GeoDiff-SAR II: 3D-Driven Foundation Diffusion Models for SAR Generation via Decoupled Control
Pith reviewed 2026-05-21 01:45 UTC · model grok-4.3
The pith
A 3D-guided framework decouples geometry from scattering to generate controllable SAR images across large azimuth gaps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By deriving a Geometric-Electromagnetic Conditioning Map from real sparse-azimuth SAR images during training and from 3D CAD models during inference, the framework converts imaging parameters into text conditions while injecting the map through ControlNet for spatial guidance, thereby unifying geometric-electromagnetic control and parameter-aware generation in one diffusion process that generalizes stably across large viewpoint gaps.
What carries the argument
The Geometric-Electromagnetic Conditioning Map (GECM), a structured intermediate representation that encodes the target pose map and dominant scattering centers to separate macroscopic geometry from microscopic scattering responses.
If this is right
- Users can specify any combination of azimuth, depression angle, and polarization and obtain a corresponding SAR image without retraining.
- The model maintains usable output quality even when large contiguous azimuth sectors are missing from the training data.
- Generated images improve fidelity and physical consistency metrics relative to earlier intensity-only conditioning approaches.
- Downstream Automatic Target Recognition classifiers trained on the synthetic outputs achieve higher accuracy on real test imagery.
Where Pith is reading between the lines
- The same decoupling idea could be tested on other sensor modalities where 3D models exist, such as LiDAR or infrared.
- If the GECM proves sufficient, future work might reduce reliance on full 3D CAD models by learning the map directly from sparse real data.
- The approach opens the possibility of on-demand SAR simulation for operational planning where flight collection is impractical.
Load-bearing premise
That a map rendered from a 3D CAD model under chosen azimuth, depression angle, and polarization conditions accurately captures the dominant scattering centers and overall shape present in real SAR returns of the same target.
What would settle it
A direct comparison showing that images generated for a specific set of imaging parameters produce lower physical-consistency scores or lower Automatic Target Recognition accuracy than real SAR measurements of the identical target taken under those exact parameters.
Figures







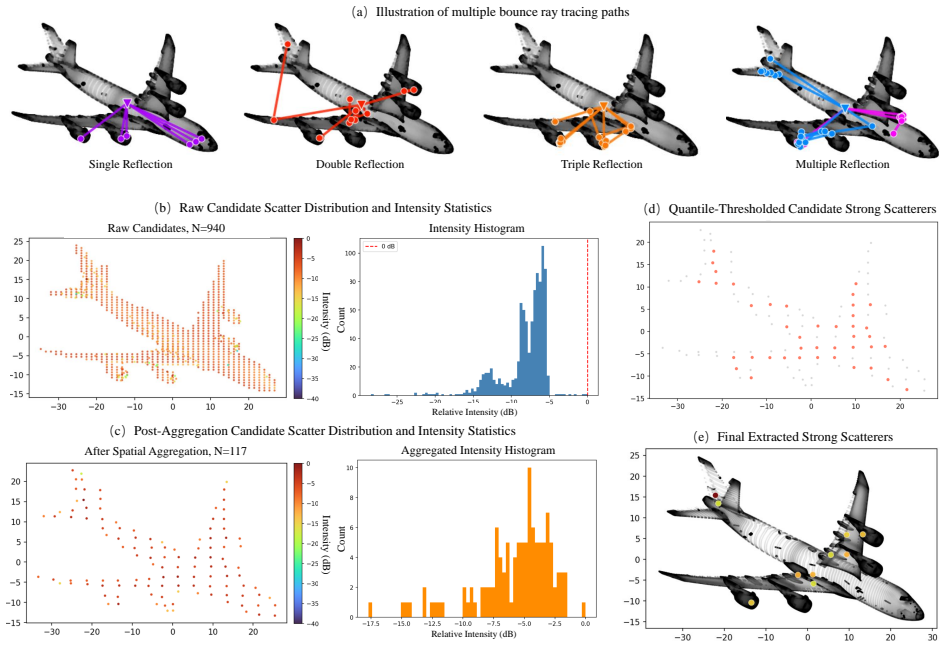






read the original abstract
Existing Synthetic Aperture Radar (SAR) image generation methods still lack reliable controllability over key imaging parameters, particularly azimuth angle, depression angle, and polarization mode. Our preliminary GeoDiff-SAR supported limited azimuth completion, but remained ineffective for large missing azimuth sectors and did not provide unified control over multiple imaging conditions. To address this problem, we propose GeoDiff-SAR II, a 3D model-guided decoupled framework for controllable SAR image generation. The proposed framework imposes controllability through physically grounded geometric-electromagnetic cues rather than image intensity alone. We introduce a Geometric-Electromagnetic Conditioning Map (GECM), a structured intermediate representation that encodes the target pose map and dominant scattering centers, thereby decoupling macroscopic geometry from microscopic scattering responses. During training, GECMs are derived from real sparse-azimuth SAR images. During inference, the same representation is rendered directly from a 3D CAD model under specified azimuth, depression angle, and polarization conditions, enabling physically consistent control across large viewpoint gaps. The imaging parameters are further converted into text conditions, while the GECM is injected through ControlNet to provide explicit spatial guidance. Combined with Low-Rank Adaptation (LoRA) on a FLUX backbone, the proposed framework unifies geometric-electromagnetic conditioning and parameter-aware generation within a single process. Experiments on simulated and real datasets demonstrate controllable generation over key SAR imaging parameters, stable generalization across large azimuth gaps, and consistent improvements in image fidelity, physical consistency, and downstream Automatic Target Recognition (ATR) performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GeoDiff-SAR II, a 3D-driven diffusion framework for controllable SAR image generation. It defines a Geometric-Electromagnetic Conditioning Map (GECM) that encodes target pose and dominant scattering centers. During training GECMs are extracted from real sparse-azimuth SAR; at inference the same representation is rendered from 3D CAD models under user-specified azimuth, depression angle, and polarization. These maps are injected via ControlNet while imaging parameters are supplied as text prompts; the backbone is FLUX fine-tuned with LoRA. Experiments on simulated and real data are said to show controllable generation, stable performance across large azimuth gaps, and gains in fidelity, physical consistency, and downstream ATR accuracy.
Significance. If the GECM truly acts as a domain-invariant bridge between CAD-rendered and real-SAR-derived conditioning signals, the work would provide a practical route to parameter-controlled SAR synthesis that could reduce reliance on scarce real measurements for ATR training. The decoupled geometric-electromagnetic design and reuse of a foundation-model backbone with LoRA are technically attractive features.
major comments (2)
- [§3.2] §3.2 (GECM rendering and injection): The central claim of stable generalization across large azimuth gaps rests on the assumption that GECMs rendered from 3D CAD models lie within the distribution of GECMs extracted from real SAR at the same parameters. No quantitative comparison (e.g., Wasserstein distance on scattering-center locations/amplitudes or overlap statistics) is reported between the two sources of GECM; without this, the ControlNet may be queried outside its training support, directly undermining both controllability and ATR gains.
- [§4.3] §4.3 and Table 3 (ATR evaluation): The abstract asserts consistent improvements in downstream ATR performance, yet the manuscript provides neither the exact ATR metric values, the baseline methods, nor any ablation that isolates the contribution of the GECM versus text conditioning alone. This absence makes it impossible to verify whether the reported gains are load-bearing or merely incremental.
minor comments (2)
- [§3.1] The abstract states that GECMs are 'derived from real sparse-azimuth SAR images' but does not specify the extraction algorithm (e.g., peak detection thresholds or pose estimation method); this detail should be added to §3.1 for reproducibility.
- [Figure 4] Figure 4 caption refers to 'large azimuth gaps' without stating the exact angular ranges tested; explicit values would clarify the scope of the generalization claim.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each major comment in detail below and outline the revisions we plan to implement.
read point-by-point responses
-
Referee: [§3.2] §3.2 (GECM rendering and injection): The central claim of stable generalization across large azimuth gaps rests on the assumption that GECMs rendered from 3D CAD models lie within the distribution of GECMs extracted from real SAR at the same parameters. No quantitative comparison (e.g., Wasserstein distance on scattering-center locations/amplitudes or overlap statistics) is reported between the two sources of GECM; without this, the ControlNet may be queried outside its training support, directly undermining both controllability and ATR gains.
Authors: We acknowledge the validity of this observation. The manuscript currently does not include a quantitative comparison between GECMs from real SAR and CAD-rendered sources. To address this, we will add such an analysis in the revised manuscript, including metrics like Wasserstein distances on scattering center positions and amplitudes, as well as overlap statistics for matched imaging parameters. This will provide evidence that the rendered GECMs are within the training distribution. revision: yes
-
Referee: [§4.3] §4.3 and Table 3 (ATR evaluation): The abstract asserts consistent improvements in downstream ATR performance, yet the manuscript provides neither the exact ATR metric values, the baseline methods, nor any ablation that isolates the contribution of the GECM versus text conditioning alone. This absence makes it impossible to verify whether the reported gains are load-bearing or merely incremental.
Authors: We agree that more detailed reporting is necessary to substantiate the ATR improvements. In the revised version, we will provide the exact metric values (such as accuracy, precision, or other relevant measures), explicitly list the baseline methods compared against, and include an ablation study that isolates the impact of the GECM conditioning from the text prompts alone. This will clarify the contribution of each component. revision: yes
Circularity Check
No circularity: framework relies on external 3D CAD rendering and real SAR data without self-referential reductions
full rationale
The paper describes a decoupled diffusion framework where GECMs are extracted from real sparse-azimuth SAR images during training and rendered from independent 3D CAD models during inference, with text conditioning on imaging parameters and ControlNet injection. No equations, fitted parameters, or self-citations are shown that define a claimed prediction or performance gain in terms of the same quantities used for evaluation. The central claims of controllability and generalization rest on the external validity of the 3D-to-GECM rendering step rather than any internal loop or renaming of inputs as outputs. This is a standard methodological proposal whose correctness can be assessed against held-out real SAR measurements without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3D CAD models of targets accurately capture the dominant scattering centers and pose geometry relevant to real SAR imaging
invented entities (1)
-
Geometric-Electromagnetic Conditioning Map (GECM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a Geometric-Electromagnetic Conditioning Map (GECM), a structured intermediate representation that encodes the target pose map and dominant scattering centers... During inference, the same representation is rendered directly from a 3D CAD model under specified azimuth, depression angle, and polarization conditions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A tutorial on synthetic aperture radar,
A. Moreira, P. Prats-Iraola, M. Younis, G. Krieger, I. Hajnsek, and K. P. Papathanassiou, “A tutorial on synthetic aperture radar,”IEEE Geoscience and Remote Sensing Magazine, vol. 1, no. 1, pp. 6–43, 2013
work page 2013
-
[2]
Deep learning meets SAR: Concepts, models, pitfalls, and perspectives,
X. X. Zhu et al., “Deep learning meets SAR: Concepts, models, pitfalls, and perspectives,” IEEE Geoscience and Remote Sensing Magazine, vol. 9, no. 4, pp. 143–172, 2021
work page 2021
-
[3]
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,”Nature, vol. 521, no. 7553, pp. 436–444, 2015. 20
work page 2015
-
[4]
Target classification using the deep convolutional networks for SAR images,
S. Chen, H. Wang, F. Xu, and Y. Q. Jin, “Target classification using the deep convolutional networks for SAR images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 54, no. 8, pp. 4806–4817, 2016
work page 2016
-
[5]
Target recognition of SAR images via few-shot learning,
B. Ding, G. Wen, C. Ma, X. Yang, and C. Qiu, “Target recognition of SAR images via few-shot learning,”Remote Sensing, vol. 12, no. 1, p. 165, 2020
work page 2020
-
[6]
SAR target recognition using zero-shot learning,
F. Zhang, C. Hu, Q. Yin, W. He, C. Li, and N. M. Robertson, “SAR target recognition using zero-shot learning,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13, 2021
work page 2021
-
[7]
Sparse-azimuth SAR target recognition via feature de- coupling,
Y. Wang, C. Wang, and H. Zhang, “Sparse-azimuth SAR target recognition via feature de- coupling,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022
work page 2022
-
[8]
Few-shot sparse-azimuth SAR target recognition,
H. Liu, X. Zhang, and Y. Li, “Few-shot sparse-azimuth SAR target recognition,”IEEE Trans- actions on Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2023
work page 2023
-
[9]
I. Goodfellow et al., “Generative adversarial nets,” inAdvances in Neural Information Pro- cessing Systems, pp. 2672–2680, 2014
work page 2014
-
[10]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh et al., “Hierarchical text-conditional image generation with CLIP latents,” arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020
work page 2020
-
[12]
High-resolution image syn- thesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image syn- thesis with latent diffusion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 10684–10695
work page 2022
-
[13]
SAR image generation using generative adversarial networks: A comprehensive review,
J. Guo et al., “SAR image generation using generative adversarial networks: A comprehensive review,”IEEE Geoscience and Remote Sensing Magazine, vol. 9, no. 2, pp. 110–130, 2021
work page 2021
-
[14]
Diffusion models for SAR image generation: A promising paradigm,
Y. Ji, X. Sun, and M. Wang, “Diffusion models for SAR image generation: A promising paradigm,”IEEE Geoscience and Remote Sensing Letters, vol. 20, pp. 1–5, 2023
work page 2023
-
[15]
I. G. Cumming and J. R. Wong,Digital Processing of Synthetic Aperture Radar Data: Algo- rithms and Implementation. Norwood, MA, USA: Artech House, 2005
work page 2005
-
[16]
Physical-aware SAR image generation via geometric priors,
Z. Zhao, Q. Li, and J. Zhang, “Physical-aware SAR image generation via geometric priors,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 200, pp. 120–135, 2023
work page 2023
-
[17]
Mitigating hallucinations in SAR image generation under sparse observation,
M. Xia, Z. Chen, and L. Huang, “Mitigating hallucinations in SAR image generation under sparse observation,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024
work page 2024
-
[18]
Hallucination in conditional diffusion models,
L. Wang et al., “Hallucination in conditional diffusion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 1234–1243, 2023
work page 2023
-
[19]
GeoDiff-SAR: A geometric prior guided diffusion model for SAR image generation,
F. Zhang, X. Wu, F. Ma, Q. Yin, and Y. Hu, “GeoDiff-SAR: A geometric prior guided diffusion model for SAR image generation,”arXiv:2601.03499, 2026
-
[20]
J. Kim et al., “3D-aware image generation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 4567–4576, 2020. 21
work page 2020
-
[21]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pp. 3836–3847, 2023
work page 2023
- [22]
-
[23]
SAR raw signal simulation of complex scenes,
G. Franceschetti, M. Migliaccio, D. Riccio, and G. Schirinzi, “SAR raw signal simulation of complex scenes,”IEEE Transactions on Aerospace and Electronic Systems, vol. 39, no. 1, pp. 323–331, 2003
work page 2003
-
[24]
Ray tracing simulation techniques for understanding high- resolution SAR images,
S. Auer, S. Hinz, and R. Bamler, “Ray tracing simulation techniques for understanding high- resolution SAR images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 48, no. 3, pp. 1445–1456, 2009
work page 2009
-
[25]
Scattering center analysis of man-made targets,
E. Schreiber and I. J. Gupta, “Scattering center analysis of man-made targets,”IEEE Trans- actions on Antennas and Propagation, vol. 53, no. 1, pp. 178–184, 2005
work page 2005
-
[26]
Generative adversarial networks for SAR image realism,
B. Lewis et al., “Generative adversarial networks for SAR image realism,” inProc. SPIE, vol. 10987, 2019, Art. no. 109870V
work page 2019
-
[27]
Image-to-image translation with conditional adversarial networks,
P. Isola, J. Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 1125–1134
work page 2017
-
[28]
Unpaired image-to-image translation using cycle-consistent adversarial networks,
J. Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 2223–2232
work page 2017
-
[29]
M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein GAN,” inProc. Int. Conf. Mach. Learn. (ICML), 2017, pp. 214–223
work page 2017
-
[30]
Taming transformers for high-resolution image syn- thesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image syn- thesis,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 12873– 12883
work page 2021
-
[31]
Physics-informed machine learning,
G. E. Karniadakis et al., “Physics-informed machine learning,”Nature Reviews Physics, vol. 3, no. 6, pp. 422–440, 2021
work page 2021
-
[32]
Improving SAR automatic target recognition using simulated data,
D. Malmgren-Hansen, A. Kusk, J. Dall, et al., “Improving SAR automatic target recognition using simulated data,” inProc. IEEE Radar Conf., 2017, pp. 1150–1153
work page 2017
-
[33]
Scattering characteristics guided network for ISAR space target component segmentation,
F. Zhong, F. Gao, T. Liu, et al., “Scattering characteristics guided network for ISAR space target component segmentation,”IEEE Geoscience and Remote Sensing Letters, vol. 22, pp. 1–5, 2025
work page 2025
-
[34]
FiLM: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V. Dumoulin, and A. Courville, “FiLM: Visual reasoning with a general conditioning layer,” inProc. AAAI Conf. Artif. Intell., 2018
work page 2018
-
[35]
LoRA: Low-rank adaptation of large language models,
E. J. Hu et al., “LoRA: Low-rank adaptation of large language models,” inProc. Int. Conf. Learn. Representations (ICLR), 2022
work page 2022
-
[36]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 4199–4209. 22
work page 2023
-
[37]
VQGAN-CLIP: Open domain image generation and editing with natural language guidance
K. Crowson, S. Biderman, D. Hall, E. D. Tow, and C. Lawrence, “VQGAN-CLIP: Open domain image generation and editing with natural language guidance,”arXiv:2204.08583, 2022
-
[38]
DeepFloyd, “IF-I-XL-v1.0,” 2023. [Online]. Available:https://huggingface.co/DeepFloyd/ IF-I-XL-v1.0
work page 2023
-
[39]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
J. Chen et al., “PixArt-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis,”arXiv:2310.00426, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
D. Podell et al., “SDXL: Improving latent diffusion models for high-resolution image synthesis,” arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Stability AI, “Stable Diffusion 3.5 Medium,” 2024. [Online]. Available:https:// huggingface.co/stabilityai/stable-diffusion-3.5-medium. 23
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.