Recognition: unknown
MUJICA: Multi-skill Unified Joint Integration of Control Architecture for Wheeled-Legged Robots
Pith reviewed 2026-05-14 19:08 UTC · model grok-4.3
The pith
A single policy integrates omnidirectional moving, climbing, and fall recovery for wheeled-legged robots using only proprioceptive sensing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MUJICA is a fully proprioceptive control architecture that trains diverse skills—omnidirectional moving, high platform climbing, and fall recovery—jointly within a single policy distinguished by unique indicator variables, incorporating accurate DC-motor constraint modeling, and uses a learned high-level skill selector to dynamically choose the optimal skill based on proprioceptions alone.
What carries the argument
The unified policy with skill indicator variables and a proprioceptive high-level skill selector that enables adaptive locomotion mode selection.
If this is right
- The robot achieves seamless transitions across locomotion modes in response to environmental changes.
- Sim-to-real robustness is enhanced through the joint training and motor modeling.
- Autonomous adjustment to unstructured environments becomes possible without external sensing.
- Task success rates improve in complex terrains on hardware like the Unitree Go2-W.
Where Pith is reading between the lines
- This method could simplify control systems by eliminating the need for multiple separate policies in hybrid robots.
- Similar joint training approaches might apply to other robot types requiring multiple behaviors.
- Testing on additional tasks such as manipulation during locomotion could reveal further capabilities.
Load-bearing premise
The assumption that joint training in simulation with indicator variables and accurate DC-motor models is sufficient to enable robust real-world performance and reliable skill selection without any real-world fine-tuning or additional sensors.
What would settle it
A real-world experiment where the robot encounters a high platform and either successfully climbs using the selected skill or fails to do so, or fails to recover from a fall using proprioception alone.
Figures






read the original abstract
Wheeled-legged robots hold promise for traversing complex terrains and offer superior mobility compared to legged robots. However, wheeled-legged robots must effectively balance both wheeled driving and legged control. Furthermore, due to noisy proprioceptive sensing and real-world motor constraints, realizing robust and adaptive locomotion at peak performance of motors remains challenging. We propose the Multi-skill Unified Joint Integration of Control Architecture (MUJICA), a unified, fully proprioceptive control framework for wheeled-legged robots that integrates diverse low-level skills-including omnidirectional moving, high platform climbing, and fall recovery-within a single policy. All skills, distinguished by unique indicator variables, are trained jointly with accurate DC-motor constraint modeling. Additionally, a high-level skill selector is learned to dynamically choose the optimal skill based solely on proprioceptions, enabling adaptive responses to the surrounding environment. Therefore, MUJICA enhances sim-to-real robustness and enables seamless transitions across diverse locomotion modes, facilitating autonomous adjustment to the environment. We validate our framework in both simulation and real-world experiments on the Unitree Go2-W robot, demonstrating significant improvements in adaptability and task success in unstructured environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MUJICA, a unified proprioceptive control framework for wheeled-legged robots that jointly trains a single policy integrating multiple skills (omnidirectional locomotion, high-platform climbing, and fall recovery) distinguished by indicator variables, incorporates accurate DC-motor modeling in simulation, and learns a high-level selector that chooses skills based solely on proprioceptive inputs. The framework is evaluated in simulation and on the physical Unitree Go2-W platform, with claims of improved sim-to-real robustness and seamless skill transitions in unstructured environments.
Significance. If the empirical claims hold under rigorous quantitative scrutiny, the work would offer a practical route to versatile hybrid locomotion without maintaining separate policies or relying on external sensing, addressing a recognized gap in wheeled-legged control. The joint-training approach with motor constraints and proprioceptive selection is a concrete contribution that could generalize to other multi-modal platforms.
major comments (2)
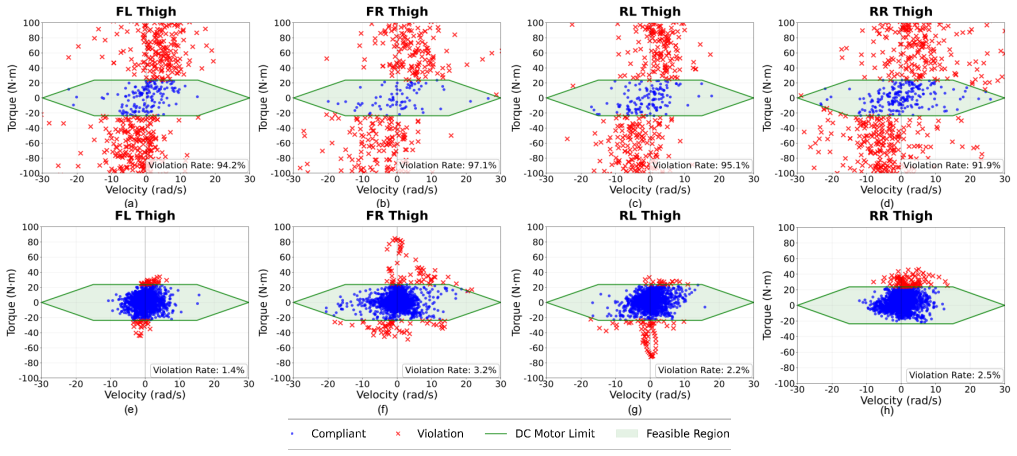
- [§4] §4 (Experimental validation): the abstract and results claim significant improvements in adaptability and task success on the Unitree Go2-W, yet no quantitative baselines, ablation studies on the indicator variables or selector, success-rate statistics, or error metrics versus prior methods are reported; this absence prevents verification that the unified policy and proprioceptive selector outperform simpler alternatives or that gains are not due to post-hoc tuning.
- [§3.2] §3.2 (High-level skill selector): the central sim-to-real claim rests on the selector learning reliable skill choice from noisy proprioception alone after joint training; the manuscript provides no explicit domain-randomization schedule, noise model details, or real-world adaptation procedure, leaving open whether the selector generalizes beyond simulation artifacts.
minor comments (2)
- Notation for the skill indicator variables is introduced without a compact table summarizing their values and corresponding behaviors; adding such a table would improve readability.
- Figure captions for the real-robot experiments should explicitly state the number of trials and environmental variations tested rather than relying on qualitative descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the empirical validation and methodological details.
read point-by-point responses
-
Referee: [§4] §4 (Experimental validation): the abstract and results claim significant improvements in adaptability and task success on the Unitree Go2-W, yet no quantitative baselines, ablation studies on the indicator variables or selector, success-rate statistics, or error metrics versus prior methods are reported; this absence prevents verification that the unified policy and proprioceptive selector outperform simpler alternatives or that gains are not due to post-hoc tuning.
Authors: We agree that the current manuscript would benefit from more rigorous quantitative analysis to support the claims of improved adaptability and task success. In the revised version, we will add: success-rate statistics and error metrics from both simulation and real-world experiments on the Unitree Go2-W; ablation studies isolating the effects of the indicator variables and the high-level selector; and comparisons against baselines including separate skill-specific policies and variants without proprioceptive selection. These additions will provide direct evidence that the unified joint-training approach outperforms simpler alternatives. revision: yes
-
Referee: [§3.2] §3.2 (High-level skill selector): the central sim-to-real claim rests on the selector learning reliable skill choice from noisy proprioception alone after joint training; the manuscript provides no explicit domain-randomization schedule, noise model details, or real-world adaptation procedure, leaving open whether the selector generalizes beyond simulation artifacts.
Authors: We acknowledge that additional details on the training and transfer process are necessary. The revised manuscript will expand §3.2 to include the full domain-randomization schedule (terrain, friction, and motor parameter ranges), the specific noise models applied to proprioceptive observations during training, and the real-world deployment procedure, which relies on the robustness induced by joint training with accurate DC-motor constraints rather than online adaptation. These clarifications will better substantiate the sim-to-real generalization of the proprioceptive selector. revision: yes
Circularity Check
No significant circularity; empirical training and validation chain is self-contained
full rationale
The paper proposes an empirical control architecture (MUJICA) that jointly trains a single policy in simulation using indicator variables to distinguish skills and accurate DC-motor modeling, then learns a proprioceptive high-level selector, with final claims resting on sim-to-real experiments on the Unitree Go2-W. No derivation chain, equations, or predictions reduce to inputs by construction; there are no self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations that close the loop. The framework is validated against external physical benchmarks rather than internal fits, making the result independent of any circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward weights and skill indicator scaling
axioms (2)
- domain assumption Proprioceptive signals alone are sufficient to distinguish and select among locomotion skills in unstructured environments
- domain assumption Accurate DC-motor constraint modeling in simulation closes the sim-to-real gap for peak-performance locomotion
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning for robotics: A survey of real- world successes,
C. Tang, B. Abbatematteo, J. Hu, R. Chandra, R. Mart ´ın-Mart´ın, and P. Stone, “Deep reinforcement learning for robotics: A survey of real- world successes,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 27, 2025, pp. 28 694–28 698
2025
-
[2]
Moe-loco: Mixture of experts for multitask locomotion,
R. Huang, S. Zhu, Y . Du, and H. Zhao, “Moe-loco: Mixture of experts for multitask locomotion,”arXiv preprint arXiv:2503.08564, 2025
-
[3]
Deep reinforcement learning in mixture of experts control system for blind wheeled-legged quadrupedal locomo- tion,
W. Zhang and K. Wang, “Deep reinforcement learning in mixture of experts control system for blind wheeled-legged quadrupedal locomo- tion,” in2024 International Conference on Advanced Robotics and Intelligent Systems (ARIS). IEEE, 2024, pp. 1–5
2024
-
[4]
I. Nahrendra, B. Yu, and H. Myung, “Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,”arXiv preprint arXiv:2301.10602, 2023
-
[5]
Fr-net: Learning robust quadrupedal fall recovery on challenging terrains through mass-contact prediction,
Y . Lu, Y . Dong, J. Zhang, J. Ma, and P. Lu, “Fr-net: Learning robust quadrupedal fall recovery on challenging terrains through mass-contact prediction,”IEEE Robotics and Automation Letters, 2025
2025
-
[6]
Renet: Fault-tolerant motion control for quadruped robots via redun- dant estimator networks under visual collapse,
Y . Zhang, Q. Qian, T. Hou, P. Zhai, X. Wei, K. Hu, J. Yi, and L. Zhang, “Renet: Fault-tolerant motion control for quadruped robots via redun- dant estimator networks under visual collapse,”IEEE Robotics and Automation Letters, pp. 1–8, 2025
2025
-
[7]
Learning robust autonomous navigation and locomotion for wheeled- legged robots,
J. Lee, M. Bjelonic, A. Reske, L. Wellhausen, T. Miki, and M. Hutter, “Learning robust autonomous navigation and locomotion for wheeled- legged robots,”Science Robotics, vol. 9, no. 89, p. eadi9641, 2024
2024
-
[8]
Reinforcement learning for blind stair climbing with legged and wheeled-legged robots,
S. Chamorro, V . Klemm, M. d. L. I. Valls, C. Pal, and R. Siegwart, “Reinforcement learning for blind stair climbing with legged and wheeled-legged robots,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 8081–8087
2024
-
[9]
Mtac: Hierarchical reinforcement learning-based multi-gait terrain-adaptive quadruped controller,
N. Shah, K. Tiwari, and A. Bera, “Mtac: Hierarchical reinforcement learning-based multi-gait terrain-adaptive quadruped controller,”arXiv preprint arXiv:2401.03337, 2023
-
[10]
Allgaits: Learning all quadruped gaits and transitions,
G. Bellegarda, M. Shafiee, and A. Ijspeert, “Allgaits: Learning all quadruped gaits and transitions,” in2025 IEEE International Confer- ence on Robotics and Automation (ICRA). IEEE, 2025, pp. 15 929– 15 935
2025
-
[11]
Versatile skill control via self-supervised adversarial imitation of unlabeled mixed motions,
C. Li, S. Blaes, P. Kolev, M. Vlastelica, J. Frey, and G. Martius, “Versatile skill control via self-supervised adversarial imitation of unlabeled mixed motions,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 2944–2950
2023
-
[12]
Penalized proximal policy optimization for safe reinforcement learning,
L. Zhang, L. Shen, L. Yang, S. Chen, B. Yuan, X. Wang, and D. Tao, “Penalized proximal policy optimization for safe reinforcement learning,”arXiv preprint arXiv:2205.11814, 2022
-
[13]
Not only rewards but also constraints: Applications on legged robot locomotion,
Y . Kim, H. Oh, J. Lee, J. Choi, G. Ji, M. Jung, D. Youm, and J. Hwangbo, “Not only rewards but also constraints: Applications on legged robot locomotion,”IEEE Transactions on Robotics, vol. 40, pp. 2984–3003, 2024
2024
-
[14]
Guided constrained policy optimization for dynamic quadrupedal robot locomotion,
S. Gangapurwala, A. Mitchell, and I. Havoutis, “Guided constrained policy optimization for dynamic quadrupedal robot locomotion,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3642–3649, 2020
2020
-
[15]
Agile continuous jumping in discontinuous terrains,
Y . Yang, G. Shi, C. Lin, X. Meng, R. Scalise, M. G. Castro, W. Yu, T. Zhang, D. Zhao, J. Tanet al., “Agile continuous jumping in discontinuous terrains,”arXiv preprint arXiv:2409.10923, 2024
-
[16]
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
J. Tan, T. Zhang, E. Coumans, A. Iscen, Y . Bai, D. Hafner, S. Bo- hez, and V . Vanhoucke, “Sim-to-real: Learning agile locomotion for quadruped robots,”arXiv preprint arXiv:1804.10332, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Rma: Rapid motor adaptation for legged robots
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “Rma: Rapid motor adaptation for legged robots,”arXiv preprint arXiv:2107.04034, 2021
-
[18]
Hybrid internal model: Learning agile legged locomotion with simulated robot response,
J. Long, Z. Wang, Q. Li, J. Gao, L. Cao, and J. Pang, “Hybrid internal model: Learning agile legged locomotion with simulated robot response,”arXiv preprint arXiv:2312.11460, 2023
-
[19]
Cat: Constraints as terminations for legged locomotion reinforcement learning,
E. Chane-Sane, P.-A. Leziart, T. Flayols, O. Stasse, P. Sou `eres, and N. Mansard, “Cat: Constraints as terminations for legged locomotion reinforcement learning,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 13 303– 13 310
2024
-
[20]
I. Dadiotis, M. Mittal, N. Tsagarakis, and M. Hutter, “Dynamic object goal pushing with mobile manipulators through model-free constrained reinforcement learning,”arXiv preprint arXiv:2502.01546, 2025
-
[21]
Alarm: Safe reinforcement learning with reliable mimicry for robust legged locomotion,
Q. Zhou, H. Ding, T. Chen, L. Man, H. Jiang, G. Zhang, B. Li, X. Rong, and Y . Li, “Alarm: Safe reinforcement learning with reliable mimicry for robust legged locomotion,”IEEE Robotics and Automa- tion Letters, 2025
2025
-
[22]
Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
E. Parisotto, J. L. Ba, and R. Salakhutdinov, “Actor-mimic: Deep multitask and transfer reinforcement learning,”arXiv preprint arXiv:1511.06342, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
Distral: Robust multitask reinforcement learning,
Y . Teh, V . Bapst, W. M. Czarnecki, J. Quan, J. Kirkpatrick, R. Hadsell, N. Heess, and R. Pascanu, “Distral: Robust multitask reinforcement learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[24]
Multi-expert learning of adaptive legged locomotion,
C. Yang, K. Yuan, Q. Zhu, W. Yu, and Z. Li, “Multi-expert learning of adaptive legged locomotion,”Science Robotics, vol. 5, no. 49, p. eabb2174, 2020
2020
-
[25]
Discovery of skill switching criteria for learning agile quadruped locomotion,
W. Yu, F. Acero, V . Atanassov, C. Yang, I. Havoutis, D. Kanoulas, and Z. Li, “Discovery of skill switching criteria for learning agile quadruped locomotion,”arXiv preprint arXiv:2502.06676, 2025
-
[26]
Versatile skill control via self-supervised adversarial imitation of unlabeled mixed motions,
C. Li, S. Blaes, P. Kolev, M. Vlastelica, J. Frey, and G. Martius, “Versatile skill control via self-supervised adversarial imitation of unlabeled mixed motions,”arXiv preprint arXiv:2209.07899, 2022
-
[27]
Unsupervised learning of visual features by contrasting cluster assign- ments,
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assign- ments,”Advances in neural information processing systems, vol. 33, pp. 9912–9924, 2020
2020
-
[28]
Asymmetric Actor Critic for Image-Based Robot Learning
L. Pinto, M. Andrychowicz, P. Welinder, W. Zaremba, and P. Abbeel, “Asymmetric actor critic for image-based robot learning,”arXiv preprint arXiv:1710.06542, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Actuator-constrained reinforcement learning for high-speed quadrupedal locomotion,
Y .-H. Shin, T.-G. Song, G. Ji, and H.-W. Park, “Actuator-constrained reinforcement learning for high-speed quadrupedal locomotion,”arXiv preprint arXiv:2312.17507, 2023
-
[31]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on robot learning. PMLR, 2022, pp. 91–100
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.