Recognition: unknown
Meta-learning-enhanced implicit full waveform inversion
Pith reviewed 2026-05-07 08:54 UTC · model grok-4.3
The pith
Meta-learning lets an implicit neural network adapt to new seismic inversion tasks after pretraining on several velocity models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
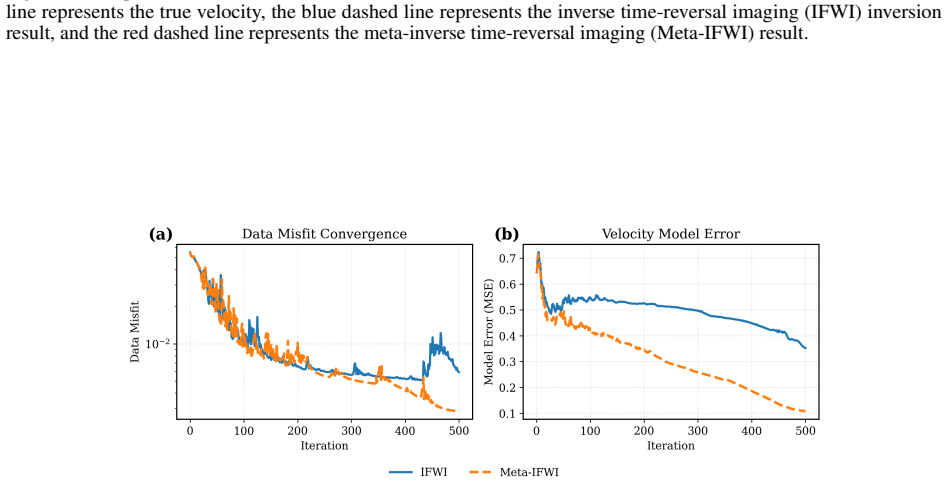
By pretraining a single implicit neural network with periodic activations on multiple velocity-inversion tasks, the network learns shared inversion priors and rapid adaptation strategies; for any new task the pretrained network can be fine-tuned to the observed seismic data with only a few gradient updates, yielding improved accuracy, faster convergence, and stronger cross-area generalization than conventional implicit full waveform inversion.
What carries the argument
A meta-learning strategy applied to an implicit neural network with periodic activation functions that parameterizes the subsurface velocity model as a continuous function of spatial coordinates, enabling the network to acquire task-shared priors during pretraining.
If this is right
- Inversion accuracy improves on both in-distribution models such as layered synthetics and the Overthrust model and on out-of-distribution models such as Marmousi 2.
- Convergence occurs in substantially fewer iterations than conventional implicit full waveform inversion.
- Computational cost per inversion task decreases because fewer gradient updates are required after pretraining.
- The method shows greater robustness and stronger generalization across different geological areas.
Where Pith is reading between the lines
- The same meta-learning pattern could be tested on other inverse problems in geophysics that currently optimize a separate model for each data set.
- If the learned priors remain effective on real data, field workflows might shift from building custom initial models to light adaptation of a shared meta-network.
- Extending the pretraining distribution to include more varied synthetic and field-derived models would test how far the generalization benefit can be pushed.
Load-bearing premise
Priors learned from a limited collection of synthetic velocity models will transfer to real field data and to geological structures substantially different from the training set without large loss of performance.
What would settle it
Apply the pretrained Meta-IFWI network to a real field seismic dataset from a previously unseen geological province and compare the final model misfit and iteration count against a standard implicit inversion run from the same starting point.
Figures








read the original abstract
Implicit full waveform inversion (IFWI) introduces implicit neural representations to parameterize the subsurface velocity model as a continuous function of spatial coordinates, which alleviates the dependence on the initial model and improves inversion flexibility. However, IFWI still requires a large number of iterative updates for each new exploration area, leading to slow convergence, high computational cost, and a lack of mechanisms to share prior knowledge across different geological settings, thereby limiting its efficiency and generalization capability. To further accelerate convergence and enhance cross-area generalization, we propose a meta-learning-based implicit full waveform inversion method, referred to as Meta-learning-enhanced implicit full waveform inversion (Meta-IFWI). In this framework, the subsurface velocity model is represented using an implicit neural network with periodic activation functions (SIREN), while a meta-learning strategy is employed to pretrain a single network on multiple velocity inversion tasks. Through this process, the network learns shared inversion priors and rapid adaptation strategies across different geological scenarios. For a new inversion task, the pretrained Meta-IFWI model can be efficiently adapted to the observed seismic data with only a few gradient updates, significantly reducing the number of iterations required for inversion. Numerical experiments conducted on in-distribution models, including layered synthetic models and the Overthrust model, as well as out-of-distribution complex models such as Marmousi 2, demonstrate that, compared with conventional IFWI, the proposed Meta-IFWI achieves improved inversion accuracy while substantially accelerating convergence and reducing computational cost. Moreover, Meta-IFWI exhibits enhanced robustness and stronger cross-area generalization capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Meta-IFWI, which parameterizes the subsurface velocity model via a SIREN implicit neural network and uses meta-learning to pretrain the network across multiple synthetic velocity inversion tasks. This allows the model to learn shared priors and rapid adaptation strategies, so that a new task can be solved with only a few gradient updates. Numerical experiments on in-distribution models (layered synthetics, Overthrust) and an out-of-distribution model (Marmousi 2) are presented to claim higher accuracy, faster convergence, lower computational cost, and stronger cross-area generalization relative to conventional IFWI.
Significance. If the experimental claims are substantiated, the work would constitute a useful advance in accelerating full-waveform inversion by transferring meta-learned priors across geological settings. The combination of implicit representations with meta-learning is timely, and the explicit out-of-distribution test on Marmousi 2 provides a concrete check on generalization within the synthetic regime. The approach directly addresses the per-task optimization burden that currently limits IFWI scalability.
major comments (2)
- [Numerical Experiments] Numerical Experiments section: the central claims of improved accuracy, substantially accelerated convergence, and reduced cost are not supported by any tabulated quantitative metrics (e.g., RMSE or SSIM of the recovered velocity models, or iteration counts to reach a target misfit). Without these numbers the magnitude of the reported gains cannot be assessed and the comparison to conventional IFWI remains qualitative.
- [Method] Method section: the meta-training protocol (number of tasks, distribution of training velocity models, inner-loop adaptation steps, and meta-optimizer hyperparameters) is described only at a high level. These quantities are load-bearing for the rapid-adaptation claim; their omission prevents reproduction and makes it impossible to judge whether the reported performance is robust or sensitive to the particular meta-training choices.
minor comments (2)
- [Abstract] Abstract: the summary paragraph would be strengthened by inserting at least one concrete quantitative result (e.g., “reduces iterations by a factor of X on the Overthrust model”) to anchor the qualitative claims.
- [Figures] Figure captions: several captions are terse and do not state the inversion parameters or the number of meta-adaptation steps used for the displayed results, reducing clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for improvement in substantiating our claims and ensuring reproducibility. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Numerical Experiments] Numerical Experiments section: the central claims of improved accuracy, substantially accelerated convergence, and reduced cost are not supported by any tabulated quantitative metrics (e.g., RMSE or SSIM of the recovered velocity models, or iteration counts to reach a target misfit). Without these numbers the magnitude of the reported gains cannot be assessed and the comparison to conventional IFWI remains qualitative.
Authors: We agree that the absence of tabulated quantitative metrics leaves the magnitude of the improvements qualitative. In the revised manuscript we have added a new table (Table 2) in the Numerical Experiments section reporting RMSE and SSIM values for all recovered velocity models (layered synthetics, Overthrust, and Marmousi 2) for both Meta-IFWI and conventional IFWI. We have also included a supplementary table listing the iteration counts required to reach successive misfit thresholds (e.g., 10^{-3} and 10^{-4}) together with wall-clock times. These additions provide direct numerical evidence for the claimed gains in accuracy, convergence speed, and computational cost. revision: yes
-
Referee: [Method] Method section: the meta-training protocol (number of tasks, distribution of training velocity models, inner-loop adaptation steps, and meta-optimizer hyperparameters) is described only at a high level. These quantities are load-bearing for the rapid-adaptation claim; their omission prevents reproduction and makes it impossible to judge whether the reported performance is robust or sensitive to the particular meta-training choices.
Authors: We acknowledge that the meta-training protocol was presented at an insufficient level of detail. The revised Method section now contains a new subsection (Section 3.3) that explicitly states: (i) the number of meta-training tasks (50), (ii) the sampling distribution used to generate the training velocity models (randomized layered and faulted models with velocity ranges 1500–4500 m/s), (iii) the inner-loop adaptation steps (5 steps per task), and (iv) the meta-optimizer hyperparameters (MAML with Adam, outer-loop learning rate 1e-4, inner-loop learning rate 1e-3). These specifications enable full reproduction and allow readers to evaluate sensitivity to the chosen protocol. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical meta-learning procedure that pretrains a SIREN-based implicit network across multiple synthetic velocity inversion tasks and then adapts the network to new tasks with few gradient steps. The central claims rest on direct numerical comparisons (accuracy, convergence speed, cost, robustness) between Meta-IFWI and standard IFWI on listed synthetic benchmarks (layered models, Overthrust in-distribution; Marmousi 2 out-of-distribution). No equations or derivations are presented that reduce to their own inputs by construction, no uniqueness theorems are imported via self-citation, and no fitted quantities are relabeled as predictions. The reported gains are therefore falsifiable experimental outcomes rather than tautological restatements of the training procedure.
Axiom & Free-Parameter Ledger
free parameters (1)
- Meta-training task count and inner-loop adaptation steps
axioms (1)
- domain assumption Implicit neural representations with periodic activations can accurately parameterize subsurface velocity models as continuous functions.
Reference graph
Works this paper leans on
-
[1]
A strategy for nonlinear elastic inversion of seismic reflection data.Geophysics, 51(10):1893–1903,
Albert Tarantola. A strategy for nonlinear elastic inversion of seismic reflection data.Geophysics, 51(10):1893–1903,
1903
-
[2]
Implicit full waveform inversion with energy-weighted gradient
S Wang and T Alkhalifah. Implicit full waveform inversion with energy-weighted gradient. In86th EAGE Annual Conference & Exhibition, volume 2025, pages 1–5. European Association of Geoscientists & Engineers,
2025
-
[3]
16 Meta-learning-enhanced implicit full waveform inversionA PREPRINT Diederik P Kingma and Jimmy Ba
URLhttps://doi.org/10.5281/zenodo.3829886. 16 Meta-learning-enhanced implicit full waveform inversionA PREPRINT Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
-
[4]
On First-Order Meta-Learning Algorithms
Alex Nichol and John Schulman. Reptile: a scalable metalearning algorithm.arXiv preprint arXiv:1803.02999, 2(3):4,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.