C-PINN: A neural network framework based on the Cord\`{e}s condition for solving linear and fully nonlinear equations in non-divergence form and its applications
Pith reviewed 2026-05-07 15:35 UTC · model grok-4.3
The pith
Embedding the Cordès condition into the loss function lets physics-informed neural networks solve non-divergence form PDEs more stably and accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By incorporating the operator structure into the loss function via the Cordès condition, the proposed neural network framework improves the conditioning of the associated optimization problem, thereby enhancing training stability and solution accuracy for linear and fully nonlinear PDEs in non-divergence form.
What carries the argument
The Cordès condition, a structural property of the PDE operator that is folded into the PINN loss function to reflect the non-divergence form directly.
If this is right
- The framework extends directly to Hamilton-Jacobi-Bellman equations and Monge-Ampère equations.
- It supports applications such as optimal transport problems.
- Numerical results indicate the method remains effective for high-dimensional instances.
- Its generality and simplicity allow use across a range of scientific and engineering PDE problems.
Where Pith is reading between the lines
- The same conditioning idea could be tried on other classes of nonlinear PDEs that standard PINNs handle poorly.
- Combining C-PINN with adaptive collocation or residual-based sampling might further reduce training cost.
- If the improvement scales, it could reduce reliance on problem-specific network architectures for certain non-divergence equations.
Load-bearing premise
That embedding the Cordès condition into the PINN loss function will reliably improve conditioning and accuracy for both linear and fully nonlinear non-divergence PDEs without introducing new instabilities or requiring problem-specific tuning.
What would settle it
A controlled numerical test on a non-divergence PDE where standard PINN training succeeds but the C-PINN version diverges or yields higher error would falsify the claimed improvement in conditioning and accuracy.
Figures






















read the original abstract
In this paper, we propose a novel Physics-Informed Neural Network (PINN) framework based on the Cord\`{e}s condition for solving both linear and fully nonlinear partial differential equations (PDEs) in non-divergence form, together with their applications. By incorporating the operator structure into the loss function, the proposed method improves the conditioning of the associated optimization problem, thereby enhancing training stability and solution accuracy. The framework is further extended to include Hamilton-Jacobi-Bellman and Monge-Amp\`{e}re equations, with applications to optimal transport. Numerical experiments demonstrate the effectiveness and robustness of the method, as well as its capability to address high-dimensional problems, highlighting the promise of learning-based approaches for tackling challenging PDEs. Owing to its generality and simplicity, the proposed method is expected to be of broad interest to the scientific and engineering communities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes C-PINN, a physics-informed neural network framework that embeds the Cordès condition into the loss function to solve linear and fully nonlinear PDEs in non-divergence form. It claims this incorporation improves the conditioning of the associated non-convex optimization problem, thereby enhancing training stability and solution accuracy. The framework is extended to Hamilton-Jacobi-Bellman and Monge-Ampère equations with applications to optimal transport, and numerical experiments are presented to demonstrate effectiveness, robustness, and applicability to high-dimensional problems.
Significance. If the claimed conditioning improvement and resulting accuracy gains hold under rigorous verification, the work could offer a practical extension of PINNs to a class of PDEs that are difficult for standard divergence-form methods, with potential value for high-dimensional optimal transport and fully nonlinear problems. The generality across linear and nonlinear cases is a strength, though the absence of direct diagnostics for the core innovation limits the current impact.
major comments (2)
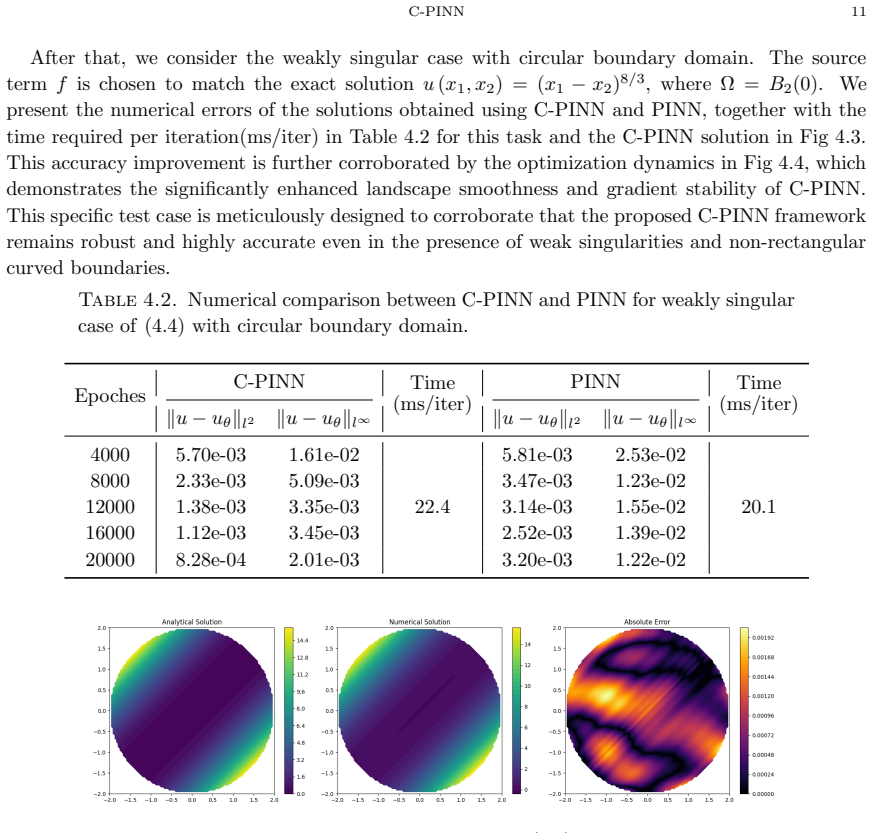
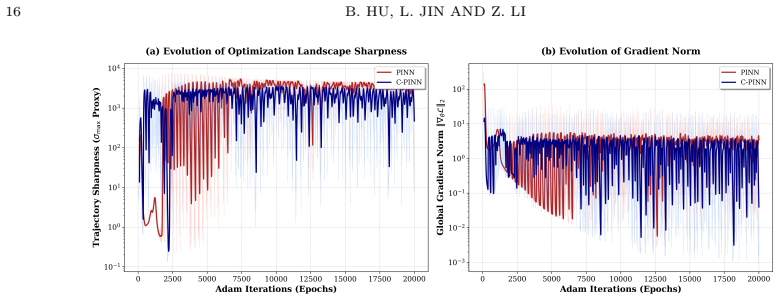
- [Numerical experiments] Numerical experiments section: The manuscript reports accuracy results on linear and nonlinear test cases but provides no quantitative diagnostics (such as loss Hessian condition numbers, eigenvalue spreads, or side-by-side optimization trajectory comparisons) that isolate the effect of the Cordès term versus standard PINN losses, network architecture, or hyperparameter choices. This directly undermines support for the central claim that embedding the Cordès condition improves conditioning and stability.
- [Loss function construction] Loss function construction (likely §3): The presentation does not clarify whether the Cordès incorporation introduces additional problem-specific scaling or weighting parameters that must be tuned per PDE, which risks contradicting the claimed generality and simplicity without introducing new instabilities.
minor comments (2)
- [Abstract] Abstract: The statement that 'numerical experiments demonstrate the effectiveness and robustness' is unsupported by any specific error metrics, baselines, or quantitative highlights, reducing clarity for readers.
- Notation: Ensure consistent use of the Cordès condition symbol and its embedding in the loss across equations and text to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the constructive comments, which have helped us identify areas for improvement. We address each major comment below.
read point-by-point responses
-
Referee: [Numerical experiments] Numerical experiments section: The manuscript reports accuracy results on linear and nonlinear test cases but provides no quantitative diagnostics (such as loss Hessian condition numbers, eigenvalue spreads, or side-by-side optimization trajectory comparisons) that isolate the effect of the Cordès term versus standard PINN losses, network architecture, or hyperparameter choices. This directly undermines support for the central claim that embedding the Cordès condition improves conditioning and stability.
Authors: We acknowledge that direct quantitative diagnostics, such as Hessian condition numbers or eigenvalue spreads, would provide stronger isolation of the Cordès term's effect on optimization conditioning. Our current experiments demonstrate consistent gains in accuracy and training stability across linear and nonlinear cases, but these are indirect. In the revised manuscript we will add side-by-side training-loss curves and, for selected low-dimensional examples, approximate condition-number estimates of the loss Hessian to furnish more direct evidence. revision: yes
-
Referee: [Loss function construction] Loss function construction (likely §3): The presentation does not clarify whether the Cordès incorporation introduces additional problem-specific scaling or weighting parameters that must be tuned per PDE, which risks contradicting the claimed generality and simplicity without introducing new instabilities.
Authors: The Cordès term is incorporated by augmenting the standard PDE residual with an operator-derived expression that follows directly from the Cordès condition; no additional problem-specific scaling or weighting coefficients are introduced beyond the conventional balancing weights already used in PINN losses. We will revise Section 3 to display the explicit loss expression and state that the hyperparameter choices remain identical in form to those of standard PINNs, thereby preserving the claimed generality. revision: partial
Circularity Check
No significant circularity; novel framework construction independent of inputs
full rationale
The paper presents C-PINN as a new construction that augments the standard PINN loss with the Cordès condition to encode operator structure. No step reduces a claimed prediction or uniqueness result to a fitted quantity defined by the target output, nor does any load-bearing premise collapse to a self-citation chain. The central claim (conditioning improvement via the modified loss) is an empirical hypothesis tested on linear/nonlinear examples rather than an identity by construction. Self-citations, if present, are not required to justify the framework itself. This is the common case of an honest new method whose verification gaps (e.g., missing Hessian diagnostics) concern correctness, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, PMLR 70: 214-223, 2017
work page 2017
-
[2]
G. Barles and P. E. Souganidis. Convergence of approximation schemes for fully nonlinear second order equations. In Proceedings of the 29th IEEE Conference on Decision and Control, 2347-2349, 1990
work page 1990
-
[3]
J. D. Benamou, B. D. Froese and A. M. Oberman. Numerical solution of the optimal transportation problem using the Monge-Amp` ere equation. Journal of Computational Physics, 260: 107-126, 2014
work page 2014
-
[4]
Y. Brenier. Polar factorization and monotone rearrangement of vector-valued functions. Communications on Pure and Applied Mathematics, 44(4): 375-417, 1991
work page 1991
-
[5]
L. A. Caffarelli and X. Cabr´ e. Fully Nonlinear Elliptic Equations. American Mathematical Society, Providence, RI, 1995
work page 1995
-
[6]
H. O. Cord` es.¨Uber die erste Randwertaufgabe bei quasilinearen Differentialgleichungen zweiter Ordnung in mehr als zwei Variablen. Mathematische Annalen, 131(3): 278-312, 1956
work page 1956
- [7]
-
[8]
M. G. Crandall, H. Ishii and P. L. Lions. User’s guide to viscosity solutions of second order partial differential equations. Bulletin of the American Mathematical Society, 27(1): 1-67, 1992
work page 1992
- [9]
- [10]
-
[11]
E. J. Dean and R. Glowinski. Numerical solution of the two-dimensional elliptic Monge-Amp` ere equation with Dirichlet boundary conditions: An augmented Lagrangian approach. Comptes Rendus Mathematique, 336(9): 779-784, 2003
work page 2003
-
[12]
K. Debrabant and E. R. Jakobsen. Semi-Lagrangian schemes for linear and fully non-linear diffusion equations. Mathematics of Computation, 82(283): 1433-1462, 2013
work page 2013
-
[13]
F. Dragoni. Differential games and Hamilton-Jacobi equations in the Heisenberg group. Communications in Partial Differential Equations, 35(6): 953-976, 2010
work page 2010
-
[14]
M. J. Feng and J. Lewis. An efficient approach for the numerical solution of the Monge-Amp` ere equation. Applied Numerical Mathematics, 61(3): 298-307, 2011. C-PINN 27
work page 2011
-
[15]
X. B. Feng and M. Neilan. Mixed finite element methods for the fully nonlinear Monge-Amp` ere equation based on the vanishing moment method. SIAM Journal on Numerical Analysis, 47(2): 1226-1250, 2009
work page 2009
-
[16]
X. B. Feng, T. Lewis and M. Neilan. A finite element method for second order nonvariational elliptic problems. SIAM Journal on Scientific Computing, 33(2): 786-801, 2011
work page 2011
-
[17]
X. B. Feng, T. Lewis and M. Neilan. Analysis of the vanishing moment method and its finite element approx- imations for second-order linear elliptic PDEs in non-divergence form. Methods and Applications of Analysis, 26(2): 167-194, 2019
work page 2019
-
[18]
X. B. Feng, R. Glowinski and M. Neilan. Recent developments in numerical methods for fully nonlinear second order partial differential equations. SIAM Review, 55(2): 205-267, 2013
work page 2013
-
[19]
B. D. Froese and A. M. Oberman. Convergent finite difference solvers for viscosity solutions of the elliptic Monge-Amp` ere equation in dimensions two and higher. SIAM Journal on Numerical Analysis, 49(4): 1692-1714, 2011
work page 2011
-
[20]
D. Gilbarg and N. S. Trudinger. Elliptic Partial Differential Equations of Second Order. Springer-Verlag, Berlin, Heidelberg, 2001
work page 2001
-
[21]
A. D. Jagtap, K. Kawaguchi and G. E. Karniadakis. Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. Journal of Computational Physics, 404: 109136, 2020
work page 2020
-
[22]
J. Han, A. Jentzen and W. E. Solving high-dimensional partial differential equations using deep learning. Pro- ceedings of the National Academy of Sciences, 115(34): 8505-8510, 2018
work page 2018
-
[23]
M. Jensen. Consistency of generalized finite difference schemes for the stochastic HJB equation. SIAM Journal on Numerical Analysis, 41(3): 1138-1156, 2003
work page 2003
-
[24]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang and L. Yang. Physics-informed machine learning. Nature Reviews Physics, 3(6): 422-440, 2021
work page 2021
-
[25]
S. Kawecki and S. J. Neukamm.C 0 finite element approximations of linear elliptic equations in non-divergence form and Hamilton-Jacobi-Bellman equations with Cord` es coefficients. Calcolo, 58(1): 9, 2021
work page 2021
-
[26]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. The 3rd International Conference for Learning Representations, San Diego, 2015
work page 2015
-
[27]
A. Krishnapriyan, A. Gholami, S. Zhe, R. Kirby and M. W. Mahoney. Characterizing possible failure modes in physics-informed neural networks. Advances in Neural Information Processing Systems, 34: 26561-26573, 2021
work page 2021
-
[28]
N. V. Krylov. Controlled Diffusion Processes. Springer-Verlag, New York, 1980
work page 1980
-
[29]
N. V. Krylov. Nonlinear Elliptic and Parabolic Equations of the Second Order. Mathematics and Its Applications, Vol. 7. D. Reidel Publishing Company, Dordrecht, 1987
work page 1987
-
[30]
N. V. Krylov. On the rate of convergence of finite-difference approximations for Bellman’s equations with variable coefficients. Probability Theory and Related Fields, 108(1): 93-157, 1997
work page 1997
-
[31]
N. V. Krylov. Lectures on Elliptic and Parabolic Equations in Sobolev Spaces. American Mathematical Society, Providence, RI, 2008
work page 2008
- [32]
- [33]
-
[34]
L. Lu, X. Meng, Z. Mao and G. E. Karniadakis. DeepXDE: A deep learning library for solving differential equations. SIAM Review, 63(1): 208-228, 2021
work page 2021
-
[35]
T. W. Meng, G. P. T. Choi and L. M. Lui. TEMPO: Feature-endowed Teichm¨ uller extremal mappings of point clouds. SIAM Journal on Imaging Sciences, 9(4): 1922-1962, 2016
work page 1922
-
[36]
R. H. Nochetto and W. Zhang. Discrete ABP estimate and convergence rates for linear elliptic equations in non-divergence form. Foundations of Computational Mathematics, 18(3): 537-593, 2018
work page 2018
-
[37]
A. M. Oberman. Convergent difference schemes for degenerate elliptic and parabolic equations: Hamilton-Jacobi equations and free boundary problems. SIAM Journal on Numerical Analysis, 44(2): 879-895, 2006
work page 2006
-
[38]
A. M. Oberman. Wide stencil finite difference schemes for the elliptic Monge-Amp` ere equation and functions of the eigenvalues of the Hessian. Discrete and Continuous Dynamical Systems - Series B, 10(1): 221-238, 2008
work page 2008
-
[39]
A. Pal, T. Gudi and P. Shakya. AC 0-IP method for distributed optimal control problem governed by a non- divergent form PDE with Cord` es coefficients. Mathematics of Computation, 95: 1679-1718, 2026
work page 2026
-
[40]
G. Peyr´ e and M. Cuturi. Computational optimal transport: With applications to data science. Foundations and Trends in Machine Learning, 11(5-6): 355-607, 2019. 28 B. HU, L. JIN AND Z. LI
work page 2019
- [41]
-
[42]
L. Ruthotto, S. J. Osher, W. Li and S. W. Fung. A machine learning framework for solving high-dimensional mean field game and mean field control problems. Proceedings of the National Academy of Sciences, 117(17): 9183-9193, 2020
work page 2020
-
[43]
F. Santambrogio. Optimal Transport for Applied Mathematicians: Calculus of Variations, PDEs, and Modeling. Progress in Nonlinear Differential Equations and Their Applications, Vol. 87. Birkh¨ auser, Cham, 2015
work page 2015
-
[44]
J. Sirignano and K. Spiliopoulos. DGM: A deep learning algorithm for solving partial differential equations. Journal of Computational Physics, 375: 1339-1364, 2018
work page 2018
-
[45]
I. Smears and E. S¨ uli. Discontinuous Galerkin finite element approximation of nondivergence form elliptic equa- tions with Cord` es coefficients. SIAM Journal on Numerical Analysis, 51(4): 2088-2106, 2013
work page 2088
-
[46]
J. Solomon, F. de Goes, G. Peyr´ e, M. Cuturi, A. Butscher, A. Nguyen, T. Du, and L. Guibas. Convolutional Wasserstein distances: Efficient optimal transportation on geometric domains. ACM Transactions on Graphics, 34(4): 67, 2015
work page 2015
-
[47]
C. Villani. Topics in Optimal Transportation. Graduate Studies in Mathematics, Vol. 58. American Mathematical Society, Providence, RI, 2003
work page 2003
-
[48]
P. P. Wang, L. X. Jin, Z. X. Li and L. J. Yi. Spectral collocation method for numerical solution to the fully nonlinear Monge-Amp` ere equation. Journal of Scientific Computing. 100:77, 1-28, 2024
work page 2024
-
[49]
S. Wang, Y. Teng and P. Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks. SIAM Journal on Scientific Computing, 43(5): A3055-A3081, 2021
work page 2021
-
[50]
S. Wang, X. Yu and P. Perdikaris. When and why PINNs fail to train: A neural tangent kernel perspective. Journal of Computational Physics, 449: 110768, 2022
work page 2022
- [51]
-
[52]
J. M. Cohen, S. Kaur, Y. Li, J. Z. Kolter, and A. Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. In Proceedings of the International Conference on Learning Representations, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.