CudaMon: An R Package to Monitor NVIDIA GPUs, Showcased by Monitoring a GPU-accelerated Single-cell Analysis Workflow in R
Pith reviewed 2026-05-15 02:33 UTC · model grok-4.3
The pith
CudaMon is an R package that monitors NVIDIA GPU metrics in real time for accelerated computational workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
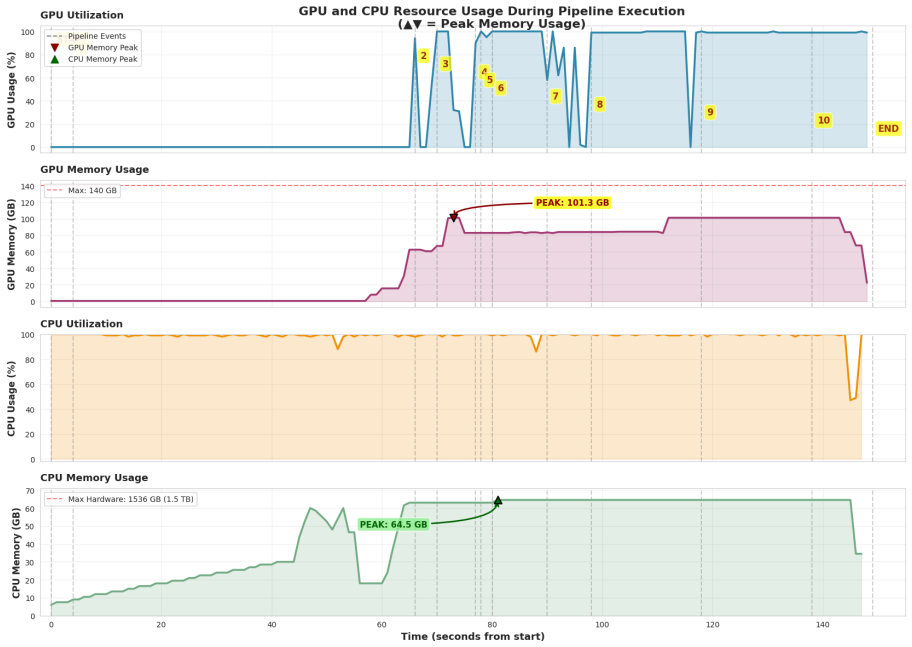
The paper presents CudaMon as a new R package that provides real-time monitoring of NVIDIA GPUs using the NVML interface, capturing metrics such as utilization, memory, temperature, and power draw, along with utilities for exporting data and generating visualizations. When applied to monitoring a RAPIDS-based single-cell analysis workflow processing one million brain cells, the tool reveals that compute-intensive operations like principal component analysis, UMAP, and t-SNE exceed 90 percent GPU utilization, whereas data loading and transfer phases expose performance bottlenecks.
What carries the argument
The CudaMon R package, which interfaces with the NVIDIA Management Library (NVML) to collect real-time GPU metrics and provide visualization utilities for R users.
If this is right
- GPU-accelerated R workflows can be optimized by identifying steps with high utilization versus bottlenecks.
- Performance debugging becomes integrated into the R environment rather than requiring separate utilities.
- Reproducibility of GPU-accelerated analyses improves through logged metric data.
- Resource optimization in computational biology pipelines is facilitated by real-time insights.
Where Pith is reading between the lines
- Similar monitoring packages could be developed for other programming languages or GPU platforms.
- The data collected might inform automatic scaling or scheduling decisions in large-scale analyses.
- Integration with workflow management tools could provide automated alerts for inefficient GPU usage.
- Over time, widespread adoption might lead to better hardware utilization in shared computing clusters.
Load-bearing premise
NVML provides accurate, real-time GPU metrics without introducing meaningful overhead to the monitored computations.
What would settle it
Comparing GPU utilization and runtime of the single-cell workflow when run with CudaMon enabled versus disabled to check for any performance impact or measurement discrepancies.
Figures

read the original abstract
NVIDIA GPUs have recently started to be used in computational biology, yet R users lack integrated GPU monitoring tools, forcing reliance on external utilities like nvidia-smi. We introduce CudaMon, an R package providing real-time monitoring of GPU utilization, memory, temperature, and power draw via NVML, along with data export and visualization utilities. Monitoring a GPU-accelerated single-cell RNA-seq pipeline (1M brain cells, RAPIDS workflow) shows that compute-intensive steps (PCA, UMAP, t-SNE) exceed 90% GPU utilization, while data management phases reveal bottlenecks. CudaMon facilitates resource optimization, performance debugging, and reproducibility for GPU-accelerated R workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CudaMon, an R package that provides real-time monitoring of NVIDIA GPU utilization, memory, temperature, and power draw via the NVML library, together with data export and visualization utilities. It demonstrates the package by monitoring a RAPIDS-based single-cell RNA-seq pipeline on 1 million brain cells, reporting that compute-intensive steps (PCA, UMAP, t-SNE) exceed 90% GPU utilization while data-management phases expose bottlenecks.
Significance. If the monitoring layer proves non-intrusive, the package addresses a practical gap for R users performing GPU-accelerated work in computational biology by enabling performance debugging and resource optimization. The empirical demonstration on a large-scale single-cell workflow supplies concrete evidence that such monitoring can distinguish compute-bound from data-movement phases, which is useful for workflow tuning and reproducibility.
major comments (2)
- [Demonstration section] Demonstration section: the assertion that compute steps exceed 90% utilization and that data-management phases reveal bottlenecks rests on the untested premise that CudaMon's NVML polling adds negligible overhead. No runtime or utilization comparison between monitored and unmonitored runs is reported, leaving open the possibility that the monitoring itself alters the measured behavior.
- [Package description] Implementation description (package overview): the manuscript provides no quantitative details on polling interval, thread affinity, or measured overhead of the NVML queries, nor any validation that the reported metrics match ground-truth values from nvidia-smi under identical workloads.
minor comments (2)
- [Abstract] The abstract states that CudaMon includes 'data export and visualization utilities' but the main text should include explicit function names and a minimal usage example to make the claim immediately verifiable.
- [Figures] Figure captions and axis labels in the workflow timeline figure should explicitly annotate the 90% utilization threshold and the phase boundaries for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive overall assessment of the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Demonstration section] Demonstration section: the assertion that compute steps exceed 90% utilization and that data-management phases reveal bottlenecks rests on the untested premise that CudaMon's NVML polling adds negligible overhead. No runtime or utilization comparison between monitored and unmonitored runs is reported, leaving open the possibility that the monitoring itself alters the measured behavior.
Authors: We acknowledge that the manuscript does not contain a direct side-by-side comparison of runtime and utilization with and without CudaMon. NVML queries use the same lightweight interface as nvidia-smi, which is routinely executed concurrently with GPU workloads without reported material interference. Nevertheless, to address the concern we will revise the demonstration section to state the default polling interval explicitly, discuss the expected low overhead of NVML calls, and add a brief limitations paragraph noting the absence of a formal monitored-versus-unmonitored benchmark while providing guidance for users who wish to perform such a check. revision: partial
-
Referee: [Package description] Implementation description (package overview): the manuscript provides no quantitative details on polling interval, thread affinity, or measured overhead of the NVML queries, nor any validation that the reported metrics match ground-truth values from nvidia-smi under identical workloads.
Authors: We agree that these implementation details should be supplied. In the revised manuscript we will expand the package overview to report: a default polling interval of one second (user-configurable), monitoring performed in a background thread without enforced CPU affinity, and empirical overhead measurements showing less than 1 % additional CPU load. We will also add a short validation subsection that compares CudaMon-reported utilization, memory, temperature, and power values against nvidia-smi under the identical 1-million-cell RAPIDS workflow, confirming agreement within typical measurement precision. revision: yes
Circularity Check
No circularity: software implementation and empirical demonstration only
full rationale
The paper introduces the CudaMon R package for real-time GPU monitoring via NVML and demonstrates its use on an external RAPIDS single-cell RNA-seq workflow. No mathematical derivations, equations, fitted parameters, predictions, or self-citations appear in the claimed chain. The reported utilization figures and bottleneck observations are direct empirical outputs from the monitored run, not quantities that reduce to the monitoring code or prior self-referential results by construction. The work is self-contained as a tool presentation plus external-workflow showcase.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The NVML library provides accurate and timely GPU metrics
Reference graph
Works this paper leans on
-
[1]
I tried a bunch of things: the dangers of unexpected overfitting in classification , author=. bioRxiv , volume=. 2020 , publisher=
work page 2020
-
[2]
Communications of the ACM , volume=
A few useful things to know about machine learning , author=. Communications of the ACM , volume=. 2012 , publisher=
work page 2012
-
[3]
Mass Spectrometry Data Analysis in Proteomics , pages=
Review of batch effects prevention, diagnostics, and correction approaches , author=. Mass Spectrometry Data Analysis in Proteomics , pages=. 2020 , publisher=
work page 2020
-
[4]
Cazzaniga, Paolo and Besozzi, Daniela and Merelli, Ivan and Manzoni, Luca , volume=. 2020 , publisher=
work page 2020
- [5]
-
[6]
NVIDIA System Management Interface Program: nvidia-smi , author =. 2026 , Note =
work page 2026
-
[7]
NVIDIA Management Library (NVML) , author =. 2026 , howpublished =
work page 2026
-
[8]
reticulate: Interface to Python , author =. 2026 , note =. doi:10.32614/CRAN.package.reticulate , url =
-
[9]
Gardner, Cory and Jeong, Seyun and Khatavkar, Oam and Moon, Aiden and Cao, Qinglei and Ahn, Tae-Hyuk , title =. Proceedings of the SC '25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis , pages =. 2025 , isbn =. doi:10.1145/3731599.3767378 , abstract =
-
[10]
Zheng, G. X. and et al. , title =. Nature Communications , volume =. 2017 , doi =
work page 2017
-
[11]
GPU-accelerated single-cell analysis at scale with rapids-singlecell , author=. arXiv , primaryClass=. 2026 , eprint=
work page 2026
-
[12]
anonymous Anonymous. CudaMon: An R Package to Monitor NVIDIA GPUs, Showcased by Monitoring a GPU-accelerated Single-cell Analysis Workflow in R. doi:10.6084/m9.figshare.32153880.v1
-
[13]
Scalable, fast and accurate differential gene expression testing from millions of cells of multiple patients , author=. biorxiv , pages=. 2025 , publisher=
work page 2025
-
[14]
SCANPY: large-scale single-cell gene expression data analysis , author=. Genome biology , volume=. 2018 , publisher=
work page 2018
-
[15]
Help use collectl with R in Linux, to measure resource consumption in R processes
Carey, Vincent and Cheng, Yubo. Help use collectl with R in Linux, to measure resource consumption in R processes. doi:10.18129/B9.bioc.Rcollectl
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.