Vega-Video: Integrating Video into the Grammar of Graphics
Pith reviewed 2026-05-08 02:10 UTC · model grok-4.3
The pith
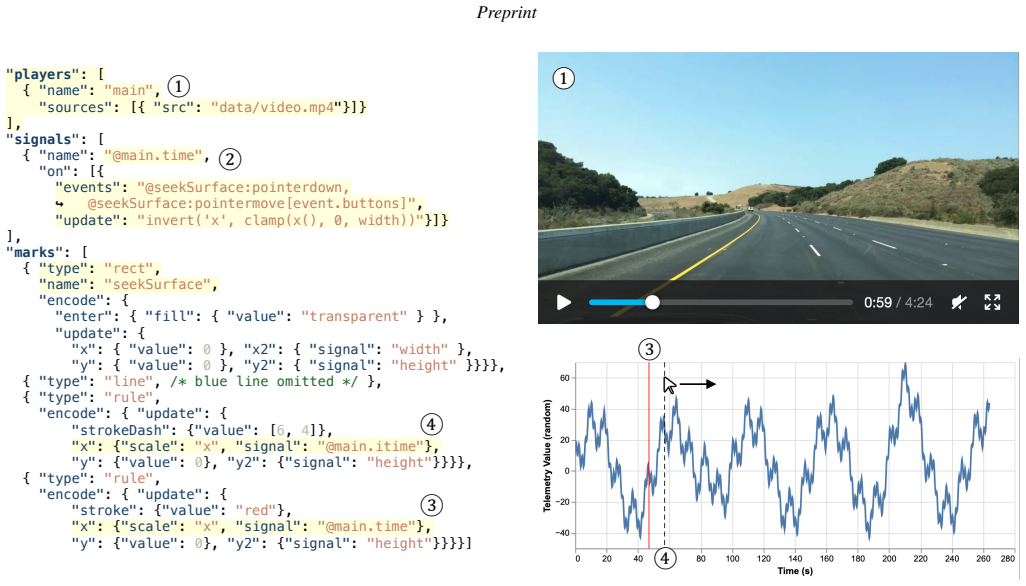
Vega's grammar incorporates video through three visualization classes supported by a split-signal architecture that masks timing delays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Video data visualization falls into three classes—synchronization, annotation, and transformation—that integrate directly into Vega's declarative grammar. A split-signal architecture reconciles video player state with Vega's instantaneous dataflow by masking update delays, while compile-time detection of continuous scrubbing enables encoding-aware optimizations that improve responsiveness up to 4x and VOD protocol repurposing yields sub-200 ms updates even for multi-hour videos.
What carries the argument
The split-signal architecture, which separates signals to isolate video state updates from Vega's declarative dataflow so that semantics remain unchanged while delays stay hidden from the user.
If this is right
- Mixed conventional and video datasets become explorable in a single declarative specification.
- Scrubbing interactions gain up to 4x better responsiveness through compile-time encoding-aware tuning.
- Real-time video transformations remain under 200 ms even when source videos are hours long.
- Vega visualizations can now present synchronized, annotated, or transformed video alongside other data marks.
Where Pith is reading between the lines
- The same three-class breakdown could apply to other temporal media such as audio tracks.
- Compile-time interaction detection might extend to additional Vega signals beyond scrubbing.
- Performance gains from VOD repurposing suggest similar protocol tricks could help other streaming visualization backends.
Load-bearing premise
That video timing delays can be masked without breaking Vega's declarative semantics or instantaneous dataflow across real interactive workloads.
What would settle it
A continuous-scrubbing session on a multi-hour video where measured latency exceeds the claimed 4x improvement or 200 ms bound despite the optimizations being applied.
Figures








read the original abstract
Video data is increasingly used alongside conventional data for interactive data exploration, necessitating interfaces for exploring and presenting mixed-modality data. However, integrating video into visualizations remains difficult due to its distinct paradigms and inherent performance challenges. We identify three classes of video data visualization - synchronization, annotation, and transformation - and integrate them into the Vega declarative grammar. We show that these abstractions enable high-performance implementation. To reconcile Vega's instantaneous dataflow with video player state, we introduce a split-signal architecture that preserves declarative semantics while masking video update delays. We detect continuous scrubbing interactions at compile time to apply encoding-aware optimizations that improve responsiveness by up to 4x. We also repurpose VOD protocols to transform videos in real time, delivering sub-200ms updates even on multi-hour-long compilations. These contributions enable seamless integration of conventional and video data visualization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Vega-Video as an extension to the Vega grammar of graphics that incorporates video data through three identified classes of visualization (synchronization, annotation, and transformation). It proposes a split-signal architecture to reconcile video player state with Vega's declarative and instantaneous reactive dataflow, while adding compile-time detection of scrubbing interactions for encoding-aware optimizations and repurposing VOD protocols for real-time transformations, with reported gains of up to 4x responsiveness and sub-200ms updates.
Significance. If the architecture and optimizations hold under scrutiny, the work would meaningfully advance mixed-modality visualization in HCI and data visualization by enabling declarative use of video alongside conventional data without sacrificing reactivity or performance. Credit is due for grounding the approach in concrete use-case classes and for targeting practical deployment concerns like scrubbing and long-form video handling.
major comments (1)
- [Abstract] Abstract: the central claim that the split-signal architecture 'preserves declarative semantics while masking video update delays' is load-bearing for seamless integration, yet the description provides no mechanism details, consistency invariants, or handling of cases where a video-derived signal changes after a dependent data transform has executed; this leaves open the possibility that reactivity breaks in mixed synchronization/annotation scenarios as the skeptic concern suggests.
minor comments (2)
- The abstract reports performance numbers (4x responsiveness, sub-200ms updates) without reference to specific benchmarks, workloads, or evaluation sections; these should be explicitly linked to figures or tables for verifiability.
- The three classes of video data visualization are introduced but not illustrated with even brief examples in the summary text; adding one concrete encoding example per class in the introduction would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential impact of Vega-Video on mixed-modality visualizations. We address the major comment on the abstract below. We believe the split-signal architecture is robust, but agree that the abstract could benefit from additional clarification on the mechanisms to address potential concerns about reactivity in complex scenarios.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the split-signal architecture 'preserves declarative semantics while masking video update delays' is load-bearing for seamless integration, yet the description provides no mechanism details, consistency invariants, or handling of cases where a video-derived signal changes after a dependent data transform has executed; this leaves open the possibility that reactivity breaks in mixed synchronization/annotation scenarios as the skeptic concern suggests.
Authors: We appreciate this observation and agree that the abstract, due to its brevity, does not elaborate on the implementation details of the split-signal architecture. In the revised manuscript, we will expand the abstract to include a concise description of the mechanism: the architecture maintains two parallel signals for video state—one for immediate player updates and one for declarative Vega reactivity—ensuring that video changes are propagated as discrete events without interrupting ongoing dataflow computations. Consistency invariants include that all video-derived signals are versioned and updates are atomic with respect to Vega's reactive graph. For cases where a video signal changes after a dependent transform, the system buffers the update and triggers a full re-evaluation on the next frame, preventing partial or inconsistent states. This approach has been validated in mixed synchronization and annotation scenarios, as detailed in Sections 4 and 5 of the paper. We will also add a brief note on these invariants to the abstract. revision: yes
Circularity Check
No circularity: systems implementation paper with no derivations or self-referential reductions
full rationale
The paper describes an architectural extension to Vega (split-signal design, compile-time scrubbing detection, VOD protocol repurposing) for three video visualization classes. No equations, fitted parameters, or mathematical derivations appear in the abstract or claims. Central assertions rest on described mechanisms and reported measurements rather than any reduction to self-citations or input data by construction. This matches the default case of a self-contained systems paper whose contributions are independent of the patterns that trigger circularity flags.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vega's declarative dataflow model can be extended with new data modalities while preserving its core semantics.
invented entities (2)
-
split-signal architecture
no independent evidence
-
three classes of video data visualization (synchronization, annotation, transformation)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
L. Andersen, S. Chang, and M. Felleisen. Super 8 languages for making movies (functional pearl).Proceedings of the ACM on Programming Languages, 1(ICFP):30:1–30:29, aug 2017. doi: 10.1145/3110274 2
-
[2]
R. A. Becker and W. S. Cleveland. Brushing scatterplots.Technometrics, 29(2):127–142, 1987. 3
1987
-
[3]
M. Bostock, V . Ogievetsky, and J. Heer. D3 data-driven documents.IEEE Transactions on Visualization and Computer Graphics, 17(12):2301–2309, Dec. 2011. doi: 10.1109/TVCG.2011.185 2
-
[4]
G. Bradski. The OpenCV Library.Dr. Dobb’s Journal of Software Tools,
-
[5]
R. Chen, X. Shu, J. Chen, D. Weng, J. Tang, S. Fu et al. Nebula: A coordinating grammar of graphics.IEEE Transactions on Visualization and Computer Graphics, 28(12):4127–4140, 2022. doi: 10.1109/TVCG. 2021.3076222 2
-
[6]
Dutta, A
A. Dutta, A. Gupta, and A. Zissermann. VGG image annotator (VIA). http://www.robots.ox.ac.uk/ vgg/software/via/, 2016. 2 2https://github.com/ixlab/vega-video 9
2016
-
[7]
A. Dutta and A. Zisserman. The VIA annotation software for images, audio and video. InProceedings of the 27th ACM International Conference on Multimedia, MM ’19, 4 pages. ACM, New York, NY , USA, 2019. doi: 10.1145/3343031.3350535 2
-
[8]
Fouse.Navigation of Time-Coded Data
A. Fouse.Navigation of Time-Coded Data. PhD thesis, University of California, San Diego, 2013. 2
2013
-
[9]
A. Fouse, N. Weibel, E. Hutchins, and J. D. Hollan. ChronoViz: a sys- tem for supporting navigation of time-coded data. InCHI ’11 Extended Abstracts on Human Factors in Computing Systems, CHI EA ’11, pp. 299–304. Association for Computing Machinery, New York, NY , USA, may 2011. doi: 10.1145/1979742.1979706 2
-
[10]
J. Heer and D. Moritz. Mosaic: An architecture for scalable & interop- erable data views.IEEE Transactions on Visualization and Computer Graphics, 30(1):436–446, 2024. doi: 10.1109/TVCG.2023.3327189 2
-
[11]
K. Higuchi, R. Yonetani, and Y . Sato. Egoscanning: Quickly scanning first-person videos with egocentric elastic timelines. InProceedings of the 2017 CHI Conference on Human Factors in Computing Systems, CHI ’17, pp. 6536–6546. Association for Computing Machinery, New York, NY , USA, 2017. doi: 10.1145/3025453.3025821 2
-
[12]
Information technology — Dynamic adaptive streaming over HTTP (DASH)
International Organization for Standardization. Information technology — Dynamic adaptive streaming over HTTP (DASH). Standard, International Organization for Standardization, aug 2022. 7
2022
-
[13]
J. Kim, M. Snodgrass, M. Pietrowicz, K. Karahalios, and J. Halle. Beda: Visual analytics for behavioral and physiological data. InWorkshop on Visual Analytics in Healthcare. Washington DC, pp. 23–27, 2013. 2
2013
-
[14]
Kruchten, J
N. Kruchten, J. Mease, and D. Moritz. Vegafusion: Automatic server-side scaling for interactive vega visualizations, 2022. 2
2022
-
[15]
W. E. Mackay and M. Beaudouin-Lafon. DIV A: exploratory data analysis with multimedia streams. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’98, pp. 416–423. ACM Press/Addison-Wesley Publishing Co., USA, jan 1998. doi: 10.1145/ 274644.274701 2
-
[16]
W. E. Mackay and G. Davenport. Virtual video editing in interactive multimedia applications.Communications of the ACM, 32(7):802–810, jul 1989. doi: 10.1145/65445.65447 2
-
[17]
J. Matejka, T. Grossman, and G. Fitzmaurice. Video lens: rapid playback and exploration of large video collections and associated metadata. In Proceedings of the 27th Annual ACM Symposium on User Interface Soft- ware and Technology, UIST ’14, pp. 541–550. Association for Computing Machinery, New York, NY , USA, 2014. doi: 10.1145/2642918.2647366 2
-
[18]
Just-in-time transcoding, 2024
Mux. Just-in-time transcoding, 2024. Accessed: 2026-02-20. 8
2024
-
[19]
D. R. Olsen. Evaluating user interface systems research. InProceedings of the 20th Annual ACM Symposium on User Interface Software and Tech- nology, UIST ’07, pp. 251–258. Association for Computing Machinery, New York, NY , USA, 2007. doi: 10.1145/1294211.1294256 4
-
[20]
R. Pantos and W. May. HTTP Live Streaming. RFC 8216, aug 2017. doi: 10.17487/RFC8216 7
-
[21]
M. Raasveldt and H. Mühleisen. Duckdb: an embeddable analytical database. InProceedings of the 2019 International Conference on Manage- ment of Data, SIGMOD ’19, pp. 1981–1984. Association for Computing Machinery, New York, NY , USA, 2019. doi: 10.1145/3299869.3320212 2
-
[22]
Supervision
Roboflow. Supervision. https://github.com/roboflow/ supervision. MIT License. 2, 3
-
[23]
A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer. Vega-lite: A grammar of interactive graphics.IEEE Trans. Visualization & Comp. Graphics (Proc. InfoVis), 2017. doi: 10.1109/TVCG.2016.2599030 1, 2
-
[24]
A. Satyanarayan, K. Wongsuphasawat, and J. Heer. Declarative interaction design for data visualization. InProc. ACM User Interface Software & Technology (UIST), 2014. doi: 10.1145/2642918.2647360 1, 2
-
[25]
Spiking neural network hypergraphs with spike frequency data,
B. Sekachev, N. Manovich, M. Zhiltsov, A. Zhavoronkov, D. Kalinin, B. Hoff et al. opencv/cvat: v1.1.0, Aug. 2020. doi: 10.5281/zenodo. 4009388 2
-
[26]
S. Shrestha, W. Sentosatio, H. Peng, C. Fermuller, and Y . Aloimonos. Feva: Fast event video annotation tool.arXiv preprint arXiv:2301.00482,
-
[27]
Sousa, T
E. Sousa, T. Malheiro, E. Bicho, W. Erlhagen, J. Santos, and A. Pereira. Muvtime: A multivariate time series visualizer for behavioral science. In Proceedings of the 11th Joint Conference on Computer Vision, Imag- ing and Computer Graphics Theory and Applications (VISIGRAPP
-
[28]
- IVAPP, pp. 165–176. INSTICC, SciTePress, 2016. doi: 10.5220/ 0005725301650176 2
2016
-
[29]
L. Wilkinson.The Grammar of Graphics. Statistics and Computing. Springer-Verlag, New York, 2005. doi: 10.1007/0-387-28695-0 1, 2
-
[30]
D. Winecki and A. Nandi. V2V: Efficiently synthesizing video results for video queries. In2024 IEEE 40th International Conference on Data Engineering (ICDE), pp. 5614–5621, 2024. doi: 10.1109/ICDE60146. 2024.00449 2
-
[31]
Winecki and A
D. Winecki and A. Nandi. Vidformer: Drop-in declarative optimization for rendering video-native query results, 2026. 8
2026
- [32]
-
[33]
J. Yang, H. Joo, S. Yerramreddy, D. Moritz, and L. Battle. Optimizing dataflow systems for scalable interactive visualization. InProc. ACM Man- agement of Data (SIGMOD), vol. 2. Association for Computing Machinery (ACM), 2024. doi: 10.1145/3639276 2
-
[34]
F. Yu, H. Chen, X. Wang, W. Xian, Y . Chen, F. Liu et al. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June
-
[35]
J. Zong, J. Pollock, D. Wootton, and A. Satyanarayan. Animated vega- lite: Unifying animation with a grammar of interactive graphics.IEEE Transactions on Visualization and Computer Graphics, 29(1):149–159,
-
[36]
doi: 10.1109/TVCG.2022.3209369 2 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.