Unlocking Crowdsourcing for Ontology Matching Validation
Pith reviewed 2026-05-20 21:59 UTC · model grok-4.3
The pith
Crowdsourcing can validate ontology matches at scale when equipped with differential trustworthiness, coherence pre-filling, and time-dependent opinion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
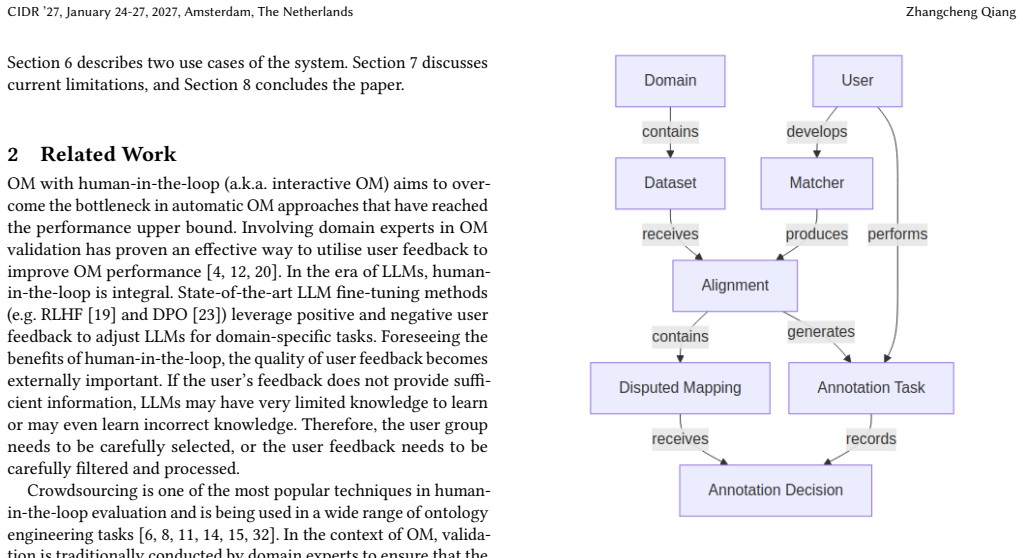
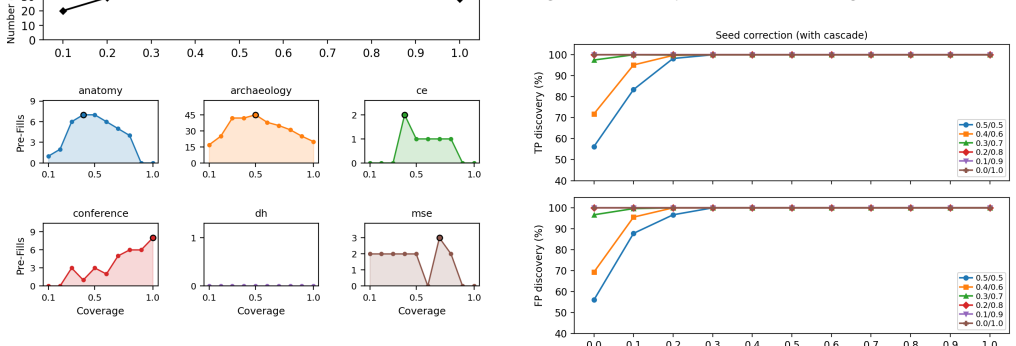
The central claim is that crowdsourcing becomes viable for ontology-matching validation once it incorporates differential trustworthiness to weight contributors by observed reliability, coherence pre-filling to seed later annotations with consistent earlier ones, and time-dependent opinion to model how judgments evolve. With these controls the platform delivers validation quality sufficient for human-in-the-loop use and works for diverse user groups and annotation regimes.
What carries the argument
The three mechanisms—differential trustworthiness, coherence pre-filling, and time-dependent opinion—that together enforce quality in crowdsourced ontology-matching validation.
If this is right
- Existing ontology-matching systems can add a human-in-the-loop validation stage without expert-only staffing.
- The platform supports varied user groups and annotation settings while preserving output quality.
- Two concrete real-world use cases become feasible once crowdsourcing replaces sole reliance on experts.
- Identified limitations supply concrete directions for further quality-control refinements.
Where Pith is reading between the lines
- The same quality controls could be tested on other knowledge-graph alignment tasks where expert time is scarce.
- If the mechanisms prove domain-robust, they might lower the cost of maintaining large, evolving ontologies.
- A natural extension would measure how much the time-dependent component improves accuracy when workers return to the same task after a delay.
Load-bearing premise
The three mechanisms keep crowdsourced validation quality comparable to that of domain experts across different ontology domains and user groups.
What would settle it
A controlled study in which crowdsourced annotations produced with the three mechanisms show substantially lower agreement with expert gold standards than expert-to-expert agreement, on a previously unseen ontology domain.
Figures



read the original abstract
Recent advances in large language models (LLMs) pose new challenges for ontology matching (OM). While OM systems built on LLMs have shown remarkable capabilities in discovering more matching candidates, traditional OM validation that relies on domain experts has become overwhelming. In this study, we explore the use of crowdsourcing for OM validation and introduce a novel crowdsourcing system. We propose three domain-specific mechanisms, namely differential trustworthiness, coherence pre-filling, and time-dependent opinion, to ensure the quality of crowdsourcing for OM validation. We demonstrate that our crowdsourcing system can be integrated with existing OM systems to enable human-in-the-loop validation. The evaluation of the system shows its effectiveness in handling diverse user groups and different annotation settings. We discuss two real-world use cases of the system and current limitations for improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses challenges in ontology matching (OM) validation arising from LLM-based OM systems that generate many candidate matches. It proposes a crowdsourcing system incorporating three domain-specific mechanisms—differential trustworthiness, coherence pre-filling, and time-dependent opinion—to maintain validation quality. The system is designed for integration with existing OM tools to support human-in-the-loop processes. The manuscript claims that evaluations demonstrate effectiveness across diverse user groups and annotation settings, and it discusses two real-world use cases along with current limitations.
Significance. If the three mechanisms can be shown to deliver validation quality comparable to domain experts across varied ontology domains, this approach would offer a scalable alternative to expert-only validation, which has become a bottleneck. The emphasis on integration with existing OM systems and real-world use cases indicates potential for immediate practical adoption in semantic web and knowledge engineering applications.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claim that the crowdsourcing system with the three mechanisms 'shows its effectiveness' rests on assertions of performance across diverse user groups, yet the manuscript supplies no quantitative metrics, baselines, statistical tests, dataset sizes, or inter-annotator agreement figures. This absence directly undermines verification of the weakest assumption that the mechanisms maintain quality sufficient to replace or augment domain experts.
- [Mechanisms] Mechanisms section: The descriptions of differential trustworthiness, coherence pre-filling, and time-dependent opinion are presented as jointly ensuring quality, but no formal definition, pseudocode, or interaction analysis is provided to show how these mechanisms address specific failure modes in OM validation (e.g., noisy crowdsourced judgments on complex alignments). Without such grounding, the claim that their combination is domain-specific and effective remains untestable.
minor comments (2)
- [Use Cases] The manuscript would benefit from explicit comparison tables showing crowdsourced validation accuracy versus expert baselines in the reported use cases.
- [System Architecture] Clarify the exact integration points with existing OM systems (e.g., which OM outputs feed into the crowdsourcing interface) to strengthen the human-in-the-loop claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional rigor and detail will strengthen the presentation of our crowdsourcing approach for ontology matching validation. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central claim that the crowdsourcing system with the three mechanisms 'shows its effectiveness' rests on assertions of performance across diverse user groups, yet the manuscript supplies no quantitative metrics, baselines, statistical tests, dataset sizes, or inter-annotator agreement figures. This absence directly undermines verification of the weakest assumption that the mechanisms maintain quality sufficient to replace or augment domain experts.
Authors: We agree that the evaluation section would be strengthened by explicit quantitative details. The manuscript currently summarizes effectiveness across user groups and annotation settings at a high level without reporting specific metrics or tests. In the revised version we will expand this section to report dataset sizes, inter-annotator agreement (e.g., Fleiss' kappa), quantitative performance metrics such as precision/recall/F1 relative to expert baselines, and appropriate statistical tests. These additions will provide verifiable support for the quality claims. revision: yes
-
Referee: [Mechanisms] Mechanisms section: The descriptions of differential trustworthiness, coherence pre-filling, and time-dependent opinion are presented as jointly ensuring quality, but no formal definition, pseudocode, or interaction analysis is provided to show how these mechanisms address specific failure modes in OM validation (e.g., noisy crowdsourced judgments on complex alignments). Without such grounding, the claim that their combination is domain-specific and effective remains untestable.
Authors: We accept that the mechanisms section would benefit from greater formality. The current text describes the three mechanisms conceptually but does not supply formal definitions or pseudocode. We will revise the section to include mathematical definitions for each mechanism, pseudocode illustrating their operation, and a brief analysis of how their combination mitigates specific failure modes such as noisy judgments on complex alignments. This will make the domain-specific design and joint effectiveness more explicit and testable. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is a system-description and evaluation work with no equations, derivations, or formal chains. The three mechanisms are introduced as novel proposals and their effectiveness is asserted via integration with OM systems plus empirical evaluation on diverse users and settings. No load-bearing step reduces by construction to a fitted input, self-definition, or self-citation chain; the central claims rest on external validation results rather than internal re-labeling of inputs.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.