What Does Deep Hedging Actually Learn? Delta Corrections, Regime Fragility, and Symbolic Distillation
Pith reviewed 2026-05-22 08:34 UTC · model grok-4.3
The pith
Deep hedging agents learn a delta haircut relative to Black-Scholes that stems from spot-implied-volatility co-movement and improves reward but is fragile to regime shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
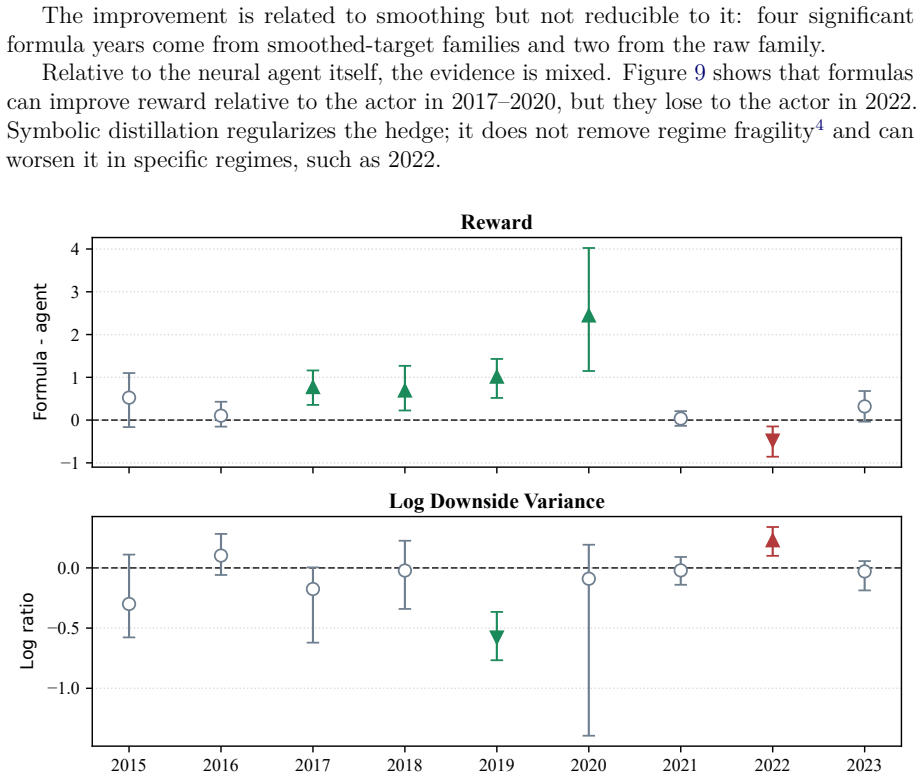
In walk-forward tests from 2015 to 2023, the TD3 agents usually learn a systematic delta haircut relative to Black-Scholes. The correction is explained by spot-implied-volatility co-movement and often improves accumulated reward and terminal downside variance, but it is regime-fragile: 2022 exposes losses in adverse daily states, while 2023 shows that underhedging can raise ordinary variance when option P&L is spot-dominated and the volatility channel is unusually weak. Symbolic regression distills the neural policies into compact formulas that preserve much of the reward, downside-variance, and CVaR advantage over Black-Scholes.
What carries the argument
TD3 reinforcement learning agents trained to minimize local downside shortfall, whose policies are distilled into symbolic formulas for interpretability.
If this is right
- The delta haircut can be approximated by simple closed-form expressions obtained through symbolic regression.
- Distilled formulas often retain or enhance the performance gains in reward and risk metrics compared to Black-Scholes.
- Regime fragility indicates that the learned hedge requires adjustment or additional safeguards during periods of changing volatility dynamics.
- Symbolic distillation makes the hedging policy auditable and tradable without the original neural network.
Where Pith is reading between the lines
- Explicitly modeling the spot-volatility relationship in the reward function could reduce the observed fragility.
- Testing the distilled formulas on out-of-sample data from different asset classes would check generalizability.
- Regime detection mechanisms might be added to switch between different learned policies based on current market conditions.
Load-bearing premise
The local downside-shortfall reward aligns with the hedger's true economic objective and the 2015-2023 windows represent typical future regimes without unmodeled breaks.
What would settle it
A test in a post-2023 period where implied volatility and spot prices decouple or where volatility remains stable while spot moves strongly would show if the delta haircut still improves outcomes or leads to underperformance.
Figures










read the original abstract
This paper studies empirical deep hedging for S&P 500 index options under a local downside-shortfall reward. It moves beyond performance comparison by asking what the learned hedge does, when it fails, and whether it can be made auditable. TD3 agents are compared with a daily-updated Black-Scholes delta hedge on the same option episodes. In walk-forward tests from 2015 to 2023, the agents usually learn a systematic delta haircut relative to Black-Scholes. The correction is explained by spot-implied-volatility co-movement and often improves accumulated reward and terminal downside variance, but it is regime-fragile: 2022 exposes losses in adverse daily states, while 2023 shows that underhedging can raise ordinary variance when option P&L is spot-dominated and the volatility channel is unusually weak. Symbolic regression distills the neural policies into compact formulas that can be traded out of sample; these formulas preserve much of the reward, downside-variance, and CVaR advantage over Black-Scholes, and sometimes sharpen it, but inherit the same fragility in difficult regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies TD3 deep hedging agents for S&P 500 index options trained under a local downside-shortfall reward. In walk-forward tests over 2015-2023 episodes, the agents learn a systematic delta haircut relative to a daily-updated Black-Scholes benchmark. This correction is attributed to spot-implied-volatility co-movement and is reported to improve accumulated reward and terminal downside variance in most regimes, though it exhibits fragility (losses in adverse 2022 states and elevated ordinary variance in 2023 when the volatility channel weakens). Symbolic regression is then applied post-training to distill the neural policies into compact formulas that largely retain the performance advantages out-of-sample while improving auditability.
Significance. If the empirical patterns and distillation results hold under tighter controls, the work advances deep hedging research by shifting focus from performance benchmarking to mechanistic interpretation and regime-aware limitations. The multi-year walk-forward design and post-hoc symbolic distillation provide concrete strengths: the former tests temporal robustness, while the latter yields auditable formulas that can be traded directly. These elements address practical concerns in risk management about model opacity and fragility, though the explanatory power of the spot-IV link remains to be isolated from confounders.
major comments (2)
- [§4] §4 (walk-forward results): The central claim that the learned delta haircut is 'explained by spot-implied-volatility co-movement' rests on observed correlations within the 2015-2023 episodes. No ablation is reported that generates controlled paths holding marginal spot and IV distributions fixed while breaking their joint dynamics (e.g., via orthogonalized or synthetic trajectories). Without this, alternative mechanisms such as liquidity premia, discrete rebalancing costs, or unmodeled jumps cannot be ruled out, leaving the causal account under-determined and directly affecting the interpretation of regime fragility in 2022/2023.
- [§3, §4] §3 and §4: The manuscript reports consistent improvements in accumulated reward and terminal downside variance but provides neither formal statistical tests (p-values, bootstrap confidence intervals, or multiple-testing corrections across regimes) nor exact data filters and full TD3 hyperparameter values. These omissions are load-bearing for the claim that the haircut 'often improves' performance, as they prevent assessment of whether observed differences exceed sampling variability or depend on undisclosed preprocessing choices.
minor comments (2)
- [§2] The precise functional form of the local downside-shortfall reward (including any scaling or threshold parameters) should be stated explicitly as an equation in the methods section to allow exact reproduction of the training objective.
- [Figures 3-5, Table 2] Figure captions for policy visualizations and performance tables would benefit from explicit mention of the number of episodes per year and the exact definition of 'terminal downside variance' to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight important aspects of causal identification and statistical rigor. We address each major comment below and indicate the revisions we intend to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (walk-forward results): The central claim that the learned delta haircut is 'explained by spot-implied-volatility co-movement' rests on observed correlations within the 2015-2023 episodes. No ablation is reported that generates controlled paths holding marginal spot and IV distributions fixed while breaking their joint dynamics (e.g., via orthogonalized or synthetic trajectories). Without this, alternative mechanisms such as liquidity premia, discrete rebalancing costs, or unmodeled jumps cannot be ruled out, leaving the causal account under-determined and directly affecting the interpretation of regime fragility in 2022/2023.
Authors: We agree that the attribution to spot-IV co-movement is based on observed correlations and economic intuition rather than a controlled ablation that isolates joint dynamics while preserving marginal distributions. Generating realistic synthetic paths that break dependence without introducing artifacts (e.g., violating no-arbitrage or option pricing consistency) is non-trivial and was not performed. We view the co-movement as the most plausible primary mechanism given the strength of the empirical link and the nature of volatility exposure in the reward, but we acknowledge that alternatives such as liquidity effects or jumps cannot be definitively excluded. In revision we will change the language from 'explained by' to 'primarily consistent with' and add an explicit limitations paragraph discussing alternative mechanisms and the absence of a full ablation study. revision: partial
-
Referee: [§3, §4] §3 and §4: The manuscript reports consistent improvements in accumulated reward and terminal downside variance but provides neither formal statistical tests (p-values, bootstrap confidence intervals, or multiple-testing corrections across regimes) nor exact data filters and full TD3 hyperparameter values. These omissions are load-bearing for the claim that the haircut 'often improves' performance, as they prevent assessment of whether observed differences exceed sampling variability or depend on undisclosed preprocessing choices.
Authors: We accept that the absence of formal statistical tests and complete hyperparameter disclosure limits the ability to assess sampling variability and robustness. In the revised version we will add bootstrap confidence intervals for the key performance differences (accumulated reward, terminal downside variance, and CVaR) across the walk-forward regimes, apply a suitable multiple-testing correction, and include the full TD3 hyperparameter table together with precise data-filtering rules in a new appendix. These additions will directly address the concern that the reported improvements may not exceed sampling variability. revision: yes
Circularity Check
No significant circularity: results derive from external benchmarks and post-training analysis
full rationale
The paper trains TD3 agents on a local downside-shortfall reward using walk-forward episodes from 2015-2023, then compares the resulting policies directly against a daily-updated Black-Scholes delta benchmark on the same episodes. The observed delta haircut and its attribution to spot-IV co-movement are extracted from the trained policies and from observed data dynamics after training; symbolic regression is applied only after policy training to distill formulas, not to define the objective or target. No equation or claim reduces by construction to a fitted parameter renamed as prediction, nor does any load-bearing premise rest on a self-citation chain that itself assumes the target result. The derivation chain therefore remains self-contained against the external Black-Scholes benchmark and out-of-sample evaluation.
Axiom & Free-Parameter Ledger
free parameters (2)
- TD3 algorithm hyperparameters
- Downside-shortfall reward parameters
axioms (1)
- domain assumption Daily-updated Black-Scholes delta constitutes the relevant baseline for comparison.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rt+1 = 10 (0.03 + PnL(100)t+1 - |PnL(100)t+1|); equivalent to minimizing E[∑ γt (PnL-) ] (Eq. 3.7-3.8)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
symbolic regression distills neural policies into compact formulas... selected complexity 9.6
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Empirical performance of alternative option pricing models.The Journal of Finance, 52(5):2003–2049,
Gurdip Bakshi, Charles Cao, and Zhiwu Chen. Empirical performance of alternative option pricing models.The Journal of Finance, 52(5):2003–2049,
work page 2003
-
[2]
doi: 10.3905/jfds.2020.1.052. William G. Cochran.Sampling Techniques. John Wiley & Sons, New York, 3rd edition,
-
[3]
Vincent François-Lavet, Peter Henderson, Riashat Islam, Marc G
doi: 10.1007/s007800050008. Vincent François-Lavet, Peter Henderson, Riashat Islam, Marc G. Bellemare, and Joelle Pineau. An introduction to deep reinforcement learning.Foundations and Trends in Machine Learning, 11(3–4):219–354,
-
[4]
Scott Fujimoto, Herke van Hoof, and David Meger
doi: 10.1561/2200000071. Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InProceedings of the 35th International Conference on Machine Learning, volume 80, pages 1587–1596. PMLR,
-
[5]
doi: 10.1609/aaai.v32i1.11694. Steven L. Heston. A closed-form solution for options with stochastic volatility with applications to bond and currency options.The Review of Financial Studies, 6(2): 327–343,
-
[6]
doi: 10.1016/j.jbankfin.2017.05.006. Petter N. Kolm and Gordon Ritter. Dynamic replication and hedging: A reinforcement learning approach.The Journal of Financial Data Science, 1(1):159–171,
-
[7]
Vasanttilak Naik. Option valuation and hedging strategies with jumps in the volatility of asset returns.The Journal of Finance, 48(5):1969–1984,
work page 1969
-
[8]
28 Xianhua Peng, Xiang Zhou, Bo Xiao, and Yi Wu
Available athttps://artowen.su.domains/mc/. 28 Xianhua Peng, Xiang Zhou, Bo Xiao, and Yi Wu. A risk sensitive contract-unified reinforcement learning approach for option hedging.arXiv preprint arXiv:2411.09659,
-
[9]
Andrei A. Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation.arXiv preprint arXiv:1511.06295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller
doi: 10.1023/A:1022506825795. David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic policy gradient algorithms. InProceedings of the 31st Interna- tional Conference on Machine Learning, volume 32 ofProceedings of Machine Learning Research, pages 387–395. PMLR,
-
[11]
29 A Symbolic-Distillation Sampling Details The smooth-focus family uses the same smoothed target as the smooth-uniform family, but changes the distribution of symbolic-regression probe points. It combines two standard devices: stratified sampling over state-space cells and importance-weighted sampling toward regions expected to matter more for fitting th...
work page 1977
-
[12]
30 Table 12: Random-seed robustness: second final-style seed
Reward, CVaR, and mean P&L are agent-minus-Black-Scholes differences; the variance columns are log agent-to-Black-Scholes ratios.∗,∗∗, and∗∗∗denote 10%, 5%, and 1% two-sided two-stage bootstrap significance, respectively. 30 Table 12: Random-seed robustness: second final-style seed. Year Reward CVaR 5% Mean P&L Log Downside Variance Log Variance 20151.875...
work page 2020
-
[13]
Comparison Reward CVaR 5% Log Downside Variance Log Variance Haircut–BS0.186(5/2)−0.074(1/1)0.030(2/1)−0.080(1/1) Haircut–Agent−0.341(0/5)−0.175(0/3)0.449(0/6)−0.119(1/1) Haircut–Formula−0.945(0/5)−0.196(0/7)0.547(0/9)−0.093(2/1) B.5 Regime-Switching Distillation Check As a targeted diagnostic for 2022, the analysis fits regime-switching symbolic policies...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.