Malleable Molecular Dynamics Simulations with GROMACS and DMR
Pith reviewed 2026-06-30 20:27 UTC · model grok-4.3
The pith
GROMACS integrated with DMR becomes malleable, dynamically adjusting MPI process counts via checkpoint-restart to cut node-hour use on bursty workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that DMR can be combined with GROMACS checkpoint/restart to produce a malleable molecular-dynamics engine whose MPI process count adapts at runtime; when the workload is sufficiently bursty, the net node-hour cost falls below that of any fixed allocation even after paying reconfiguration overhead.
What carries the argument
DMR middleware API for MPI malleability, paired with communication-efficiency-aware reconfiguration and GROMACS native checkpoint/restart.
If this is right
- Static allocations become unnecessary for workloads whose compute demand changes during a single run.
- Queue delays shrink because jobs can start with fewer processes and grow later.
- Idle nodes decrease when a job shrinks during low-demand phases.
- Overall node-hour billing for GROMACS users falls when burstiness exceeds reconfiguration cost.
Where Pith is reading between the lines
- The same checkpoint-restart plus reconfiguration pattern could be applied to other MPI codes that already support restarts.
- If the measured overheads remain low across more workloads, batch schedulers may begin to expose malleability APIs by default.
- A follow-up test could vary the frequency of reconfiguration calls to find the burstiness threshold at which savings appear.
Load-bearing premise
The combined cost of reconfiguration and checkpoint/restart stays small enough, and the workload varies enough, that total node-hours drop below those of a static run.
What would settle it
A controlled experiment in which every dynamic run consumes more total node-hours than an equivalent static run for the same final molecular configuration would falsify the savings claim.
Figures
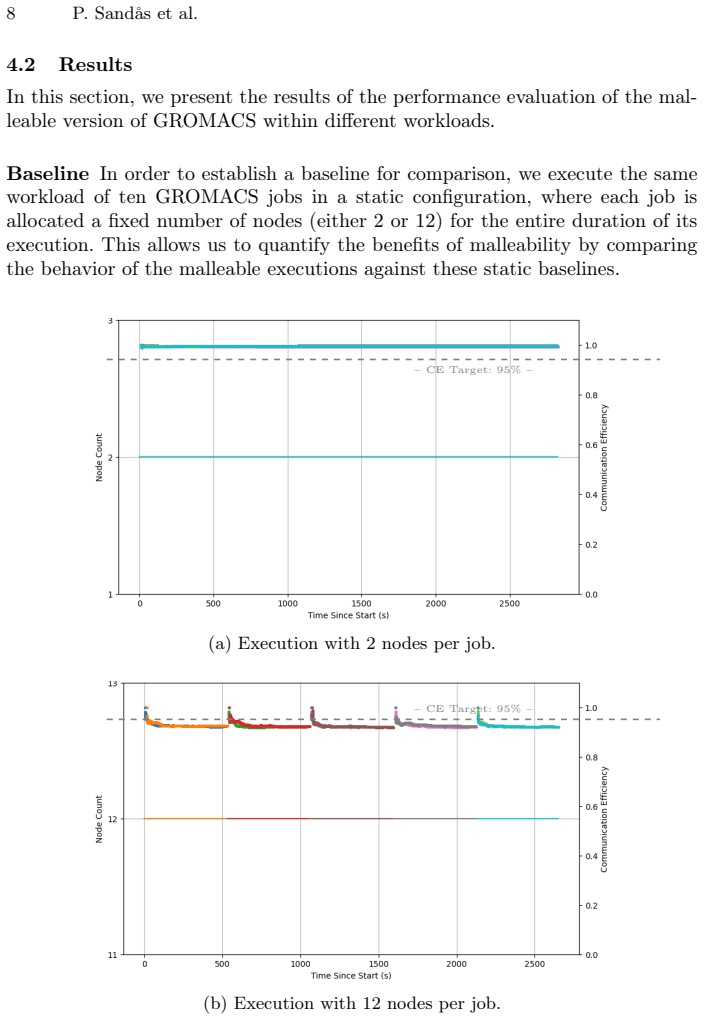
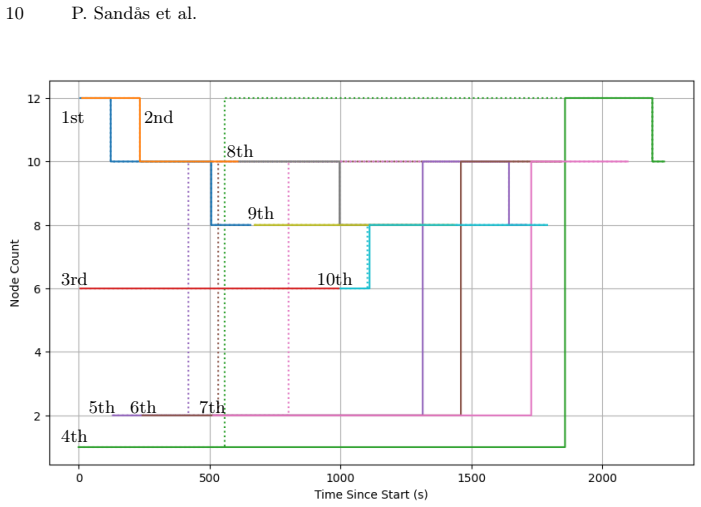
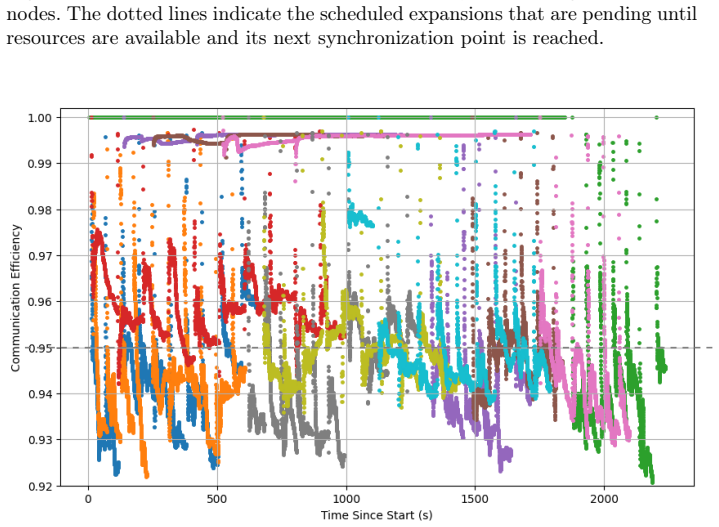
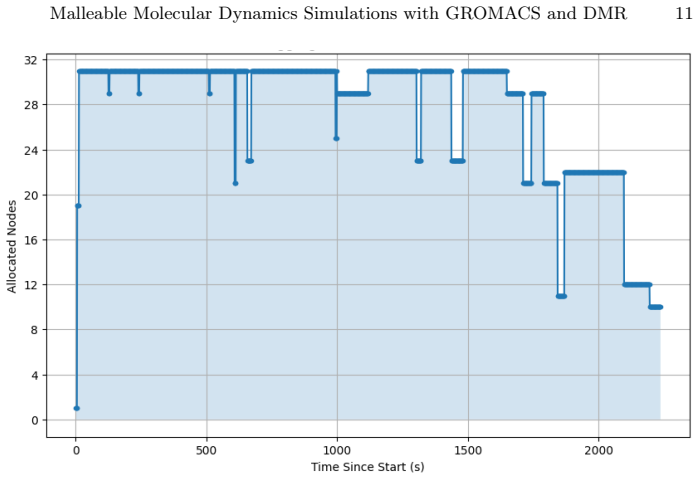
read the original abstract
Static resource allocations in high-performance computing (HPC) lead to inefficiencies for time-varying workloads, causing idle resources, queue delays, and higher node-hour costs. The Dynamic Management of Resources (DMR) middleware enables MPI process malleability in Slurm via a simple API decoupled from scheduler internals. In this work, we integrate DMR into the GROMACS molecular dynamics engine to obtain a malleable variant that can dynamically adapt its MPI process count by combining communication-efficiency-aware reconfiguration with GROMACS' native checkpoint/restart mechanism. We evaluate this design on the MareNostrum~5 supercomputer, comparing dynamic runs against static executions and quantifying reconfiguration overheads, time-to-solution, and node-hour savings for bursty GROMACS workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes the integration of the Dynamic Management of Resources (DMR) middleware into the GROMACS molecular dynamics engine. This produces a malleable variant capable of dynamically adapting its MPI process count during execution by combining DMR's communication-efficiency-aware reconfiguration with GROMACS' native checkpoint/restart mechanism. The work evaluates the approach on the MareNostrum 5 supercomputer by comparing dynamic runs to static allocations and reports measurements of reconfiguration overheads, time-to-solution, and node-hour savings specifically for bursty GROMACS workloads.
Significance. If the reported measurements confirm that reconfiguration overhead remains low enough relative to avoided idle-resource waste to produce net node-hour savings on bursty workloads, the result would be a practical contribution to resource-efficient HPC scheduling for molecular dynamics. The reliance on existing GROMACS checkpoint/restart and a scheduler-agnostic DMR API increases the likelihood of adoption in production MD workflows.
major comments (2)
- [Evaluation] The abstract states that overheads, time-to-solution, and node-hour savings are quantified on MareNostrum 5, yet no numerical values, tables, or figures with these data appear in the provided manuscript text. Because the central claim of net savings rests on reconfiguration cost being low relative to burst-induced waste, the evaluation section must include the concrete measurements (with error bars) that demonstrate this threshold is crossed for the tested workloads.
- [Results] The weakest assumption—that DMR reconfiguration plus checkpoint/restart overhead is low enough and workloads sufficiently bursty for net benefit—is load-bearing. The manuscript should add an explicit comparison (e.g., a table or plot) showing measured overhead versus savings per workload burst pattern so readers can verify the condition under which the malleable variant outperforms static allocation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for explicit evaluation data. We will revise the manuscript to include the requested measurements and comparisons.
read point-by-point responses
-
Referee: [Evaluation] The abstract states that overheads, time-to-solution, and node-hour savings are quantified on MareNostrum 5, yet no numerical values, tables, or figures with these data appear in the provided manuscript text. Because the central claim of net savings rests on reconfiguration cost being low relative to burst-induced waste, the evaluation section must include the concrete measurements (with error bars) that demonstrate this threshold is crossed for the tested workloads.
Authors: We acknowledge that the submitted manuscript text did not include the concrete numerical results, tables, or figures from the MareNostrum 5 experiments. In the revised version we will add a dedicated evaluation section presenting the measured reconfiguration overheads, time-to-solution values, and node-hour savings (with error bars) for the bursty workloads, explicitly demonstrating that the net savings threshold is crossed. revision: yes
-
Referee: [Results] The weakest assumption—that DMR reconfiguration plus checkpoint/restart overhead is low enough and workloads sufficiently bursty for net benefit—is load-bearing. The manuscript should add an explicit comparison (e.g., a table or plot) showing measured overhead versus savings per workload burst pattern so readers can verify the condition under which the malleable variant outperforms static allocation.
Authors: We agree that an explicit side-by-side comparison is required. The revised manuscript will include a table or plot directly comparing measured reconfiguration overhead against node-hour savings for each tested burst pattern, enabling readers to verify the conditions under which the malleable variant yields net benefit over static allocation. revision: yes
Circularity Check
No circularity: software integration and empirical measurements only
full rationale
The paper describes a practical engineering task: integrating the DMR middleware API into GROMACS to enable dynamic MPI process count changes via the existing checkpoint/restart mechanism, followed by runtime measurements of overhead, time-to-solution, and node-hour usage on MareNostrum 5. No equations, fitted parameters, uniqueness theorems, or derivations are present. The central claim is an existence result (the integration works and produces measured savings on bursty workloads) that is directly falsifiable by the reported timings; it does not reduce to any self-referential definition or self-citation chain. Self-citations, if any, are incidental and not load-bearing for the result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
eu/(2021), started December 2021 – Coordinated by Barcelona Supercomputing Center (BSC)
Eupilot: Pilot using independent, local and open technologies.https://eupilot. eu/(2021), started December 2021 – Coordinated by Barcelona Supercomputing Center (BSC)
2021
-
[2]
and Murtola, Teemu and Schulz, Roland and Páll, Szilárd and Smith, Jeremy C
Abraham, M.J., Murtola, T., Schulz, R., Páll, S., Smith, J.C., Hess, B., Lin- dahl, E.: GROMACS: High performance molecular simulations through multi- level parallelism from laptops to supercomputers. SoftwareX1-2, 19–25 (2015). https://doi.org/10.1016/j.softx.2015.06.001
-
[3]
Gabriel, E., Fagg, G.E., Bosilca, G., Angskun, T., Dongarra, J.J., Squyres, J.M., Sahay, V., Kambadur, P., Barrett, B., Lumsdaine, A., Castain, R.H., Daniel, D.J., Graham, R.L., Woodall, T.S.: Open MPI: Goals, concept, and design of a next generation MPI implementation. In: Recent Advances in Parallel Virtual Machine and Message Passing Interface. pp. 97–...
-
[4]
Journal of Chemical Theory and Computation4(3), 435–447 (2008)
Hess, B., Kutzner, C., van der Spoel, D., Lindahl, E.: Gromacs 4: Al- gorithms for highly efficient, load-balanced, and scalable molecular simula- tion. Journal of Chemical Theory and Computation4(3), 435–447 (2008). https://doi.org/10.1021/ct700301q
-
[5]
In: Proceedings of the 36th Parallel CFD International Conference
Iserte, S., Houzeaux, G., Sandås, P., Peña, A.J., Garcia-Gasulla, M.: Malleable computational fluid dynamics simulations. In: Proceedings of the 36th Parallel CFD International Conference. Merida, Yucatan, Mexico (Nov 2025)
2025
-
[6]
International Journal of High Performance Computing Application33, 1–10 (Aug 2018)
Iserte,S.,Martínez,H.,Barrachina,S.,Castillo,M.,Mayo,R.,Peña,A.J.:Dynamic reconfiguration of non-iterative scientific applications: A case study with HPG- aligner. International Journal of High Performance Computing Application33, 1–10 (Aug 2018). https://doi.org/10.1177/1094342018802347
-
[7]
IEEE Transactions on Computers 70, 1443–1457 (Sep 2020)
Iserte, S., Mayo, R., Quintana-Ortí, E.S., Peña, A.J.: DMRlib: Easy-coding and ef- ficient resource management for job malleability. IEEE Transactions on Computers 70, 1443–1457 (Sep 2020). https://doi.org/10.1109/TC.2020.3022933
-
[8]
Journal of Supercomputing76, 255–274 (Oct 2020)
Iserte, S., Rojek, K.: A study of the effect of process malleability in the energy effi- ciency on gpu-based clusters. Journal of Supercomputing76, 255–274 (Oct 2020). https://doi.org/10.1007/s11227-019-03034-x
-
[9]
Iserte, S.: High-throughput Computation through Efficient Re- source Management. Ph.D. Thesis, Universitat Jaume I (Nov 2018). https://doi.org/10.6035/14101.2018.176272
-
[10]
In: Euro-par Workshops Proceedings
Iserte, S., Lopez, V., Garcia-Gasulla, M., Peña, A.J.: Parallel efficiency-aware stan- dard mpi-based malleability. In: Euro-par Workshops Proceedings. Madrid, Spain (Aug 2024)
2024
-
[11]
Iserte, S., Madon, M., Da Costa, G., Pierson, J.M., Peña, A.J.: MPI malleability validationunderreplayedreal-worldHPCconditions.FutureGenerationComputer Systems p. 108305 (Dec 2025). https://doi.org/10.1016/j.future.2025.108305
-
[12]
Future Generation Computer Systems p
Iserte, S., Martín-Álvarez, I., Rojek, K., Aliaga, J.I., Castillo, M., Folwarska, W., Peña,A.J.:ResourceoptimizationwithMPIprocessmalleabilityfordynamicwork- loads in HPC clusters. Future Generation Computer Systems p. 107949 (2025). https://doi.org/10.1016/j.future.2025.107949
-
[13]
Lopez, V., Ramirez Miranda, G., Garcia-Gasulla, M.: Talp: A lightweight tool to unveil parallel efficiency of large-scale executions. In: Proceedings of the 2021 on Performance EngineeRing, Modelling, Analysis, and VisualizatiOn STrategy. p. 3–10. PERMAVOST ’21 (2021). https://doi.org/10.1145/3452412.3462753 Malleable Molecular Dynamics Simulations with G...
-
[14]
In: Proceedings of the 19th International Conference on Parallel Pro- cessing
Martín, G., Marinescu, M.C., Singh, D.E., Carretero, J.: FLEX-MPI: an MPI ex- tension for supporting dynamic load balancing on heterogeneous non-dedicated systems. In: Proceedings of the 19th International Conference on Parallel Pro- cessing. p. 138–149. Euro-Par’13 (2013). https://doi.org/10.1007/978-3-642-40047- 6_16,https://doi.org/10.1007/978-3-642-40047-6_16
-
[15]
The International Journal of High Performance Computing Applications38(2), 69–93 (2024)
Martín-Álvarez, I., Aliaga, J.I., Castillo, M., Iserte, S., Mayo, R.: Dy- namic spawning of MPI processes applied to malleability. The International Journal of High Performance Computing Applications38(2), 69–93 (2024). https://doi.org/10.1177/10943420231176527
-
[16]
In: IEEE International Parallel and Distributed Processing Symposium
Prabhakaran, S., Neumann, M., Rinke, S., Wolf, F., Gupta, A., Kale, L.V.: A batch system with efficient adaptive scheduling for malleable and evolving applications. In: IEEE International Parallel and Distributed Processing Symposium. pp. 429– 438 (2015). https://doi.org/10.1109/IPDPS.2015.34
-
[17]
Bioinformatics29(7), 845–854 (02 2013)
Pronk, S., Páll, S., Schulz, R., Larsson, P., Bjelkmar, P., Apostolov, R., Shirts, M.R., Smith, J.C., Kasson, P.M., van der Spoel, D., Hess, B., Lindahl, E.: Gromacs 4.5: A high-throughput and highly parallel open source molecular simulation toolkit. Bioinformatics29(7), 845–854 (02 2013). https://doi.org/10.1093/bioinformatics/btt055
-
[18]
https://doi.org/10.5281/zenodo.3893789
Páll, S.: Supplementary information for heterogeneous parallelization and ac- celeration of molecular dynamics simulations in GROMACS (Jun 2020). https://doi.org/10.5281/zenodo.3893789
-
[19]
In: IEEE International Symposium on Parallel and Distributed Processing
Sudarsan, R., Ribbens, C.J.: Scheduling resizable parallel applications. In: IEEE International Symposium on Parallel and Distributed Processing. pp. 1–10 (2009). https://doi.org/10.1109/IPDPS.2009.5161077
-
[20]
In: Computational Science (ICCS)
Sudarsan, R., Ribbens, C.J., Farkas, D.: Dynamic resizing of parallel scientific simulations: A case study using LAMMPS. In: Computational Science (ICCS). pp. 175–184 (2009)
2009
-
[21]
IEEE Transactions on Parallel and Distributed Systems pp
Tarraf, A., Schreiber, M., Cascajo, A., Besnard, J.B., Vef, M.A., Huber, D., Happ, S., Brinkmann, A., Singh, D.E., Hoppe, H.C., Miranda, A., Peña, A.J., Machado, R., Gasulla, M.G., Schulz, M., Carpenter, P., Pickartz, S., Rotaru, T., Iserte, S., Lopez, V., Ejarque, J., Sirwani, H., Wolf, F.: Malleability in mod- ern HPC systems: Current experiences, chall...
-
[22]
Journal of Computational Chemistry 26(16), 1701–1718 (2005)
Van Der Spoel, D., Lindahl, E., Hess, B., Groenhof, G., Mark, A.E., Berendsen, H.J.C.: GROMACS: Fast, flexible, and free. Journal of Computational Chemistry 26(16), 1701–1718 (2005)
2005
-
[23]
In: Job Scheduling Strategies for Parallel Processing
Yoo,A.B.,Jette,M.A.,Grondona,M.:Slurm:Simplelinuxutilityforresourceman- agement. In: Job Scheduling Strategies for Parallel Processing. pp. 44–60 (2003). https://doi.org/10.1007/10968987_3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.