Recognition: unknown
Sparse K-spatial-median clustering for high-dimensional data
Pith reviewed 2026-05-09 19:15 UTC · model grok-4.3
The pith
A clustering method using spatial medians and hard feature exclusion improves stability for high-dimensional heavy-tailed data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
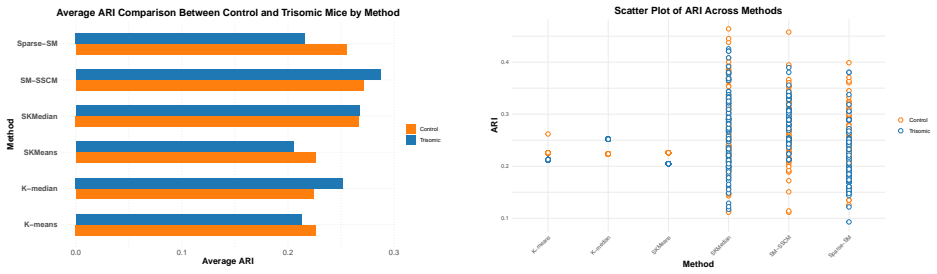
The central claim is that replacing the mean updates of Lloyd's algorithm with spatial medians, permitting either a Euclidean or a spatial-sign-covariance-based assignment rule, and applying a dispersion-based hard feature-exclusion rule whose threshold is set by a permutation Gap criterion produces clustering accuracy that is competitive with K-means and sparse K-means while delivering visibly higher stability in simulations drawn from correlated Gaussian and multivariate t distributions.
What carries the argument
The hard feature-exclusion rule, which removes dimensions whose across-center dispersion falls below a permutation-selected Gap threshold, supplies the sparsity mechanism while the spatial-median updates supply the robustness.
If this is right
- Clustering accuracy remains competitive with standard K-means and sparse K-means under both Gaussian and heavy-tailed models.
- Stability across repeated runs or slight data perturbations improves relative to the baselines.
- The automatic exclusion step removes irrelevant dimensions without requiring separate variable-selection tuning.
- The assignment step can incorporate a robust Mahalanobis-type distance when feature scales or dependence matter.
Where Pith is reading between the lines
- The same spatial-median center updates could be inserted into other partitioning algorithms to gain similar robustness without changing the overall framework.
- Because exclusion is driven by dispersion across centers, the procedure implicitly ranks variables by their contribution to separation and could therefore feed directly into post-clustering interpretation.
- If the Gap criterion works for exclusion, the same permutation idea might be used to choose the number of clusters K in the same run.
Load-bearing premise
The across-center dispersion, paired with the permutation Gap threshold, reliably keeps signal-bearing dimensions and discards irrelevant ones even when features are correlated and tails are heavy.
What would settle it
A controlled simulation in which the method excludes a known separating feature or retains most known noise features would show the exclusion rule has failed.
Figures



read the original abstract
We propose a robust clustering framework for high-dimensional data with heavy tails and a large fraction of irrelevant variables. The method replaces the mean updates of Lloyd's $K$-means with \emph{spatial medians} to enhance robustness. For the assignment step, it admits either a Euclidean rule for computational simplicity or a robust Mahalanobis-type metric constructed from the spatial sign covariance matrix to account for heterogeneous scales and feature dependence. To handle the $p \gg n$ regime, we further introduce a simple \emph{hard feature-exclusion} mechanism that removes weakly separating dimensions based on across-center dispersion, with the exclusion threshold selected automatically via a permutation-based Gap criterion. Simulation studies under correlated Gaussian and multivariate $t$ models demonstrate that the proposed approach provides competitive clustering accuracy and improved stability relative to $K$-means and sparse $K$-means baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a robust clustering framework called sparse K-spatial-median clustering for high-dimensional data. It replaces mean updates in K-means with spatial medians for robustness to heavy tails, uses either Euclidean or robust Mahalanobis-type assignment based on the spatial sign covariance matrix, and introduces hard feature exclusion based on across-center dispersion with the threshold selected via a permutation Gap criterion. Simulations under correlated Gaussian and multivariate t models report competitive clustering accuracy and improved stability relative to K-means and sparse K-means baselines.
Significance. If the performance claims hold after addressing the concerns below, the work would provide a practical robust alternative for clustering high-dimensional data with outliers, heavy tails, and many irrelevant features. The automatic feature-exclusion step and emphasis on stability could be useful in applications such as genomics or imaging, where reproducibility matters. The simulations offer initial supporting evidence, though they require more detail to fully assess generalizability.
major comments (2)
- [Feature exclusion and Gap criterion] The hard feature-exclusion rule based on across-center dispersion, with threshold chosen by the permutation Gap criterion, may fail to preserve weak signal features under the paper's own correlated models. Standard permutations break the dependence structure in the correlated Gaussian and t distributions used for simulation, producing an incorrect null for the Gap statistic. This risks excluding informative dimensions or retaining noise, which directly affects the central claim of improved stability (see simulation setup and method description).
- [Simulation studies] The simulation studies report favorable accuracy and stability but provide no information on the number of replications, standard errors or variability measures for the reported metrics, or exact parameter values (e.g., correlation coefficients, degrees of freedom for the t distribution). This makes it impossible to determine whether the observed gains are reliable or could be artifacts of the specific design.
minor comments (3)
- [Abstract] Ensure consistent use of terminology between the title ('Sparse K-spatial-median clustering') and the abstract description.
- Add pseudocode or a clear algorithmic outline for the full procedure, including how the spatial sign covariance is estimated in the p ≫ n regime.
- Clarify the exact formula for the across-center dispersion statistic used to rank features for exclusion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Feature exclusion and Gap criterion] The hard feature-exclusion rule based on across-center dispersion, with threshold chosen by the permutation Gap criterion, may fail to preserve weak signal features under the paper's own correlated models. Standard permutations break the dependence structure in the correlated Gaussian and t distributions used for simulation, producing an incorrect null for the Gap statistic. This risks excluding informative dimensions or retaining noise, which directly affects the central claim of improved stability (see simulation setup and method description).
Authors: We agree that standard permutations destroy the correlation structure present in the simulated data, which is a recognized limitation of permutation-based procedures under dependence. The Gap criterion is applied to the across-center dispersion measure to select an automatic threshold for hard feature exclusion, with the goal of removing dimensions that do not contribute meaningfully to separation. While the referee's concern is valid in principle, the simulations under the paper's correlated Gaussian and multivariate-t settings show that the procedure retains competitive accuracy and improves stability relative to baselines. To address the point directly, the revised manuscript will include an explicit discussion of the exchangeability assumption underlying the permutation null and its potential impact on weak-signal retention, together with a brief sensitivity analysis using an alternative resampling scheme that approximately preserves pairwise correlations. revision: partial
-
Referee: [Simulation studies] The simulation studies report favorable accuracy and stability but provide no information on the number of replications, standard errors or variability measures for the reported metrics, or exact parameter values (e.g., correlation coefficients, degrees of freedom for the t distribution). This makes it impossible to determine whether the observed gains are reliable or could be artifacts of the specific design.
Authors: We acknowledge that the simulation section is missing these essential details. The revised manuscript will report the number of Monte Carlo replications, standard errors (or interquartile ranges) for all accuracy and stability metrics, and the precise parameter values used, including the correlation coefficient and degrees of freedom for the multivariate-t model. These additions will allow readers to assess the reliability of the reported improvements. revision: yes
Circularity Check
No circularity: algorithmic proposal relies on external Gap criterion and empirical simulations
full rationale
The paper describes a clustering algorithm replacing K-means means with spatial medians, optionally using a spatial-sign covariance for assignments, and applying hard feature exclusion whose threshold is set by the established permutation Gap statistic (external to the paper). No derivation, theorem, or prediction is claimed that reduces by the paper's own equations to a fitted parameter or self-citation. Simulations under specified models supply the performance claims without any load-bearing step that is definitionally equivalent to its inputs. This is the common case of a self-contained algorithmic contribution validated externally.
Axiom & Free-Parameter Ledger
free parameters (1)
- feature-exclusion threshold
axioms (2)
- domain assumption Spatial medians are robust to heavy tails and outliers in the assignment and update steps
- domain assumption The across-center dispersion measure combined with the Gap criterion correctly identifies irrelevant dimensions
Reference graph
Works this paper leans on
-
[1]
Simple and Scalable Sparse k-means Clustering via Feature Ranking , url =
Zhang, Zhiyue and Lange, Kenneth and Xu, Jason , booktitle =. Simple and Scalable Sparse k-means Clustering via Feature Ranking , url =
-
[2]
2004 , journal=
Feature Selection in k-Median Clustering , author=. 2004 , journal=
2004
-
[3]
and Yang, Miin-Shen , title =
Benjamin, Josephine Bernadette M. and Yang, Miin-Shen , title =. IEEE Access , year =
-
[4]
MacQueen, J. B. , title =. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability , volume =. 1967 , publisher =
1967
-
[5]
J. A. Hartigan and M. A. Wong , journal =. Algorithm AS 136: A K-Means Clustering Algorithm , volume =
-
[6]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =
Tibshirani, Robert and Walther, Guenther and Hastie, Trevor , title =. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =. doi:https://doi.org/10.1111/1467-9868.00293 , url =
-
[7]
Cuesta-Albertos, J. A. and Gordaliza, A. and Matr. Trimmed k-Means: An Attempt to Robustify Quantizers , journal =. 1997 , volume =
1997
-
[8]
and Salibian-Barrera, M
Kondo, Y. and Salibian-Barrera, M. and Zamar, R. , title =. 2012 , howpublished =
2012
-
[9]
Robust and sparse K-means clustering for high-dimensional data , journal =
Brodinov. Robust and Sparse k-Means Clustering for High-Dimensional Data , journal =. 2019 , volume =. doi:10.1007/s11634-019-00356-9 , url =
-
[10]
Electronic Journal of Statistics , number =
Wei Sun and Junhui Wang and Yixin Fang , title =. Electronic Journal of Statistics , number =. 2012 , doi =
2012
-
[11]
, booktitle =
Bradley, Paul and Mangasarian, Olvi and Street, W. , booktitle =. Clustering via Concave Minimization , url =
-
[12]
and Dubes, Richard C
Jain, Anil K. and Dubes, Richard C. , title =
-
[13]
Model-based Clustering of High-dimensional Data: A Review , journal =. 2014 , issn =. doi:https://doi.org/10.1016/j.csda.2012.12.008 , url =
-
[14]
Journal of the American Statistical Association , volume =
Chris Fraley and Adrian E Raftery , title =. Journal of the American Statistical Association , volume =. 2002 , publisher =. doi:10.1198/016214502760047131 , URL =
-
[15]
Journal of Machine Learning Research , year =
Pan, Wei and Shen, Xiaotong , title =. Journal of Machine Learning Research , year =
-
[16]
The Annals of Statistics , year =
Jin, Jiashun and Wang, Wanjie , title =. The Annals of Statistics , year =
-
[17]
Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume =
Chang, Wei-Chien , title =. Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume =. doi:https://doi.org/10.2307/2347949 , url =
-
[18]
Principal Component Analysis , journal =. 1987 , note =. doi:https://doi.org/10.1016/0169-7439(87)80084-9 , url =
-
[19]
Parsons, Lance and Haque, Ehtesham and Liu, Huan , title =. 2004 , issue_date =. doi:10.1145/1007730.1007731 , journal =
-
[20]
IEEE Transactions on Pattern Analysis and Machine Intelligence , title=
Elhamifar, Ehsan and Vidal, Ren. IEEE Transactions on Pattern Analysis and Machine Intelligence , title=. 2013 , volume=
2013
-
[21]
Mahdi Soltanolkotabi and Emmanuel J. Cand. The Annals of Statistics , number =. 2012 , doi =
2012
-
[22]
Journal of Machine Learning Research , year =
Yu-Xiang Wang and Huan Xu , title =. Journal of Machine Learning Research , year =
-
[23]
Proceedings of the National Academy of Sciences , year =
Vardi, Yehuda and Zhang, Cun-Hui , title =. Proceedings of the National Academy of Sciences , year =
-
[24]
2010 , doi =
Oja, Hannu , title =. 2010 , doi =
2010
-
[25]
and Plastria, F
Weiszfeld, E. and Plastria, F. , title =. Annals of Operations Research , year =
-
[26]
and Baragilly, Mohammed , title =
Gabr, Hend and Willis, Brian H. and Baragilly, Mohammed , title =. Journal of Applied Statistics , year =
-
[27]
Journal of the American Statistical Association , year =
A Framework for Feature Selection in Clustering , author =. Journal of the American Statistical Association , year =
-
[28]
Journal of Classification , year =
Comparing Partitions , author =. Journal of Classification , year =
-
[29]
Journal of Statistical Planning and Inference , year =
Sign and Rank Covariance Matrices , author =. Journal of Statistical Planning and Inference , year =
-
[30]
Statistics and Computing , year =
The k -Step Spatial Sign Covariance Matrix , author =. Statistics and Computing , year =
-
[31]
Journal of Multivariate Analysis , year =
A Generalized Spatial Sign Covariance Matrix , author =. Journal of Multivariate Analysis , year =
-
[32]
Tohoku Mathematical Journal , year =
Sur le point pour lequel la somme des distances de n points donn\'es est minimum , author =. Tohoku Mathematical Journal , year =
-
[33]
Nature communications , volume=
ClusterMap for Multi-scale Clustering Analysis of Spatial Gene Expression , author=. Nature communications , volume=. 2021 , publisher=
2021
-
[34]
Nature communications , volume=
In-vivo Integration of Soft Neural Probes Through High-Resolution Printing of Liquid Electronics on The Cranium , author=. Nature communications , volume=. 2024 , publisher=
2024
-
[35]
Elastic Deep Autoencoder for Text Embedding Clustering by An Improved Graph Regularization , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.eswa.2023.121780 , url =
-
[36]
Journal of Classification , volume=
A Survey on Feature Weighting Based K-means Algorithms , author=. Journal of Classification , volume=. 2016 , publisher=
2016
-
[37]
Electronic Journal of Statistics , volume =
Wei Sun and Junhui Wang and Yixin Fang , title =. Electronic Journal of Statistics , volume =. 2012 , doi =
2012
-
[38]
E. W. Forgy , title =. Biometrics , volume =
-
[39]
Sparse K-means Clustering Algorithm With Anchor Graph Regularization , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.ins.2024.120504 , url =
-
[40]
Journal of the American Statistical Association , volume=
Variable Selection for Model-based Clustering , author=. Journal of the American Statistical Association , volume=. 2006 , publisher=
2006
-
[41]
The Annals of Statistics , volume=
Robust K-means Clustering for Distributions With Two Moments , author=. The Annals of Statistics , volume=. 2021 , publisher=
2021
-
[42]
Ding, Chris and He, Xiaofeng , title =. 2004 , isbn =. doi:10.1145/1015330.1015408 , booktitle =
-
[43]
Egyptian Informatics Journal , volume=
Determining the Optimal Number of Clusters by Enhanced Gap Statistic in K-mean Algorithm , author=. Egyptian Informatics Journal , volume=. 2024 , publisher=
2024
-
[44]
High-Dimensional Data Analysis for Elliptically Symmetric Distributions
High-Dimensional Data Analysis for Elliptically Symmetric Distributions , author=. arXiv preprint arXiv:2604.13944 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.