Recognition: unknown
UniBCI: Towards a Unified Pretrained Model for Invasive Brain-Computer Interfaces
Pith reviewed 2026-05-09 20:32 UTC · model grok-4.3
The pith
A single pretrained model learns generalizable representations from diverse invasive neural recordings and outperforms specialized models on BCI tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniBCI integrates context-conditioned spatio-temporal tokenization to embed neural signals with metadata, hierarchical Interval-Area Attention to model spike dynamics via linear attention and locality via sliding windows, and a scalable self-supervised masked signals reconstruction objective. When pretrained on a large corpus of standardized heterogeneous recordings spanning multiple species, subjects, brain regions, and paradigms, the resulting representations transfer to achieve state-of-the-art performance on diverse invasive BCI downstream tasks while using fewer trainable parameters and lower inference latency.
What carries the argument
The context-conditioned spatio-temporal tokenization (CST) scheme together with hierarchical Interval-Area Attention (IAA) that jointly embed signals and metadata into a shared space and capture both long-range spike patterns and local dependencies.
If this is right
- A pretrained model reduces the volume of labeled data required for new BCI applications by leveraging representations learned from unlabeled heterogeneous sources.
- Cross-species and cross-region transfer becomes feasible, allowing models trained on one brain area or animal to initialize decoders for another.
- Efficiency improvements in parameter count and latency support deployment in resource-constrained or real-time BCI settings.
- Self-supervised pretraining on spikes provides a scalable way to incorporate growing archives of invasive recordings without task-specific labeling.
Where Pith is reading between the lines
- The same standardization steps could be tested on non-invasive signals such as EEG to check whether one architecture serves both invasive and scalp recordings.
- If the learned representations capture shared coding motifs, they might accelerate discovery of conserved neural mechanisms across mammals.
- The efficiency profile suggests the model could be fine-tuned on-device for closed-loop neuroprosthetics with limited compute.
Load-bearing premise
Heterogeneous recordings from different species, subjects, brain regions, and behavioral paradigms can be made compatible through unified normalization and tokenization so that a single model learns representations that generalize across them.
What would settle it
Train UniBCI on the existing corpus then test on a fresh invasive recording set from an unseen species or paradigm; if fine-tuned performance falls below that of a model trained from scratch on the new data alone, the unification claim does not hold.
Figures








read the original abstract
Modeling invasive neural spike data is fundamental to advancing high-performance brain-computer interfaces (BCIs). However, existing approaches face critical challenges, including limited-scale heterogeneous data, cross-domain distribution shift, and the intrinsic spatiotemporal complexity of invasive neural signals. In this work, we propose UniBCI, a unified pretrained model for invasive Brain-Computer Interfaces. The model integrates three key components: (1) a context-conditioned spatio-temporal tokenization (CST) scheme that embeds neural signals together with metadata into a shared representation space; (2) a hierarchical Interval-Area Attention (IAA) mechanism that captures patterns of spike dynamics in slots via linear attention and locality dependencies via sliding-window attention; and (3) a scalable self-supervised masked signals reconstruction objective for learning generalizable neural representations from large-scale unlabeled data. We construct a pretraining corpus spanning multiple species, subjects, brain regions, and behavioral experiment paradigms. These heterogeneous recordings are standardize via our proposed unified normalization and tokenization. Comprehensive experiments demonstrate that UniBCI achieves SOTA performance across diverse downstream tasks while improving generalization. Moreover, the model achieves a strong balance between accuracy and efficiency, with fewer trainable parameters and lower inference latency. These results suggest that UniBCI provides a practical step toward general-purpose neural foundation models, enabling robust, scalable, and transferable representation learning for invasive neural data. The code for this paper is available at: https://anonymous.4open.science/r/UniBCI-C805.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniBCI, a unified pretrained model for invasive brain-computer interfaces. It introduces three components: (1) context-conditioned spatio-temporal tokenization (CST) that embeds neural spike signals together with metadata into a shared space, (2) hierarchical Interval-Area Attention (IAA) that combines linear attention over spike dynamics with sliding-window attention for locality, and (3) a scalable self-supervised masked reconstruction objective trained on a large corpus of unlabeled invasive recordings spanning multiple species, subjects, brain regions, and behavioral paradigms. The recordings are standardized via unified normalization and tokenization. The central claims are that UniBCI achieves state-of-the-art performance on diverse downstream tasks, improves generalization across domains, and maintains a favorable accuracy-efficiency trade-off (fewer trainable parameters and lower inference latency). Code is stated to be available at an anonymous repository.
Significance. If the empirical claims are substantiated, the work would constitute a meaningful step toward general-purpose foundation models for invasive neural data. The self-supervised pipeline on heterogeneous unlabeled recordings, the CST tokenization scheme, and the IAA mechanism together address a recognized bottleneck in BCI research—cross-domain distribution shift—while the reported efficiency gains could support practical deployment. The explicit release of code is a positive factor for reproducibility.
major comments (3)
- [Abstract] Abstract: The assertion that UniBCI 'achieves SOTA performance across diverse downstream tasks while improving generalization' is presented without any quantitative metrics, baseline comparisons, ablation results, or description of how distribution shift was measured. Because these empirical claims are load-bearing for the central contribution, the absence of supporting numbers in the abstract (and the need to consult the experimental sections for verification) weakens the manuscript's ability to stand on its own.
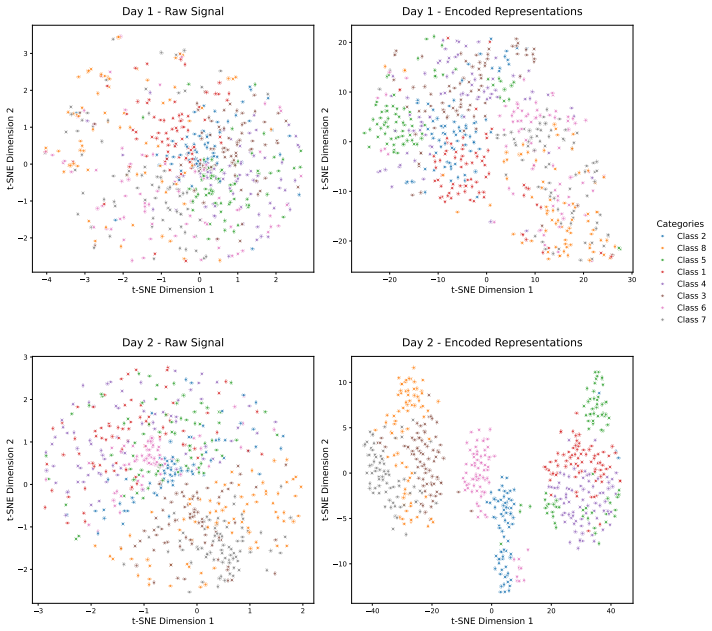
- [Method (CST and unified normalization)] The weakest assumption—that heterogeneous recordings spanning multiple species, subjects, brain regions, and paradigms can be aligned via unified normalization and CST tokenization—is stated but not accompanied by explicit diagnostics (e.g., pre-/post-normalization distribution distances, domain-adaptation metrics, or cross-species transfer gaps). This alignment is prerequisite for the generalization claim and therefore requires targeted evidence in the experimental evaluation.
- [Experiments / Results] The efficiency claims (fewer trainable parameters and lower inference latency) are asserted without tabulated comparisons against the cited baselines or ablations that isolate the contribution of IAA versus standard attention. These numbers are central to the 'strong balance between accuracy and efficiency' statement and must be reported with concrete values and controls.
minor comments (2)
- [Abstract] The code repository link is given as anonymous; the manuscript would benefit from a permanent, non-anonymous link or a clear statement of when the code will be made public.
- [Method] Notation for the IAA mechanism (linear attention over slots versus sliding-window attention) could be clarified with a small diagram or explicit equations showing how the two branches are combined.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that UniBCI 'achieves SOTA performance across diverse downstream tasks while improving generalization' is presented without any quantitative metrics, baseline comparisons, ablation results, or description of how distribution shift was measured. Because these empirical claims are load-bearing for the central contribution, the absence of supporting numbers in the abstract (and the need to consult the experimental sections for verification) weakens the manuscript's ability to stand on its own.
Authors: We agree that the abstract should be more self-contained to allow readers to evaluate the central claims immediately. In the revised version, we will incorporate key quantitative results, including specific SOTA performance gains on downstream tasks, measured generalization improvements across domains (e.g., cross-species and cross-paradigm transfer), and efficiency metrics, while keeping the abstract concise. revision: yes
-
Referee: [Method (CST and unified normalization)] The weakest assumption—that heterogeneous recordings spanning multiple species, subjects, brain regions, and paradigms can be aligned via unified normalization and CST tokenization—is stated but not accompanied by explicit diagnostics (e.g., pre-/post-normalization distribution distances, domain-adaptation metrics, or cross-species transfer gaps). This alignment is prerequisite for the generalization claim and therefore requires targeted evidence in the experimental evaluation.
Authors: We acknowledge that explicit diagnostics would provide stronger support for the alignment via unified normalization and CST tokenization. We will add targeted analyses in the experimental section, including pre- and post-normalization distribution distances, domain-adaptation metrics, and quantified cross-species transfer gaps, to directly substantiate the generalization improvements. revision: yes
-
Referee: [Experiments / Results] The efficiency claims (fewer trainable parameters and lower inference latency) are asserted without tabulated comparisons against the cited baselines or ablations that isolate the contribution of IAA versus standard attention. These numbers are central to the 'strong balance between accuracy and efficiency' statement and must be reported with concrete values and controls.
Authors: We agree that concrete tabulated comparisons and ablations are required to substantiate the efficiency claims. In the revised manuscript, we will add detailed tables comparing trainable parameters and inference latency against all baselines, along with ablations isolating the IAA mechanism versus standard attention, including corresponding accuracy and efficiency metrics. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a standard self-supervised pretraining architecture (CST tokenization + IAA attention + masked reconstruction) trained on an externally constructed corpus of unlabeled heterogeneous neural recordings. The self-supervised objective is defined independently of any downstream task labels or performance metrics. No equations, parameters, or results are shown to reduce by construction to fitted inputs, self-citations, or renamed empirical patterns. The central claims rest on empirical generalization results rather than tautological derivations, making the pipeline self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous invasive neural recordings can be standardized via unified normalization and tokenization to support cross-domain pretraining
invented entities (2)
-
Context-conditioned spatio-temporal tokenization (CST)
no independent evidence
-
Hierarchical Interval-Area Attention (IAA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Eegpt: Pretrained transformer for universal and reliable representation of eeg signals.Advances in Neural Information Processing Systems, 37:39249–39280, 2024
Guagnyu Wang, Wenchao Liu, Yuhong He, Cong Xu, Lin Ma, and Haifeng Li. Eegpt: Pretrained transformer for universal and reliable representation of eeg signals.Advances in Neural Information Processing Systems, 37:39249–39280, 2024
2024
-
[2]
Yuchen Zhou, Jiamin Wu, Zichen Ren, Zhouheng Yao, Weiheng Lu, Kunyu Peng, Qihao Zheng, Chunfeng Song, Wanli Ouyang, and Chao Gou. Csbrain: A cross-scale spatiotemporal brain foundation model for eeg decoding.arXiv preprint arXiv:2506.23075, 2025
-
[3]
CBramod: A criss-cross brain foundation model for EEG decoding
Jiquan Wang, Sha Zhao, Zhiling Luo, Yangxuan Zhou, Haiteng Jiang, Shijian Li, Tao Li, and Gang Pan. CBramod: A criss-cross brain foundation model for EEG decoding. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[4]
A very large- scale microelectrode array for cellular-resolution electrophysiology.Nature Communications, 8(1):1802, 2017
David Tsai, Daniel Sawyer, Adrian Bradd, Rafael Yuste, and Kenneth L Shepard. A very large- scale microelectrode array for cellular-resolution electrophysiology.Nature Communications, 8(1):1802, 2017
2017
-
[5]
Fully integrated silicon probes for high-density recording of neural activity.Nature, 551(7679):232– 236, 2017
James J Jun, Nicholas A Steinmetz, Joshua H Siegle, Daniel J Denman, Marius Bauza, Brian Barbarits, Albert K Lee, Costas A Anastassiou, Alexandru Andrei, Ça˘gatay Aydın, et al. Fully integrated silicon probes for high-density recording of neural activity.Nature, 551(7679):232– 236, 2017
2017
-
[6]
Machine learning for neural decoding.eneuro, 7(4), 2020
Joshua I Glaser, Ari S Benjamin, Raeed H Chowdhury, Matthew G Perich, Lee E Miller, and Konrad P Kording. Machine learning for neural decoding.eneuro, 7(4), 2020
2020
-
[7]
Neural decoding of cursor motion using a kalman filter.Advances in neural information processing systems, 15, 2002
Wei Wu, M Black, Yun Gao, M Serruya, A Shaikhouni, J Donoghue, and Elie Bienenstock. Neural decoding of cursor motion using a kalman filter.Advances in neural information processing systems, 15, 2002
2002
-
[8]
Gaussian-process factor analysis for low-dimensional single-trial analysis of neural population activity.Advances in neural information processing systems, 21, 2008
Byron M Yu, John P Cunningham, Gopal Santhanam, Stephen Ryu, Krishna V Shenoy, and Maneesh Sahani. Gaussian-process factor analysis for low-dimensional single-trial analysis of neural population activity.Advances in neural information processing systems, 21, 2008
2008
-
[9]
Finding structure in time.Cognitive science, 14(2):179–211, 1990
Jeffrey L Elman. Finding structure in time.Cognitive science, 14(2):179–211, 1990
1990
-
[10]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[11]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. InThe International Conference on Learning Representations (ICLR), 2022
2022
-
[12]
Representation learning for neural population activity with Neural Data Transformers.Neurons, Behavior, Data analysis, and Theory, August 2021
Joel Ye and Chethan Pandarinath. Representation learning for neural population activity with Neural Data Transformers.Neurons, Behavior, Data analysis, and Theory, August 2021
2021
-
[13]
Neural data transformer 2: multi- context pretraining for neural spiking activity.Advances in Neural Information Processing Systems, 36:80352–80374, 2023
Joel Ye, Jennifer Collinger, Leila Wehbe, and Robert Gaunt. Neural data transformer 2: multi- context pretraining for neural spiking activity.Advances in Neural Information Processing Systems, 36:80352–80374, 2023
2023
-
[14]
A generalist intracorti- cal motor decoder.bioRxiv, 2025
Joel Ye, Fabio Rizzoglio, Adam Smoulder, Hongwei Mao, Xuan Ma, Patrick Marino, Raeed Chowdhury, Dalton Moore, Gary Blumenthal, William Hockeimer, et al. A generalist intracorti- cal motor decoder.bioRxiv, 2025. 10
2025
-
[15]
A unified, scalable framework for neural population decoding.Advances in Neural Information Processing Systems, 36:44937–44956, 2023
Mehdi Azabou, Vinam Arora, Venkataramana Ganesh, Ximeng Mao, Santosh Nachimuthu, Michael Mendelson, Blake Richards, Matthew Perich, Guillaume Lajoie, and Eva Dyer. A unified, scalable framework for neural population decoding.Advances in Neural Information Processing Systems, 36:44937–44956, 2023
2023
-
[16]
Generalizable, real-time neural decoding with hybrid state-space models
Avery Hee-Woon Ryoo, Nanda H Krishna, Ximeng Mao, Mehdi Azabou, Eva L Dyer, Matthew G Perich, and Guillaume Lajoie. Generalizable, real-time neural decoding with hybrid state-space models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[17]
Real-time machine learning strategies for a new kind of neuroscience experiments
Ayesha Vermani, Matthew Dowling, Hyungju Jeon, Ian Jordan, Josue Nassar, Yves Bernaerts, Yuan Zhao, Steven Van Vaerenbergh, and Il Memming Park. Real-time machine learning strategies for a new kind of neuroscience experiments. In2024 32nd european signal processing conference (eusipco), pages 1127–1131. IEEE, 2024
2024
-
[18]
A brain-computer interface that evokes tactile sensations improves robotic arm control
Sharlene N Flesher, John E Downey, Jeffrey M Weiss, Christopher L Hughes, Angelica J Herrera, Elizabeth C Tyler-Kabara, Michael L Boninger, Jennifer L Collinger, and Robert A Gaunt. A brain-computer interface that evokes tactile sensations improves robotic arm control. Science, 372(6544):831–836, 2021
2021
-
[19]
A high-performance speech neuroprosthesis.Nature, 620(7976):1031–1036, 2023
Francis R Willett, Erin M Kunz, Chaofei Fan, Donald T Avansino, Guy H Wilson, Eun Young Choi, Foram Kamdar, Matthew F Glasser, Leigh R Hochberg, Shaul Druckmann, et al. A high-performance speech neuroprosthesis.Nature, 620(7976):1031–1036, 2023
2023
-
[20]
Au- tonomous optimization of neuroprosthetic stimulation parameters that drive the motor cortex and spinal cord outputs in rats and monkeys.Cell Reports Medicine, 4(4), 2023
Marco Bonizzato, Rose Guay Hottin, Sandrine L Cote, Elena Massai, Léo Choinière, Uzay Macar, Samuel Laferriere, Parikshat Sirpal, Stephan Quessy, Guillaume Lajoie, et al. Au- tonomous optimization of neuroprosthetic stimulation parameters that drive the motor cortex and spinal cord outputs in rats and monkeys.Cell Reports Medicine, 4(4), 2023
2023
-
[21]
Walking naturally after spinal cord injury using a brain–spine interface.Nature, 618(7963):126–133, 2023
Henri Lorach, Andrea Galvez, Valeria Spagnolo, Felix Martel, Serpil Karakas, Nadine Intering, Molywan Vat, Olivier Faivre, Cathal Harte, Salif Komi, et al. Walking naturally after spinal cord injury using a brain–spine interface.Nature, 618(7963):126–133, 2023
2023
-
[22]
Multiple neural spike train data analysis: state-of-the-art and future challenges.Nature neuroscience, 7(5):456–461, 2004
Emery N Brown, Robert E Kass, and Partha P Mitra. Multiple neural spike train data analysis: state-of-the-art and future challenges.Nature neuroscience, 7(5):456–461, 2004
2004
-
[23]
Large-scale recording of neuronal ensembles.Nature neuroscience, 7(5):446– 451, 2004
György Buzsáki. Large-scale recording of neuronal ensembles.Nature neuroscience, 7(5):446– 451, 2004
2004
-
[24]
How advances in neural recording affect data analysis
Ian H Stevenson and Konrad P Kording. How advances in neural recording affect data analysis. Nature neuroscience, 14(2):139–142, 2011
2011
-
[25]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020
2020
-
[26]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[27]
Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33:17283–17297, 2020
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santi- ago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33:17283–17297, 2020
2020
-
[28]
Generating Long Sequences with Sparse Transformers
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review arXiv 1904
-
[29]
Decoding and geometry of ten finger movements in human posterior parietal cortex and motor cortex.Journal of Neural Engineering, 20(3):036020, 2023
Charles Guan, Tyson Aflalo, Kelly Kadlec, Jorge Gámez de Leon, Emily R Rosario, Ausaf Bari, Nader Pouratian, and Richard A Andersen. Decoding and geometry of ten finger movements in human posterior parietal cortex and motor cortex.Journal of Neural Engineering, 20(3):036020, 2023
2023
-
[30]
Long-term recordings of motor and premotor cortical spiking activity during reaching in monkeys.Data set, 2025
Matthew G Perich, Lee E Miller, Mehdi Azabou, and Eva L Dyer. Long-term recordings of motor and premotor cortical spiking activity during reaching in monkeys.Data set, 2025. 11
2025
-
[31]
Zoltowski, Anqi Wu, Raeed H
Felix Pei, Joel Ye, David M. Zoltowski, Anqi Wu, Raeed H. Chowdhury, Hansem Sohn, Joseph E. O’Doherty, Krishna V . Shenoy, Matthew T. Kaufman, Mark Churchland, Mehrdad Jazayeri, Lee E. Miller, Jonathan Pillow, Il Memming Park, Eva L. Dyer, and Chethan Pandarinath. Neural latents benchmark ’21: Evaluating latent variable models of neural population activit...
2021
-
[32]
MiniLMv2: Multi-head self-attention relation distillation for compressing pretrained transformers
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. MiniLMv2: Multi-head self-attention relation distillation for compressing pretrained transformers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2140–2151, Online, August 2021. Association for Computational Linguistics
2021
-
[33]
Learning phrase representations using rnn encoder– decoder for statistical machine translation
Kyunghyun Cho, Bart Van Merriënboer, Ça˘glar Gulçehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder– decoder for statistical machine translation. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1724–1734, 2014
2014
-
[34]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[35]
universal translator
Yizi Zhang, Yanchen Wang, Donato M Jiménez-Benetó, Zixuan Wang, Mehdi Azabou, Blake Richards, Renee Tung, Olivier Winter, Eva Dyer, Liam Paninski, et al. Towards a" universal translator" for neural dynamics at single-cell, single-spike resolution.Advances in Neural Information Processing Systems, 37:80495–80521, 2024
2024
-
[36]
Stabilizing brain- computer interfaces through alignment of latent dynamics
Brianna M Karpowicz, Yahia H Ali, Lahiru N Wimalasena, Andrew R Sedler, Mohammad Reza Keshtkaran, Kevin Bodkin, Xuan Ma, Lee E Miller, and Chethan Pandarinath. Stabilizing brain- computer interfaces through alignment of latent dynamics. nov 2022. doi: 10.1101/2022.04. 06.487388.URL https://www. biorxiv. org/content/10.1101/2022.04, 6:v2
-
[37]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
2002
-
[38]
Using adversarial networks to extend brain computer interface decoding accuracy over time
Xuan Ma, Fabio Rizzoglio, Kevin L Bodkin, Eric Perreault, Lee E Miller, and Ann Kennedy. Using adversarial networks to extend brain computer interface decoding accuracy over time. elife, 12:e84296, 2023
2023
-
[39]
Bidirectional cross-day alignment of neural spikes and behavior using a hybrid snn-ann algorithm.Frontiers in Neuroscience, 20:1772958, 2026
Binjie Hong, Zihang Xu, Tengyu Zhang, and Tielin Zhang. Bidirectional cross-day alignment of neural spikes and behavior using a hybrid snn-ann algorithm.Frontiers in Neuroscience, 20:1772958, 2026
2026
-
[40]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018
2018
-
[41]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[42]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652, 2021
work page internal anchor Pith review arXiv 2021
-
[43]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[44]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[45]
Multi-session, multi-task neural decoding from distinct cell-types and brain regions
Mehdi Azabou, Krystal Xuejing Pan, Vinam Arora, Ian Jarratt Knight, Eva L Dyer, and Blake Aaron Richards. Multi-session, multi-task neural decoding from distinct cell-types and brain regions. InThe Thirteenth International Conference on Learning Representations, 2025. 12
2025
-
[46]
Yizi Zhang, Yanchen Wang, Mehdi Azabou, Alexandre Andre, Zixuan Wang, Hanrui Lyu, The International Brain Laboratory, Eva Dyer, Liam Paninski, and Cole Hurwitz. Neural encoding and decoding at scale.arXiv preprint arXiv:2504.08201, 2025
-
[47]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[48]
Yue Song, T. Anderson Keller, Yisong Yue, Pietro Perona, and Max Welling. Langevin flows for modeling neural latent dynamics. 2025. 13 A RELATED WORK A.1 Neural Decoding Methods Neural decoding aims to infer behavioral or cognitive variables from neural activity. Early ap- proaches were primarily based on linear statistical models and dynamical systems, s...
-
[49]
Normalized Spike Trains Tokens 1.00 0.75 0.50 0.25 0.000.250.500.751.00 1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00 1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00
-
[50]
Metadata-conditioned Context Tokens 1.00 0.75 0.50 0.25 0.000.250.500.751.00 1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00 1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00
-
[51]
around distinct contextual anchors, forming separable clusters that reflect underlying experimental conditions and provide a semantic prior for neural signal modeling
Spatio-temporal Tokens Mouse (VLS) - Licking T ask Mouse (SNR) - Licking T ask Mouse (M2) - Licking T ask Macaque (HPC) - Hidden Goal T ask Macaque (PMd) - Pacman T ask Figure 8: Token distributions on a hyperspherical space across stages, showing how metadata pro- gressively structures neural representations from entangled spike tokens to organized spati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.