Recognition: no theorem link
Data-aware candidate selection in NL2SQL translation via small separating instances
Pith reviewed 2026-05-13 03:22 UTC · model grok-4.3
The pith
Small separating instances enable better selection of the correct SQL from NL2SQL candidates when only two or three options are available.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
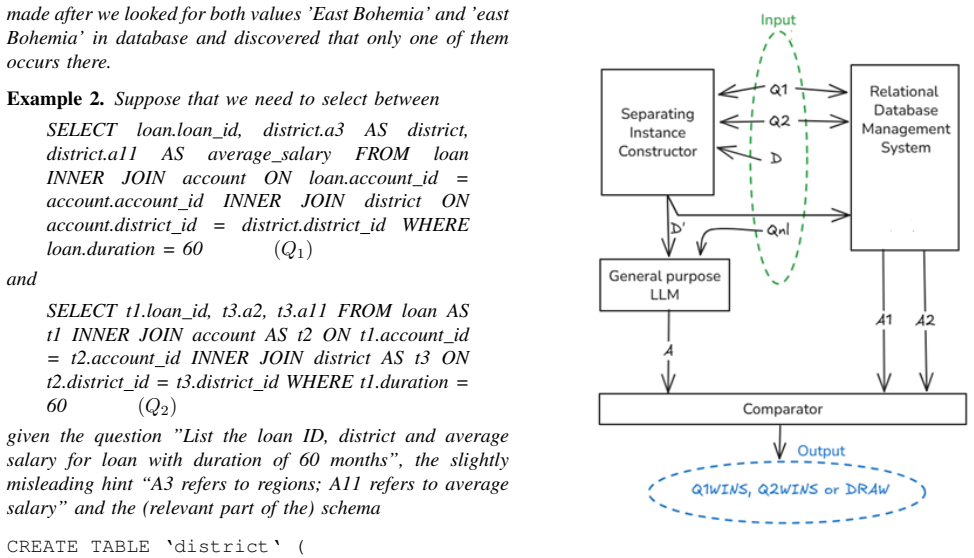
We propose a data-aware candidate selection method for NL2SQL translation based on separating instances and provenance. We implement this approach and evaluate it against three natural baselines on a subset of BIRD-DEV. Experiments show that our method significantly outperforms baselines when only two or three candidates are given and no consistency score is available.
What carries the argument
Small separating instances with provenance: minimal database states that produce different outputs or data paths for the correct SQL translation versus incorrect candidates, allowing distinction without external scores.
Load-bearing premise
Small separating instances can be identified efficiently and that they reliably distinguish the correct candidate on the BIRD-DEV subset and similar data.
What would settle it
Executing the prototype on the BIRD-DEV subset with only two or three candidates and observing that it does not significantly outperform the baselines, or that instance generation is too slow for repeated use.
Figures


read the original abstract
We propose a data-aware candidate selection method for NL2SQL translation based on separating instances and provenance. We implement this approach and evaluate it against three natural baselines on a subset of BIRD-DEV. Experiments show that our method significantly outperforms baselines when only two or three candidates are given and no consistency score is available. The code of our prototype can be found at https://github.com/staskikotx/SISelection
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a data-aware candidate selection method for NL2SQL that identifies small separating instances (minimal databases distinguishing candidate SQL queries) together with provenance to pick the correct candidate from a small set. The approach is implemented and evaluated against three baselines on a subset of BIRD-DEV; experiments indicate significant outperformance when only two or three candidates are supplied and no consistency score is available. Prototype code is released on GitHub.
Significance. If the empirical results hold under broader conditions, the method offers a practical, data-driven way to disambiguate NL2SQL candidates without relying on model confidence or consistency checks. The separating-instance idea is a fresh angle for candidate selection and the public code supports reproducibility. Significance is currently limited by the narrow evaluation scope (one benchmark subset) and the unstated cost of generating separating instances at scale.
major comments (2)
- [§4] §4 (Evaluation): the claim of significant outperformance rests on results for a BIRD-DEV subset, yet the text supplies neither the subset size, selection criteria, nor any statistical test or error bars. This information is load-bearing for assessing whether the reported gains are robust.
- [§3] §3 (Approach): the efficiency of identifying small separating instances is asserted as a precondition but no complexity analysis or worst-case size bounds relative to the original database are provided; this directly affects the practicality claim when candidate sets grow.
minor comments (2)
- [Abstract] Abstract: the phrase 'significantly outperforms' should be accompanied by the actual accuracy deltas or win rates for the 2- and 3-candidate regimes.
- Notation: the distinction between 'separating instance' and 'provenance' is introduced without a compact formal definition; a short boxed definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation of minor revision. We address each major comment below and will revise the manuscript accordingly to improve transparency and completeness.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): the claim of significant outperformance rests on results for a BIRD-DEV subset, yet the text supplies neither the subset size, selection criteria, nor any statistical test or error bars. This information is load-bearing for assessing whether the reported gains are robust.
Authors: We agree that these details are necessary to assess robustness. The manuscript does not currently specify the subset size, selection criteria, or include statistical tests or error bars. In the revised version, we will add the subset size, describe the selection criteria (queries from BIRD-DEV with 2-3 candidates and no consistency score), and incorporate error bars with basic statistical measures to support the significance of the gains. revision: yes
-
Referee: [§3] §3 (Approach): the efficiency of identifying small separating instances is asserted as a precondition but no complexity analysis or worst-case size bounds relative to the original database are provided; this directly affects the practicality claim when candidate sets grow.
Authors: We acknowledge the lack of formal complexity analysis. We will revise §3 to include a discussion of the practical efficiency observed in our experiments, where separating instances remain small, and clarify that the method targets small candidate sets (2-3 queries). A full worst-case analysis relative to database size is not provided, as it depends on query fragments and schemas outside the paper's scope; we will note this as a limitation for future work. revision: partial
Circularity Check
No significant circularity; purely empirical evaluation
full rationale
The paper proposes and empirically evaluates a data-aware candidate selection method for NL2SQL translation using separating instances and provenance. It reports performance gains over three baselines on a BIRD-DEV subset when only 2-3 candidates are supplied. No equations, derivations, fitted parameters, or formal proofs appear in the provided text. The central claim rests on experimental comparison rather than any chain that reduces by construction to its own inputs, self-citations, or ansatzes. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Small separating instances exist and can be found for the candidate SQL queries on the target database.
Reference graph
Works this paper leans on
-
[1]
Text-to-sql benchmarks are broken: An in-depth analysis of annotation errors
T. Jin, Y . Choi, Y . Zhu, and D. Kang, “Text-to-sql benchmarks are broken: An in-depth analysis of annotation errors.”
-
[2]
Alpha- sql: Zero-shot text-to-sql using monte carlo tree search,
B. Li, J. Zhang, J. Fan, Y . Xu, C. Chen, N. Tang, and Y . Luo, “Alpha- sql: Zero-shot text-to-sql using monte carlo tree search,”arXiv preprint arXiv:2502.17248, 2025
-
[3]
Clear: A parser-independent disambiguation framework for nl2sql,
M. Zhang, K. Ma, L. Xu, K. Zhang, Y . Peng, and R. Jin, “Clear: A parser-independent disambiguation framework for nl2sql,” in2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 2025, pp. 1–14
work page 2025
-
[4]
VeriEQL: Bounded equivalence verification for complex SQL queries with integrity constraints,
Y . He, P. Zhao, X. Wang, and Y . Wang, “VeriEQL: Bounded equivalence verification for complex SQL queries with integrity constraints,”Pro- ceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA1, pp. 1071–1099, 2024
work page 2024
-
[5]
L. De Moura and N. Bjørner, “Z3: An efficient smt solver,” inInter- national conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 2008, pp. 337–340
work page 2008
-
[6]
Automated validating and fixing of Text-to-SQL translation with execution consistency,
Y . Yang, Z. Wang, Y . Xia, Z. Wei, H. Ding, R. Piskac, H. Chen, and J. Li, “Automated validating and fixing of Text-to-SQL translation with execution consistency,”Proceedings of the ACM on Management of Data, vol. 3, no. 3, pp. 1–28, 2025
work page 2025
-
[7]
Explaining wrong queries using small examples,
Z. Miao, S. Roy, and J. Yang, “Explaining wrong queries using small examples,” inProceedings of the 2019 International Conference on Management of Data, 2019, pp. 503–520
work page 2019
-
[8]
P. Buneman and W.-C. Tan, “Provenance in databases,” inProceedings of the 2007 ACM SIGMOD international conference on Management of data, 2007, pp. 1171–1173
work page 2007
-
[9]
T. J. Green, G. Karvounarakis, and V . Tannen, “Provenance semirings,” inProceedings of the twenty-sixth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, 2007, pp. 31–40
work page 2007
-
[10]
Gprom-a swiss army knife for your provenance needs,
“Gprom-a swiss army knife for your provenance needs,”A Quarterly bulletin of the Computer Society of the IEEE Technical Committee on Data Engineering, vol. 41, no. 1, 2018
work page 2018
-
[11]
Provsql: A general system for keeping track of the provenance and probability of data,
A. Sen, S. Maniu, and P. Senellart, “Provsql: A general system for keeping track of the provenance and probability of data,”arXiv preprint arXiv:2504.12058, 2025
-
[12]
Grounding natural language to sql translation with data-based self-explanations,
Y . Fan, T. Ren, C. Huang, Z. He, and X. S. Wang, “Grounding natural language to sql translation with data-based self-explanations,” in 2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 2025, pp. 29–42
work page 2025
-
[13]
SpotIt+: Verification-based Text-to-SQL Evaluation with Database Constraints
R. Klopfenstein, Y . He, A. Tremante, Y . Wang, N. Narodytska, and H. Wu, “Spotit+: Verification-based text-to-sql evaluation with database constraints,”arXiv preprint arXiv:2603.04334, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
DPC: Training-Free Text-to-SQL Candidate Selection via Dual-Paradigm Consistency
B. Li, O. O. K. Hei, Y . Yu, and Y . Luo, “Dpc: Training-free text-to-sql candidate selection via dual-paradigm consistency,” 2026. [Online]. Available: https://arxiv.org/abs/2604.15163
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Automatic metadata extraction for text-to-SQL,
V . Shkapenyuk, D. Srivastava, T. Johnson, and P. Ghane, “Automatic metadata extraction for text-to-SQL,”arXiv preprint arXiv:2505.19988, 2025
-
[16]
Chase-SQL: Multi-path reasoning and preference optimized candidate selection in text-to-sql,
M. Pourreza, H. Li, R. Sun, Y . Chung, S. Talaei, G. T. Kakkar, Y . Gan, A. Saberi, F. Ozcan, and S. O. Arik, “Chase-SQL: Multi-path reasoning and preference optimized candidate selection in text-to-sql,” arXiv preprint arXiv:2410.01943, 2024
-
[17]
XiYan-SQL: A Novel Multi-Generator Framework For Text-to-SQL
Y . Liu, Y . Zhu, Y . Gao, Z. Luo, X. Li, X. Shi, Y . Hong, J. Gao, Y . Li, B. Dinget al., “Xiyan-sql: A novel multi-generator framework for text- to-sql,”arXiv preprint arXiv:2507.04701, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Available: https://github.com/ContextualAI/bird-sql
[Online]. Available: https://github.com/ContextualAI/bird-sql
-
[19]
Available: https://github.com/GSR-SQL/GSR
[Online]. Available: https://github.com/GSR-SQL/GSR
-
[20]
CSC-SQL: Corrective self-consistency in text- to-SQL via reinforcement learning,
L. Sheng and S.-S. Xu, “CSC-SQL: Corrective self-consistency in text- to-SQL via reinforcement learning,”arXiv preprint arXiv:2505.13271, 2025
-
[21]
M. Pourreza, S. Talaei, R. Sun, X. Wan, H. Li, A. Mirhoseini, A. Saberi, S. Ariket al., “Reasoning-sql: Reinforcement learning with sql tai- lored partial rewards for reasoning-enhanced text-to-sql,”arXiv preprint arXiv:2503.23157, 2025
-
[22]
Cheaper, Better, Faster, Stronger: Robust Text-to-SQL without Chain-of-Thought or Fine-Tuning
Y . D. D ¨onder, D. Hommel, A. W. Wen-Yi, D. Mimno, and U. E. S. Jo, “Cheaper, better, faster, stronger: Robust text-to-sql without chain- of-thought or fine-tuning,”arXiv preprint arXiv:2505.14174, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Opensearch-sql: Enhancing text- to-sql with dynamic few-shot and consistency alignment,
X. Xie, G. Xu, L. Zhao, and R. Guo, “Opensearch-sql: Enhancing text- to-sql with dynamic few-shot and consistency alignment,”Proceedings of the ACM on Management of Data, vol. 3, no. 3, pp. 1–24, 2025
work page 2025
-
[24]
Memo-sql: Structured decomposition and experience-driven self- correction for training-free nl2sql,
Z. Yang, W. Wang, Y . Xu, L. Song, Y . Matsuda, W. Han, and B. Bai, “Memo-sql: Structured decomposition and experience-driven self- correction for training-free nl2sql,”arXiv preprint arXiv:2601.10011, 2026
-
[25]
Omnisql: Synthesizing high-quality text-to-sql data at scale,
H. Li, S. Wu, X. Zhang, X. Huang, J. Zhang, F. Jiang, S. Wang, T. Zhang, J. Chen, R. Shiet al., “Omnisql: Synthesizing high-quality text-to-sql data at scale,”arXiv preprint arXiv:2503.02240, 2025
-
[26]
The death of schema linking? text-to-sql in the age of well-reasoned language models,
K. Maamari, F. Abubaker, D. Jaroslawicz, and A. Mhedhbi, “The death of schema linking? text-to-sql in the age of well-reasoned language models,”arXiv preprint arXiv:2408.07702, 2024
-
[27]
DeepEye-SQL: A Software-Engineering-Inspired Text-to-SQL Framework
B. Li, C. Chen, Z. Xue, Y . Mei, and Y . Luo, “Deepeye-sql: A software-engineering-inspired text-to-sql framework,”arXiv preprint arXiv:2510.17586, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Chess: Contextual harnessing for efficient sql synthesis,
S. Talaei, M. Pourreza, Y .-C. Chang, A. Mirhoseini, and A. Saberi, “Chess: Contextual harnessing for efficient sql synthesis,”arXiv preprint arXiv:2405.16755, 2024
-
[29]
Agentar-scale-sql: Advancing text-to-sql through orchestrated test-time scaling,
P. Wang, B. Sun, X. Dong, Y . Dai, H. Yuan, M. Chu, Y . Gao, X. Qi, P. Zhang, and Y . Yan, “Agentar-scale-sql: Advancing text-to-sql through orchestrated test-time scaling,”arXiv preprint arXiv:2509.24403, 2025
-
[30]
[Online]. Available: https://github.com/HKUSTDial/Alpha-SQL/blob/ master/alphasql/runner/preprocessor.py APPENDIXA PROMPTTEMPLATE FORBASEALGORITHM. You are an experienced database expert. You need to ,→evaluate a query in natural language into a small ,→set of tuples of values, given the database ,→information, the database instance, a question and ,→some...
work page 2063
-
[31]
The SQL should accurately represent the question
-
[32]
The SQL should accurately use the given knowledge ,→evidence
-
[33]
The SELECT clause should not include any additional ,→columns that are not included in the question
-
[34]
The order of column(s) in the SELECT clause must be the ,→same as the order in the question
-
[35]
Check if the operations are being performed correctly ,→according to the column type. ### Database Schema: {DB_SCHEMA} ### Question: {QUESTION} ### Knowledge Evidence: {KNOWLEDGE_EVIDENCE} ### Candidate SQL Queries: {SQL_QUERIES} ### Your answer should strictly follow the following json ,→format: ‘‘‘json {{ "principles": "", // The principles involved in ...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.