlo methods in scientific computing (Las Vegas, NV, 1994), volume 106 ofLect. Notes Stat., pages 299–317. Springer, New York, 1995
work page 1994
-
[26]
Art B. Owen. Monte Carlo variance of scrambled net quadrature.SIAM J. Numer. Anal., 34(5):1884–1910, 1997
work page 1910
-
[27]
Automatic optimal-rate convergence of randomized nets using median-of-means.Math
Zexin Pan. Automatic optimal-rate convergence of randomized nets using median-of-means.Math. Comp., 95(359):1415–1446, 2026
work page 2026
-
[28]
Dimension-independent convergence rates of randomized nets using median-of-means.Math
Zexin Pan. Dimension-independent convergence rates of randomized nets using median-of-means.Math. Comp., 2026
work page 2026
-
[29]
Zexin Pan and Art B. Owen. The nonzero gain coefficients of Sobol’s sequences are always powers of two. J. Complexity, 75:Paper No. 101700, 16, 2023
work page 2023
-
[30]
Zexin Pan and Art B. Owen. Super-polynomial accuracy of one dimensional randomized nets using the median of means.Math. Comp., 92(340):805–837, 2023
work page 2023
-
[31]
Zexin Pan and Art B. Owen. Super-polynomial accuracy of multidimensional randomized nets using the median-of-means.Math. Comp., 93(349):2265–2289, 2024
work page 2024
-
[32]
M. Yu. Rosenbloom and M. A. Tsfasman. Codes for them-metric.Problemy Peredachi Informatsii, 33(1):55–63, 1997
work page 1997
-
[33]
I. M. Sobol’. Distribution of points in a cube and approximate evaluation of integrals. ˇZ. Vyˇ cisl. Mat i Mat. Fiz., 7:784–802, 1967
work page 1967
-
[34]
Kosuke Suzuki and Takehito Yoshiki. Formulas for the Walsh coefficients of smooth functions and their application to bounds on the Walsh coefficients.J. Approx. Theory, 205:1–24, 2016. AppendixA.A fast implementation Here we describe the construction algorithm of the Hankel random digital net in 1-d. The case of multiple dimensions can be obtained by comb...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.