Open-Weight LLMs Are Often Competitive with Commercial APIs for Political Science Text Classification
Pith reviewed 2026-05-20 02:52 UTC · model grok-4.3
The pith
Local open-weight models often match commercial API performance on political science text classification tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
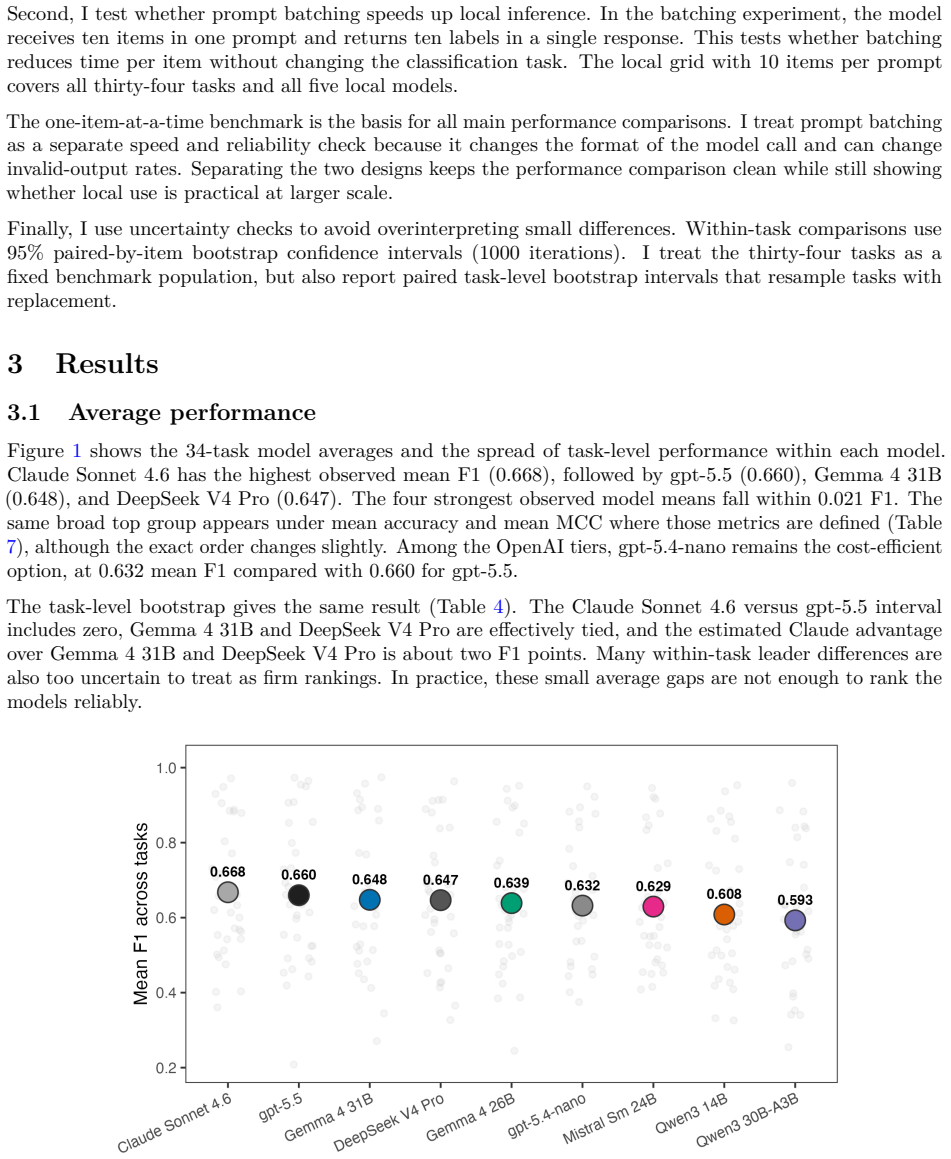
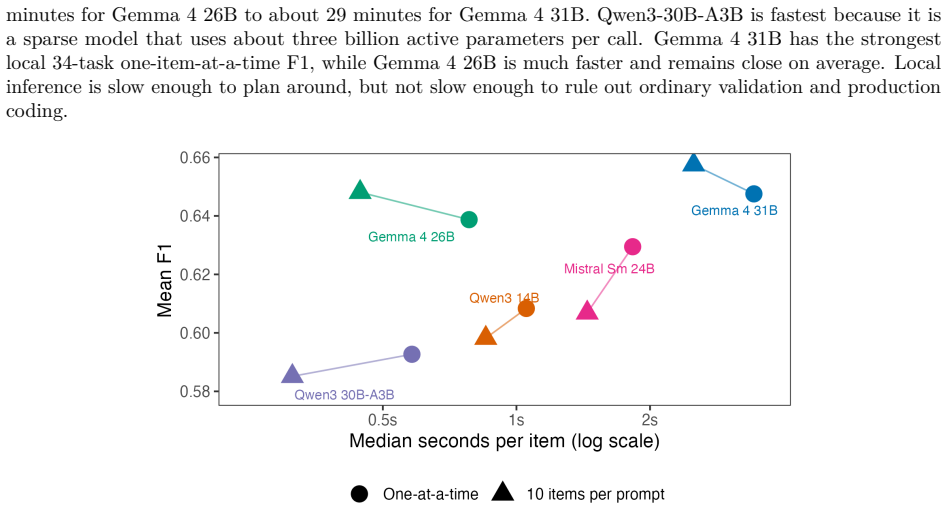
Local open-weight models match or exceed API performance on 9 tasks. On average the best API model exceeds the best local model by 0.015 F1, and the four strongest observed model means fall within 0.021 F1. Local models perform especially well on simpler tasks, while API models hold a clearer edge on complex tasks with many labels or multiple outputs per item.
What carries the argument
The task-specific oracle comparison that selects the best model per task and measures performance by F1 score across the 34 political science tasks.
If this is right
- Local models become practical candidates for many political science classification tasks.
- Researchers must validate candidate models on task-specific labels before scaling up.
- Batching several items in one prompt usually lowers local runtime per item but can produce invalid response formats or labels.
- API models retain advantages on complex tasks with many labels or multiple outputs per item.
Where Pith is reading between the lines
- Researchers gain data privacy and exact reproducibility by shifting to local models when performance is close.
- Task complexity rather than model access method appears to drive most of the observed performance differences.
- Testing the same comparison on classification tasks from other social science fields could check whether the competitiveness pattern holds more broadly.
Load-bearing premise
The 34 selected political science tasks and the nine tested models are representative enough to generalize that local open-weight models form a practical alternative for many classification tasks in the field.
What would settle it
A replication on a new collection of 50 political science tasks that finds local models underperform APIs by more than 0.05 F1 on average would undermine the claim of broad competitiveness.
Figures





read the original abstract
Can researchers use local open-weight models instead of commercial APIs for LLM text classification? Local models avoid marginal API charges, keep data on the researcher's machine, and make exact model versions easier to preserve. I benchmark five local models against four commercial API models on 34 political science classification tasks. Local models are often competitive, especially on simpler tasks. In a task-specific oracle comparison, local models match or exceed API performance on 9 tasks; on average, the best API model exceeds the best local model by 0.015 F1. The four strongest observed model means fall within 0.021 F1. API models have their clearest edge on complex tasks with many labels or multiple outputs per item. Batching several items in one prompt usually reduces local runtime per item, but specific model-task pairs can return invalid response formats or labels. Taken together, the results make local open-weight models a practical candidate alternative for many political science classification tasks, provided researchers validate candidate models on task-specific labels and check batching reliability before scaling up.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically compares five open-weight local LLMs against four commercial API models across 34 political science text classification tasks. It reports that local models are often competitive, matching or exceeding the best API performance on 9 tasks in an oracle comparison; the best API exceeds the best local model by 0.015 F1 on average, and the four strongest model means lie within 0.021 F1. Local models perform especially well on simpler tasks, while API models show clearer advantages on complex tasks with many labels or multiple outputs per item. The work concludes that local models are a practical alternative for many such tasks, provided task-specific validation.
Significance. If the central empirical comparison holds, the concrete F1 gaps and task counts provide a useful reference for political science researchers seeking cost, privacy, and reproducibility benefits from local models. The identification of task-complexity moderators (label count, output arity) adds practical guidance. The small observed differences suggest model choice is often not decisive, but only if the 34 tasks adequately sample the space of problems in the field.
major comments (2)
- [Methods / Task selection] The manuscript provides no description of how the 34 tasks were sampled or selected, nor any summary of their characteristics such as label cardinality or output arity (single vs. multiple per item). This is load-bearing for the abstract's generalization that local models are a practical alternative for 'many political science classification tasks,' especially since the abstract itself notes API advantages on complex tasks; without this information the observed 0.015 F1 gap and 9/34 wins cannot be extrapolated.
- [Results] No statistical significance tests, standard errors, or confidence intervals are reported for the F1 differences (including the 0.015 average gap and the within-0.021 range for top models). This weakens assessment of whether the small gaps are distinguishable from task- or prompt-sampling variability.
minor comments (1)
- [Abstract / Methods] Prompt templates, exact model versions, and batch sizes are not detailed in the abstract or methods; adding these (or a reproducibility appendix) would improve clarity without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed report. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods / Task selection] The manuscript provides no description of how the 34 tasks were sampled or selected, nor any summary of their characteristics such as label cardinality or output arity (single vs. multiple per item). This is load-bearing for the abstract's generalization that local models are a practical alternative for 'many political science classification tasks,' especially since the abstract itself notes API advantages on complex tasks; without this information the observed 0.015 F1 gap and 9/34 wins cannot be extrapolated.
Authors: We agree that explicit details on task selection and characteristics are needed to support the scope of our claims. The 34 tasks were assembled to span a range of political science applications (e.g., sentiment, stance, topic, and policy classification) drawn from publicly available datasets and prior studies. To address the concern, we will insert a new subsection in the Methods section that describes the selection criteria and adds a summary table reporting label cardinality, output arity (single- vs. multi-label), and indicators of task complexity for each task. This addition will allow readers to evaluate how well the observed patterns generalize and will qualify the abstract's statement accordingly. revision: yes
-
Referee: [Results] No statistical significance tests, standard errors, or confidence intervals are reported for the F1 differences (including the 0.015 average gap and the within-0.021 range for top models). This weakens assessment of whether the small gaps are distinguishable from task- or prompt-sampling variability.
Authors: We concur that measures of uncertainty would improve interpretation of the small observed differences. We will add bootstrap confidence intervals (resampling across the 34 tasks) for the average F1 gap between best API and best local model, as well as for the range spanned by the top four model means. Standard errors will also be reported for the key comparisons. These additions will help readers assess whether the gaps are distinguishable from task-level variability while preserving the descriptive nature of the main results. revision: yes
Circularity Check
No circularity: pure empirical benchmarking with no derivations or self-referential reductions
full rationale
This is an empirical benchmarking study that directly measures F1 performance of five local models against four API models across 34 fixed political science classification tasks. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The reported results (e.g., 9 tasks where local models match or exceed APIs, average 0.015 F1 gap) are computed outputs from running the models on the chosen tasks rather than quantities defined in terms of themselves or reduced via self-citation. The representativeness of the 34 tasks is a question of external validity and sampling, not a circularity in any derivation chain. The paper is self-contained against its own experimental benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption F1 score is an appropriate single-number summary for comparing classification performance across heterogeneous tasks
Reference graph
Works this paper leans on
-
[1]
Incivility in Congressional Tweets
“Incivility in Congressional Tweets.”American Politics Research50 (6): 769–80. https://doi.org/10.1177/1532673X 221109516. Bestvater, Samuel E., and Burt L. Monroe
-
[2]
Sentiment Is Not Stance: Target-Aware Opinion Classification for Political Text Analysis
“Sentiment Is Not Stance: Target-Aware Opinion Classification for Political Text Analysis.”Political Analysis31 (2): 235–56. https://doi.org/10.1017/pan. 2022.10. Brandt, Patrick T., Sultan Alsarra, Vito D’Orazio, et al
work page doi:10.1017/pan 2022
-
[4]
Stance Detection: A Practical Guide to Classifying Political Beliefs in Text
“Stance Detection: A Practical Guide to Classifying Political Beliefs in Text.” Political Science Research and Methods13 (3): 611–28. https://doi.org/10.1017/psrm.2024.35. Burnham, Michael, Kayla Kahn, Ryan Yang Wang, and Rachel X. Peng
-
[5]
Political DEBATE: Efficient Zero-Shot and Few-Shot Classifiers for Political Text
“Political DEBATE: Efficient Zero-Shot and Few-Shot Classifiers for Political Text.”Political Analysis, 1–15. https://doi.org/10.1017/ pan.2025.10028. Chae, Youngjin, and Thomas Davidson
-
[6]
Large Language Models for Text Classification: From Zero-Shot Learning to Instruction-Tuning
“Large Language Models for Text Classification: From Zero-Shot Learning to Instruction-Tuning.”Sociological Methods & Research55 (2): 501–67. https: //doi.org/10.1177/00491241251325243. Congressional Research Service. n.d.Congressional Research Service (CRS) Products. Congress.gov, Library of Congress. https://www.congress.gov/crs-products. Di Cocco, Jess...
-
[7]
“How Populist Are Parties? Measuring Degrees of Populism in Party Manifestos Using Supervised Machine Learning.”Political Analysis30 (3): 311–27. https://doi.org/10.1017/pan.2021.29. Douglass, Rex W., Thomas Leo Scherer, J. Andrés Gannon, et al
-
[8]
Introducing ICBe: An Event Extraction Dataset from Narratives about International Crises
“Introducing ICBe: An Event Extraction Dataset from Narratives about International Crises.”Political Science Research and Methods 12 (4): 729–49. https://doi.org/10.1017/psrm.2024.17. Erlich, Aaron, Stefano G. Dantas, Benjamin E. Bagozzi, Daniel Berliner, and Brian Palmer-Rubin
-
[9]
Multi-Label Prediction for Political Text-as-Data
“Multi-Label Prediction for Political Text-as-Data.”Political Analysis30 (4): 463–80. https://doi.org/10.1 017/pan.2021.15. Garcia Corral, Paulina, Hanna Bechara, Ran Zhang, and Slava Jankin
work page 2021
-
[10]
PolitiCause: An Annotation Scheme and Corpus for Causality in Political Texts
“PolitiCause: An Annotation Scheme and Corpus for Causality in Political Texts.”Proceedings of the 2024 Joint International Conference 9 on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)(Torino, Italia), 12836–45. https://aclanthology.org/2024.lrec-main.1124/. Gilardi, Fabrizio, Meysam Alizadeh, and Maël Kubli
work page 2024
-
[11]
Proceedings of the National Academy of Sciences 120(30)
“ChatGPT Outperforms Crowd Workers for Text-Annotation Tasks.”Proceedings of the National Academy of Sciences120 (30): e2305016120. https://doi.org/10.1073/pnas.2305016120. González-Bustamante, Bastián. 2024.Benchmarking LLMs in Political Content Text-Annotation: Proof-of- Concept with Toxicity and Incivility Data. https://doi.org/10.48550/arXiv.2409.0974...
-
[12]
Codebook LLMs: Evaluating LLMs as Measurement Tools for Political Science Concepts
“Codebook LLMs: Evaluating LLMs as Measurement Tools for Political Science Concepts.”Political Analysis34 (2): 188–204. https://doi.org/10.1017/pan.20 25.10017. Haunss, Sebastian, Priska Daphi, Jan Matti Dollbaum, Lidiya Hristova, Pál Susánszky, and Elias Steinhilper
-
[13]
PAPEA: A Modular Pipeline for the Automation of Protest Event Analysis
“PAPEA: A Modular Pipeline for the Automation of Protest Event Analysis.”Political Science Research and Methods, 1–18. https://doi.org/10.1017/psrm.2025.10013. Jones, Bryan D., Frank R. Baumgartner, Sean M. Theriault, Derek A. Epp, Shruti Khandekar, and Daniel Little. 2025.Policy Agendas Project: Codebook. https://www.comparativeagendas.net/pages/master- ...
-
[14]
“Do AIs Know What the Most Important Issue Is? Using Language Models to Code Open-Text Social Survey Responses at Scale.”Research & Politics11 (1): 1–7. https://doi.org/10.1177/20531680241231468. Müller, Stefan, and Naofumi Fujimura
-
[15]
Campaign Communication and Legislative Leadership
“Campaign Communication and Legislative Leadership.” Political Science Research and Methods13 (3): 545–66. https://doi.org/10.1017/psrm.2024.11. Ornstein, Joseph T., Elise N. Blasingame, and Jake S. Truscott
-
[16]
How to Train Your Stochastic Parrot: Large Language Models for Political Texts
“How to Train Your Stochastic Parrot: Large Language Models for Political Texts.”Political Science Research and Methods13 (2): 264–81. https://doi.org/10.1017/psrm.2024.64. Osnabrügge, Moritz, Elliott Ash, and Massimo Morelli
-
[17]
Cross-Domain Topic Classification for Political Texts
“Cross-Domain Topic Classification for Political Texts.”Political Analysis31 (1): 59–80. https://doi.org/10.1017/pan.2021.37. Pendzel, Sagi, Nir Lotan, Alon Zoizner, and Einat Minkov. 2023.Detecting Multidimensional Political Incivility on Social Media. https://doi.org/10.48550/arXiv.2305.14964. Pipal, Christian, Eva-Maria Vogel, Morgan Wack, and Frank Es...
-
[18]
Politicians in the Line of Fire: Incivility and the Treatment of Women on Social Media
“Politicians in the Line of Fire: Incivility and the Treatment of Women on Social Media.”Research & Politics6 (1): 1–7. https://doi.org/10.1177/ 2053168018816228. 10 Sermpezis, Pavlos, Stelios Karamanidis, Eva Paraschou, et al. 2024.AgoraSpeech: A Multi-Annotated Comprehensive Dataset of Political Discourse Through the Lens of Humans and AI. Dataset. Zeno...
-
[19]
Theocharis, Yannis, Pablo Barberá, Zoltán Fazekas, and Sebastian Adrian Popa
https://doi.org/10.1007/s42001-026-00469-0. Theocharis, Yannis, Pablo Barberá, Zoltán Fazekas, and Sebastian Adrian Popa
-
[20]
The Dynamics of Political Incivility on Twitter
“The Dynamics of Political Incivility on Twitter.”SAGE Open10 (2): 2158244020919447. https://doi.org/10.1177/21582440 20919447. Zhang, Meiqing, Furkan Cakmak, Markus Neumann, et al
-
[21]
Comparable 2022 General Election Advertising Datasets from Meta and Google
“Comparable 2022 General Election Advertising Datasets from Meta and Google.”Scientific Data12:
work page 2022
-
[22]
https://doi.org/10.1038/s41597- 025-05228-w. Companion materials Prompt sources, batching details, summary CSVs, and reproduction instructions are on the GitHub repository at https://github.com/hhilbig/polsci-open-bench. 11 Tasks Table 2: Thirty-four tasks in the benchmark. ’Type’ is the report grouping used in Figure 3; it is a broad annotation type rath...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.