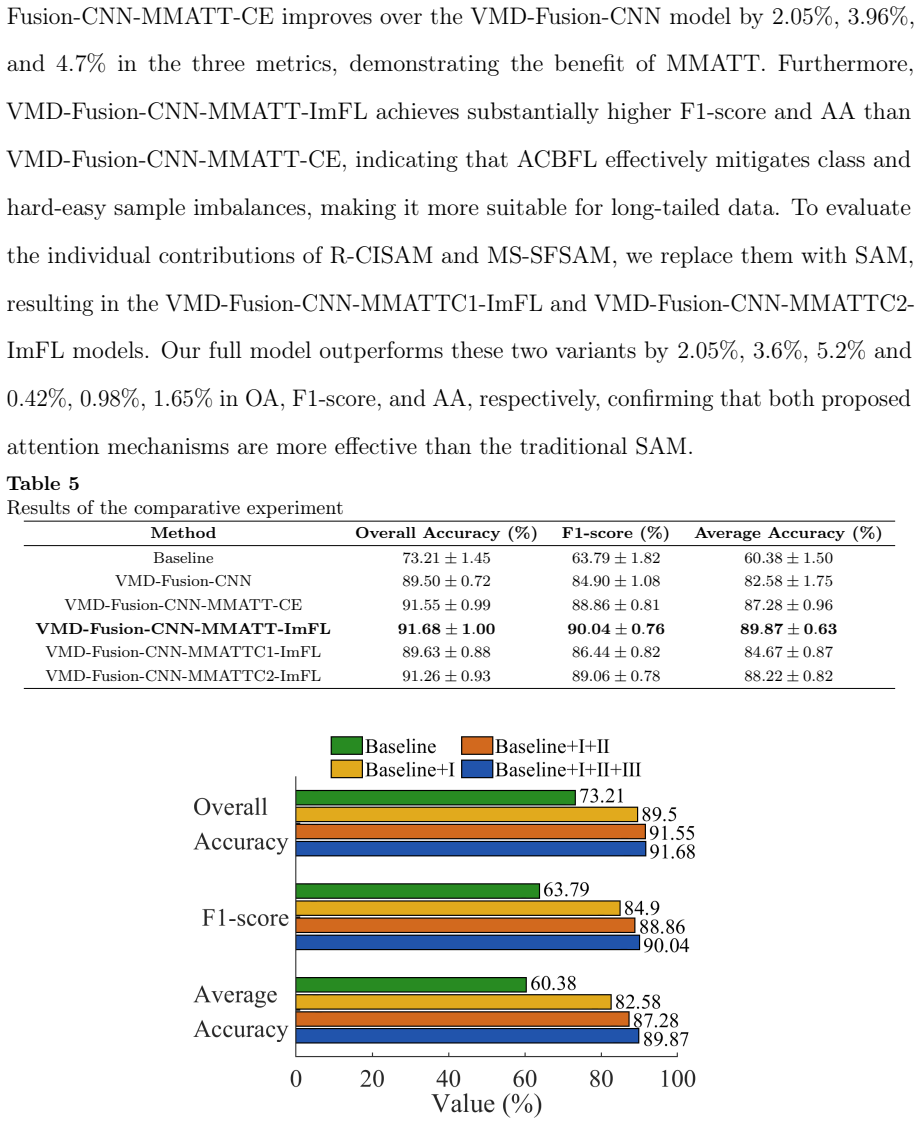
Modulation Feature Enhancement with a Multi-Stage Attention Network for Underwater Acoustic Target Recognition
Pith reviewed 2026-05-22 10:04 UTC · model grok-4.3
The pith
A CNN with multi-stage attention and adjusted focal loss improves recognition of ships from underwater noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that combining variational mode decomposition for high-fidelity 3/2-D DEMON spectral features, a 1-D CNN augmented by the Multi-Stage Multi-Type Attention Mechanism with Residual Channel-Independent Spectral Attention and Multi-Scale Separate-and-Fuse Spectral Attention, plus an Adjustable Class-Balanced Focal Loss produces measurably better classification of real ship-radiated acoustic signals despite class imbalance and ocean noise.
What carries the argument
The Multi-Stage Multi-Type Attention Mechanism (MMATT) that adaptively refines spectral features at multiple depths inside the 1-D CNN using residual channel-independent and multi-scale separate-and-fuse spectral attention blocks.
If this is right
- The extracted modulation features become more discriminative for ship classes under realistic noise.
- The network can maintain high performance even when training data has large differences in the number of examples per class.
- Feature refinement happens automatically at several stages rather than only at the input or output.
- Overall recognition rates rise on maritime surveillance tasks that rely on passive acoustic listening.
Where Pith is reading between the lines
- The same attention blocks could be dropped into other one-dimensional signal networks for tasks such as engine fault detection or speech enhancement.
- If the VMD-derived spectra prove stable across different ocean conditions, similar decomposition steps may simplify preprocessing pipelines for other noisy time-series problems.
- The adjustable loss parameter offers a practical knob that future work could tune automatically for new acoustic datasets.
Load-bearing premise
The 3/2-D spectrum produced by variational mode decomposition isolates modulation envelope information that reliably distinguishes ship classes while staying stable against real ocean noise variations.
What would settle it
A head-to-head test on the same real-world ship-radiated noise dataset in which the full proposed pipeline shows no statistically significant accuracy gain over a plain 1-D CNN trained with standard cross-entropy loss.
Figures











read the original abstract
Underwater acoustic target recognition is critical for maritime applications, yet it faces challenges arising from the complex and diverse nature of ship-radiated noise. To address these issues, we propose a robust deep learning-based framework. First, we introduce a feature extraction and fusion method based on variational mode decomposition (VMD) and the 3/2-D spectrum to generate high-fidelity 2-D DEMON spectral features, which effectively capture modulation envelope information. To further enhance feature representation, we design a one-dimensional convolutional neural network (1-D CNN) integrated with a novel Multi-Stage Multi-Type Attention Mechanism (MMATT) that adaptively refines features at different network depths. Within this mechanism, we propose a Residual Channel-Independent Spectral Attention Mechanism (R-CISAM) and a Multi-Scale Separate-and-Fuse Spectral Attention Mechanism (MS-SFSAM). Moreover, to mitigate performance degradation caused by severe class imbalance inherent in real-world ship-radiated noise data, we devise an Adjustable Class-Balanced Focal Loss (ACBFL), which provides flexibility across tasks with varying degrees of imbalance. Experimental results on a real-world ship-radiated noise dataset demonstrate that the proposed solutions effectively enhance underwater acoustic target recognition performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a deep learning framework for underwater acoustic target recognition from ship-radiated noise. It first extracts 2-D DEMON spectral features via variational mode decomposition (VMD) combined with a 3/2-D spectrum to capture modulation envelope information. These features are then processed by a 1-D CNN augmented with a Multi-Stage Multi-Type Attention Mechanism (MMATT) that incorporates Residual Channel-Independent Spectral Attention (R-CISAM) and Multi-Scale Separate-and-Fuse Spectral Attention (MS-SFSAM). To address class imbalance, the authors introduce an Adjustable Class-Balanced Focal Loss (ACBFL). Experiments on a real-world ship-radiated noise dataset are reported to demonstrate performance improvements.
Significance. If the central performance claims hold after addressing the experimental gaps, the work could advance practical underwater acoustic recognition by providing a pipeline that jointly improves modulation feature quality and handles severe class imbalance common in maritime datasets. The explicit design of MMATT components and the adjustable loss offer concrete, implementable ideas that could be tested in other noisy signal domains.
major comments (2)
- [Experimental results] Experimental results section: the reported accuracy gains on the real-world dataset are presented without quantitative baselines (e.g., standard DEMON + 1-D CNN), error bars, or ablation studies that isolate the contribution of the VMD + 3/2-D spectrum feature extractor while holding the MMATT 1-D CNN and ACBFL fixed. This omission makes it impossible to attribute the headline improvement to the proposed feature extraction step rather than to the attention modules or loss alone.
- [Feature extraction] Feature extraction section (abstract and §3): the claim that the VMD-derived 3/2-D spectrum 'effectively capture[s] modulation envelope information' that is both class-discriminative and robust to ocean noise is asserted but not tested via a controlled swap against a conventional Hilbert-envelope DEMON spectrum or EMD baseline. Without this isolation, the weakest assumption identified in the reader's report remains unaddressed and load-bearing for the central claim.
minor comments (1)
- [§3] The notation for the 3/2-D spectrum and the precise definition of the adjustable balancing factor in ACBFL should be given explicitly with equations rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental validation that will improve the clarity and rigor of our claims. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: the reported accuracy gains on the real-world dataset are presented without quantitative baselines (e.g., standard DEMON + 1-D CNN), error bars, or ablation studies that isolate the contribution of the VMD + 3/2-D spectrum feature extractor while holding the MMATT 1-D CNN and ACBFL fixed. This omission makes it impossible to attribute the headline improvement to the proposed feature extraction step rather than to the attention modules or loss alone.
Authors: We agree that the current presentation of results does not sufficiently isolate the contribution of the proposed VMD + 3/2-D spectrum feature extractor. In the revised manuscript we will add quantitative comparisons against a standard DEMON + 1-D CNN baseline, report mean accuracy with standard deviations across multiple random seeds to provide error bars, and include ablation studies that hold the MMATT 1-D CNN and ACBFL fixed while varying only the feature extraction pipeline. These additions will enable clearer attribution of performance gains. revision: yes
-
Referee: [Feature extraction] Feature extraction section (abstract and §3): the claim that the VMD-derived 3/2-D spectrum 'effectively capture[s] modulation envelope information' that is both class-discriminative and robust to ocean noise is asserted but not tested via a controlled swap against a conventional Hilbert-envelope DEMON spectrum or EMD baseline. Without this isolation, the weakest assumption identified in the reader's report remains unaddressed and load-bearing for the central claim.
Authors: The design of the VMD + 3/2-D spectrum is motivated by VMD's superior handling of non-stationary signals compared with EMD. We acknowledge, however, that the manuscript does not contain a direct head-to-head comparison against a conventional Hilbert-envelope DEMON spectrum or an EMD-based baseline while keeping the downstream MMATT network and ACBFL fixed. We will perform and report these controlled experiments in the revision to empirically support the claim that the proposed feature extractor yields more class-discriminative and noise-robust modulation information. revision: yes
Circularity Check
No significant circularity; empirical ML proposal with independent components
full rationale
The paper introduces VMD-based 3/2-D spectrum feature extraction, MMATT attention blocks (R-CISAM and MS-SFSAM), and ACBFL loss as externally motivated engineering choices for underwater acoustic data. Performance claims rest on end-to-end experiments on a real-world ship-radiated noise dataset rather than any derivation that reduces accuracy or feature discriminability to a fitted parameter or self-citation by construction. No equations equate outputs to inputs, and cited techniques (VMD, focal loss variants) are standard and independent of the target result.
Axiom & Free-Parameter Ledger
free parameters (1)
- Adjustable balancing factor in ACBFL
axioms (1)
- domain assumption VMD decomposition plus 3/2-D spectrum produces high-fidelity modulation features
Reference graph
Works this paper leans on
-
[1]
W. Wang, S. Yan, L. Mao, Z. Sui, J. Yang, Robust direct position determination for chirp signal-based underwater acoustic sensor networks, Signal Processing 230 (2025) 109841. doi:https://doi.org/10.1016/j.sigpro.2024.109841. 27
-
[2]
J. Yang, S. Yan, L. Mao, Z. Sui, W. Wang, D. Zeng, Underwater acoustic signal denoising based on sparse TQWT and wavelet thresholding, Digital Signal Processing 153 (2024) 104601. doi:https://doi.org/10.1016/j.dsp.2024.104601
-
[3]
Z. Sui, S. Yan, Frequency Channel Equalization Based on Variable Step-Size LMS Al- gorithm for OFDM Underwater Communications, in: 2019 IEEE International Confer- ence on Signal Processing, Communications and Computing (ICSPCC), 2019, pp. 1–5. doi:10.1109/ICSPCC46631.2019.8960813
-
[4]
Gradient-based learning applied to document recognition,
Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE 86 (11) (1998) 2278–2324. doi:10.1109/5.726791
-
[5]
P. Zhu, Y. Zhang, Y. Huang, C. Zhao, K. Zhao, F. Zhou, Underwater acoustic target recognition based on spectrum component analysis of ship radiated noise, Applied Acoustics 211 (2023) 109552. doi:https://doi.org/10.1016/j.apacoust.2023.109552
-
[6]
F. Liu, T. Shen, Z. Luo, D. Zhao, S. Guo, Underwater target recognition using convolutional recurrent neural networks with 3-D Mel-spectrogram and data augmentation, Applied Acoustics 178 (2021) 107989. doi:https://doi.org/10.1016/j.apacoust.2021.107989
-
[7]
A. Pollara, A. Sutin, H. Salloum, Improvement of the Detection of Envelope Modulation on Noise (DEMON) and its application to small boats, in: OCEANS 2016 MTS/IEEE Monterey, 2016, pp. 1–10. doi:10.1109/OCEANS.2016.7761197
-
[8]
P. Clark, I. Kirsteins, L. Atlas, Multiband analysis for colored amplitude-modulated ship noise, in: 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, 2010, pp. 3970–3973. doi:10.1109/ICASSP.2010.5495776
-
[9]
Z. Chen, Q. Liu, Y. Wang, SNR-based weighted fusion algorithm of multiple sub-band DEMON spectrum, in: 2017 IEEE 2nd Advanced Information Technol- ogy, Electronic and Automation Control Conference (IAEAC), 2017, pp. 2305–2308. doi:10.1109/IAEAC.2017.8054432. 28
-
[10]
K. Dragomiretskiy, D. Zosso, Variational Mode Decomposition, IEEE Transactions on Signal Processing 62 (3) (2014) 531–544. doi:10.1109/TSP.2013.2288675
-
[11]
C. Zhu, T. Cao, L. Chen, X. Dai, Q. Ge, X. Zhao, High-Order Domain Feature Extraction Technology for Ocean Acoustic Observation Signals: A Review, IEEE Access 11 (2023) 17665–17683. doi:10.1109/ACCESS.2023.3244782
-
[12]
Q. Zhang, L. Da, Y. Zhang, Y. Hu, Integrated neural networks based on fea- ture fusion for underwater target recognition, Applied Acoustics 182 (2021) 108261. doi:https://doi.org/10.1016/j.apacoust.2021.108261
-
[13]
L. Sichun, Y. Desen, DEMON Feature Extraction of Acoustic Vector Signal based on 3/2-D spectrum, in: 2007 2nd IEEE Conference on Industrial Electronics and Applications, 2007, pp. 2239–2243. doi:10.1109/ICIEA.2007.4318809
-
[14]
D. Xu, H. Zheng, Q. Hu, A Novel Feature Extraction Method for Underwater Acoustic Target Based on Parameter Optimized VMD and 1(1/2)-D Spectrum, in: Proceedings of the 2020 4th International Conference on Digital Signal Processing, ICDSP ’20, Association for Computing Machinery, New York, NY, USA, 2020, p. 86–91. doi:10.1145/3408127.3408149
-
[15]
Z. Niu, G. Zhong, H. Yu, A review on the attention mechanism of deep learning, Neurocom- puting 452 (2021) 48–62. doi:https://doi.org/10.1016/j.neucom.2021.03.091
-
[16]
L. Zhao, Y. Song, J. Xiong, J. Xu, D. Li, F. Liu, T. Shen, A time-delay neural network for ship-radiated noise recognition based on residual block and attention mechanism, Digital Signal Processing 149 (2024) 104504. doi:https://doi.org/10.1016/j.dsp.2024.104504
-
[17]
B. Wang, W. Zhang, Y. Zhu, C. Wu, S. Zhang, An Underwater Acoustic Target Recognition Method Based on AMNet, IEEE Geoscience and Remote Sensing Letters 20 (2023) 1–5. doi:10.1109/LGRS.2023.3235659
-
[18]
S. Yang, A. Jin, X. Zeng, H. Wang, X. Hong, M. Lei, Underwater acoustic target recognition based on sub-band concatenated Mel spectrogram and multidomain atten- 29 tion mechanism, Engineering Applications of Artificial Intelligence 133 (2024) 107983. doi:https://doi.org/10.1016/j.engappai.2024.107983
-
[19]
S. Woo, J. Park, J.-Y. Lee, I. S. Kweon, CBAM: Convolutional Block Attention Module, in: Computer Vision – ECCV 2018, Springer-Verlag, Berlin, Heidelberg, 2018, p. 3–19. doi:10.1007/978-3-030-01234-2_1
-
[20]
B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, Y. Kalantidis, Decoupling representation and classifier for long-tailed recognition, in: Eighth International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[21]
J. Wang, W. Zhang, Y. Zang, Y. Cao, J. Pang, T. Gong, K. Chen, Z. Liu, C. C. Loy, D. Lin, Seesaw Loss for Long-Tailed Instance Segmentation, in: 2021 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 9690–9699. doi:10.1109/CVPR46437.2021.00957
-
[22]
Z. Wang, G. Cao, X. Xi, J. Wang, OpenNet: Incremental Learning for Autonomous Driving Object Detection with Balanced Loss, in: 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2023, pp. 2675–2682. doi:10.1109/SMC53992.2023.10394429
-
[23]
C. Huang, Y. Li, C. C. Loy, X. Tang, Learning Deep Representation for Imbalanced Classification, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5375–5384. doi:10.1109/CVPR.2016.580
-
[24]
T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, Distributed representations of words and phrases and their compositionality, in: Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, NIPS’13, Curran Associates Inc., Red Hook, NY, USA, 2013, p. 3111–3119
work page 2013
-
[25]
D. Mahajan, R. Girshick, V. Ramanathan, K. He, M. Paluri, Y. Li, A. Bharambe, L. van der Maaten, Exploring the Limits of Weakly Supervised Pretraining, in: V. Ferrari, M. Hebert, C. Sminchisescu, Y. Weiss (Eds.), Computer Vision – ECCV 2018, Springer International Publishing, Cham, 2018, pp. 185–201. 30
work page 2018
-
[26]
T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal Loss for Dense Object Detection, in: 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2999–3007. doi:10.1109/ICCV.2017.324
-
[27]
Y. Dong, X. Shen, Z. Jiang, H. Wang, Recognition of imbalanced underwater acoustic datasets with exponentially weighted cross-entropy loss, Applied Acoustics 174 (2021) 107740. doi:https://doi.org/10.1016/j.apacoust.2020.107740
-
[28]
Y. Ma, M. Liu, Y. Zhang, B. Zhang, K. Xu, B. Zou, Z. Huang, Imbalanced Underwater Acous- tic Target Recognition with Trigonometric Loss and Attention Mechanism Convolutional Network, Remote Sensing 14 (16) (2022). doi:10.3390/rs14164103
-
[29]
D. Santos-Domínguez, S. Torres-Guijarro, A. Cardenal-López, A. Pena-Gimenez, ShipsEar: An underwater vessel noise database, Applied Acoustics 113 (2016) 64–69. doi:https://doi.org/10.1016/j.apacoust.2016.06.008
-
[30]
H. I. Hummel, R. van der Mei, S. Bhulai, A survey on machine learning in ship radiated noise, Ocean Engineering 298 (2024) 117252. doi:https://doi.org/10.1016/j.oceaneng.2024.117252
-
[31]
J. Hu, L. Shen, G. Sun, Squeeze-and-Excitation Networks, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132–7141. doi:10.1109/CVPR.2018.00745
-
[32]
L. van der Maaten, G. Hinton, Visualizing Data using t-SNE, Journal of Machine Learning Research 9 (86) (2008) 2579–2605. 31
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.