Recognition: unknown
Task-Aware Answer Preservation under Audio Compression for Large Audio Language Models
Pith reviewed 2026-05-08 03:33 UTC · model grok-4.3
The pith
A protocol certifies audio compression budgets only when they preserve answers for the worst query families in large audio models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
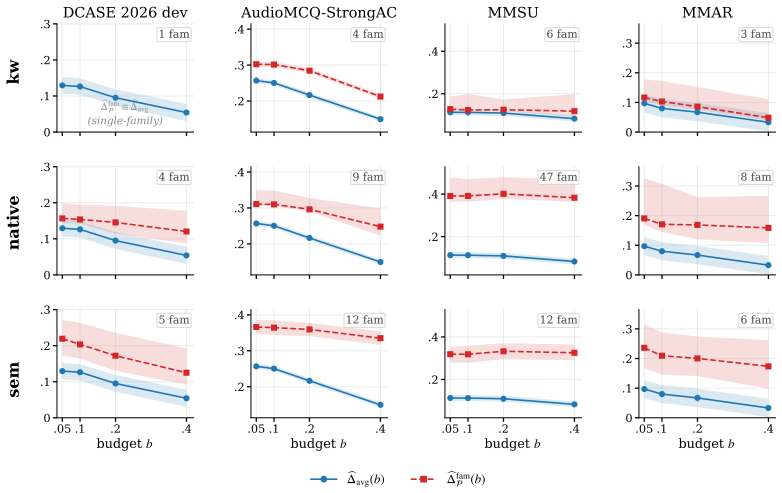
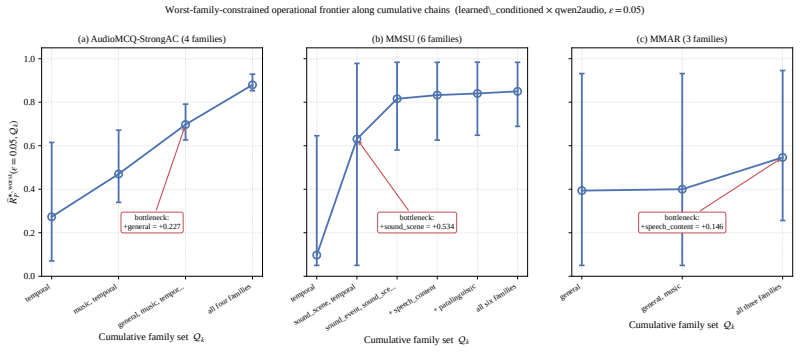
We formulate answer-preserving audio compression as a compressor acceptance-rejection criterion that accepts a scheme only when the excess answer-error it induces on the worst-affected query family remains below a chosen threshold. From this we derive a sign-off protocol returning compression budgets that satisfy the worst-family checks with statistical confidence. On five multiple-choice audio benchmarks with two Qwen-based models the protocol reveals family-level damage hidden by aggregate metrics, shows that the query-family partition alters the approved budget, and identifies regimes in which query-conditioned compression outperforms unconditional compression for answer preservation.
What carries the argument
The compressor acceptance-rejection criterion, which judges a compressor solely by the excess answer-error it causes on the single worst query family and is enforced by a sign-off protocol that returns statistically guaranteed budgets.
If this is right
- The approved compression budget changes when the partition of queries into families is altered.
- Query-conditioned compression passes the acceptance test at higher rates than unconditional compression in identifiable regimes.
- Aggregate accuracy can mask large degradations within individual query families.
- The protocol supplies explicit statistical confidence bounds for worst-family preservation.
Where Pith is reading between the lines
- The same worst-family check could be applied to other efficiency methods such as quantization or pruning.
- Automatic discovery of query families from unlabeled data would make the protocol more practical for new domains.
- Ongoing monitoring of family-level performance after deployment would catch distribution shifts that invalidate an earlier certification.
Load-bearing premise
The chosen query families and benchmarks capture the deployment scenarios where answer preservation is most critical.
What would settle it
A real-world deployment using a protocol-approved budget in which a previously untested but important query family shows answer-error rates well above the certified threshold.
Figures












read the original abstract
Large audio language models (LALMs) are increasingly used to reason over long audio clips, yet deployment often compresses audio before inference to reduce memory and latency. The risk is that compression can leave aggregate accuracy acceptable while sharply degrading answers for a deployment-critical query family. We study answer-preserving audio compression, judging a compressor by the excess answer-error it induces, especially for the worst-affected family. We formulate this theoretically as a compressor acceptance-rejection criterion, derive a practical sign-off protocol that returns compression budgets satisfying worst-family checks with statistical confidence, and evaluate it on five multiple-choice audio question-answering benchmarks with two Qwen-based backbones. The protocol exposes hidden family-level damage, shows that the chosen query-family partition can change the approved budget, and identifies regimes where query-conditioned compression helps maintain answer preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a framework for task-aware audio compression in large audio language models (LALMs) to preserve answers for critical query families. It introduces an acceptance-rejection criterion based on excess answer-error for the worst-affected family, derives a sign-off protocol that ensures worst-family checks with statistical confidence, and evaluates the approach on five multiple-choice audio question-answering benchmarks using two Qwen-based LALMs. Key findings include the exposure of hidden family-level damage under compression, the dependence of approved compression budgets on the choice of query-family partition, and scenarios where query-conditioned compression improves answer preservation.
Significance. If the results hold, this work is significant because it shifts the focus from aggregate accuracy to worst-case performance over deployment-critical query families in audio compression for LALMs. This is particularly relevant for real-world deployments where certain query types must remain reliable despite compression for efficiency. The provision of a practical protocol with statistical guarantees and the demonstration of query-conditioned compression benefits add practical value. The evaluation across multiple benchmarks supports generalizability.
major comments (2)
- §3.2 (protocol derivation): The acceptance-rejection criterion relies on a worst-family check with statistical bounding, but the manuscript does not specify how the query-family partition is validated or chosen independently of the data; the reported sensitivity to partition choice (as a finding) raises the risk that the approved budget is not robust to alternative reasonable partitions.
- Evaluation section, Table 2: The reported improvements from query-conditioned compression over standard methods are presented without accompanying p-values or confidence intervals on the difference in answer-error rates; this weakens the claim that query-conditioned compression 'helps maintain answer preservation' in identified regimes.
minor comments (3)
- Abstract: The five benchmarks are not named, which reduces immediate clarity for readers; listing them (e.g., as in §4.1) would help.
- Figure 4: The plots comparing approved budgets across partitions would benefit from explicit error bars or shaded regions indicating variability across the two Qwen backbones.
- §2 (related work): A few additional citations on recent audio compression methods for multimodal models would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address each major comment point by point below, indicating planned changes to the manuscript.
read point-by-point responses
-
Referee: §3.2 (protocol derivation): The acceptance-rejection criterion relies on a worst-family check with statistical bounding, but the manuscript does not specify how the query-family partition is validated or chosen independently of the data; the reported sensitivity to partition choice (as a finding) raises the risk that the approved budget is not robust to alternative reasonable partitions.
Authors: The query-family partition is intended to be supplied by the practitioner based on domain knowledge of deployment-critical query types (e.g., safety-related or domain-specific audio queries), rather than being derived or validated from the evaluation data. This design choice is inherent to the task-aware framing. The reported sensitivity to partition choice is presented as an empirical finding to highlight that different reasonable partitions can yield different approved budgets, thereby underscoring the need for careful, application-specific selection. In the revision we will clarify in §3.2 that the protocol takes a user-provided partition as input and is independent of the test data; we will also add brief guidance on constructing such partitions (e.g., via expert annotation on a held-out set or predefined task taxonomies). This addresses the robustness concern while preserving the core contribution. revision: partial
-
Referee: Evaluation section, Table 2: The reported improvements from query-conditioned compression over standard methods are presented without accompanying p-values or confidence intervals on the difference in answer-error rates; this weakens the claim that query-conditioned compression 'helps maintain answer preservation' in identified regimes.
Authors: We agree that quantitative statistical support will strengthen the empirical claims. In the revised manuscript we will augment Table 2 with p-values and 95% confidence intervals on the differences in answer-error rates between query-conditioned and baseline compression methods. These will be obtained via bootstrap resampling (or paired tests where appropriate) across the five benchmarks and two LALM backbones. The added statistics will directly support the identified regimes where query-conditioned compression improves answer preservation. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The provided abstract and context describe a theoretical formulation of an acceptance-rejection criterion for compressors, followed by derivation of a statistical sign-off protocol and empirical evaluation on benchmarks. No equations, fitted parameters, or self-citations are shown that reduce the protocol, worst-family checks, or query-family partitions to tautological inputs by construction. The sensitivity to query-family choice is presented as an empirical finding rather than a definitional necessity. The chain from theory to protocol to evaluation stands independently without load-bearing self-reference or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the landscape of spoken language models: A comprehensive survey.Transactions on Machine Learning Research, 2025
Siddhant Arora, Kai-Wei Chang, Chung-Ming Chien, Yifan Peng, Haibin Wu, Yossi Adi, Emmanuel Dupoux, Hung yi Lee, Karen Livescu, and Shinji Watanabe. On the landscape of spoken language models: A comprehensive survey.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URLhttps://openreview.net/ forum?id=BvxaP3sVbA
2025
-
[2]
Audiolm: a language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing, 31:2523–2533, 2023
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. Audiolm: a language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing, 31:2523–2533, 2023
2023
-
[3]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
John Wiley & Sons, 1999
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
1999
-
[5]
High fidelity neural audio compression.Transactions on Machine Learning Research, 2023
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression.Transactions on Machine Learning Research, 2023. ISSN 2835-8856
2023
-
[6]
An introduction to the bootstrap, 1993
Bradley Efron and R Tibshirani. An introduction to the bootstrap, 1993
1993
-
[7]
Model-aware rate-distortion limits for task-oriented source coding,
Andriy Enttsel and Vincent Corlay. Model-aware rate-distortion limits for task-oriented source coding.arXiv preprint arXiv:2602.12866, 2026
-
[8]
Increasing the confidence in student’st interval
Constantinos Goutis and George Casella. Increasing the confidence in student’st interval. The Annals of Statistics, 20(3):1501–1513, 1992
1992
-
[9]
Measuring audio’s impact on correctness: Audio-contribution-aware post-training of large audio language models
Haolin He, Xingjian Du, Renhe Sun, Zheqi Dai, Yujia Xiao, Mingru Yang, Jiayi Zhou, Xiquan Li, Zhengxi Liu, Zining Liang, Chunyat Wu, Qianhua He, Tan Lee, Xie Chen, Wei-Long Zheng, Weiqiang Wang, Mark Plumbley, Jian Liu, and Qiuqiang Kong. Measuring audio’s impact on correctness: Audio-contribution-aware post-training of large audio language models. InInte...
2026
-
[10]
Channel selection using gumbel softmax
Charles Herrmann, Richard Strong Bowen, and Ramin Zabih. Channel selection using gumbel softmax. InEuropean conference on computer vision, pages 241–257. Springer, 2020
2020
-
[11]
Estimating mutual information.Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, 69(6): 066138, 2004
Alexander Kraskov, Harald Stögbauer, and Peter Grassberger. Estimating mutual information.Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, 69(6): 066138, 2004
2004
-
[12]
The history of bootstrapping: Tracing the development of resampling with replacement.The Mathematics Enthusiast, 18(1):78–99, 2021
Denise LaFontaine. The history of bootstrapping: Tracing the development of resampling with replacement.The Mathematics Enthusiast, 18(1):78–99, 2021
2021
-
[13]
Sufficiency and approximate sufficiency.The Annals of Mathematical Statistics, pages 1419–1455, 1964
L Le. Sufficiency and approximate sufficiency.The Annals of Mathematical Statistics, pages 1419–1455, 1964
1964
-
[14]
Ls-eend: Long-form streaming end-to-end neural diarization with online attractor extraction.IEEE Transactions on Audio, Speech and Language Processing, 2025
Di Liang and Xiaofei Li. Ls-eend: Long-form streaming end-to-end neural diarization with online attractor extraction.IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[15]
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, Wenxi Chen, Yuanzhe Chen, Zhuo Chen, Jian Cong, Kai Li, Keliang Li, Siyou Li, Xinfeng Li, Xiquan Li, Zheng Lian, Yuzhe Liang, Minghao Liu, Zhikang Niu, Tianrui Wang, Yuping Wang, Yuxuan Wang, Yihao Wu, Guanrou Yang, Jianwei Yu, Ruibin Yuan, Zhisheng Zheng, Ziya Zhou, Haina Zhu, Wei Xu...
-
[16]
An exploration of log-mel spectrogram and MFCC features for Alzheimer’s dementia recognition from spontaneous speech
Amit Meghanani, Chandran Savithri Anoop, and AG Ramakrishnan. An exploration of log-mel spectrogram and MFCC features for Alzheimer’s dementia recognition from spontaneous speech. In2021 IEEE spoken language technology workshop (SLT), pages 670–677. IEEE, 2021
2021
-
[17]
Fundamental limits of prompt compression: A rate-distortion framework for black-box language models.Advances in Neural Information Processing Systems, 37:94934–94970, 2024
Alliot Nagle, Adway Girish, Marco Bondaschi, Michael Gastpar, Ashok Vardhan Makkuva, and Hyeji Kim. Fundamental limits of prompt compression: A rate-distortion framework for black-box language models.Advances in Neural Information Processing Systems, 37:94934–94970, 2024
2024
-
[18]
On measures of entropy and information
Alfréd Rényi. On measures of entropy and information. InProceedings of the fourth Berkeley symposium on mathematical statistics and probability, volume 1: contributions to the theory of statistics, volume 4, pages 547–562. University of California Press, 1961
1961
-
[19]
Michael Smithson.Confidence intervals. 140. Sage, 2003
2003
-
[20]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.arXiv preprint arXiv:2206.04615, 2022
work page internal anchor Pith review arXiv 2022
-
[21]
Challenging big-bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023
2023
-
[22]
The information bottleneck method
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method.arXiv preprint physics/0004057, 2000
work page internal anchor Pith review arXiv 2000
-
[23]
Kullback-leibler distance as a measure of the information filtered from multivariate data.Physical Review E-Statistical, Nonlinear, and Soft Matter Physics, 76(3):031123, 2007
Michele Tumminello, Fabrizio Lillo, and Rosario N Mantegna. Kullback-leibler distance as a measure of the information filtered from multivariate data.Physical Review E-Statistical, Nonlinear, and Soft Matter Physics, 76(3):031123, 2007
2007
-
[24]
Towards understanding chain-of-thought prompting: An empirical study of what matters
Dingdong Wang, Junan Li, Jincenzi Wu, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. MMSU: A massive multi-task spoken language understanding and reasoning benchmark, 2026. URLhttps://arxiv.org/abs/2506.04779
-
[25]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Multi-domain audio question answering benchmark toward acoustic content reasoning, 2026
Chao-Han Huck Yang, Sreyan Ghosh, Qing Wang, Jaeyeon Kim, Hengyi Hong, Sonal Kumar, Guirui Zhong, Zhifeng Kong, S Sakshi, Vaibhavi Lokegaonkar, Oriol Nieto, Ramani Duraiswami, Dinesh Manocha, Gunhee Kim, Jun Du, Rafael Valle, and Bryan Catanzaro. Multi-domain audio question answering benchmark toward acoustic content reasoning, 2026. URLhttps://arxiv.org/...
-
[27]
Batude: Budget-aware neural network compression based on tucker decomposition
Miao Yin, Huy Phan, Xiao Zang, Siyu Liao, and Bo Yuan. Batude: Budget-aware neural network compression based on tucker decomposition. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8874–8882, 2022
2022
-
[28]
what word was spoken?
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2021. 11 Limitations Query-family coarsening.The formal object is query-level or familywise Bayes risk over Q, while the experiments approximate it wi...
2021
-
[29]
Truncated selector training.Both selectors terminate well short of the nominal schedule, and the conditioned selector terminates earlier than the agnostic selector
-
[30]
Parameter asymmetry dominated by the query embedding.The conditioned selector’s large parameter count is almost entirely the token embedding table; its scoring core is only modestly larger than the agnostic selector’s
-
[31]
Mel-spectrogram input features.V1 selectors operate on 768-dimensional mel features rather than the backbone’s native 1280-dimensional audio-tower embeddings. None of these caveats affect the structural findings on the family-level excess-risk gap, nested monotonicity, or factor overlap; they interact with the operational conditioned-gain estimate in §I.6...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.