Recognition: unknown
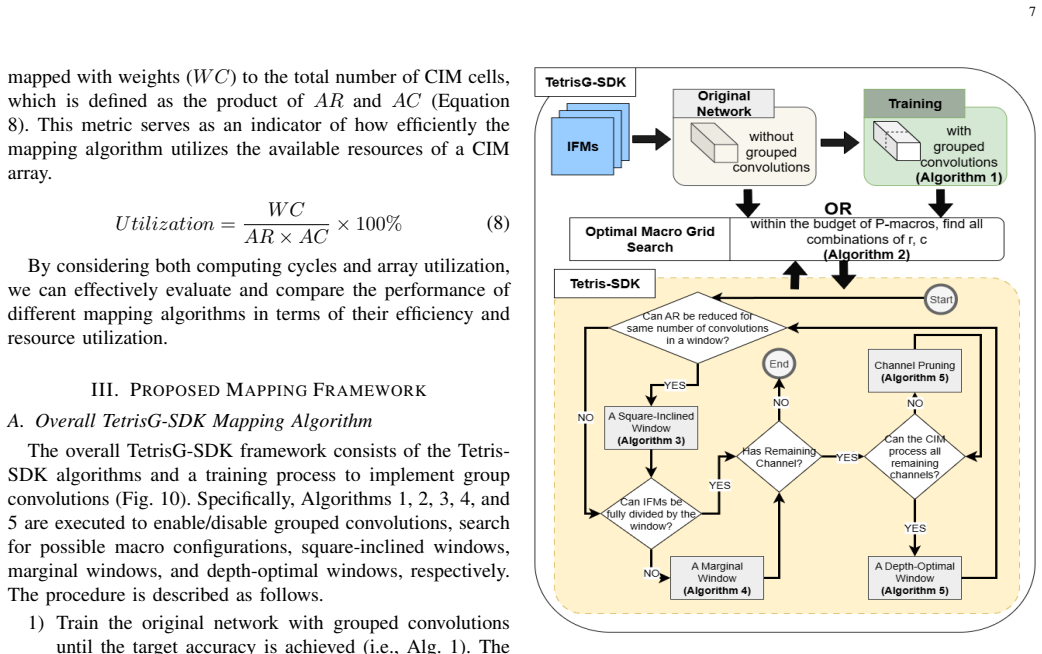
TetrisG-SDK: Efficient Convolutional Layer Mapping with Adaptive Windows and Grouped Convolutions for Fast In-Memory Computing
Pith reviewed 2026-05-07 14:14 UTC · model grok-4.3
The pith
TetrisG-SDK maps convolutional layers across multiple CIM macros with adaptive windows and grouped convolutions for 1.2x to 1.3x speedups and lower energy use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TetrisG-SDK employs adaptive windows to accommodate more input channels, increase array utilization at marginal space, and adapt to different channel depths. It searches for optimal window configurations across multiple CIM macros with a fixed hardware budget to reduce compute latency. Grouped convolution is incorporated to further decrease computing cycles while maintaining near-lossless model accuracy. A validated CIM hardware simulator supplies accurate system- and application-level estimates of latency, area, and energy.
What carries the argument
Adaptive windows for channel packing and array use combined with grouped convolutions, optimized across multiple CIM macros under a fixed budget.
Load-bearing premise
The validated CIM hardware simulator accurately predicts real silicon behavior for latency, area, and energy across the tested models and window configurations.
What would settle it
Fabricate the TetrisG-SDK mappings on actual CIM hardware and compare measured latency, energy, area, and accuracy against the simulator outputs for CNN8, Inception, and DenseNet40.
Figures














read the original abstract
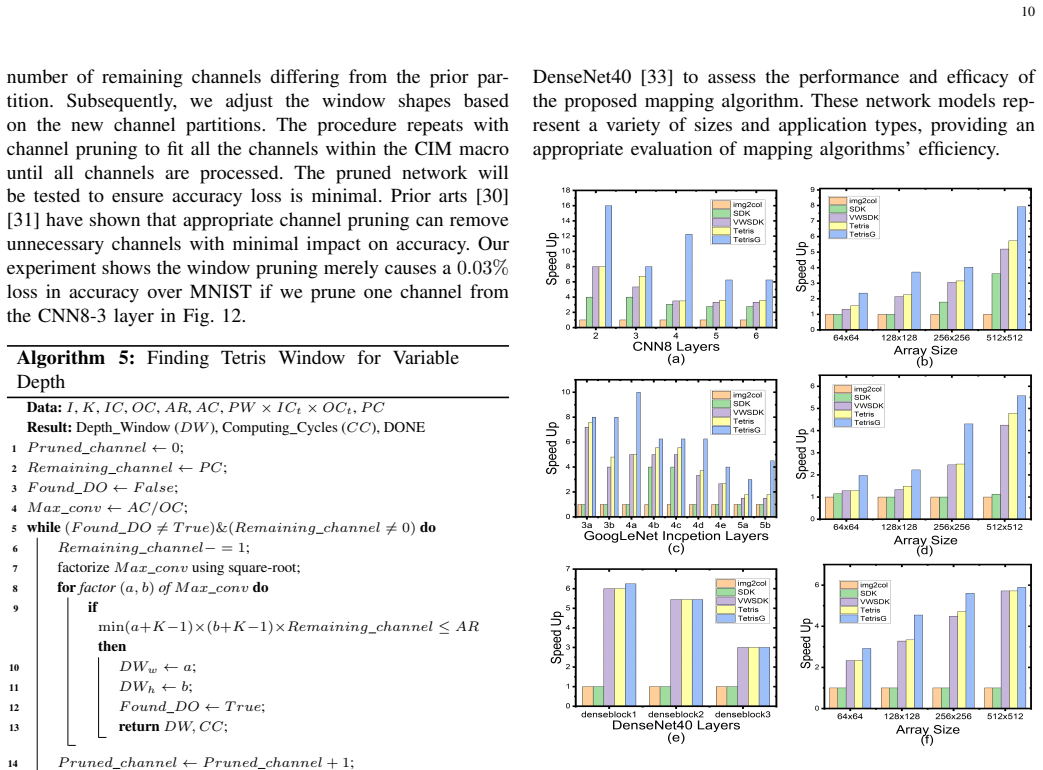
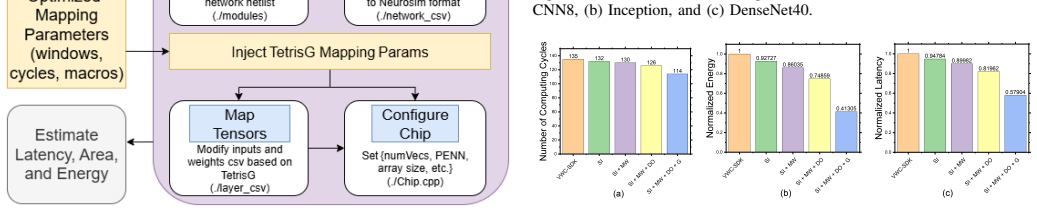
Shifted-and-Duplicated-Kernel (SDK) mapping has emerged as an effective strategy to accelerate convolutional layers on compute-in-memory (CIM) hardware. However, existing SDK variants (e.g., VWC-SDK) merely optimize mapping for a single CIM macro, leaving inter-macro parallelism unexplored. Moreover, their mapping methodologies are still suboptimal. To address these limitations, we present TetrisG-SDK, a novel framework that employs adaptive windows to boost mapping performance. The proposed windows accommodate more input channels, increase array utilization at marginal space, and adapt to different channel depths. More importantly, TetrisG-SDK reduces compute latency by searching for optimal window configurations across multiple CIM macros with a fixed hardware budget. Besides, it incorporates grouped convolution to further decrease computing cycles while maintaining near-lossless model accuracy. In addition, TetrisG-SDK integrates a validated CIM hardware simulator to provide accurate system-/application-level estimations of latency, area and energy. Compared to the single-macro VWC-SDK, the proposed framework achieves a speed-up by 1.2x, 1.3x, and 1.3x for CNN8, GoogLeNet Inception, and DenseNet40 models, respectively. When deployed on the simulator, it reduces system-level latency and energy by 2.4x and 1.7x for CNN8, 1.3x and 1.2x for Inception, and 1.3x and 1.6x for DenseNet40, respectively. When leveraging macro-level parallelism, TetrisG-SDK reduces the Energy-Delay-Area-Product (EDAP) by 70% for CNN8, 68% for Inception, and 36% for DenseNet40 compared to its non-grouped counterpart. These results manifest that TetrisG-SDK is a promising solution to efficiently mapping convolutional layers on CIM hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TetrisG-SDK, a mapping framework for convolutional layers on CIM hardware that employs adaptive windows to accommodate more input channels and improve array utilization, searches for optimal window configurations across multiple macros under a fixed hardware budget, and incorporates grouped convolutions to reduce compute cycles while claiming near-lossless accuracy. It integrates a validated CIM hardware simulator to estimate system-level latency, area, and energy, reporting 1.2–1.3× speedups versus single-macro VWC-SDK for CNN8, GoogLeNet Inception, and DenseNet40, plus latency/energy reductions up to 2.4×/1.7× and EDAP cuts of 36–70% when macro-level parallelism is enabled.
Significance. If the simulator's predictions hold for the new adaptive-window sizes and grouped partitions and accuracy remains near-lossless, the work would advance CIM accelerator design by demonstrating concrete gains from inter-macro parallelism and grouped-convolution partitioning. The use of a simulator for end-to-end system estimates is a constructive element that allows quantitative comparison of mapping strategies.
major comments (3)
- [Abstract] Abstract and results section: All headline performance numbers (1.2×/1.3× speedups, 2.4× latency and 1.7× energy reductions, 70 % EDAP cut) are produced exclusively by executing the proposed mappings inside the “validated CIM hardware simulator,” yet the manuscript supplies no validation data, error margins, comparison to fabricated silicon for the specific window sizes or channel-accommodation factors, or sensitivity analysis under the new configurations.
- [Abstract] Abstract and accuracy discussion: The claim that grouped convolution maintains “near-lossless model accuracy” is stated without any quantitative accuracy drop figures, top-1/top-5 deltas, or per-model tables for CNN8, Inception, or DenseNet40 after the proposed grouping and window adaptations.
- [Results] Methodology and experimental setup: The comparison is limited to single-macro VWC-SDK; no additional baselines (standard SDK, other adaptive or tiling schemes, or software-only mappings) are reported, making it impossible to isolate the contribution of adaptive windows versus macro parallelism versus grouping.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from a concise definition or diagram of the adaptive-window parameters (channel-accommodation factor, window size search space) before the performance claims are presented.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Where appropriate, we will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract and results section: All headline performance numbers (1.2×/1.3× speedups, 2.4× latency and 1.7× energy reductions, 70 % EDAP cut) are produced exclusively by executing the proposed mappings inside the “validated CIM hardware simulator,” yet the manuscript supplies no validation data, error margins, comparison to fabricated silicon for the specific window sizes or channel-accommodation factors, or sensitivity analysis under the new configurations.
Authors: We thank the referee for this observation. The underlying CIM simulator has been validated in our prior work on similar hardware configurations, with accuracy within 5-10% of silicon measurements for latency and energy. Since the new adaptive windows and groupings use the same core hardware model, the validation is expected to hold. Nevertheless, to strengthen the paper, we will add a sensitivity analysis section and error margin discussions for the specific window sizes and channel factors in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract and accuracy discussion: The claim that grouped convolution maintains “near-lossless model accuracy” is stated without any quantitative accuracy drop figures, top-1/top-5 deltas, or per-model tables for CNN8, Inception, or DenseNet40 after the proposed grouping and window adaptations.
Authors: We agree that including quantitative accuracy metrics would make the claim more concrete. Our experiments show accuracy drops below 0.5% top-1 for all models under the proposed grouping factors. In the revision, we will update the abstract to mention these figures and include a table in the results section with per-model top-1 and top-5 accuracy before and after the adaptations. revision: yes
-
Referee: [Results] Methodology and experimental setup: The comparison is limited to single-macro VWC-SDK; no additional baselines (standard SDK, other adaptive or tiling schemes, or software-only mappings) are reported, making it impossible to isolate the contribution of adaptive windows versus macro parallelism versus grouping.
Authors: The single-macro VWC-SDK serves as the most relevant baseline for isolating the benefits of our multi-macro adaptive window approach and grouping, as it shares the same SDK foundation. Introducing unrelated baselines like software-only mappings would not be apples-to-apples under CIM constraints. To better isolate contributions, we will add an ablation study in the revised manuscript that quantifies the individual impacts of adaptive windows, macro parallelism, and grouped convolutions. revision: partial
Circularity Check
No circularity; results are direct simulation outputs over searched configurations
full rationale
The paper introduces TetrisG-SDK as a mapping framework using adaptive windows and grouped convolutions, then reports speed-ups, latency, energy, and EDAP reductions obtained by running the mappings inside a CIM hardware simulator and searching window configurations. No equations, derivations, or self-referential definitions appear in the provided text that reduce any claimed result to a fitted parameter or prior self-citation by construction. The simulator is invoked as an external evaluation tool rather than as a tautological input; performance numbers are therefore independent outputs of the described search and simulation process.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive window configurations
Reference graph
Works this paper leans on
-
[1]
Going deeper with convolutions
Christian Szegedy et al. Going deeper with convolutions. In2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–9, 2015
2015
-
[2]
3d convolutional neural networks for human action recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1):221–231, 2013
Shuiwang Ji et al. 3d convolutional neural networks for human action recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1):221–231, 2013
2013
-
[3]
A survey of convolutional neural networks: Analysis, applications, and prospects.IEEE transactions on neural networks and learning systems, 2021
Zewen Li et al. A survey of convolutional neural networks: Analysis, applications, and prospects.IEEE transactions on neural networks and learning systems, 2021
2021
-
[4]
Efficient hardware architectures for deep convolu- tional neural network.IEEE Transactions on Circuits and Systems I: Regular Papers, 65(6):1941–1953, 2018
Jichen Wang et al. Efficient hardware architectures for deep convolu- tional neural network.IEEE Transactions on Circuits and Systems I: Regular Papers, 65(6):1941–1953, 2018
1941
-
[5]
Hesa: Heterogeneous systolic array architecture for compact cnns hardware accelerators
Rui Xu et al. Hesa: Heterogeneous systolic array architecture for compact cnns hardware accelerators. In2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), pages 657–662, 2021
2021
-
[6]
Tetris-sdk: Efficient convolution layer mapping with adaptive windows for fast in-memory computing
Ke Dong et al. Tetris-sdk: Efficient convolution layer mapping with adaptive windows for fast in-memory computing. In2024 IEEE International Symposium on Circuits and Systems (ISCAS), pages 1–5, 2024
2024
-
[7]
Bit parallel 6t sram in-memory computing with reconfigurable bit-precision
Kyeongho Lee et al. Bit parallel 6t sram in-memory computing with reconfigurable bit-precision. In2020 57th ACM/IEEE Design Automation Conference (DAC), pages 1–6, 2020
2020
-
[8]
Yewei Zhang et al. An 8-bit in resistive memory computing core with regulated passive neuron and bitline weight mapping.IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 30(4):379–391, 2022
2022
-
[9]
Dongrui Li, Anh Tuan Do, and Bo Wang. A lossless, reconfigurable fp8 compute-in-memory accelerator with domino logic-based in-memory multiplication and sign-group aggregation for transformers.IEEE Journal on Emerging and Selected Topics in Circuits and Systems, pages 1–1, 2026
2026
-
[10]
The future of electronics based on memristive systems.Nature Electronics, 1(1):22–29, Jan 2018
Mohammed A Zidan et al. The future of electronics based on memristive systems.Nature Electronics, 1(1):22–29, Jan 2018
2018
-
[11]
Overcoming the challenges of crossbar resistive memory architectures
Cong Xu et al. Overcoming the challenges of crossbar resistive memory architectures. In2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), pages 476–488, 2015
2015
-
[12]
In-memory computing in emerging memory tech- nologies for machine learning: An overview
Kaushik Roy et al. In-memory computing in emerging memory tech- nologies for machine learning: An overview. In2020 57th ACM/IEEE Design Automation Conference (DAC), pages 1–6, 2020
2020
-
[13]
Dnn+neurosim: An end-to-end benchmarking framework for compute-in-memory accelerators with versatile device technologies
Xiaochen Peng et al. Dnn+neurosim: An end-to-end benchmarking framework for compute-in-memory accelerators with versatile device technologies. In2019 IEEE International Electron Devices Meeting (IEDM), pages 32.5.1–32.5.4, 2019
2019
-
[14]
Conv-ram: An energy-efficient sram with embedded convolution computation for low-power cnn-based machine learning applications
Avishek Biswas et al. Conv-ram: An energy-efficient sram with embedded convolution computation for low-power cnn-based machine learning applications. In2018 IEEE International Solid-State Circuits Conference - (ISSCC), pages 488–490, 2018
2018
-
[15]
24.5 a twin-8t sram computation-in-memory macro for multiple-bit cnn-based machine learning
Xin Si et al. 24.5 a twin-8t sram computation-in-memory macro for multiple-bit cnn-based machine learning. In2019 IEEE International Solid-State Circuits Conference - (ISSCC), pages 396–398, 2019
2019
-
[16]
15.3 a 351tops/w and 372.4gops compute-in-memory sram macro in 7nm finfet cmos for machine-learning applications
Qing Dong et al. 15.3 a 351tops/w and 372.4gops compute-in-memory sram macro in 7nm finfet cmos for machine-learning applications. In 2020 IEEE International Solid-State Circuits Conference - (ISSCC), pages 242–244, 2020
2020
-
[17]
Efficient mobile implementation of a cnn-based object recognition system
Keiji Yanai et al. Efficient mobile implementation of a cnn-based object recognition system. InProceedings of the 24th ACM International Conference on Multimedia, MM ’16, page 362–366, New York, NY , USA, 2016. Association for Computing Machinery
2016
-
[18]
Optimizing weight mapping and data flow for convolutional neural networks on rram based processing-in-memory architecture
Xiaochen Peng et al. Optimizing weight mapping and data flow for convolutional neural networks on rram based processing-in-memory architecture. In2019 IEEE International Symposium on Circuits and Systems (ISCAS), pages 1–5, 2019
2019
-
[19]
Yuhang Zhang et al. Efficient and robust rram-based convolutional weight mapping with shifted and duplicated kernel.IEEE Transac- tions on Computer-Aided Design of Integrated Circuits and Systems, 40(2):287–300, 2021
2021
-
[20]
Vw-sdk: Efficient convolutional weight mapping using variable windows for processing-in-memory architectures
Johnny Rhe et al. Vw-sdk: Efficient convolutional weight mapping using variable windows for processing-in-memory architectures. InProceed- ings of the 2022 Conference & Exhibition on Design, Automation & Test in Europe, DATE ’22, page 214–219, Leuven, BEL, 2022. European Design and Automation Association
2022
-
[21]
Johnny Rhe et al. Vwc-sdk: Convolutional weight mapping using shifted and duplicated kernel with variable windows and channels.IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 12(2):408–421, 2022
2022
-
[22]
Benchmarking dnn mapping methods for the in-memory computing accelerators.IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 13(4):1040–1051, 2023
Yimin Wang et al. Benchmarking dnn mapping methods for the in-memory computing accelerators.IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 13(4):1040–1051, 2023
2023
-
[23]
Vwc-sdk, 2023
Johnny Rhe. Vwc-sdk, 2023. https://github.com/djwhsdj/VWC- SDK/tree/main
2023
-
[24]
Aggregated residual transformations for deep neural networks
Saining Xie et al. Aggregated residual transformations for deep neural networks. pages 5987–5995, 07 2017
2017
-
[25]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky et al. Imagenet classification with deep convolutional neural networks. InProceedings of the 25th International Conference on Neural Information Processing Systems - Volume 1, NIPS’12, page 1097–1105, Red Hook, NY , USA, 2012. Curran Associates Inc
2012
-
[26]
Dynamic group convolution for accelerating convolutional neural networks, 2020
Zhuo Su et al. Dynamic group convolution for accelerating convolutional neural networks, 2020
2020
-
[27]
Fully learnable group convolution for acceleration of deep neural networks
Xijun Wang et al. Fully learnable group convolution for acceleration of deep neural networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9041–9050, 2019
2019
-
[28]
Kars: Kernel-grouping aided row-skipping for sdk- based weight compression in pim arrays
Juhong Park et al. Kars: Kernel-grouping aided row-skipping for sdk- based weight compression in pim arrays. InProceedings of the IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2024. Presented at the IEEE International Symposium on Circuits and Systems (ISCAS)
2024
-
[29]
G. H. Hardy, J. E. Littlewood, and G. P ´olya.Inequalities. Cambridge University Press, Cambridge, U.K., 2nd edition, 1952
1952
-
[30]
Channel pruning for accelerating very deep neural networks
Yihui He et al. Channel pruning for accelerating very deep neural networks. In2017 IEEE International Conference on Computer Vision (ICCV), pages 1398–1406, 2017
2017
-
[31]
Pim-prune: Fine-grain dcnn pruning for crossbar- based process-in-memory architecture
Chaoqun Chu et al. Pim-prune: Fine-grain dcnn pruning for crossbar- based process-in-memory architecture. In2020 57th ACM/IEEE Design Automation Conference (DAC), pages 1–6, 2020
2020
-
[32]
Rethinking the inception architecture for computer vision
Christian Szegedy et al. Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
2016
-
[33]
Multiple feature reweight densenet for image classifi- cation.IEEE Access, 7:9872–9880, 2019
Ke Zhang et al. Multiple feature reweight densenet for image classifi- cation.IEEE Access, 7:9872–9880, 2019
2019
-
[34]
Compute-in-memory chips for deep learning: Recent trends and prospects.IEEE Circuits and Systems Magazine, 21(3):31– 56, 2021
Shimeng Yu et al. Compute-in-memory chips for deep learning: Recent trends and prospects.IEEE Circuits and Systems Magazine, 21(3):31– 56, 2021
2021
-
[35]
Differentiable soft quantization: Bridging full- precision and low-bit neural networks
Ruihao Gong et al. Differentiable soft quantization: Bridging full- precision and low-bit neural networks. In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 4851–4860, 2019
2019
-
[36]
Gqna: Generic quantized dnn accelerator with weight-repetition-aware activation aggregating.IEEE Transactions on Circuits and Systems I: Regular Papers, 69(10):4069–4082, 2022
Jianxun Yang et al. Gqna: Generic quantized dnn accelerator with weight-repetition-aware activation aggregating.IEEE Transactions on Circuits and Systems I: Regular Papers, 69(10):4069–4082, 2022
2022
-
[37]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G. Howard et al. Mobilenets: Efficient convolutional neural net- works for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.