Narrative Sharpens Gender Gaps: Surveying Film Characters with LLM Agents
Pith reviewed 2026-05-22 04:43 UTC · model grok-4.3
The pith
LLM agents built from film scripts reproduce and exaggerate gender differences in attitudes based on portrayed behaviors alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
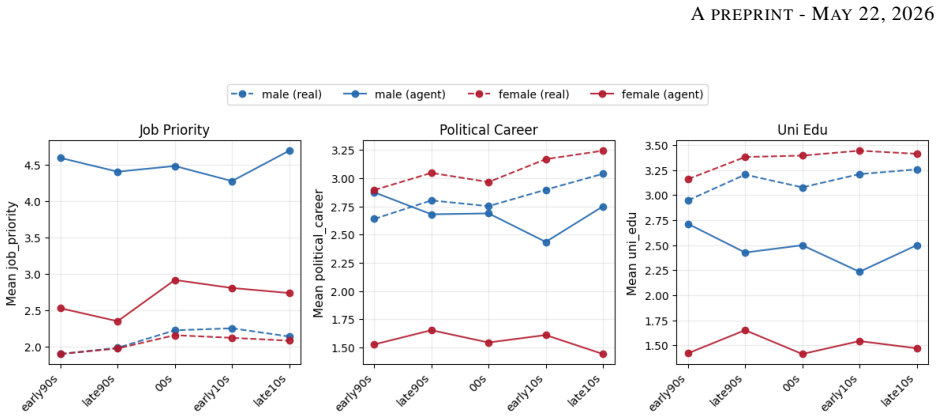
Using 160 films from 1990 to 2019, the authors create 734 character agents by feeding script dialogue and scene descriptions into language models, then condensing each persona through reflection steps before eliciting responses to gender-attitude questions. The agents produce consistent gender differences without any demographic prompting, and these simulated gaps exceed the size and stability of historical survey data. The work shows that narrative elements sharpen rather than reduce gender contrasts, which undercuts the assumption in cultivation theory that repeated media exposure leads to mainstreaming of views.
What carries the argument
The LLM agent simulation that conditions responses on condensed personas derived from film scripts and scene descriptions, then elicits answers to standardized gender-attitude survey items.
If this is right
- Large media collections can be surveyed for encoded attitudes at scale without manual annotation of every character.
- AI systems trained on film scripts and dialogue may acquire stylized gender views before any further model training occurs.
- The mainstreaming mechanism in cultivation theory requires adjustment when applied to narrative media that heightens rather than averages differences.
- Gender attitudes in the simulations arise from depicted actions and speech patterns more than from any stated identity labels.
- Decade-to-decade changes in simulated gaps track film content more closely than real population trends do.
Where Pith is reading between the lines
- The same agent construction method could be applied to other cultural domains such as television or novels to compare how different media forms shape attitude gaps.
- Early intervention on training data selection might reduce inherited stylization if film corpora are shown to be a primary source of the observed sharpening.
- Direct comparisons between agent responses and matched historical respondent subgroups could test how closely the simulations track real viewer exposure effects.
Load-bearing premise
The survey responses mainly capture the content of the film scripts and scenes rather than patterns already present in the language model before any script input is given.
What would settle it
Building agents from the same scripts but with all gender-specific dialogue and behaviors swapped and then checking whether the attitude gaps reverse direction or disappear.
Figures
read the original abstract
Mainstream film is one of the richest sources of cultural content that AI systems learn from. Yet we have few tools for measuring the gender values it encodes. We present a proof-of-concept framework that turns fictional film characters into surveyable LLM agents. Using 160 U.S. films (1990--2019), we build 734 character agents from script dialogue and scene descriptions, condense their personas via expert-style reflections, and simulate World Values Survey gender-attitude responses. Agents reproduce systematic gender differences without explicit demographic prompting, suggesting attitudes emerge from behavior rather than identity labels. Benchmarked against historical survey data, agents exaggerate gender gaps and show greater decade-to-decade volatility than real populations. Narrative sharpens rather than homogenizes gender contrasts, complicating the consistent-input assumption underlying cultivation theory's mainstreaming mechanism. AI systems trained on such corpora may inherit this stylization before any model-level amplification occurs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a proof-of-concept framework that converts characters from 160 U.S. films (1990–2019) into LLM agents built from script dialogue and scene descriptions. After condensing personas via expert-style reflections, the authors simulate World Values Survey responses on gender attitudes for 734 agents. The central claims are that agents reproduce systematic gender differences without explicit demographic prompting, that these gaps are exaggerated and more volatile than historical survey benchmarks, and that narrative input sharpens rather than homogenizes gender contrasts, thereby challenging the consistent-input assumption in cultivation theory’s mainstreaming mechanism.
Significance. If the attribution to narrative content can be isolated and the simulation validated, the work supplies a scalable computational method for quantifying gender-value encodings in mainstream media corpora. This has direct relevance for understanding pre-training data biases in large language models and for empirically testing cultivation theory with falsifiable, character-level measurements.
major comments (3)
- [Methods] Methods section (agent construction and prompting): The claim that observed gender gaps and the sharpening effect are attributable to film narratives rather than base-model priors is load-bearing for the central thesis, yet the manuscript provides no ablation that removes or neutralizes narrative input (e.g., agents built from character names alone, randomized neutral descriptions, or script-ablated controls). Without such isolation, the exaggeration relative to historical surveys and the decade-to-decade volatility cannot be confidently tied to the 1990–2019 films.
- [Results] Results section (benchmarking and statistical controls): The statements that agents “exaggerate gender gaps” and exhibit “greater decade-to-decade volatility” are presented without reported details on how historical survey samples were matched, what statistical tests or effect-size thresholds were applied, or robustness checks across prompt variations and model choices. These omissions leave the quantitative comparisons open to alternative explanations.
- [Methods] Validation subsection: No human baseline or inter-rater validation is described for the expert-style reflections or for the simulated survey responses. Without such grounding, it remains unclear whether the agents’ outputs primarily reflect the supplied narrative content or patterns already latent in the underlying LLM.
minor comments (2)
- [Abstract] Abstract: The phrase “expert-style reflections” is introduced without a brief definition or reference to the exact prompting template; a one-sentence clarification would improve readability.
- [Figures/Tables] Figure captions and tables: Ensure all reported gender-gap magnitudes include confidence intervals or standard errors so readers can assess the practical significance of the exaggeration claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. The comments highlight important areas for strengthening the attribution of effects to narrative content and improving the robustness of our analyses. We address each major comment below and indicate the revisions we will make in the updated version of the paper.
read point-by-point responses
-
Referee: [Methods] Methods section (agent construction and prompting): The claim that observed gender gaps and the sharpening effect are attributable to film narratives rather than base-model priors is load-bearing for the central thesis, yet the manuscript provides no ablation that removes or neutralizes narrative input (e.g., agents built from character names alone, randomized neutral descriptions, or script-ablated controls). Without such isolation, the exaggeration relative to historical surveys and the decade-to-decade volatility cannot be confidently tied to the 1990–2019 films.
Authors: We agree that isolating the contribution of narrative input is essential to support our central thesis. The current framework constructs agents exclusively from script-derived dialogue and scene descriptions, with no explicit demographic or identity prompts, allowing attitudes to emerge from portrayed behaviors. To strengthen this, we will add an ablation study in the revised Methods and Results sections. This will include control conditions such as agents initialized with only character names and basic demographics, or with randomized neutral descriptions, to isolate the effect of the film narrative content on the observed gender gaps and volatility. revision: yes
-
Referee: [Results] Results section (benchmarking and statistical controls): The statements that agents “exaggerate gender gaps” and exhibit “greater decade-to-decade volatility” are presented without reported details on how historical survey samples were matched, what statistical tests or effect-size thresholds were applied, or robustness checks across prompt variations and model choices. These omissions leave the quantitative comparisons open to alternative explanations.
Authors: We appreciate this point and will enhance the transparency of our benchmarking. In the revised manuscript, we will provide detailed descriptions of: the matching procedure between agent responses and historical World Values Survey data (including demographic and temporal alignment), the statistical methods employed (such as independent t-tests for gap comparisons and variance tests for volatility), effect size calculations (e.g., Cohen's d), and additional robustness analyses varying prompt templates and using alternative LLM backbones. These additions will better rule out alternative explanations and solidify the comparisons. revision: yes
-
Referee: [Methods] Validation subsection: No human baseline or inter-rater validation is described for the expert-style reflections or for the simulated survey responses. Without such grounding, it remains unclear whether the agents’ outputs primarily reflect the supplied narrative content or patterns already latent in the underlying LLM.
Authors: We acknowledge the value of human validation for grounding the simulations. As this is a proof-of-concept study with a large number of agents, a comprehensive inter-rater reliability study was not feasible within the current scope. However, we will incorporate a limited human evaluation in the revision: a subset of 50 agents will be reviewed by domain experts to assess the fidelity of the condensed personas and survey responses to the original script material. We will report inter-rater agreement metrics and discuss any discrepancies. This will be presented as an initial validation step, with full-scale validation noted as future work. revision: partial
Circularity Check
No significant circularity in empirical simulation framework
full rationale
The paper describes an empirical proof-of-concept that constructs LLM agents from film script dialogue and scene descriptions, condenses personas via reflections, and simulates World Values Survey responses. No equations, fitted parameters, or derivations are present that would reduce reported gender gaps or volatility to quantities defined by the authors' own choices. Results are benchmarked against external historical survey data rather than internal fits. No self-citation load-bearing for uniqueness theorems, ansatzes, or renamings of known results. The central claims rest on the agent construction and comparison process, which does not collapse by construction to the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We build 734 character agents from 160 U.S. films... simulate World Values Survey gender-attitude responses.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ISSN 1476-4989. doi: 10.1017/pan.2023.2. URLhttp://dx.doi.org/10.1017/pan.2023.2. David Bamman, Brendan T. O’Connor, and Noah A. Smith. Learning latent personas of film characters. InAnnual Meeting of the Association for Computational Linguistics,
-
[2]
ISSN 1091-6490. doi: 10.1073/pnas.2409770121. URL http://dx.doi.org/10.1073/pnas. 2409770121. James Bisbee, Joshua D. Clinton, Cassy Dorff, Brenton Kenkel, and Jennifer M. Larson. Synthetic replacements for human survey data? the perils of large language models.Political Analysis, 32(4):401–416, May
-
[3]
ISSN 1476-4989. doi: 10.1017/pan.2024.5. URLhttp://dx.doi.org/10.1017/pan.2024.5. Henry Farrell, Alison Gopnik, Cosma Shalizi, and James Evans. Large ai models are cultural and social technologies. Science, 387(6739):1153–1156, March
-
[4]
ISSN 1095-9203. doi: 10.1126/science.adt9819. URL http: //dx.doi.org/10.1126/science.adt9819. 5 APREPRINT- MAY22, 2026 George Gerbner and Larry Gross. Living with television: The violence profile.Journal of Communication, 26(2): 172–199,
-
[5]
doi: 10.1111/j.1460-2466.1976.tb01397.x. Christian Haerpfer, Ronald Inglehart, Alejandro Moreno, Christian Welzel, Kseniya Kizilova, Jaime Diez-Medrano, Marta Lagos, Pippa Norris, Eduard Ponarin, and Bi Puranen. World values survey time-series (1981-2022) cross- national data-set,
-
[6]
URLhttps://www.worldvaluessurvey.org/WVSDocumentationWVL.jsp. Stuart Hall. Encoding/decoding. In Stuart Hall, Dorothy Hobson, Andrew Lowe, and Paul Willis, editors,Culture, Media, Language: Working Papers in Cultural Studies, 1972–79. Hutchinson, London,
work page 1972
-
[7]
ISSN 2573-0142. doi: 10.1145/3359300. URLhttp://dx.doi.org/10.1145/3359300. Austin C. Kozlowski, Matt Taddy, and James A. Evans. The geometry of culture: Analyzing the meanings of class through word embeddings.American Sociological Review, 84(5):905–949, September
-
[8]
ISSN 1939-8271. doi: 10.1177/0003122419877135. URLhttp://dx.doi.org/10.1177/0003122419877135. Victor R Martinez, Krishna Somandepalli, and Shrikanth Narayanan. Boys don’t cry (or kiss or dance): A computational linguistic lens into gendered actions in film.PLoS One, 17(12):e0278604, December
-
[9]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
URL https://arxiv.org/abs/2411.10109. Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. Whose opinions do language models reflect?,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://arxiv.org/abs/2303.17548. Rohit Saxena and Frank Keller. MovieSum: An abstractive summarization dataset for movie screenplays. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics ACL 2024, pages 4043–4050, Bangkok, Thailand and virtual meeting, August
-
[11]
URLhttps://aclanthology.org/2024.findings-acl.239
Association for Computational Linguistics. URLhttps://aclanthology.org/2024.findings-acl.239. Gaye Tuchman. Introduction: The symbolic annihilation of women by the mass media. In Gaye Tuchman, Arlene Kaplan Daniels, and James Benét, editors,Hearth and Home: Images of Women in the Mass Media, pages 3–38. Oxford University Press, New York,
work page 2024
-
[12]
URLhttp://www.jstor.org/stable/189945
ISSN 08912432. URLhttp://www.jstor.org/stable/189945. Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. Men also like shopping: Reducing gender bias amplification using corpus-level constraints. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, page 2979–2989. Association for Computational L...
work page 2017
-
[13]
URLhttp://dx.doi.org/10.18653/v1/D17-1323
doi: 10.18653/v1/d17-1323. URLhttp://dx.doi.org/10.18653/v1/D17-1323. A Survey Emulation Prompt The following prompt template was adapted from Park et al. (2024) and used to simulate survey responses for each character agent. 6 APREPRINT- MAY22, 2026 V ariables: !<INPUT 0>!: demographic descriptions !<INPUT 1>!: survey questions <commentblockmarker> ### <...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.