MPI Malleability Validation under Replayed Real-World HPC Conditions
Pith reviewed 2026-05-07 10:56 UTC · model grok-4.3
The pith
Replaying real HPC workload logs on a production supercomputer shows efficiency-aware MPI malleability shortens malleable job times by 27% without delaying baseline workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
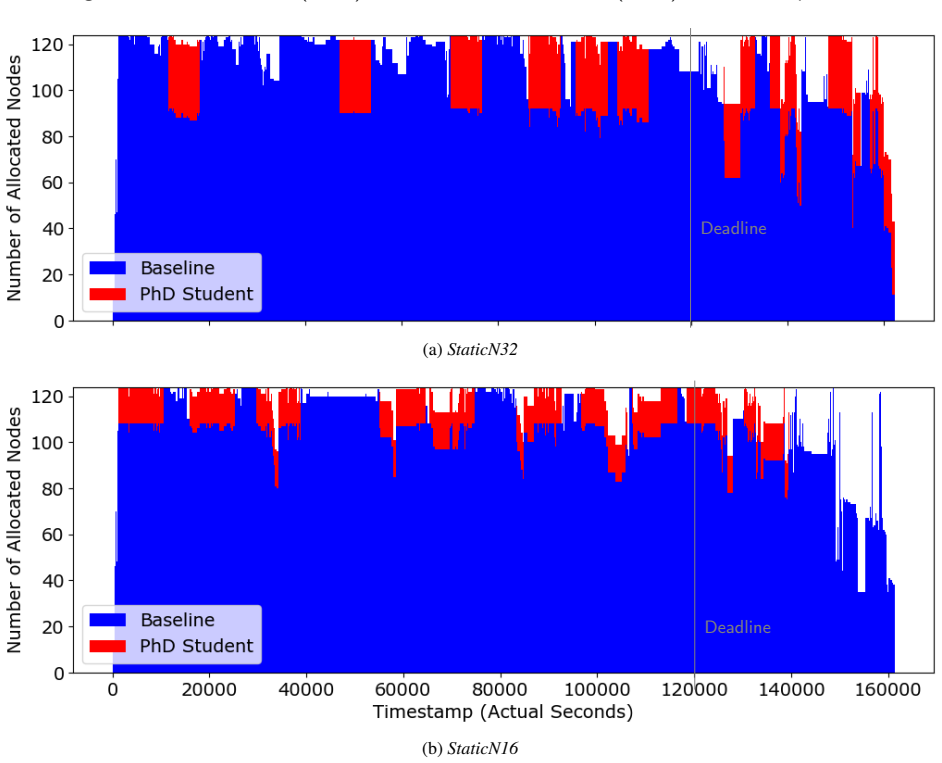
The authors introduce a replay-based validation method that reproduces real cluster conditions by adapting workload logs to the target HPC infrastructure. When applied to MPI malleability on a 125-node partition, parallel efficiency-aware malleability reduced the malleable workload's execution time by 27% without increasing the completion time of the baseline workload, while maintaining the resource utilization rate despite added queueing delays for certain jobs.
What carries the argument
The workload log replay methodology, which adapts historical job and user data to current cluster conditions to enable realistic validation of malleable MPI applications that dynamically adjust their process count based on observed parallel efficiency.
If this is right
- Malleable workloads finish earlier when resizing follows parallel efficiency.
- Non-malleable baseline workloads incur no extra delay from the presence of malleable jobs.
- Cluster-wide resource utilization remains at the same level as without malleability.
- Some jobs experience longer queue waits as a side effect of dynamic process adjustment.
Where Pith is reading between the lines
- The replay technique could be reused to test other dynamic resource management methods such as job migration or power capping.
- Production clusters might first run limited log-replay pilots before enabling malleability cluster-wide.
- Comparing replay outcomes against pure simulation results would quantify how much additional realism the log replay supplies.
- Similar efficiency gains could appear on other systems whose workload traces show comparable job-size distributions.
Load-bearing premise
Replaying the workload logs faithfully reproduces the actual job arrival patterns, user behaviors, and cluster conditions on the target system.
What would settle it
Running the identical malleability policy on the same replayed logs but measuring no reduction near 27% in malleable workload time or an increase in baseline workload completion time would falsify the reported performance benefit.
Figures












read the original abstract
Dynamic Resource Management (DRM) techniques can be leveraged to maximize throughput and resource utilization in computational clusters. Although DRM has been extensively studied through analytical workloads and simulations, skepticism persists among end administrators and users regarding their feasibility under real-world conditions. To address this problem, we propose a novel methodology for validating DRM techniques, such as malleability, in realistic scenarios that reproduce actual cluster conditions of jobs and users by replaying workload logs on a High-performance Computing (HPC) infrastructure. Our methodology is capable of adapting the workload to the target cluster. We evaluate our methodology in a malleability-enabled 125-node partition of the Marenostrum 5 supercomputer. Our results validate the proposed method and assess the benefits of MPI malleability on a novel use case of a pioneer user of malleability (our "PhD Student"): parallel efficiency-aware malleability reduced a malleable workload time by 27% without delaying the baseline workload, although introducing queueing delays for individual jobs, but maintaining the resource utilization rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a methodology for validating dynamic resource management techniques such as MPI malleability by replaying real-world workload logs on actual HPC hardware, with workload adaptation to the target cluster. Evaluated on a 125-node malleability-enabled partition of Marenostrum 5, it claims that parallel efficiency-aware malleability reduces malleable workload completion time by 27% without delaying the baseline workload, while introducing queueing delays for some jobs but preserving overall resource utilization.
Significance. If the replay methodology accurately captures real conditions, this provides empirical evidence from production hardware that could help overcome administrator skepticism toward DRM techniques. The use of replayed logs on real infrastructure rather than pure simulation is a strength for credibility and reproducibility.
major comments (2)
- [Evaluation methodology] The central 27% reduction claim (abstract) depends on static log replay with fixed submission times reproducing actual cluster behavior. However, this does not model dynamic user responses where shortened job runtimes could prompt earlier follow-on submissions, potentially changing observed time savings, queueing delays, and utilization.
- [Abstract and evaluation] Support for the reported outcomes on Marenostrum 5 is limited by insufficient details on experimental setup, controls, statistical significance, and how the workload was adapted to the 125-node partition, as these are load-bearing for validating the malleability benefits.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make to improve clarity and completeness.
read point-by-point responses
-
Referee: [Evaluation methodology] The central 27% reduction claim (abstract) depends on static log replay with fixed submission times reproducing actual cluster behavior. However, this does not model dynamic user responses where shortened job runtimes could prompt earlier follow-on submissions, potentially changing observed time savings, queueing delays, and utilization.
Authors: Our methodology deliberately replays fixed submission times from production logs to reproduce observed cluster conditions on real hardware without introducing unverified assumptions about user behavior. Modeling dynamic responses (e.g., earlier follow-on submissions) would require additional user studies or behavioral models outside the scope of this hardware-validation-focused work. We will add a brief discussion of this limitation and its implications in the revised manuscript. revision: partial
-
Referee: [Abstract and evaluation] Support for the reported outcomes on Marenostrum 5 is limited by insufficient details on experimental setup, controls, statistical significance, and how the workload was adapted to the 125-node partition, as these are load-bearing for validating the malleability benefits.
Authors: We agree that additional details are required. In the revised manuscript we will expand the experimental setup section with explicit information on controls, the statistical methods used to assess significance of the reported 27% reduction, and the precise adaptation steps applied to the workload logs for the 125-node partition. revision: yes
Circularity Check
No circularity: empirical log-replay validation on real hardware
full rationale
The paper describes an empirical methodology that replays existing workload logs on a 125-node malleability-enabled partition of Marenostrum 5 to measure the effects of MPI malleability. The reported 27% reduction in malleable workload time is an observed outcome of the hardware experiment rather than a quantity derived from equations or fitted parameters. No mathematical derivation chain exists that reduces a claimed prediction back to its own inputs by construction, nor are there load-bearing self-citations, uniqueness theorems, or ansatzes that close on themselves. The evaluation is therefore self-contained against external benchmarks (real hardware runs) and receives a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Replaying workload logs on the target cluster accurately reproduces real-world conditions of jobs and users.
Reference graph
Works this paper leans on
-
[1]
H. Martínez, J. Tárraga, I. Medina, S. Barrachina, M. Castillo, J. Dopazo, E. S. Quintana-Ortí, A dynamic pipeline for RNA se- quencing on multicore processors, in: Proceedings of the 20th Eu- ropean MPI Users’ Group Meeting, EuroMPI ’13, Association for Computing Machinery, New York, NY, USA, 2013, pp. 235–240. doi:10.1145/2488551.2488581
-
[2]
doi:10.1007/s42514-024-00203-0
H.Zhong,X.Pan,Z.He,H.Wang,D.Huang,Z.Chen,GPUacceler- ationforDNAsequencealignmentalgorithmanditsapplication,CCF TransactionsonHighPerformanceComputing7(2)(2025)169–177. doi:10.1007/s42514-024-00203-0
-
[3]
B. Hess, C. Kutzner, D. van der Spoel, E. Lindahl, GROMACS 4: Algorithms for Highly Efficient, Load-Balanced, and Scalable MolecularSimulation,JournalofChemicalTheoryandComputation 4 (3) (2008) 435–447.doi:10.1021/ct700301q
-
[4]
M. Vázquez, G. Houzeaux, S. Koric, A. Artigues, J. Aguado-Sierra, R. Arís, D. Mira, H. Calmet, F. Cucchietti, H. Owen, A. Taha, E.D.Burness,J.M.Cela,M.Valero,Alya:Multiphysicsengineering simulation toward exascale, Journal of Computational Science 14 (2016) 15–27.doi:10.1016/j.jocs.2015.12.007
-
[5]
D. Caviedes-Voullième, M. Morales-Hernández, M. R. Norman, I. Özgen Xian, SERGHEI (SERGHEI-SWE) v1.0: a performance- portable high-performance parallel-computing shallow-water solver for hydrology and environmental hydraulics, Geoscientific Model Development16(3)(2023)977–1008.doi:10.5194/gmd-16-977-2023
-
[6]
R.Martínez-Cuenca,J.Luis-Gómez,S.Iserte,S.Chiva,OntheUseof DeepLearningandComputationalFluidDynamicsfortheEstimation of Uniform Momentum Source Components of Propellers, iScience 26 (2023) 1–14.doi:10.1016/j.isci.2023.108297
-
[7]
P.Rosciszewski,A.Krzywaniak,S.Iserte,K.Rojek,P.Gepner,Opti- mizing Throughput of Seq2Seq Model Training on the IPU Platform for AI-accelerated CFD Simulations, Future Generation Computer Systems 143 (2023) 149–162.doi:10.1016/j.future.2023.05.004
-
[8]
W.F.Godoy,P.Valero-Lara,K.Teranishi,P.Balaprakash,J.S.Vetter, LargeLanguageModelEvaluationforHigh-PerformanceComputing Software Development, Concurrency and Computation: Practice and Experience 36 (26) (2024) e8269.doi:10.1002/cpe.8269
-
[9]
H.-J. Bungartz, C. Riesinger, M. Schreiber, G. Snelting, A. Zwinkau, Invasive computing in HPC with X10, in: Proceedings of the third ACM SIGPLAN X10 Workshop, X10 ’13, ACM, New York, NY, USA, 2013, pp. 12–19.doi:10.1145/2481268.2481274
-
[10]
M. Garcia, J. Labarta, J. Corbalan, Hints to improve automatic load balancing with LeWI for hybrid applications, Journal of Parallel and Distributed Computing 74 (9) (2014) 2781–2794.doi:10.1016/j.jp dc.2014.05.004
-
[11]
V. Lopez, J. Criado, R. Peñacoba, R. Ferrer, X. Teruel, M. Garcia- Gasulla, An OpenMP Free Agent Threads Implementation, in: OpenMP: Enabling Massive Node-Level Parallelism: 17th Interna- tionalWorkshoponOpenMP,IWOMP2021,Bristol,UK,September 14–16,2021,Proceedings,Springer-Verlag,Berlin,Heidelberg,2021, pp. 211–225.doi:10.1007/978-3-030-85262-7_15
-
[12]
D. Huber, M. Streubel, I. Comprés, M. Schulz, M. Schreiber, H. Pritchard, Towards dynamic resource management with mpi ses- sions and pmix, in: Proceedings of the 29th European MPI Users’ Group Meeting, EuroMPI/USA ’22, Association for Computing Ma- chinery, New York, NY, USA, 2022, p. 57–67.doi:10.1145/3555819. 3555856
-
[13]
Iserte Agut, High-throughput Computation through Efficient Re- source Management, Ph.D
S. Iserte Agut, High-throughput Computation through Efficient Re- source Management, Ph.D. Thesis, Universitat Jaume I, accepted: 2018-12-05T10:00:25Z Publication Title: TDX (Tesis Doctorals en Xarxa) (Nov. 2018).doi:10.6035/14101.2018.176272
-
[14]
Martín, M.-C
G. Martín, M.-C. Marinescu, D. E. Singh, J. Carretero, FLEX-MPI: an MPI Extension for Supporting Dynamic Load Balancing on Het- erogeneousNon-dedicatedSystems,in:Euro-ParParallelProcessing, 2013, pp. 138–149
2013
-
[15]
R. Bhattarai, H. Pritchard, S. Ghafoor, Dynamic Resource Manage- ment for Elastic Scientific Workflows using PMIx, in: 2024 IEEE S. Iserte et al.:Preprint submitted to ElsevierPage 17 of 22 MPI Malleability Validation under HPC Conditions International Parallel and Distributed Processing Symposium Work- shops (IPDPSW), 2024.doi:10.1109/IPDPSW63119.2024.00131
-
[16]
S.Iserte,I.Martín-Álvarez,K.Rojek,J.I.Aliaga,M.Castillo,W.Fol- warska, A. J. Peña, Resource optimization with MPI process mal- leability for dynamic workloads in HPC clusters, Future Generation ComputerSystems(2025)107949doi:10.1016/j.future.2025.107949
-
[17]
R. Sudarsan, C. J. Ribbens, ReSHAPE: A Framework for Dynamic Resizing and Scheduling of Homogeneous Applications in a Parallel Environment, in: 2007 International Conference on Parallel Process- ing (ICPP 2007), 2007, pp. 44–44.doi:10.1109/ICPP.2007.73
-
[18]
O. Sarood, A. Langer, A. Gupta, L. Kale, Maximizing throughput of overprovisioned HPC data centers under a strict power budget, in: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’14, IEEE Press, NewOrleans,Louisana,2014,pp.807–818.doi:10.1109/SC.2014.71
-
[19]
Prabhakaran, M
S. Prabhakaran, M. Neumann, S. Rinke, F. Wolf, A. Gupta, L. V. Kale, A Batch System with Efficient Adaptive Scheduling for Mal- leable and Evolving Applications, in: Proceedings of the 2015 IEEE InternationalParallelandDistributedProcessingSymposium,IPDPS ’15,IEEEComputerSociety,USA,2015,pp.429–438.doi:10.1109/ IPDPS.2015.34
2015
-
[20]
Consciousness and Cognition20(2011) https://doi.org/10.1016/j
S. Iserte, R. Mayo, E. S. Quintana-Ortí, V. Beltran, A. J. Peña, DMR API: Improving Cluster Productivity by Turning Applications into Malleable, Parallel Computing 78 (2018) 54–66.doi:10.1016/j. parco.2018.07.006
work page doi:10.1016/j 2018
-
[21]
R. Sudarsan, C. J. Ribbens, D. Farkas, Dynamic Resizing of Parallel Scientific Simulations: A Case Study Using LAMMPS, in: Proceed- ings of the 9th International Conference on Computational Science: PartI,ICCS’09,Springer-Verlag,Berlin,Heidelberg,2009,pp.175– 184.doi:10.1007/978-3-642-01970-8_18
-
[22]
A Study of the Effect of Process MalleabilityintheEnergyEfficiencyonGPU-basedClusters
S. Iserte, K. Rojek, A Study of the Effect of Process Malleability in the Energy Efficiency on GPU-based Clusters, Journal of Supercom- puting 76 (2020) 255–274.doi:10.1007/s11227-019-03034-x
-
[23]
Dynamic reconfiguration of noniterative scientific applications: A case study with HPG aligner
S. Iserte, H. Martínez, S. Barrachina, M. Castillo, R. Mayo, A. J. Peña,Dynamicreconfigurationofnoniterativescientificapplications: A case study with HPG aligner, The International Journal of High Performance Computing Applications 33 (5) (2019) 804–816.doi: 10.1177/1094342018802347
-
[24]
N. Zakay, D. G. Feitelson, Preserving User Behavior Characteristics inTrace-BasedSimulationofParallelJobScheduling,in:2014IEEE 22ndInternationalSymposiumonModelling,Analysis&Simulation ofComputerandTelecommunicationSystems,2014,pp.51–60.doi: 10.1109/MASCOTS.2014.15
-
[25]
S. Schlagkamp, Influence of Dynamic Think Times on Parallel Job Scheduler Performances in Generative Simulations, in: 3rd confer- ence on Networked Systems Design & Implementation, 2017.doi: 10.1007/978-3-319-61756-5_7
-
[26]
B.Schroeder,A.Wierman,M.Harchol-Balter,Openversusclosed:a cautionary tale, in: Proceedings of the 3rd conference on Networked Systems Design & Implementation - Volume 3, NSDI’06, USENIX Association, USA, 2006, p. 18
2006
-
[27]
N.Zakay,D.G.Feitelson,OnIdentifyingUserSessionBoundariesin Parallel Workload Logs, in: Workshop on Job Scheduling Strategies for Parallel Processing, 2013.doi:10.1007/978-3-642-35867-8_12
-
[28]
M. Madon, G. Da Costa, J.-M. Pierson, Replay with Feedback: : How does the performance of HPC system impact user submission behavior?, Future Generation Computer Systems 155 (C) (2024) 66– 79.doi:10.1016/j.future.2024.01.024
-
[29]
D. G. Feitelson, Resampling with Feedback: A New Paradigm of Using Workload Data for Performance Evaluation, in: Workshop on Job Scheduling Strategies for Parallel Processing, 2021.doi:10.100 7/978-3-030-88224-2_1
2021
-
[30]
D. G. Feitelson, Packing Schemes for Gang Scheduling, in: Pro- ceedings of the Workshop on Job Scheduling Strategies for Parallel Processing, IPPS ’96, Springer-Verlag, Berlin, Heidelberg, 1996, pp. 89–110
1996
-
[31]
U.Lublin,D.G.Feitelson,Theworkloadonparallelsupercomputers: modeling the characteristics of rigid jobs, Journal of Parallel and Distributed Computing 63 (11) (2003) 1105–1122.doi:10.1016/S074 3-7315(03)00108-4
-
[32]
J. I. Aliaga, M. Castillo, S. Iserte, I. Martín-Álvarez, R. Mayo, A Survey on Malleability Solutions for High-Performance Distributed Computing, Applied Science 12 (2022) 1–32.doi:10.3390/app12105 231
-
[33]
A.Tarraf,M.Schreiber,A.Cascajo,J.-B.Besnard,M.-A.Vef,D.Hu- ber, S. Happ, A. Brinkmann, D. E. Singh, H.-C. Hoppe, A. Miranda, A. J. Peña, R. Machado, M. G. Gasulla, M. Schulz, P. Carpenter, S. Pickartz, T. Rotaru, S. Iserte, V. Lopez, J. Ejarque, H. Sirwani, F.Wolf,MalleabilityinModernHPCSystems:CurrentExperiences, Challenges, and Future Opportunities, IEE...
- [34]
-
[35]
D.G.Feitelson,L.Rudolph,TowardsConvergenceinJobSchedulers forParallelSupercomputers,in:ProceedingsoftheWorkshoponJob Scheduling Strategies for Parallel Processing, IPPS ’96, Springer- Verlag, Berlin, Heidelberg, 1996, pp. 1–26
1996
-
[36]
S.Iserte,G.Houzeaux,P.Sandås,A.J.Peña,M.Garcia-Gasulla,Mal- leable Computational Fluid Dynamics Simulations, in: Proceedings of the 36th Parallel CFD International Conference, Merida, Yucatan, Mexico, 2025
2025
-
[37]
2024).doi:10.1007/s11227-024 -06277-5
I.Martín-Álvarez,J.I.Aliaga,M.Castillo,S.Iserte,Proteo:aframe- workforthegenerationandevaluationofmalleableMPIapplications, The Journal of Supercomputing (Jul. 2024).doi:10.1007/s11227-024 -06277-5
-
[38]
D.Huber,S.Iserte,M.Schreiber,A.J.Peña,M.Schulz,Bridgingthe GapBetweenGenericityandProgrammabilityofDynamicResources inHPC,in:ISCHighPerformance2025ResearchPaperProceedings (40th International Conference), 2025, pp. 1–11
2025
-
[39]
S. Iserte, I. Martín-Álvarez, K. Rojek, J. I. Aliaga, M. Castillo, A. J. Peña, Towards the Democratization and Standardization of Dynamic Resources with MPI Spawning, in: R. Wyrzykowski, J. Dongarra, E. Deelman, K. Karczewski (Eds.), Parallel Processing and Applied Mathematics, Springer Nature Switzerland, Cham, 2025, pp. 287– 300.doi:10.1007/978-3-031-85697-6_19
-
[40]
In: Proceedings of PER- MAVOST (2021)
V. Lopez, G. Ramirez Miranda, M. Garcia-Gasulla, TALP: A Lightweight Tool to Unveil Parallel Efficiency of Large-scale Exe- cutions, in: Proceedings of the 2021 on Performance EngineeRing, Modelling,Analysis,andVisualizatiOnSTrategy,PERMAVOST’21, Association for Computing Machinery, New York, NY, USA, 2021, pp. 3–10.doi:10.1145/3452412.3462753
-
[41]
succesful execution
K. Rojek, , R. Wyrzykowski, Parallelization of 3D MPDATA Al- gorithm Using Many Graphics Processors, in: Proceedings of the 13th International Conference on Parallel Computing Technologies - Volume 9251, Guide Proceedings, 2015, pp. 445–457.doi:10.100 7/978-3-319-21909-7_43. S. Iserte et al.:Preprint submitted to ElsevierPage 18 of 22 Appendix: Artifact D...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.