How does limma-trend work? An empirical partially Bayes perspective
Pith reviewed 2026-05-21 03:44 UTC · model grok-4.3
The pith
Limma-trend computes approximate partially Bayes p-values by conditioning on residual variances and unit summaries, and its nonparametric generalization controls FDR asymptotically even if the variance trend is misspecified.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
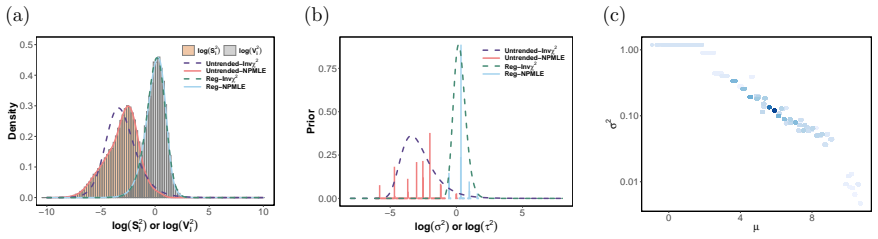
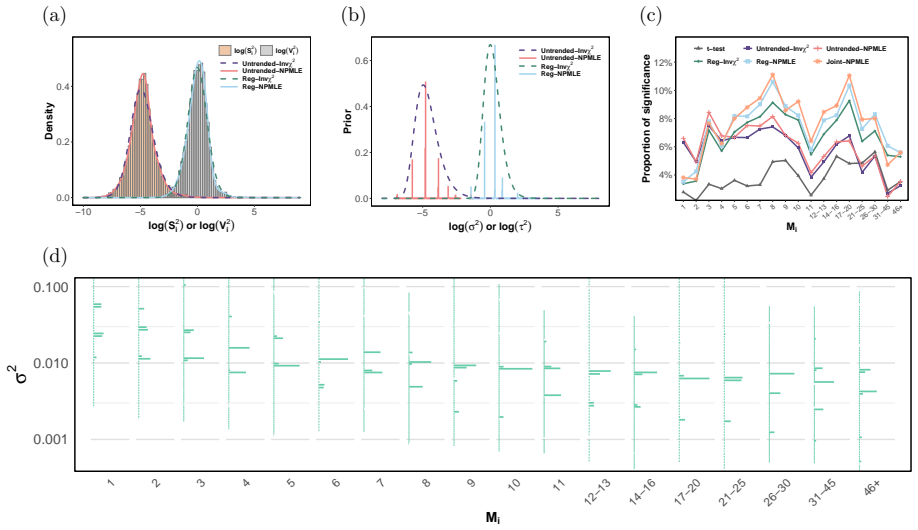
From an empirical partially Bayes perspective, limma-trend computes approximate partially Bayes p-values that condition on the residual sample variance and the unit-level summary. The same framework explains why MAnorm2 can sometimes fail to control FDR. A nonparametric generalization estimates the residual variance prior using nonparametric maximum likelihood and, under dense signals, asymptotically controls the FDR even when the trend is misspecified or inconsistently estimated. A second procedure learns the full shape of the conditional variance distribution directly from the data.
What carries the argument
Nonparametric maximum likelihood estimation of the residual variance prior, which replaces the parametric trend and enables FDR control without requiring correct trend specification under dense signals.
If this is right
- When signals are dense the nonparametric procedure controls FDR without needing an accurately specified or consistently estimated trend.
- The same perspective accounts for occasional FDR failures observed with MAnorm2 in ChIP-seq settings.
- The full nonparametric version allows the entire conditional variance distribution to vary with the unit-level summary rather than only its mean.
- Both procedures remain applicable to the same high-throughput regression settings as standard limma-trend.
Where Pith is reading between the lines
- Practitioners could default to the nonparametric version in exploratory analyses where the true variance trend is uncertain.
- The density requirement suggests checking empirical signal prevalence before relying on the asymptotic guarantee.
- Similar nonparametric prior estimation might be applied to other shrinkage problems in multiple testing beyond variance.
- The approach highlights a trade-off between parametric simplicity and robustness that could be quantified in finite-sample simulations.
Load-bearing premise
Signals must be sufficiently dense for the asymptotic FDR control to hold when the trend is misspecified.
What would settle it
A simulation with sparse signals in which the nonparametric procedure produces false discovery rates substantially above the nominal level while the parametric limma-trend does not, or a real-data analysis showing excess false positives under the new method.
Figures

read the original abstract
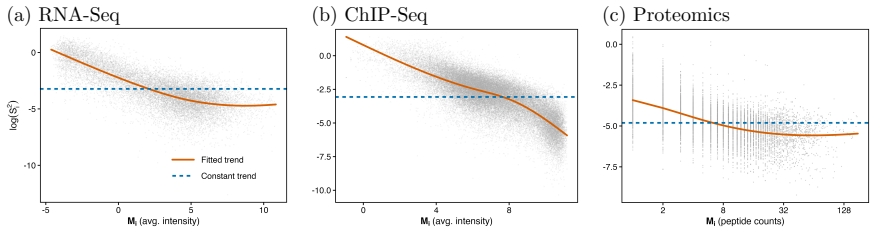
In high-throughput biology, it is common to fit thousands of linear regressions -- one per gene, protein, or other unit -- with very few samples per unit. Limma-trend, one of the most widely used methods in this setting, improves power by shrinking variance estimates parametrically toward a fitted curve (the trend) relating variance to a unit-level summary (e.g., average intensity, peptide count), before computing p-values and applying the Benjamini-Hochberg procedure to control the false discovery rate (FDR). We study limma-trend through the lens of empirical partially Bayes inference, a paradigm in which a prior is posited and estimated for the nuisance parameters while parameters of interest remain fixed. From this perspective, limma-trend computes approximate partially Bayes p-values that condition on the residual sample variance and the unit-level summary. The same framework explains why MAnorm2, a popular variant for ChIP-seq, can sometimes fail to control FDR. We then derive a nonparametric generalization of limma-trend that estimates the residual variance prior using nonparametric maximum likelihood. Under dense signals, this procedure asymptotically controls the FDR -- even when the trend is misspecified or inconsistently estimated. To allow the full shape of the conditional variance distribution to depend on the unit-level summary, we develop a second procedure that learns it directly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript interprets limma-trend through an empirical partially Bayes lens, showing that it produces approximate p-values by conditioning on the residual sample variance and a unit-level summary while shrinking variances toward a fitted trend curve. It derives a nonparametric generalization that estimates the residual-variance prior via nonparametric maximum likelihood and claims that, under dense signals, this procedure asymptotically controls the FDR even when the trend is misspecified or inconsistently estimated. A second procedure is introduced that allows the full conditional variance distribution to depend on the unit-level summary.
Significance. If the asymptotic FDR results are rigorously established, the work supplies a useful theoretical account of a widely deployed method and introduces a more flexible nonparametric alternative that remains valid under trend misspecification. Such guarantees would strengthen the methodological foundation for variance shrinkage in high-throughput multiple testing.
major comments (2)
- [Abstract and statement of the main theorem] Main theoretical result on asymptotic FDR control: the guarantee is stated to hold only 'under dense signals,' yet no explicit lower bound or rate on the non-null proportion π₁ (in terms of the number of tests p) is supplied. Without this, it is impossible to verify whether the NPMLE-based procedure continues to deliver valid p-values and FDR control in the sparse regimes (e.g., π₁ = o(1)) that are common in genomics, where signal-induced bias may prevent consistent estimation of the variance prior.
- [Section deriving the nonparametric limma-trend] Derivation of the nonparametric generalization: the claim that the procedure controls FDR even under inconsistent trend estimation relies on the dense-signal regime to separate the prior from the data; the manuscript should clarify whether the proof uses a uniform lower bound on π₁ that is independent of p or a weaker condition that still permits the result to hold when the trend is misspecified.
minor comments (2)
- [Introduction] The notation for the unit-level summary (e.g., average intensity) is introduced late; defining it explicitly in the introduction would improve readability.
- [Discussion] A brief comparison table of the parametric limma-trend, the nonparametric version, and MAnorm2 under the partially Bayes view would help readers see the distinctions at a glance.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments, which have helped us clarify the conditions underlying our asymptotic FDR results. We have revised the manuscript to explicitly state the lower bound on the non-null proportion used in the proofs and to add discussion of its implications for sparse regimes. Our responses to the major comments are given below.
read point-by-point responses
-
Referee: Main theoretical result on asymptotic FDR control: the guarantee is stated to hold only 'under dense signals,' yet no explicit lower bound or rate on the non-null proportion π₁ (in terms of the number of tests p) is supplied. Without this, it is impossible to verify whether the NPMLE-based procedure continues to deliver valid p-values and FDR control in the sparse regimes (e.g., π₁ = o(1)) that are common in genomics, where signal-induced bias may prevent consistent estimation of the variance prior.
Authors: We agree that an explicit condition on π₁ is necessary for rigor. Our proof of asymptotic FDR control for the NPMLE-based procedure assumes that the non-null proportion satisfies π₁ ≥ δ for some fixed δ > 0 independent of p. This dense-signal assumption ensures that the contribution of the non-null units does not vanish asymptotically, allowing the NPMLE to consistently recover the marginal distribution of the residual variances despite the presence of signals and even when the trend is misspecified. We do not claim validity in sparse regimes where π₁ → 0 (possibly at arbitrary rates), as signal-induced bias can then prevent consistent prior estimation. We have revised the abstract and the statement of the main theorem to include this explicit lower bound, and we have added a paragraph in the discussion section noting that the result does not extend to sparse settings without further assumptions. revision: yes
-
Referee: Derivation of the nonparametric generalization: the claim that the procedure controls FDR even under inconsistent trend estimation relies on the dense-signal regime to separate the prior from the data; the manuscript should clarify whether the proof uses a uniform lower bound on π₁ that is independent of p or a weaker condition that still permits the result to hold when the trend is misspecified.
Authors: The proof uses a uniform lower bound π₁ ≥ δ > 0 that is independent of p. This condition is what permits separation of the variance prior from the observed data even under trend misspecification or inconsistent trend estimation: because a positive fraction of units are non-null, the NPMLE can still identify the correct marginal distribution of the residual variances. We have revised the section deriving the nonparametric generalization to state this condition explicitly and to explain why the dense-signal regime is essential for the misspecification-robustness result. No weaker condition (such as π₁ → 0 at a slow rate) is used or claimed in the current proofs. revision: yes
Circularity Check
No circularity: asymptotic FDR result derived independently of fitted prior
full rationale
The paper frames limma-trend as approximate partially Bayes inference and derives a nonparametric generalization via nonparametric maximum likelihood estimation of the residual-variance prior. The central claim—an asymptotic FDR guarantee under dense signals that holds even under trend misspecification—is obtained through theoretical analysis rather than by re-expressing a fitted quantity as a prediction or by reducing to a self-citation. No equation or step equates the output to its input by construction; the estimation step is standard empirical-Bayes practice whose validity is justified separately by the density assumption and asymptotic arguments.
Axiom & Free-Parameter Ledger
free parameters (1)
- trend curve
axioms (1)
- domain assumption Each unit follows a linear regression model with normal errors and the residual variances share a common prior that can be estimated from the collection of units.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We then derive a nonparametric generalization of limma-trend that estimates the residual variance prior using nonparametric maximum likelihood. Under dense signals, this procedure asymptotically controls the FDR—even when the trend is misspecified or inconsistently estimated.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
limma-trend computes approximate partially Bayes p-values that condition on the residual sample variance and the unit-level summary.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Fourier Transform and Its Applications , author =. 1999 , edition =
work page 1999
-
[2]
Probability Surveys , number =
Nathan Ross , title =. Probability Surveys , number =. 2011 , doi =
work page 2011
-
[3]
Asymptotic and compound e-values: multiple testing and empirical
Ignatiadis, Nikolaos and Wang, Ruodu and Ramdas, Aaditya , journal=. Asymptotic and compound e-values: multiple testing and empirical
-
[4]
Compound decision theory and empirical
Zhang, Cun-Hui , journal=. Compound decision theory and empirical
-
[5]
arXiv preprint arXiv:2209.13686 , year=
False discovery rate adjustments for average significance level controlling tests , author=. arXiv preprint arXiv:2209.13686 , year=
-
[6]
Journal of the Royal Statistical Society: Series B , volume=
Compound decisions and empirical Bayes , author=. Journal of the Royal Statistical Society: Series B , volume=. 1969 , publisher=
work page 1969
- [7]
-
[8]
Herbert Robbins Selected Papers , pages=
Asymptotically subminimax solutions of compound statistical decision problems , author=. Herbert Robbins Selected Papers , pages=
-
[9]
The Annals of Statistics , year =
Du, Lilun and Zhang, Chunming , title =. The Annals of Statistics , year =
-
[10]
J. A. Ferreira and A. H. Zwinderman , title =. The Annals of Statistics , number =
-
[11]
The Annals of Statistics , number =
Etienne Roquain and Nicolas Verzelen , title =. The Annals of Statistics , number =
-
[12]
Storey, John D. and Taylor, Jonathan E. and Siegmund, David , title =. Journal of the Royal Statistical Society: Series B , volume =
- [13]
-
[14]
Boucheron, Stéphane and Lugosi, Gábor and Massart, Pascal , title =. 2013 , abstract =
work page 2013
-
[15]
Kwon, Yeil and Zhao, Zhigen , title =. Biometrika , volume =. 2023 , doi =
work page 2023
-
[16]
Journal of the American Statistical Association , volume =
Lilun Du and Inchi Hu , title =. Journal of the American Statistical Association , volume =. 2022 , publisher =
work page 2022
-
[17]
The Annals of Statistics , number =
Sujayam Saha and Adityanand Guntuboyina , title =. The Annals of Statistics , number =
-
[18]
J. Kiefer and J. Wolfowitz , title =. The Annals of Mathematical Statistics , number =
-
[19]
The Annals of Statistics , number =
Noel Cressie , title =. The Annals of Statistics , number =
- [20]
-
[21]
Journal of the American Statistical Association , volume =
Tweedie's Formula and Selection Bias , author =. Journal of the American Statistical Association , volume =. 2011 , publisher =
work page 2011
-
[22]
Voom: Precision Weights Unlock Linear Model Analysis Tools for
Law, Charity W and Chen, Yunshun and Shi, Wei and Smyth, Gordon K , year =. Voom: Precision Weights Unlock Linear Model Analysis Tools for. Genome Biology , volume =
-
[23]
Yuhan Hao and Stephanie Hao and Erica Andersen-Nissen and William M. Mauck and Shiwei Zheng and Andrew Butler and Maddie J. Lee and Aaron J. Wilk and Charlotte Darby and Michael Zager and Paul Hoffman and Marlon Stoeckius and Efthymia Papalexi and Eleni P. Mimitou and Jaison Jain and Avi Srivastava and Tim Stuart and Lamar M. Fleming and Bertrand Yeung an...
-
[24]
and Boutros, Michel and Michelson, Alan M
Choe, Seung E. and Boutros, Michel and Michelson, Alan M. and Church, George M. and Halfon, Marc S. , title =. Genome Biology , volume =. 2005 , doi =
work page 2005
- [25]
-
[26]
Fox, Robert J. and Dimmic, Matthew W. , title =. BMC Bioinformatics , volume =. 2006 , doi =
work page 2006
-
[27]
Fasolino, Maria and Schwartz, Guy W. and Patil, Anuj R. and Rutter, Guy A. and Rorsman, Patrik and Eizirik, Decio L. and Marchetti, Piero and Wernig, Markus and Weir, Gordon C. and Dutta, Anindya and others , title =. Nature Metabolism , volume =. 2022 , doi =
work page 2022
-
[28]
Lopez, Romain and Regier, Jeffrey and Cole, Michael B. and Jordan, Michael I. and Yosef, Nir , title =. Nature Methods , volume =. 2018 , doi =
work page 2018
-
[29]
Journal of the Royal Statistical Society: Series B , volume =
Genovese, Christopher and Wasserman, Larry , title =. Journal of the Royal Statistical Society: Series B , volume =
- [30]
-
[31]
and Nowicka, Malgorzata and Soneson, Charlotte and Robinson, Mark D
Weber, Lukas M. and Nowicka, Malgorzata and Soneson, Charlotte and Robinson, Mark D. , year =. Diffcyt:. Communications Biology , volume =
- [32]
-
[33]
The Annals of Statistics , volume =
Wenhua Jiang and Cun-Hui Zhang , title =. The Annals of Statistics , volume =. 2009 , publisher =
work page 2009
-
[34]
and Zhang, Yijing and Shao, Zhen , year =
Tu, Shiqi and Li, Mushan and Chen, Haojie and Tan, Fengxiang and Xu, Jian and Waxman, David J. and Zhang, Yijing and Shao, Zhen , year =. Genome Research , volume =
- [35]
-
[36]
Sartor, Maureen A and Tomlinson, Craig R and Wesselkamper, Scott C and Sivaganesan, Siva and Leikauf, George D and Medvedovic, Mario , year =. Intensity-Based Hierarchical. BMC Bioinformatics , volume =
-
[37]
The Proteomic Landscape of Genome-Wide Genetic Perturbations , author =. 2023 , journal =
work page 2023
-
[38]
Phipson, Belinda and Oshlack, Alicia , year =. Genome Biology , volume =
-
[39]
Smyth, Gordon K , journal =. Linear Models and Empirical. 2004 , volume =
work page 2004
-
[40]
Ignatiadis, Nikolaos and Sen, Bodhisattva , year =. Empirical Partially. The Annals of Statistics , volume =
-
[41]
Benjamini, Yoav and Hochberg, Yosef , year =. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing , shorttitle =. Journal of the Royal Statistical Society: Series B , volume =
-
[42]
Nonparametric Estimation of Genewise Variance for Microarray Data , author =. 2010 , journal =
work page 2010
-
[43]
Carroll, R. J. and Wang, Y. , year =. Nonparametric Variance Estimation in the Analysis of Microarray Data: A Measurement Error Approach , shorttitle =. Biometrika , volume =
-
[44]
Variance Estimation in the Analysis of Microarray Data , author =. 2009 , journal =
work page 2009
-
[45]
Statistics in Medicine , volume =
Li, Mushan and Ma, Yanyuan , title =. Statistics in Medicine , volume =
- [46]
-
[47]
and Nettleton, Dan and McCarthy, Davis J
Lund, Steven P. and Nettleton, Dan and McCarthy, Davis J. and Smyth, Gordon K. , year =. Detecting Differential Expression in. Statistical Applications in Genetics and Molecular Biology , volume =
-
[48]
Moderated Estimation of Fold Change and Dispersion for
Love, Michael I and Huber, Wolfgang and Anders, Simon , year =. Moderated Estimation of Fold Change and Dispersion for. Genome Biology , volume =
-
[49]
and Chen, Yunshun and Smyth, Gordon K
McCarthy, Davis J. and Chen, Yunshun and Smyth, Gordon K. , year =. Differential Expression Analysis of Multifactor. Nucleic Acids Research , volume =
- [50]
-
[51]
Berg, Philip and Popescu, George , year =. Baldur:. Molecular & Cellular Proteomics , volume =
-
[52]
and Zhou Tran, Yan and Mermelekas, Georgios and Johansson, Henrik J
Zhu, Yafeng and Orre, Lukas M. and Zhou Tran, Yan and Mermelekas, Georgios and Johansson, Henrik J. and Malyutina, Alina and Anders, Simon and Lehti. 2020 , journal =
work page 2020
-
[53]
Townsend, E. C. and Xu, K. and De La Cruz, K. and Huang, L. and Sandstrom, S. and Meudt, J. J. and Shanmuganayagam, D. and Huttenlocher, A. and Gibson, A. L. F. and Kalan, L. R. , editor =. Establishing an. 2025 , journal =
work page 2025
-
[54]
and Phipson, Belinda and Wu, Di and Hu, Yifang and Law, Charity W
Ritchie, Matthew E. and Phipson, Belinda and Wu, Di and Hu, Yifang and Law, Charity W. and Shi, Wei and Smyth, Gordon K. , year =. Limma Powers Differential Expression Analyses for. Nucleic Acids Research , volume =
-
[55]
Covariate-assisted Ranking and Screening for Large-scale Two-sample Inference (with Discussion) , author =. 2019 , journal =
work page 2019
-
[56]
Li, Mushan and Tu, Shiqi and Li, Zijia and Tan, Fengxiang and Liu, Jian and Wang, Qian and Zhang, Yuannyu and Xu, Jian and Zhang, Yijing and Zhou, Feng and Shao, Zhen , year =. Cell Discovery , volume =
-
[57]
The Plasmodium falciparum transcriptome in severe malaria reveals altered expression of genes involved in important processes including surface antigen--encoding var genes , author=. PLoS Biology , volume=. 2018 , publisher=
work page 2018
-
[58]
Goswami, Sangeeta and Apostolou, Irina and Zhang, Jan and Skepner, Jill and Anandhan, Swetha and Zhang, Xuejun and Xiong, Liangwen and Trojer, Patrick and Aparicio, Ana and Subudhi, Sumit K and others , journal=. Modulation of. 2018 , publisher=
work page 2018
-
[59]
Cox, D. R. , year =. A Note on Partially. Biometrika , volume =
-
[60]
Convex Optimization, Shape Constraints, Compound Decisions, and Empirical
Koenker, Roger and Mizera, Ivan , year =. Convex Optimization, Shape Constraints, Compound Decisions, and Empirical. Journal of the American Statistical Association , volume =
-
[61]
Dicker, Lee H. and Zhao, Sihai D. , year =. High-Dimensional Classification via Nonparametric Empirical. Biometrika , volume =
-
[62]
and Guntuboyina, Adityanand and Sen, Bodhisattva , title =
Soloff, Jake A. and Guntuboyina, Adityanand and Sen, Bodhisattva , title =. Journal of the Royal Statistical Society: Series B , year =
-
[63]
Estimates of Income for Small Places: An Application of
Fay III, Robert E and Herriot, Roger A , year =. Estimates of Income for Small Places: An Application of. Journal of the American Statistical Association , volume =
-
[64]
Advances in Neural Information Processing Systems , author =
Covariate-Powered Empirical. Advances in Neural Information Processing Systems , author =. 2019 , volume =
work page 2019
- [65]
-
[66]
Robust Hyperparameter Estimation Protects against Hypervariable Genes and Improves Power to Detect Differential Expression , author =. 2016 , journal =
work page 2016
-
[67]
Lu, Mengyin and Stephens, Matthew , journal =. Variance Adaptive Shrinkage (. 2016 , volume =
work page 2016
-
[68]
Selection and Validation of Normalization Methods for C-
Fan, Jianqing and Niu, Yue , year =. Selection and Validation of Normalization Methods for C-. Bioinformatics , volume =
-
[69]
Nucleic Acids Research , volume =
Chen, Yunshun and Chen, Lizhong and Lun, Aaron T L and Baldoni, Pedro L and Smyth, Gordon K , year =. Nucleic Acids Research , volume =
-
[70]
A Generalization of the Method of Maximum Likelihood: Estimating a Mixing Distribution (Abstract) , author =. 1950 , journal =
work page 1950
-
[71]
Large-Scale Estimation under Unknown Heteroskedasticity , author =. 2025 , journal =
work page 2025
- [72]
-
[73]
Large-Scale Inference: Empirical
Efron, Bradley , year =. Large-Scale Inference: Empirical
- [74]
-
[75]
Prediction-Powered Adaptive Shrinkage Estimation , booktitle =
Li, Sida and Ignatiadis, Nikolaos , year =. Prediction-Powered Adaptive Shrinkage Estimation , booktitle =
-
[76]
A Bioconductor workflow for processing, evaluating, and interpreting expression proteomics data , author=. F1000Research , volume=
-
[77]
Communications biology , volume=
diffcyt: Differential discovery in high-dimensional cytometry via high-resolution clustering , author=. Communications biology , volume=. 2019 , publisher=
work page 2019
-
[78]
Proteome Analysis of Corynebacterium diphtheriae--Macrophage Interaction , author=. Proteomics , pages=. 2025 , publisher=
work page 2025
-
[79]
The Journal of clinical investigation , volume=
Modulation of EZH2 expression in T cells improves efficacy of anti--CTLA-4 therapy , author=. The Journal of clinical investigation , volume=. 2018 , publisher=
work page 2018
-
[80]
CILP2 is a potential biomarker for the prediction and therapeutic target of peritoneal metastases in colorectal cancer , author=. Scientific Reports , volume=. 2024 , publisher=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.