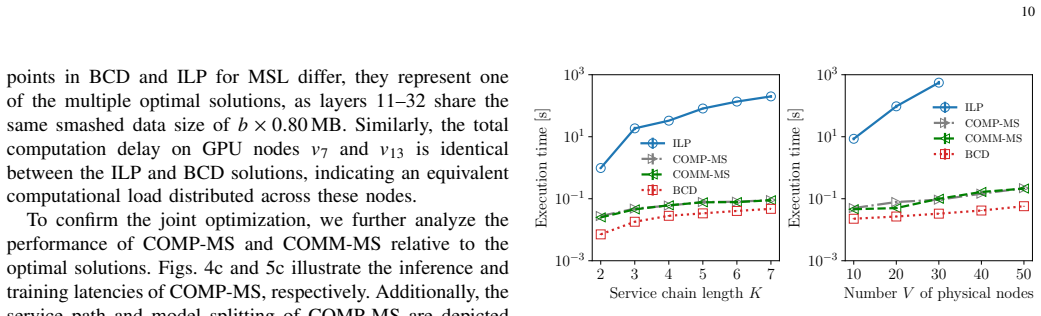
Recognition: unknown
Optimization of Model Splitting, Placement, and Chaining for Multi-hop Split Learning and Inference
Pith reviewed 2026-05-07 15:16 UTC · model grok-4.3
The pith
An ILP model jointly optimizes splitting, placement, and chaining for multi-hop split learning to minimize latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate an Integer Linear Programming (ILP) model to jointly optimize model splitting, placement, and chaining (data routing) in the SFC-based MSL/MSI architecture, aiming to minimize end-to-end inference or training latency. Additionally, we propose a Block Coordinate Descent (BCD)-based heuristic algorithm to efficiently solve the problem.
What carries the argument
The joint ILP optimization over model cut points, sub-model placements on nodes, and paths for smashed data under SFC constraints.
If this is right
- The joint optimization yields lower end-to-end latency than optimizing splitting and placement independently.
- The BCD heuristic solves the problem efficiently for practical network sizes while staying close to optimal.
- Evaluations confirm the formulation captures the trade-offs in multi-hop environments effectively.
Where Pith is reading between the lines
- If the network conditions change frequently, periodic re-solving of the ILP would be needed to maintain performance gains.
- The approach could be adapted to other chained processing tasks beyond neural network splitting, such as video analytics pipelines.
- Real-world deployment would require integrating the optimizer with network monitoring to update inputs dynamically.
Load-bearing premise
Network topology, node compute capacities, link latencies, and model layer sizes are known in advance and remain static long enough for the solution to be computed and deployed.
What would settle it
Deploy the optimized splitting, placement, and routes from the ILP on a testbed with the assumed static conditions and measure whether the observed latency matches the model's predicted minimum.
Figures









read the original abstract
Service Function Chaining (SFC) establishes efficient communication paths by ensuring that traffic traverses a predefined sequence of network functions in a specified order to meet particular service requirements. Inspired by this concept, we have proposed an SFC-based architecture for multi-hop split learning (MSL) and split inference (MSI), facilitating distributed AI applications to effectively route smashed data across multi-hop networks. However, the multi-hop environment presents new challenges, including (1) determining optimal cut points, (2) deploying split sub-models on appropriate computing nodes, and (3) routing smashed data through the underlying communication networks while adhering to service requirements. To address these challenges, we formulate an Integer Linear Programming (ILP) model to jointly optimize model splitting, placement, and chaining (data routing) in the SFC-based MSL/MSI architecture, aiming to minimize end-to-end inference or training latency. Additionally, we propose a Block Coordinate Descent (BCD)-based heuristic algorithm to efficiently solve the problem. Comprehensive evaluations demonstrate the effectiveness and characteristics of the proposed formulation and algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an SFC-based architecture for multi-hop split learning (MSL) and split inference (MSI) to route smashed data across networks. It formulates an Integer Linear Programming (ILP) model that jointly optimizes model splitting (cut points), placement of sub-models on nodes, and chaining (data routing) to minimize end-to-end latency. A Block Coordinate Descent (BCD)-based heuristic is introduced to solve the ILP efficiently for larger instances, and comprehensive evaluations are used to demonstrate effectiveness and characteristics of the approach.
Significance. If the evaluations confirm that the ILP produces feasible low-latency solutions and the BCD heuristic scales while staying close to optimal, the work supplies a concrete modeling tool for resource allocation in distributed AI over multi-hop networks. The joint treatment of splitting, placement, and SFC-style chaining extends prior split-learning literature in a structured way that could serve as a baseline for edge-cloud deployments under static conditions.
major comments (1)
- [ILP Model Formulation] The ILP formulation (problem statement and constraints) treats network topology, node compute capacities, link latencies, and model layer sizes as fixed, perfectly known inputs. This assumption is load-bearing for the central latency-minimization claim: any runtime fluctuation in congestion, node availability, or smashed-data sizes would invalidate the pre-computed solution, yet the manuscript provides no re-optimization trigger, uncertainty modeling, or online adaptation mechanism.
minor comments (3)
- [Abstract] The abstract states that 'comprehensive evaluations demonstrate effectiveness' but does not name the topologies, model sizes, or baseline algorithms used; adding these details would strengthen the claim.
- [Mathematical Formulation] Notation for variables and constraints in the ILP could be summarized in a dedicated table to improve readability.
- [Heuristic Algorithm] The BCD heuristic description would benefit from pseudocode or an explicit iteration breakdown to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comment regarding the assumptions in our ILP formulation. We address the point below and have made a revision to clarify the scope of the work.
read point-by-point responses
-
Referee: [ILP Model Formulation] The ILP formulation (problem statement and constraints) treats network topology, node compute capacities, link latencies, and model layer sizes as fixed, perfectly known inputs. This assumption is load-bearing for the central latency-minimization claim: any runtime fluctuation in congestion, node availability, or smashed-data sizes would invalidate the pre-computed solution, yet the manuscript provides no re-optimization trigger, uncertainty modeling, or online adaptation mechanism.
Authors: We agree that the ILP model and associated constraints are formulated under the assumption of fixed, perfectly known inputs for topology, capacities, latencies, and layer sizes. This is a deliberate modeling choice to enable the joint optimization of splitting, placement, and SFC-style chaining for end-to-end latency minimization in a static setting, which aligns with the baseline use case noted in the referee's significance assessment. The manuscript does not include re-optimization triggers, uncertainty sets, or online adaptation mechanisms, as these would constitute a distinct research direction (e.g., stochastic or dynamic programming). To address the comment, we will revise the manuscript by (i) adding an explicit statement of the static-input assumption at the beginning of the problem formulation section and (ii) inserting a short paragraph in the conclusion that acknowledges this limitation and outlines potential future extensions such as periodic re-solving with the BCD heuristic or integration with monitoring-based triggers. These changes clarify applicability without altering the core technical contributions. revision: yes
Circularity Check
No circularity in standard ILP formulation and BCD heuristic for MSL/MSI optimization
full rationale
The paper directly formulates an ILP model whose objective (end-to-end latency) and constraints are explicitly constructed from the given network topology, node capacities, link latencies, and model layer sizes; this is a conventional optimization setup rather than a derivation that reduces to its inputs by construction. No self-definitional variables, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described approach. The BCD heuristic is presented as an efficient solver for the same ILP, again without circular reduction. The assumption of static known inputs is a modeling limitation but does not create circularity in the claimed derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Network topology, node capacities, and link characteristics are known a priori and static.
- domain assumption The BCD heuristic converges to a useful solution within acceptable time.
Reference graph
Works this paper leans on
-
[1]
Split Learning for Health: Distributed Deep Learning without Sharing Raw Patient Data,
P. Vepakomma, O. Gupta, T. Swedish, and R. Raskar, “Split Learning for Health: Distributed Deep Learning without Sharing Raw Patient Data,” Dec. 2018
2018
-
[2]
ESFL: Efficient Split Federated Learning over Resource-Constrained Heterogeneous Wireless Devices,
G. Zhu, Y . Deng, X. Chen, H. Zhang, Y . Fang, and T. F. Wong, “ESFL: Efficient Split Federated Learning over Resource-Constrained Heterogeneous Wireless Devices,”IEEE Internet of Things Journal, vol. 11, no. 16, pp. 27 153–27 166, Aug. 2024
2024
-
[3]
Efficient Parallel Split Learning over Resource-Constrained Wireless Edge Networks,
Z. Lin, G. Zhu, Y . Deng, X. Chen, Y . Gao, K. Huang, and Y . Fang, “Efficient Parallel Split Learning over Resource-Constrained Wireless Edge Networks,”IEEE Transactions on Mobile Computing, vol. 23, no. 10, pp. 9224–9239, Oct. 2024
2024
-
[4]
Estimating the Training Time in Single- and Multi-Hop Split Federated Learning,
J. Tirana, S. Lalis, and D. Chatzopoulos, “Estimating the Training Time in Single- and Multi-Hop Split Federated Learning,” inProc. of the 8th International Workshop on Edge Systems, Analytics and Networking, ser. EdgeSys ’25. New York, NY , USA: Association for Computing Machinery, Mar. 2025, pp. 37–42
2025
-
[5]
Hierarchical Split Federated Learning: Convergence Analysis and Sys- tem Optimization,
Z. Lin, W. Wei, Z. Chen, C.-T. Lam, X. Chen, Y . Gao, and J. Luo, “Hierarchical Split Federated Learning: Convergence Analysis and Sys- tem Optimization,”IEEE Transactions on Mobile Computing, vol. 24, no. 10, pp. 9352–9367, Oct. 2025
2025
-
[6]
Service Function Chaining Architecture for Multi-hop Split Inference and Learning,
T. Hara and M. Sasabe, “Service Function Chaining Architecture for Multi-hop Split Inference and Learning,” Sep. 2025, arXiv:2509.10001
-
[7]
Inference Routing over Multi-Hop Edge Networks,
C. Xu, Y . Liu, and J. Yang, “Inference Routing over Multi-Hop Edge Networks,”IEEE Transactions on Cognitive Communications and Net- working, vol. 12, pp. 1356–1367, 2026
2026
-
[8]
Pipelining Split Learning in Multi-hop Edge Networks,
W. Wei, Z. Lin, T. Li, X. Li, and X. Chen, “Pipelining Split Learning in Multi-hop Edge Networks,” Sep. 2025
2025
-
[9]
Service Function Chaining (SFC) Architecture,
J. M. Halpern and C. Pignataro, “Service Function Chaining (SFC) Architecture,” RFC 7665, Oct. 2015. [Online]. Available: https://www.rfc-editor.org/info/rfc7665
2015
-
[10]
Optimal Model Placement and Online Model Splitting for Device-Edge Co-Inference,
J. Yan, S. Bi, and Y .-J. A. Zhang, “Optimal Model Placement and Online Model Splitting for Device-Edge Co-Inference,”IEEE Transactions on Wireless Communications, vol. 21, no. 10, pp. 8354–8367, Oct. 2022
2022
-
[11]
Split Learning over Wireless Networks: Parallel Design and Resource Management,
W. Wu, M. Li, K. Qu, C. Zhou, X. Shen, W. Zhuang, X. Li, and W. Shi, “Split Learning over Wireless Networks: Parallel Design and Resource Management,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 4, pp. 1051–1066, Apr. 2023
2023
-
[12]
A Bargaining Game for Personal- ized, Energy Efficient Split Learning over Wireless Networks,
M. Kim, A. DeRieux, and W. Saad, “A Bargaining Game for Personal- ized, Energy Efficient Split Learning over Wireless Networks,” inProc. of IEEE Wireless Communications and Networking Conference (WCNC), Mar. 2023, pp. 1–6
2023
-
[13]
Adaptive Split Learning over Energy-Constrained Wireless Edge Networks,
Z. Li, W. Wu, S. Wu, and W. Wang, “Adaptive Split Learning over Energy-Constrained Wireless Edge Networks,” inIEEE INFOCOM 2024 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), May 2024, pp. 1–6
2024
-
[14]
Optimal Cut Layer Bounds for Split Learning,
M. Marinova, M. Poposka, Z. Hadzi-Velkov, and V . Rakovic, “Optimal Cut Layer Bounds for Split Learning,”IEEE Communications Letters, vol. 29, no. 4, pp. 749–753, Apr. 2025
2025
-
[15]
Optimization Framework for Splitting DNN Inference Jobs over Computing Networks,
S. Jung and H.-W. Lee, “Optimization Framework for Splitting DNN Inference Jobs over Computing Networks,”Computer Networks, vol. 232, p. 109814, Aug. 2023
2023
-
[16]
Edge/Cloud Infinite-Time Horizon Resource Allo- cation for Distributed Machine Learning and General Tasks,
I. Sartzetakis, P. Soumplis, P. Pantazopoulos, K. V . Katsaros, V . Sourlas, and E. Varvarigos, “Edge/Cloud Infinite-Time Horizon Resource Allo- cation for Distributed Machine Learning and General Tasks,”IEEE Transactions on Network and Service Management, vol. 21, no. 1, pp. 697–713, Feb. 2024
2024
-
[17]
Optimization of Data and Model Transfer for Federated Learning to Manage Large-Scale Network,
K. Tajiri and R. Kawahara, “Optimization of Data and Model Transfer for Federated Learning to Manage Large-Scale Network,”IEEE Transac- tions on Network and Service Management, vol. 22, no. 2, pp. 958–973, Apr. 2025
2025
-
[18]
Dynamic Topology and Resource Allocation for Distributed Training in Mobile Edge Computing,
W. Fan, D. Wang, F. Xiao, Y . Zuo, M. Lv, L. Han, and S.-Y . Hsieh, “Dynamic Topology and Resource Allocation for Distributed Training in Mobile Edge Computing,”IEEE Transactions on Mobile Computing, vol. 24, no. 11, pp. 11 927–11 941, Jan. 2025
2025
-
[19]
Capacitated Shortest Path Tour Problem- Based Integer Linear Programming for Service Chaining and Function Placement in NFV Networks,
M. Sasabe and T. Hara, “Capacitated Shortest Path Tour Problem- Based Integer Linear Programming for Service Chaining and Function Placement in NFV Networks,”IEEE Transactions on Network and Service Management, vol. 18, no. 1, pp. 104–117, Mar. 2021
2021
-
[20]
Linear Programming,
R. J. Vanderbei, “Linear Programming,” inEncyclopedia of Applied and Computational Mathematics. Springer, 2015, pp. 796–800
2015
-
[21]
Coordinate Descent Algorithms,
S. J. Wright, “Coordinate Descent Algorithms,”Mathematical Program- ming, vol. 151, no. 1, pp. 3–34, Jun. 2015
2015
-
[22]
Service-Concatenation Routing with Applications to Network Functions Virtualization,
S. Bhat and G. N. Rouskas, “Service-Concatenation Routing with Applications to Network Functions Virtualization,” inProc. of the International Conference on Computer Communication and Networks (ICCCN). Vancouver, BC, Canada: IEEE, Jul. 2017, pp. 1–9
2017
-
[23]
On the Approximation of Curves by Line Segments Using Dynamic Programming,
R. Bellman, “On the Approximation of Curves by Line Segments Using Dynamic Programming,”Commun. ACM, vol. 4, no. 6, p. 284, Jun. 1961
1961
-
[24]
Speedy and Efficient Service Chaining and Function Placement Based on Lagrangian Heuristics for Capacitated Shortest Path Tour Problem,
T. Hara and M. Sasabe, “Speedy and Efficient Service Chaining and Function Placement Based on Lagrangian Heuristics for Capacitated Shortest Path Tour Problem,”Journal of Network and Systems Man- agement, vol. 31, no. 1, p. 24, Dec. 2022
2022
-
[25]
On the Convergence of the Block Nonlinear Gauss–Seidel Method under Convex Constraints,
L. Grippo and M. Sciandrone, “On the Convergence of the Block Nonlinear Gauss–Seidel Method under Convex Constraints,”Operations Research Letters, vol. 26, no. 3, pp. 127–136, Apr. 2000
2000
-
[26]
The NSFNET Backbone Network,
D. L. Mills and H. Braun, “The NSFNET Backbone Network,” in Proc. of the ACM Workshop on Frontiers in Computer Communications Technology, Aug. 1987, pp. 191–196
1987
-
[27]
Deep Residual Learning for Image Recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” inProc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2016, pp. 770–778
2016
-
[28]
Ima- geNet: A Large-Scale Hierarchical Image Database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Ima- geNet: A Large-Scale Hierarchical Image Database,” inProc. of IEEE Conference on Computer Vision and Pattern Recognition, Jun. 2009, pp. 248–255
2009
-
[29]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “PyTorch: An Imperative Style, High- Performance Deep Learning Library,” Dec. 2019, arXiv:1912.01703
work page internal anchor Pith review arXiv 2019
-
[30]
Gurobi Optimizer Reference Manual,
Gurobi Optimization, LLC, “Gurobi Optimizer Reference Manual,”
-
[31]
Available: https://www.gurobi.com
[Online]. Available: https://www.gurobi.com
-
[32]
Exploring Network Structure, Dynamics, and Function Using Networkx,
A. Hagberg, P. Swart, and D. S Chult, “Exploring Network Structure, Dynamics, and Function Using Networkx,” Los Alamos National Lab. (LANL), Los Alamos, NM (United States), Tech. Rep. LA-UR-08- 05495; LA-UR-08-5495, Jan. 2008. Takanori Harareceived the B.Eng. degree from Na- tional Institution for Academic Degrees and Quality Enhancement of Higher Educati...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.