Recognition: unknown
MoE-Hub: Taming Software Complexity for Seamless MoE Overlap with Hardware-Accelerated Communication on Multi-GPU Systems
Pith reviewed 2026-05-08 04:27 UTC · model grok-4.3
The pith
MoE-Hub decouples data transmission from address management to enable seamless communication overlap in multi-GPU MoE systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
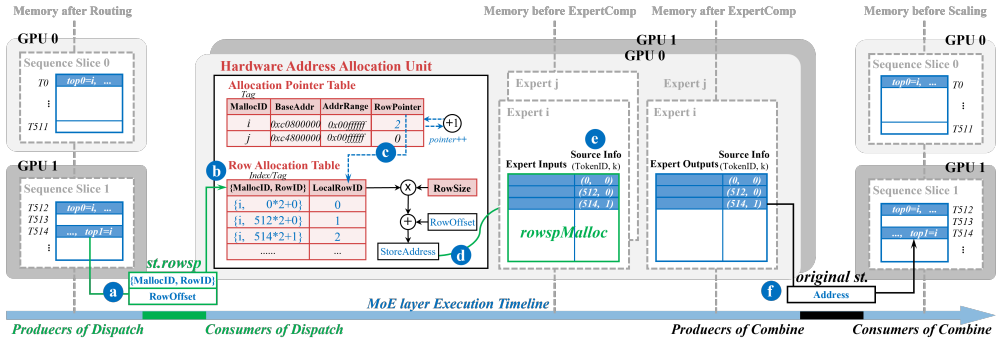
MoE-Hub resolves the root abstraction mismatch by hardware-accelerating the entire communication control plane, so that producers send data right after routing with only a logical destination while the GPU hub transparently performs address allocation and data-flow orchestration, producing seamless overlap and measured per-layer speedups of 1.40x-3.08x together with end-to-end speedups of 1.21x-1.98x.
What carries the argument
The destination-agnostic communication paradigm in which data transmission is separated from address management and offloaded to lightweight hardware inside the GPU hub.
If this is right
- Per-layer execution times improve by 1.40x to 3.08x over current state-of-the-art systems.
- Full end-to-end training or inference runs improve by 1.21x to 1.98x.
- Communication and computation overlap becomes transparent without extra programmer effort.
- Software for dynamic token routing becomes simpler because address resolution is removed from the critical path.
Where Pith is reading between the lines
- The same decoupling pattern could support other irregular, data-dependent communication patterns that appear in graph neural networks or sparse transformers.
- GPU vendors might consider embedding similar lightweight hubs in future interconnect designs to handle dynamic workloads more efficiently.
- MoE training frameworks could drop custom address-resolution passes and rely on the hardware abstraction instead.
- Scaling experiments on clusters larger than those tested would reveal whether the hub remains lightweight when the number of experts and GPUs grows.
Load-bearing premise
Lightweight hardware added to the GPU hub can manage address allocation and data-flow orchestration at scale without adding performance overhead or requiring incompatible changes to existing GPU architectures.
What would settle it
A prototype implementation of the GPU hub hardware that shows either increased end-to-end latency for MoE layers or no improvement in overlap relative to current software baselines would falsify the central performance claim.
Figures















read the original abstract
The Mixture-of-Experts (MoE) architecture is crucial for scaling large language models, but its scalability is severely limited by inter-GPU communication bottlenecks in multi-GPU systems. Although overlapping communication with computation is a widely recognized optimization, its effective deployment still remains challenging, both in terms of performance and programmability. In this work, we identify the root cause as a fundamental abstraction mismatch between MoE's dynamic, irregular token-to-expert mapping and the static, address-centric communication model of modern GPUs, which necessitates a complex software mediation phase to resolve addresses before data transfers, limiting performance and software flexibility. To resolve this, we propose MoE-Hub, a hardware-software co-design that introduces a destination-agnostic communication paradigm. MoE-Hub decouples data transmission from address management, allowing producers to send data immediately after routing using only a logical destination, while address allocation and data-flow orchestration are handled transparently by lightweight hardware in the GPU hub. By hardware-accelerating the entire communication control plane, MoE-Hub enables seamless and transparent overlap. Our evaluation shows that MoE-Hub achieves 1.40x-3.08x per-layer and 1.21x-1.98x end-to-end speedup over state-of-the-art systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies the root cause of limited scalability in Mixture-of-Experts (MoE) architectures on multi-GPU systems as an abstraction mismatch between dynamic token-to-expert mappings and the static address-centric communication model of GPUs, which requires complex software mediation. It proposes MoE-Hub, a hardware-software co-design that introduces a destination-agnostic communication paradigm. This allows producers to send data using only logical destinations immediately after routing, with address allocation and data-flow orchestration handled transparently by lightweight hardware in the GPU hub. Hardware acceleration of the communication control plane enables seamless overlap, with reported speedups of 1.40x-3.08x per-layer and 1.21x-1.98x end-to-end over state-of-the-art systems.
Significance. If the central claims hold, MoE-Hub could significantly advance the field by simplifying software for MoE overlap and providing hardware support for efficient communication in multi-GPU setups. This co-design approach addresses a key bottleneck in scaling large language models, potentially leading to improved performance and flexibility in distributed training and inference without major changes to existing GPU architectures.
major comments (2)
- The abstract presents concrete performance improvements (1.40x-3.08x per-layer and 1.21x-1.98x end-to-end) but omits any description of the experimental methodology, chosen baselines, hardware platform details, or error bars, which is critical for assessing the validity of the speedups claimed for the proposed design.
- The assertion that 'lightweight hardware in the GPU hub' can transparently resolve logical destinations to physical addresses and orchestrate data flows without software mediation or performance overheads lacks supporting details such as microarchitectural specifications, estimated area and latency costs, or compatibility analysis with current GPU memory models and interconnects like NVLink.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the significance of MoE-Hub. We address each major comment below, providing clarifications from the manuscript and indicating planned revisions.
read point-by-point responses
-
Referee: The abstract presents concrete performance improvements (1.40x-3.08x per-layer and 1.21x-1.98x end-to-end) but omits any description of the experimental methodology, chosen baselines, hardware platform details, or error bars, which is critical for assessing the validity of the speedups claimed for the proposed design.
Authors: We agree that space constraints in the abstract limit inclusion of full methodology details. The Evaluation section of the manuscript fully specifies the experimental setup, including the multi-GPU hardware platform with NVLink interconnects, the chosen state-of-the-art baselines for MoE systems, and performance results reported with variability across repeated runs. To address the concern, we will revise the abstract to include a concise reference to the evaluation methodology and hardware platform. revision: yes
-
Referee: The assertion that 'lightweight hardware in the GPU hub' can transparently resolve logical destinations to physical addresses and orchestrate data flows without software mediation or performance overheads lacks supporting details such as microarchitectural specifications, estimated area and latency costs, or compatibility analysis with current GPU memory models and interconnects like NVLink.
Authors: The manuscript describes the MoE-Hub hardware-software co-design at the architectural level, emphasizing how the GPU hub transparently handles address resolution and data-flow orchestration to enable destination-agnostic transmission. We acknowledge that the current version does not include detailed microarchitectural specifications, quantitative area/latency estimates, or exhaustive compatibility analysis. We will expand the design section with additional qualitative discussion of compatibility with existing GPU memory models and NVLink, while noting that full hardware implementation metrics are left for future work. revision: partial
- Quantitative microarchitectural specifications, area, and latency cost estimates for the proposed lightweight hardware, as these require detailed hardware modeling and synthesis beyond the scope of the current manuscript.
Circularity Check
No circularity in MoE-Hub hardware-software co-design proposal
full rationale
The paper presents a systems design for decoupling data transmission from address management in MoE communication via a new GPU hub hardware component. No mathematical derivations, equations, fitted parameters, or predictions are present in the abstract or described claims. The central argument rests on identifying an abstraction mismatch and proposing a transparent hardware solution, without any self-referential definitions, self-citation load-bearing steps, or renaming of known results. The evaluation speedups are reported outcomes rather than constructed predictions. This is a standard non-circular design proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modern GPUs rely on a static, address-centric communication model that conflicts with MoE's dynamic token-to-expert mapping.
invented entities (2)
-
Destination-agnostic communication paradigm
no independent evidence
-
Lightweight hardware in the GPU hub
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, H. Behl, A. Benhaim, M. Bilenko, J. Bjorck, S. Bubeck, M. Cai, Q. Cai, V . Chaudhary, D. Chen, D. Chen, W. Chen, Y .-C. Chen, Y .-L. Chen, H. Cheng, P. Chopra, X. Dai, M. Dixon, R. Eldan, V . Fragoso, J. Gao, M. Gao, M. Gao, A. Garg, A. D. Giorno, A. Goswa...
work page internal anchor Pith review arXiv 2024
-
[2]
Flashdmoe: Fast distributed moe in a single kernel,
O. J. Aimuyo, B. Oh, and R. Singh, “Flashdmoe: Fast distributed moe in a single kernel,”arXiv preprint arXiv:2506.04667, 2025
-
[3]
Moe training best practices on amd gpus
AMD, “Moe training best practices on amd gpus.” https://rocm.blogs.amd.com/software-tools-optimization/primus-moe- package/README.html, 2025
2025
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,”arXiv preprint arXiv:2308.12966, vol. 1, no. 2, p. 3, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Verifying semantic equivalence of large models with equality saturation
O. Balmau, A.-M. Kermarrec, R. Pires, A. L. E. Santo, M. de V os, and M. Vujasinovic, “Accelerating moe model inference with expert sharding,” inProceedings of the 5th Workshop on Machine Learning and Systems, ser. EuroMLSys ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 192–199. [Online]. Available: https://doi.org/10.1145/3721146.3721940
-
[6]
Cen- tauri: Enabling efficient scheduling for communication-computation overlap in large model training via communication partitioning,
C. Chen, X. Li, Q. Zhu, J. Duan, P. Sun, X. Zhang, and C. Yang, “Cen- tauri: Enabling efficient scheduling for communication-computation overlap in large model training via communication partitioning,” in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 178–191
2024
-
[7]
Scalable irregular parallelism with gpus: getting cpus out of the way,
Y . Chen, B. Brock, S. Porumbescu, A. Buluc ¸, K. Yelick, and J. D. Owens, “Scalable irregular parallelism with gpus: getting cpus out of the way,” inProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, ser. SC ’22. IEEE Press, 2022
2022
-
[8]
Mirage persistent kernel: A compiler and runtime for mega-kernelizing tensor programs,
X. Cheng, Z. Zhang, Y . Zhou, J. Ji, J. Jiang, Z. Zhao, Z. Xiao, Z. Ye, Y . Huang, R. Lai, H. Jin, B. Hou, M. Wu, Y . Dong, A. Yip, Z. Ye, S. Wang, W. Yang, X. Miao, T. Chen, and Z. Jia, “Mirage persistent kernel: A compiler and runtime for mega-kernelizing tensor programs,”
- [9]
-
[10]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
D. Dai, C. Deng, C. Zhao, R. X. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wu, Z. Xie, Y . K. Li, P. Huang, F. Luo, C. Ruan, Z. Sui, and W. Liang, “Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models,” 2024. [Online]. Available: https://arxiv.org/abs/2401.06066
work page internal anchor Pith review arXiv 2024
-
[11]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI, A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Yang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Chen, J. Yuan, J. Qiu, J. Song, K. Dong, K. Gao, K. Guan, L. Wan...
work page internal anchor Pith review arXiv 2024
-
[12]
Deepseek-v3 technical report,
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Wang, J. Chen, J. Chen, J. Yuan, J...
-
[13]
[Online]. Available: https://arxiv.org/abs/2412.19437
work page internal anchor Pith review arXiv
-
[14]
GLaM: Efficient scaling of language models with mixture-of-experts,
N. Du, Y . Huang, A. M. Dai, S. Tong, D. Lepikhin, Y . Xu, M. Krikun, Y . Zhou, A. W. Yu, O. Firat, B. Zoph, L. Fedus, M. P. Bosma, Z. Zhou, T. Wang, E. Wang, K. Webster, M. Pellat, K. Robinson, K. Meier-Hellstern, T. Duke, L. Dixon, K. Zhang, Q. Le, Y . Wu, Z. Chen, and C. Cui, “GLaM: Efficient scaling of language models with mixture-of-experts,” inProce...
2022
-
[15]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[16]
Megablocks: Effi- cient sparse training with mixture-of-experts,
T. Gale, D. Narayanan, C. Young, and M. Zaharia, “Megablocks: Effi- cient sparse training with mixture-of-experts,”Proceedings of Machine Learning and Systems, vol. 5, pp. 288–304, 2023
2023
-
[17]
C. Guo, R. Zhang, J. Xu, J. Leng, Z. Liu, Z. Huang, M. Guo, H. Wu, S. Zhao, J. Zhao, and K. Zhang, “Gmlake: Efficient and transparent gpu memory defragmentation for large-scale dnn training with virtual memory stitching,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume...
-
[18]
Faster- moe: modeling and optimizing training of large-scale dynamic pre- trained models,
J. He, J. Zhai, T. Antunes, H. Wang, F. Luo, S. Shi, and Q. Li, “Faster- moe: modeling and optimizing training of large-scale dynamic pre- trained models,” inProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2022, pp. 120–134
2022
-
[19]
K. Hong, X. Li, M. Liu, Q. Mao, T. Wu, Z. Huang, L. Chen, Z. Wang, Y . Zhang, Z. Zhu, G. Dai, and Y . Wang, “Efficient and adaptable overlapping for computation and communication via signaling and reordering,” 2025. [Online]. Available: https://arxiv.org/abs/2504.19519
-
[20]
Toward efficient inference for mixture of experts,
H. Huang, N. Ardalani, A. Sun, L. Ke, H.-H. S. Lee, S. Bhosale, C.-J. Wu, and B. Lee, “Toward efficient inference for mixture of experts,”Advances in Neural Information Processing Systems, vol. 37, pp. 84 033–84 059, 2024
2024
-
[21]
Tutel: Adaptive mixture-of-experts at scale,
C. Hwang, W. Cui, Y . Xiong, Z. Yang, Z. Liu, H. Hu, Z. Wang, 14 R. Salas, J. Jose, P. Ram, H. Chau, P. Cheng, F. Yang, M. Yang, and Y . Xiong, “Tutel: Adaptive mixture-of-experts at scale,” inProceedings of Machine Learning and Systems, D. Song, M. Carbin, and T. Chen, Eds., vol. 5. Curan, 2023, pp. 269–287. [Online]. Available: https://proceedings.mlsys...
2023
-
[22]
Pre-gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference,
R. Hwang, J. Wei, S. Cao, C. Hwang, X. Tang, T. Cao, and M. Yang, “Pre-gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference,” in2024 ACM/IEEE 51st Annual Interna- tional Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 1018–1031
2024
-
[23]
Breaking the com- putation and communication abstraction barrier in distributed machine learning workloads,
A. Jangda, J. Huang, G. Liu, A. H. N. Sabet, S. Maleki, Y . Miao, M. Musuvathi, T. Mytkowicz, and O. Saarikivi, “Breaking the com- putation and communication abstraction barrier in distributed machine learning workloads,” inProceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2022, ...
2022
-
[24]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M.-A. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mixtral of experts,” 2024. [Onl...
work page internal anchor Pith review arXiv 2024
-
[25]
Lancet: Accelerating mixture-of-experts training via whole graph computation- communication overlapping,
C. Jiang, Y . Tian, Z. Jia, S. Zheng, C. Wu, and Y . Wang, “Lancet: Accelerating mixture-of-experts training via whole graph computation- communication overlapping,”Proceedings of Machine Learning and Systems, vol. 6, pp. 74–86, 2024
2024
-
[26]
Minference 1.0: accelerating pre-filling for long-context llms via dynamic sparse attention,
H. Jiang, Y . Li, C. Zhang, Q. Wu, X. Luo, S. Ahn, Z. Han, A. H. Abdi, D. Li, C.-Y . Lin, Y . Yang, and L. Qiu, “Minference 1.0: accelerating pre-filling for long-context llms via dynamic sparse attention,” inPro- ceedings of the 38th International Conference on Neural Information Processing Systems, ser. NIPS ’24. Red Hook, NY , USA: Curran Associates Inc., 2024
2024
-
[27]
A detailed and flexible cycle-accurate network-on-chip simulator,
N. Jiang, D. U. Becker, G. Michelogiannakis, J. Balfour, B. Towles, D. E. Shaw, J. Kim, and W. J. Dally, “A detailed and flexible cycle-accurate network-on-chip simulator,” in2013 IEEE international symposium on performance analysis of systems and software (ISPASS). IEEE, 2013, pp. 86–96
2013
-
[28]
C. Jin, Z. Jiang, Z. Bai, Z. Zhong, J. Liu, X. Li, N. Zheng, X. Wang, C. Xie, Q. Huang, W. Heng, Y . Ma, W. Bao, S. Zheng, Y . Peng, H. Lin, X. Liu, X. Jin, and X. Liu, “Megascale-moe: Large- scale communication-efficient training of mixture-of-experts models in production,” 2025. [Online]. Available: https://arxiv.org/abs/2505.11432
-
[29]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review arXiv 2001
-
[30]
Locality- centric data and threadblock management for massive gpus,
M. Khairy, V . Nikiforov, D. Nellans, and T. G. Rogers, “Locality- centric data and threadblock management for massive gpus,” in2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020, pp. 1022–1036
2020
-
[31]
Accel-sim: An extensible simulation framework for validated gpu modeling,
M. Khairy, Z. Shen, T. M. Aamodt, and T. G. Rogers, “Accel-sim: An extensible simulation framework for validated gpu modeling,” in 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020, pp. 473–486
2020
-
[32]
InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23)
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 611–626. [Online]. Availabl...
-
[33]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with conditional computation and automatic sharding,”arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review arXiv 2006
-
[34]
Accelerating distributed MoE training and inference with lina,
J. Li, Y . Jiang, Y . Zhu, C. Wang, and H. Xu, “Accelerating distributed MoE training and inference with lina,” in2023 USENIX Annual Technical Conference (USENIX ATC 23). Boston, MA: USENIX Association, Jul. 2023, pp. 945–959. [Online]. Available: https://www.usenix.org/conference/atc23/presentation/li-jiamin
2023
-
[35]
Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache,
B. Lin, C. Zhang, T. Peng, H. Zhao, W. Xiao, M. Sun, A. Liu, Z. Zhang, L. Li, X. Qiu, S. Li, Z. Ji, T. Xie, Y . Li, and W. Lin, “Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache,” 2024. [Online]. Available: https://arxiv.org/abs/2401.02669
-
[36]
Janus: A unified distributed training framework for sparse mixture-of-experts models,
J. Liu, J. H. Wang, and Y . Jiang, “Janus: A unified distributed training framework for sparse mixture-of-experts models,” inProceedings of the ACM SIGCOMM 2023 Conference, ser. ACM SIGCOMM ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 486–498. [Online]. Available: https://doi.org/10.1145/3603269.3604869
-
[37]
Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189,
E. Lu, Z. Jiang, J. Liu, Y . Du, T. Jiang, C. Hong, S. Liu, W. He, E. Yuan, Y . Wang, Z. Huang, H. Yuan, S. Xu, X. Xu, G. Lai, Y . Chen, H. Zheng, J. Yan, J. Su, Y . Wu, N. Y . Zhang, Z. Yang, X. Zhou, M. Zhang, and J. Qiu, “Moba: Mixture of block attention for long-context llms,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13189
-
[38]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation,
Meta AI, “The llama 4 herd: The beginning of a new era of natively multimodal ai innovation,”https://ai.meta.com/blog/llama-4- multimodal-intelligence/, checked on, vol. 4, no. 7, p. 2025, 2025
2025
-
[39]
Finepack: Transparently improving the efficiency of fine-grained trans- fers in multi-gpu systems,
H. Muthukrishnan, D. Lustig, O. Villa, T. Wenisch, and D. Nellans, “Finepack: Transparently improving the efficiency of fine-grained trans- fers in multi-gpu systems,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2023, pp. 516–529
2023
-
[40]
Efficient multi-gpu shared memory via automatic optimiza- tion of fine-grained transfers,
H. Muthukrishnan, D. Nellans, D. Lustig, J. A. Fessler, and T. F. Wenisch, “Efficient multi-gpu shared memory via automatic optimiza- tion of fine-grained transfers,” in2021 ACM/IEEE 48th Annual Interna- tional Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 139–152
2021
-
[41]
X. Nie, X. Miao, Z. Wang, Z. Yang, J. Xue, L. Ma, G. Cao, and B. Cui, “Flexmoe: Scaling large-scale sparse pre-trained model training via dynamic device placement,”Proc. ACM Manag. Data, vol. 1, no. 1, May 2023. [Online]. Available: https://doi.org/10.1145/3588964
-
[42]
Peer-to-peer & unified virtual addressing
NVIDIA, “Peer-to-peer & unified virtual addressing.” https://developer.download.nvidia.com/CUDA/training/cuda webinars GPUDirect uva.pdf, 2011
2011
-
[43]
Doubling all2all performance with nvidia collective communi- cation library 2.12,
——, “Doubling all2all performance with nvidia collective communi- cation library 2.12,”https://developer.nvidia.com/blog/doubling-all2all- performance-with/nvidia-collective-communication/library-2-12/, 2022
2022
-
[44]
Applying mixture of experts in llm architectures
——, “Applying mixture of experts in llm architectures.” https://developer.nvidia.com/blog/applying-mixture-of-experts-in-llm- architectures/, 2024
2024
-
[45]
Cuda templates for linear algebra subroutines
——, “Cuda templates for linear algebra subroutines.” https://github.com/NVIDIA/cutlass, 2024
2024
-
[46]
Introduction to nvidia dgx h100/h200 systems
——, “Introduction to nvidia dgx h100/h200 systems.” https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to- dgxh100.html, 2024
2024
-
[47]
New llm: Snowflake arctic model for sql and code generation
——, “New llm: Snowflake arctic model for sql and code generation.”https://developer.nvidia.com/blog/new-llm-snowflake-arctic- model-for-sql-and-code-generation/, 2024
2024
-
[48]
Mixture of experts powers the most intelligent frontier ai models, runs 10x faster to deliver 1/10 the token cost on nvidia blackwell nvl72
——, “Mixture of experts powers the most intelligent frontier ai models, runs 10x faster to deliver 1/10 the token cost on nvidia blackwell nvl72.” https://blogs.nvidia.com/blog/mixture-of-experts-frontier-models/, 2025
2025
-
[49]
Nvidia openshmem library (nvshmem) documentation
——, “Nvidia openshmem library (nvshmem) documentation.” https://docs.nvidia.com/nvshmem/api/index.html, 2025
2025
-
[50]
Transformer engine
——, “Transformer engine.”https://github.com/NVIDIA/TransformerEngine, 2025
2025
-
[51]
Gpt-oss
OpenAI, “Gpt-oss.”https://github.com/openai/gpt-oss, 2025
2025
-
[52]
Introducing gpt-5
——, “Introducing gpt-5.”https://openai.com/index/introducing-gpt-5, 2025
2025
-
[53]
T3: Transparent tracking & triggering for fine-grained overlap of compute & collectives,
S. Pati, S. Aga, M. Islam, N. Jayasena, and M. D. Sinclair, “T3: Transparent tracking & triggering for fine-grained overlap of compute & collectives,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2024, pp. 1146–1164
2024
-
[54]
Deepspeed-moe: Advancing mixture- of-experts inference and training to power next-generation ai scale,
S. Rajbhandari, C. Li, Z. Yao, M. Zhang, R. Y . Aminabadi, A. A. Awan, J. Rasley, and Y . He, “Deepspeed-moe: Advancing mixture- of-experts inference and training to power next-generation ai scale,” inInternational conference on machine learning. PMLR, 2022, pp. 18 332–18 346
2022
-
[55]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He, “Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,” inProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 3505– 3506
2020
-
[56]
Introducing dbrx: A new state-of-the-art open llm,
M. Research, “Introducing dbrx: A new state-of-the-art open llm,” https://www.databricks.com/blog/introducing-dbrx-new-state-art-open- llm, 2024
2024
-
[57]
Scaling vision with 15 sparse mixture of experts,
C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. Susano Pinto, D. Keysers, and N. Houlsby, “Scaling vision with 15 sparse mixture of experts,”Advances in Neural Information Processing Systems, vol. 34, pp. 8583–8595, 2021
2021
-
[58]
The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “The sparsely-gated mixture-of-experts layer,”Outrageously large neural networks, vol. 2, 2017
2017
-
[59]
Pipemoe: Accelerating mixture- of-experts through adaptive pipelining,
S. Shi, X. Pan, X. Chu, and B. Li, “Pipemoe: Accelerating mixture- of-experts through adaptive pipelining,” inIEEE INFOCOM 2023-IEEE Conference on Computer Communications. IEEE, 2023, pp. 1–10
2023
-
[60]
Schemoe: An extensible mixture-of-experts distributed training system with tasks scheduling,
S. Shi, X. Pan, Q. Wang, C. Liu, X. Ren, Z. Hu, Y . Yang, B. Li, and X. Chu, “Schemoe: An extensible mixture-of-experts distributed training system with tasks scheduling,” inProceedings of the Nineteenth European Conference on Computer Systems, 2024, pp. 236–249
2024
-
[61]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catan- zaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,”arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[62]
Pangu ultra moe: How to train your big moe on ascend npus,
Y . Tang, Y . Yin, Y . Wang, H. Zhou, Y . Pan, W. Guo, Z. Zhang, M. Rang, F. Liu, N. Zhang, B. Li, Y . Dong, X. Meng, Y . Wang, D. Li, Y . Li, D. Tu, C. Chen, Y . Yan, F. Yu, R. Tang, Y . Wang, B. Huang, B. Wang, B. Liu, C. Zhang, D. Kuang, F. Liu, G. Huang, J. Wei, J. Qin, J. Ran, J. Li, J. Zhao, L. Dai, L. Li, L. Deng, P. Qin, P. Zeng, Q. Gu, S. Tang, S...
-
[63]
Harnessing inter-gpu shared memory for seamless moe communication-computation fusion,
H. Wang, Y . Xia, D. Yang, X. Zhou, and D. Cheng, “Harnessing inter-gpu shared memory for seamless moe communication-computation fusion,” inProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, 2025, pp. 170–182
2025
-
[64]
Overlap communication with dependent computation via decomposition in large deep learning models,
S. Wang, J. Wei, A. Sabne, A. Davis, B. Ilbeyi, B. Hechtman, D. Chen, K. S. Murthy, M. Maggioni, Q. Zhang, S. Kumar, T. Guo, Y . Xu, and Z. Zhou, “Overlap communication with dependent computation via decomposition in large deep learning models,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and O...
-
[65]
Prophet: Fine-grained load balancing for parallel training of large- scale moe models,
W. Wang, Z. Lai, S. Li, W. Liu, K. Ge, Y . Liu, A. Shen, and D. Li, “Prophet: Fine-grained load balancing for parallel training of large- scale moe models,” in2023 IEEE International Conference on Cluster Computing (CLUSTER), 2023, pp. 82–94
2023
-
[66]
Xattention: Block sparse attention with antidiagonal scoring.arXiv preprint arXiv:2503.16428,
R. Xu, G. Xiao, H. Huang, J. Guo, and S. Han, “Xattention: Block sparse attention with antidiagonal scoring,” 2025. [Online]. Available: https://arxiv.org/abs/2503.16428
-
[67]
Moesys: A distributed and efficient mixture-of-experts training and inference system for internet services,
D. Yu, L. Shen, H. Hao, W. Gong, H. Wu, J. Bian, L. Dai, and H. Xiong, “Moesys: A distributed and efficient mixture-of-experts training and inference system for internet services,”IEEE Transactions on Services Computing, vol. 17, no. 5, pp. 2626–2639, 2024
2024
-
[68]
SmartMoE: Efficiently training Sparsely-Activated models through combining offline and online parallelization,
M. Zhai, J. He, Z. Ma, Z. Zong, R. Zhang, and J. Zhai, “SmartMoE: Efficiently training Sparsely-Activated models through combining offline and online parallelization,” in2023 USENIX Annual Technical Conference (USENIX ATC 23). Boston, MA: USENIX Association, Jul. 2023, pp. 961–975. [Online]. Available: https://www.usenix.org/conference/atc23/presentation/zhai
2023
-
[69]
Comet: Fine-grained computation-communication overlapping for mixture-of-experts,
S. Zhang, N. Zheng, H. Lin, Z. Jiang, W. Bao, C. Jiang, Q. Hou, W. Cui, S. Zheng, L.-W. Chang, Q. Chen, and X. Liu, “Comet: Fine-grained computation-communication overlapping for mixture-of-experts,” inProceedings of Machine Learning and Systems, M. Zaharia, G. Joshi, and Y . Lin, Eds., vol. 7. MLSys, 2025. [Online]. Available: https://proceedings.mlsys.o...
2025
-
[70]
Mpmoe: Memory efficient moe for pre-trained models with adaptive pipeline parallelism,
Z. Zhang, Y . Xia, H. Wang, D. Yang, C. Hu, X. Zhou, and D. Cheng, “Mpmoe: Memory efficient moe for pre-trained models with adaptive pipeline parallelism,”IEEE Transactions on Parallel and Distributed Systems, vol. 35, no. 6, pp. 998–1011, 2024
2024
-
[71]
Deepep: an efficient expert-parallel communication library,
C. Zhao, S. Zhou, L. Zhang, C. Deng, Z. Xu, Y . Liu, K. Yu, J. Li, and L. Zhao, “Deepep: an efficient expert-parallel communication library,” https://github.com/deepseek-ai/DeepEP, 2025. 16
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.