Numerical approximation of Markovian BSDEs in infinite horizon and elliptic PDEs
Pith reviewed 2026-05-08 01:43 UTC · model grok-4.3
The pith
Numerical schemes based on Picard contraction and neural networks approximate infinite-horizon Markovian BSDEs with proven convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A probabilistic representation using the Malliavin derivative allows proving contraction of a Picard scheme for infinite-horizon BSDEs, which in turn justifies two numerical approximation schemes with error bounds and convergence results, while a third neural network scheme succeeds without relying on contraction.
What carries the argument
The Picard fixed-point iteration based on the contraction mapping for the infinite-horizon BSDE, approximated via space grids or neural networks.
If this is right
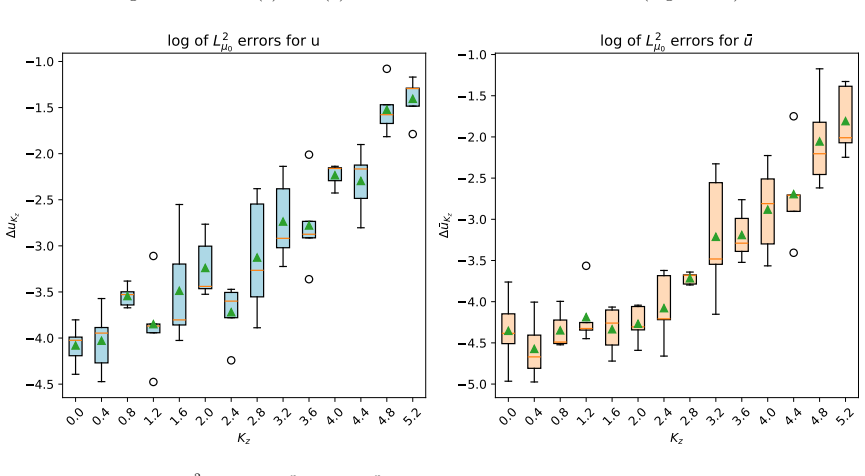
- The grid-based scheme yields tight error bounds in low dimensions but suffers from exponential growth in computational time as dimension increases.
- Neural network approximations prove convergent and maintain accuracy in very high dimensions by avoiding the curse of dimensionality.
- The non-contractive neural scheme extends practical applicability to BSDEs with stronger dependence on the control variable.
Where Pith is reading between the lines
- These methods could be tested on specific elliptic PDEs arising from the BSDE representation to verify accuracy against known analytical solutions.
- Combining the schemes with variance reduction techniques might further improve performance in high-dimensional settings.
- Extension to non-Markovian cases would require different representations beyond Malliavin calculus.
Load-bearing premise
The contraction property for the Picard scheme holds only under stronger assumptions on the Lipschitz constants than those required for mere existence and uniqueness of the BSDE solution.
What would settle it
A numerical test case where the error bounds for the grid or neural schemes do not hold as dimension increases or when the z-Lipschitz constant violates the contraction condition.
Figures









read the original abstract
We study backward stochastic differential equations (BSDEs) in infinite horizon and design efficient numerical schemes for solving them. We establish a probabilistic representation of the solution of the BSDE using Malliavin derivative and prove results for contraction of a Picard scheme. We develop three numerical schemes, of which the first two are based on a fixed point argument using contraction, imposing additional assumptions compared to what is needed for existence and uniqueness of the solution. The first scheme is a space grid based approximation where we establish tight numerical error bounds using a growth truncation argument; it performs well in low dimensions but computational times increase exponentially with dimension. The second scheme uses neural network approximations for which we have proved a convergence result. Using neural networks alleviates the curse of dimensionality, giving good accuracy in very high dimensions. The third scheme also uses neural networks but does not rely on contraction arguments, showcasing good performance even for larger z-Lipschitz dependence outside the domain of contraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops three numerical schemes for infinite-horizon Markovian BSDEs (linked to elliptic PDEs). Schemes 1 and 2 rely on a Picard fixed-point contraction mapping, with scheme 1 using a space-grid approximation that yields explicit error bounds via growth truncation, and scheme 2 using neural-network approximations for which a convergence result is proved. Scheme 3 employs neural networks without the contraction assumption and is supported by numerical experiments showing good performance for larger z-Lipschitz constants. The approach uses Malliavin calculus for the probabilistic representation and imposes additional assumptions for the contraction-based schemes beyond those needed for existence and uniqueness.
Significance. If the convergence results hold under the stated conditions, the work provides concrete, implementable methods that mitigate the curse of dimensionality in high-dimensional infinite-horizon BSDEs via neural networks, while the grid scheme offers rigorous error control in low dimensions. The explicit treatment of the non-contraction regime through numerical validation is a practical strength, though the theoretical guarantees remain confined to the contraction setting.
major comments (2)
- [Abstract / scheme descriptions] Abstract and the description of the schemes: the headline statement that 'we have proved a convergence result' for the neural-network scheme (scheme 2) is accurate only under the additional contraction assumptions (sufficiently small z-Lipschitz constant). These assumptions are explicitly noted as stricter than those required for existence/uniqueness of the infinite-horizon BSDE, so the proved convergence does not extend to the full existence regime; this qualification should be stated more prominently to avoid overstating the scope of the theoretical result.
- [Third scheme / numerical experiments] Section on the third scheme: no convergence theorem is provided for the neural-network scheme that operates outside the contraction domain. While numerical experiments demonstrate good performance for larger z-Lipschitz dependence, the absence of any error bound or consistency proof means the method lacks the theoretical backing claimed for the first two schemes; this gap is load-bearing for the paper's assertion of 'efficient numerical schemes … with proved convergence'.
minor comments (2)
- [Introduction / theorem statements] Clarify the precise statement of the additional assumptions (e.g., the threshold on the z-Lipschitz constant) in the introduction and in the statements of the convergence theorems for schemes 1 and 2.
- [PDE connection] The link between the BSDE schemes and the associated elliptic PDEs is mentioned but could be made more explicit, e.g., by stating the PDE form and the precise correspondence used for validation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below and will revise the manuscript accordingly to improve precision and clarity.
read point-by-point responses
-
Referee: [Abstract / scheme descriptions] Abstract and the description of the schemes: the headline statement that 'we have proved a convergence result' for the neural-network scheme (scheme 2) is accurate only under the additional contraction assumptions (sufficiently small z-Lipschitz constant). These assumptions are explicitly noted as stricter than those required for existence/uniqueness of the infinite-horizon BSDE, so the proved convergence does not extend to the full existence regime; this qualification should be stated more prominently to avoid overstating the scope of the theoretical result.
Authors: We agree that the abstract and scheme descriptions should qualify the convergence result for Scheme 2 more prominently. The proved convergence holds only under the contraction assumptions (sufficiently small z-Lipschitz constant), which are stricter than the conditions for existence and uniqueness. We will revise the abstract to state explicitly that the convergence result for the neural-network scheme is established under these additional assumptions, thereby avoiding any overstatement of scope. revision: yes
-
Referee: [Third scheme / numerical experiments] Section on the third scheme: no convergence theorem is provided for the neural-network scheme that operates outside the contraction domain. While numerical experiments demonstrate good performance for larger z-Lipschitz dependence, the absence of any error bound or consistency proof means the method lacks the theoretical backing claimed for the first two schemes; this gap is load-bearing for the paper's assertion of 'efficient numerical schemes … with proved convergence'.
Authors: We acknowledge that Scheme 3 lacks a convergence theorem, as it is intended for the non-contraction regime where the Picard fixed-point argument does not apply. The manuscript presents Scheme 3 as a practical alternative validated by numerical experiments showing good performance for larger z-Lipschitz constants, without claiming a theoretical convergence result for it. We will revise the relevant sections (including any statements referring to 'proved convergence' for the schemes) to clearly restrict such claims to Schemes 1 and 2, and to emphasize the experimental nature of Scheme 3. We do not currently have a proof for Scheme 3 and do not assert one. revision: partial
Circularity Check
No significant circularity; derivations rely on external Malliavin calculus and fixed-point theory
full rationale
The paper derives a probabilistic representation via Malliavin derivatives and proves Picard contraction under explicit Lipschitz conditions, then constructs three schemes with error bounds or convergence statements that follow directly from those contraction results. Scheme 2's NN convergence is proved inside the same contraction regime already stated for existence, while scheme 3 is presented only numerically without a theorem; neither step reduces to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. All load-bearing steps cite standard external probabilistic tools rather than prior author work that would close a loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence and uniqueness of solution to the infinite-horizon BSDE under suitable conditions
Reference graph
Works this paper leans on
-
[1]
C. Beck, L. Gonon, and A. Jentzen. Overcoming the curse of dimensionality in the numerical approximation of high-dimensional semilinear elliptic partial differential equations. Partial Differ. Equ. Appl. , 5(6):Paper No. 31, 47, 2024
work page 2024
-
[2]
P. Briand and Y. Hu. Stability of BSDEs with random terminal time and homogenization of semilinear elliptic PDEs . Journal of Functional Analysis , 155(2):455--494, 1998
work page 1998
-
[3]
P. Briand and Y. Hu. Quadratic BSDE s with convex generators and unbounded terminal conditions . Probab. Theory Related Fields , 141 (3-4):543--567, 2008
work page 2008
-
[4]
L. Chamakh, E. Gobet, and W. Liu. Orlicz norms and concentration inequalities for -heavy tailed random variables . hal-03175697
-
[5]
J. Chessari, R. Kawai, Y. Shinozaki, and T. Yamada. Numerical methods for backward stochastic differential equations: A survey . Probability Surveys , 20(none):486 -- 567, 2023
work page 2023
-
[6]
N. El Karoui, S. Peng, and M.-C. Quenez. Backward stochastic differential equations in finance. Math. Finance , 7 (1):1--71, 1997
work page 1997
-
[7]
M. Fuhrman and G. Tessitore. The B ismut- E lworthy formula for backward SDE s and applications to nonlinear K olmogorov equations and control in infinite dimensional spaces. Stoch. Stoch. Rep. , 74 (1-2):429--464, 2002
work page 2002
- [8]
- [9]
-
[10]
K. Hornik. Approximation capabilities of multilayer feedforward networks. Neural networks , 4(2):251--257, 1991
work page 1991
-
[11]
S. Kremsner, A. Steinicke, and M. Szölgyenyi. A deep neural network algorithm for semilinear elliptic PDEs with applications in insurance mathematics. Risks , 8(4), 2020
work page 2020
-
[12]
H. Kunita. Stochastic flows and stochastic differential equations . Cambridge Studies in Advanced Mathematics. 24. Cambridge: Cambridge University Press , 1997
work page 1997
- [13]
- [14]
-
[15]
N. Nüsken and L. Richter. Interpolating between BSDE s and PINN s -- deep learning for elliptic and parabolic boundary value problems, 2021
work page 2021
-
[16]
E. Pardoux and A. R a s canu. Stochastic Differential Equations, Backward SDEs, Partial Differential Equations , volume 69 of Stochastic Modelling and Applied Probability . Springer-Verlag, 2014
work page 2014
- [17]
-
[18]
A W. Van der Vaart and J. A. Wellner. Weak Convergence and Empirical Processes: With Applications to Statistics . Springer Series in Statistics. Springer-Verlag, New York, 1996
work page 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.