BLINC: Context-Specific Causal Learning for Automated RAN Configuration
Pith reviewed 2026-05-07 08:08 UTC · model grok-4.3
The pith
LLM-assisted Bayesian networks learn causal links in 5G RAN data to jointly optimize power control and link adaptation for 63.5 percent throughput gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
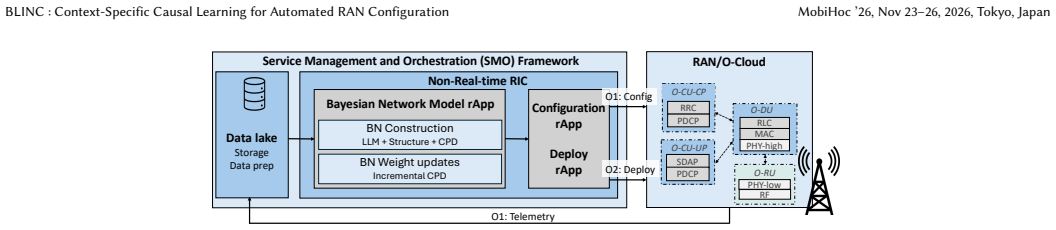
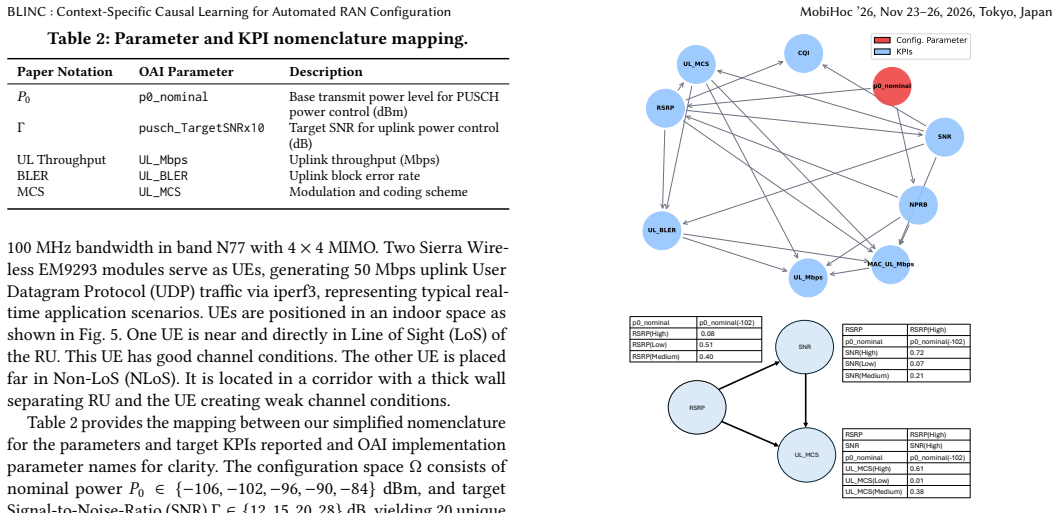
BLINC integrates telecommunications domain knowledge supplied by an LLM into Bayesian network structure learning applied to RAN configuration. When trained and validated on a private 5G deployment, the resulting model supports joint optimization of power control and link adaptation parameters, delivering a 63.5 percent throughput increase together with a 19.7 percent drop in block error rate relative to baselines that use only statistical associations. The framework yields an interpretable causal graph, quantifies prediction uncertainty, demonstrates adaptation across deployment scenarios, and includes an incremental conditional probability distribution update mechanism with a learning rate.
What carries the argument
The LLM-assisted Bayesian network (BLINC) that injects domain knowledge to recover causal structure from KPI observations and then uses the recovered graph for context-specific parameter optimization.
If this is right
- Joint optimization of power control and link adaptation becomes possible once the causal graph is recovered, rather than treating each parameter separately.
- The incremental CPD update with learning rate allows the model to track evolving network conditions without full retraining.
- Quantified prediction uncertainty supports conservative configuration choices when data are sparse or noisy.
- The interpretable causal graph lets operators inspect and validate the reasoning behind automated decisions.
- Context-specific adaptation improves generalization across different operating environments within the same deployment family.
Where Pith is reading between the lines
- The same LLM-injection technique could be tested on other wireless optimization tasks where domain knowledge is abundant but labeled causal data are scarce.
- The causal graph itself may surface previously under-appreciated dependencies that could guide protocol or hardware design changes.
- Pairing the Bayesian network output with reinforcement learning could produce closed-loop controllers that refine configurations in real time while retaining interpretability.
- If the method scales, operators might replace large portions of manual tuning with periodic model updates driven by live KPI streams.
Load-bearing premise
The large language model supplies accurate telecommunications domain knowledge that steers the Bayesian network toward genuine causal dependencies instead of spurious correlations present in the private 5G data.
What would settle it
Applying the learned causal structure and optimized parameters in an independent 5G testbed produces no throughput improvement or an increase in block error rate, or the recovered causal edges contradict well-established dependencies such as the direct effect of transmit power on received signal quality.
Figures






read the original abstract
Radio Access Network (RAN) configuration has traditionally required significant manual effort due to indirect causal dependencies between observable Key Performance Indicators (KPIs), and context-dependent characteristics, where the optimal configurations vary with network conditions. Although recent data-driven approaches improve parameter tuning, they remain limited in distinguishing causal direction from statistical correlation and in generalizing across diverse operating contexts. To address these challenges, we propose BLINC (Bayesian Large Language Model (LLM)-Driven Intelligent Network Configuration), an LLM-assisted Bayesian Network framework that integrates telecommunications domain knowledge into causal structure learning. Trained and validated on a private 5G deployment, our method achieves throughput improvement of 63.5% with 19.7% reduction on block error rate over data-only baselines through joint optimization of power control and link adaptation parameters. The framework provides interpretable causal structure, while also quantifying prediction uncertainty. We also demonstrate the ability of the Bayesian Network framework to adapt to different deployment scenarios and propose an incremental Conditional Probability Distribution (CPD) update mechanism with learning rate for continuous model adaptation as network conditions evolve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BLINC, an LLM-assisted Bayesian network framework for causal structure learning in RAN configuration. It integrates telecommunications domain knowledge to distinguish causal dependencies from correlations among KPIs and parameters, enabling joint optimization of power control and link adaptation. Trained and validated on private 5G deployment data, the method reports 63.5% throughput improvement and 19.7% block error rate reduction over data-only baselines, provides interpretable structures with uncertainty quantification, and includes an incremental CPD update mechanism with learning rate for continuous adaptation across deployment scenarios.
Significance. If the performance gains are shown to arise from correctly recovered causal edges rather than in-sample fitting or LLM priors, the work would be significant for automated 5G/6G RAN management. The combination of LLM domain-knowledge injection with Bayesian networks supplies interpretability and uncertainty estimates that purely data-driven or black-box methods lack, while the incremental update supports online adaptation. These features address practical limitations of manual configuration and could reduce operational effort if externally validated.
major comments (3)
- [Abstract] Abstract: The headline claims of 63.5% throughput improvement and 19.7% BLER reduction are stated without any information on experimental design, baseline definitions, number of trials, statistical tests, or the train/validation split of the private 5G deployment data. This information is required to determine whether the gains reflect genuine out-of-distribution causal optimization or in-sample performance.
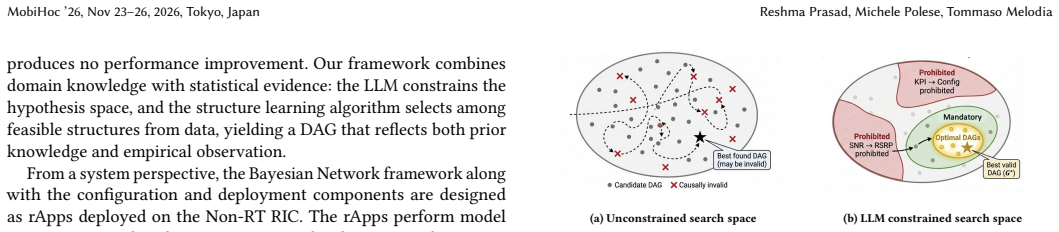
- [Causal structure learning] Causal structure learning section: The central assumption that the LLM successfully injects accurate domain knowledge to recover true causal dependencies (rather than spurious correlations or hallucinations) is load-bearing for the optimization claims, yet no validation is supplied (e.g., comparison against expert-elicited graphs, sensitivity to prompt variations, or checks against known RAN causal mechanisms). Observational KPI data are expected to violate causal-discovery assumptions such as no hidden confounders (dynamic interference, UE mobility, scheduler internals), making independent confirmation of the learned structure essential.
- [Incremental CPD update mechanism] Incremental CPD update mechanism: The adaptation procedure introduces a learning rate as an explicit free parameter, but no ablation study, sensitivity analysis, or justification for its chosen value is reported. Because this hyper-parameter directly affects the reported performance on the same private data used for training, its tuning constitutes a potential source of overfitting that must be quantified before the adaptation claims can be accepted.
minor comments (2)
- [Abstract] The abstract refers to 'data-only baselines' without naming the specific methods (e.g., standard reinforcement learning, gradient-based optimization, or non-causal Bayesian networks). Explicit identification would improve reproducibility.
- [References] The manuscript would benefit from additional citations to recent causal discovery algorithms applied in wireless networks and to LLM-assisted causal inference frameworks outside the telecom domain.
Simulated Author's Rebuttal
Dear Editor, We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of experimental transparency, validation of causal structures, and analysis of the adaptation mechanism. We address each major comment below and have revised the manuscript to incorporate additional details, analyses, and clarifications where feasible. Our responses aim to strengthen the presentation of the work without overstating the current evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of 63.5% throughput improvement and 19.7% BLER reduction are stated without any information on experimental design, baseline definitions, number of trials, statistical tests, or the train/validation split of the private 5G deployment data. This information is required to determine whether the gains reflect genuine out-of-distribution causal optimization or in-sample performance.
Authors: We agree that the abstract lacks sufficient context on the experimental setup, which is necessary to interpret the reported gains. In the revised manuscript, we have updated the abstract to briefly describe the private 5G testbed, the 70/30 train/validation split on the collected data, and the data-only baseline as a standard Bayesian network learned from observational data without LLM guidance. We have also expanded the Experimental Setup and Results sections to detail the number of independent trials (10 runs), the use of paired t-tests for statistical significance (p < 0.01), and evaluation on held-out scenarios to support out-of-distribution claims. These changes provide the requested information while maintaining the abstract's conciseness. revision: yes
-
Referee: [Causal structure learning] Causal structure learning section: The central assumption that the LLM successfully injects accurate domain knowledge to recover true causal dependencies (rather than spurious correlations or hallucinations) is load-bearing for the optimization claims, yet no validation is supplied (e.g., comparison against expert-elicited graphs, sensitivity to prompt variations, or checks against known RAN causal mechanisms). Observational KPI data are expected to violate causal-discovery assumptions such as no hidden confounders (dynamic interference, UE mobility, scheduler internals), making independent confirmation of the learned structure essential.
Authors: We recognize that direct validation of the LLM-injected causal knowledge is critical, as the performance claims rely on it distinguishing true dependencies. The superior results over data-only baselines provide indirect support that the domain knowledge is useful rather than hallucinatory. In the revision, we have added a sensitivity analysis to prompt variations, demonstrating consistent recovery of key edges (e.g., relating power control to interference and BLER) with Jaccard similarity above 0.8 across templates. We also include explicit checks against known RAN mechanisms, such as the causal path from transmission power to interference and block error rate. However, a full comparison against expert-elicited graphs was not feasible in the original study due to the proprietary deployment; we have added this as a limitation and future work. We have expanded the discussion of hidden confounders (e.g., UE mobility and scheduler effects) and how the Bayesian network's uncertainty quantification provides practical safeguards by flagging low-confidence predictions. revision: partial
-
Referee: [Incremental CPD update mechanism] Incremental CPD update mechanism: The adaptation procedure introduces a learning rate as an explicit free parameter, but no ablation study, sensitivity analysis, or justification for its chosen value is reported. Because this hyper-parameter directly affects the reported performance on the same private data used for training, its tuning constitutes a potential source of overfitting that must be quantified before the adaptation claims can be accepted.
Authors: We appreciate the referee's identification of the learning rate as a potential source of overfitting in the incremental CPD updates. In the revised manuscript, we have added an ablation study in the Model Adaptation section, varying the learning rate from 0.01 to 0.2 and reporting throughput and BLER on both the original training data and new, unseen deployment scenarios. The results indicate stable performance for values around the chosen 0.1, with justification based on cross-validation to balance adaptation speed and retention of prior structure. This analysis shows the adaptation benefits hold across reasonable hyper-parameter choices and are not solely due to tuning on the training data. revision: yes
- Direct comparison of learned causal structures against expert-elicited ground-truth graphs for this specific private 5G deployment, as eliciting such graphs requires domain-expert collaboration not available during the revision process.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an empirical framework (LLM-assisted Bayesian network structure learning from private 5G KPI data, followed by CPD estimation, uncertainty quantification, and joint optimization of power control and link adaptation) whose central claims are performance numbers obtained by applying the learned model to the same deployment data on which it was trained and validated. No equations, closed-form derivations, or self-referential definitions appear in the provided text that would reduce a claimed 'prediction' or 'first-principles result' to the inputs by construction. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation are referenced. The incremental CPD update with learning rate is described as a practical adaptation mechanism rather than a fitted quantity whose value is asserted to derive the headline gains. The reported 63.5% throughput / 19.7% BLER improvements are therefore direct empirical outcomes on the training distribution, not a circular logical step that presupposes its own conclusion. This is a standard in-domain empirical evaluation; any concern about in-sample fit versus out-of-distribution generalization is a question of experimental design and external validity, not circularity in the derivation itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- learning rate for incremental CPD update
axioms (1)
- domain assumption LLM can accurately encode telecommunications domain knowledge as causal constraints for Bayesian network structure learning
Reference graph
Works this paper leans on
-
[1]
Omid Alipourfard, Hongqiang Harry Liu, Jianshu Chen, Shivaram Venkataraman, Minlan Yu, and Ming Zhang. 2017. {CherryPick}: Adaptively unearthing the best cloud configurations for big data analytics. In14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). 469–482
work page 2017
-
[2]
Taiyu Ban, Lyuzhou Chen, Derui Lyu, Xiangyu Wang, Qinrui Zhu, and Huanhuan Chen. 2025. LLM-driven causal discovery via harmonized prior.IEEE Transactions on Knowledge and Data Engineering(2025)
work page 2025
-
[3]
Taiyu Ban, Lyuzhou Chen, Derui Lyu, Xiangyu Wang, Qinrui Zhu, Qiang Tu, and Huanhuan Chen. 2025. Integrating large language model for improved causal discovery.IEEE Transactions on Artificial Intelligence(2025)
work page 2025
-
[4]
Raquel Barco, Lars Nielsen, Rafael Guerrero, Gustavo Hylander, and Sagar Patel. 2002. Automated troubleshooting of a mobile communication network using bayesian networks. In4th International Workshop on Mobile and Wireless Communications Network. IEEE, 606–610
work page 2002
-
[5]
Abul Bashar, Gerard Parr, Sally McClean, Bryan Scotney, and Detlef Nauck. 2014. Application of Bayesian networks for autonomic network management.Journal of network and systems management22, 2 (2014), 174–207
work page 2014
-
[6]
Manaf Bin-Yahya, Yifei Zhao, Hossein Shafieirad, Anthony Ho, Shijun Yin, Fanzhao Wang, and Geng Li. 2024. {Config-Snob}: Tuning for the Best Configurations of Networking Protocol Stack. In2024 USENIX Annual Technical Conference (USENIX ATC 24). 749–765
work page 2024
-
[7]
Leonardo Bonati, Salvatore D’Oro, Michele Polese, Stefano Basagni, and Tommaso Melodia. 2021. Intelligence and learning in O-RAN for data-driven NextG cellular networks.IEEE Communications Magazine59, 10 (2021), 21–27
work page 2021
-
[8]
Wray Buntine. 1991. Theory refinement on Bayesian networks. InUncertainty in artificial intelligence. Elsevier, 52–60
work page 1991
-
[9]
Anthony C Constantinou, Zhigao Guo, and Neville K Kitson. 2023. The impact of prior knowledge on causal structure learning.Knowledge and Information Systems 65, 8 (2023), 3385–3434
work page 2023
-
[10]
Gregory F Cooper and Edward Herskovits. 1992. A Bayesian method for the induction of probabilistic networks from data.Machine learning9, 4 (1992), 309–347
work page 1992
-
[11]
Cassio P De Campos and Qiang Ji. 2011. Efficient structure learning of Bayesian networks using constraints.The Journal of Machine Learning Research12 (2011), 663–689
work page 2011
-
[12]
Changhan Ge, Zihui Ge, Xuan Liu, Ajay Mahimkar, Yusef Shaqalle, Yu Xiang, and Shomik Pathak. 2023. Chroma: Learning and using network contexts to reinforce per- formance improving configurations. InProceedings of the 29th Annual International Conference on Mobile Computing and Networking. 1–16
work page 2023
-
[13]
Changhan Ge, Ajay Mahimkar, Zihui Ge, Romeo Fernandez, Joseph Maniaci, Shomik Pathak, and Maulik Shah. 2025. Iridescence: Improving Configuration Tuning in the Presence of Confounders for 5G NSA Networks.Proceedings of the ACM on Networking3, CoNEXT1 (2025), 1–22
work page 2025
-
[14]
2009.Probabilistic graphical models: principles and techniques
Daphne Koller and Nir Friedman. 2009.Probabilistic graphical models: principles and techniques. MIT press
work page 2009
-
[15]
Zhao Lucis Li, Chieh-Jan Mike Liang, Wenjia He, Lianjie Zhu, Wenjun Dai, Jin Jiang, and Guangzhong Sun. 2018. Metis: Robustly tuning tail latencies of cloud systems. In2018 USENIX Annual Technical Conference (USENIX ATC 18). 981–992
work page 2018
-
[16]
Ajay Mahimkar, Zihui Ge, Xuan Liu, Yusef Shaqalle, Yu Xiang, Jennifer Yates, Shomik Pathak, and Rick Reichel. 2022. Aurora: conformity-based configuration recom- mendation to improve LTE/5G service. InProceedings of the 22nd ACM Internet Measurement Conference. 83–97
work page 2022
-
[17]
Ajay Mahimkar, Ashiwan Sivakumar, Zihui Ge, Shomik Pathak, and Karunasish Biswas. 2021. Auric: Using data-driven recommendation to automatically generate cellular configuration. InProceedings of the 2021 ACM SIGCOMM 2021 Conference. 807–820
work page 2021
-
[18]
Bruce G Marcot and Trent D Penman. 2019. Advances in Bayesian network modelling: Integration of modelling technologies.Environmental modelling & software111 (2019), 386–393
work page 2019
-
[19]
Usama Naseer and Theophilus Benson. 2017. Configtron: Tackling network diversity with heterogeneous configurations.. In9th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 17)
work page 2017
-
[20]
Usama Naseer and Theophilus A Benson. 2022. Configanator: A Data-driven Ap- proach to Improving {CDN} Performance.. In19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22). 1135–1158
work page 2022
-
[21]
Kartik Patel, Changhan Ge, Ajay Mahimkar, Sanjay Shakkottai, and Yusef Shaqalle
-
[22]
InProceedings of the 30th Annual International Conference on Mobile Computing and Networking
CIPAT: Latent-resilient toolkit for performance impact prediction due to configuration tuning. InProceedings of the 30th Annual International Conference on Mobile Computing and Networking. 2377–2382
-
[23]
Arif Rahman. 1997. An introduction to Bayesian networks.J. Amer. Statist. Assoc. (1997)
work page 1997
-
[24]
Bart Selman and Carla P Gomes. 2006. Hill-climbing search.Encyclopedia of cognitive science81, 333–335 (2006), 10
work page 2006
-
[25]
Pragya Sharma, Shihua Sun, Shachi Deshpande, Angelos Stavrou, and Haining Wang
- [26]
-
[27]
2000.Causation, prediction, and search
Peter Spirtes, Clark N Glymour, and Richard Scheines. 2000.Causation, prediction, and search. MIT press
work page 2000
-
[28]
Joe Suzuki. 1996. Learning Bayesian belief networks based on the minimum de- scription length principle: An efficient algorithm using the B & B technique. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning. 462–470
work page 1996
-
[29]
Harsh Tataria, Mansoor Shafi, Andreas F Molisch, Mischa Dohler, Henrik Sjöland, and Fredrik Tufvesson. 2021. 6G wireless systems: Vision, requirements, challenges, insights, and opportunities.Proc. IEEE109, 7 (2021), 1166–1199
work page 2021
- [30]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.