A critical comparison of handling zeros in high-dimensional compositional count data
Pith reviewed 2026-05-22 02:03 UTC · model grok-4.3
The pith
Existing imputation strategies for zeros in compositional count data must be adapted to discrete and zero-inflated structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The review establishes that violations of continuity assumptions in the log-ratio framework induce numerical instabilities and biased statistical inferences when applied to sequencing-derived compositional count data. Systematic comparison of imputation strategies reveals that their behavior shifts when the discrete, lattice-valued nature of the counts is respected, and it identifies open challenges that motivate future zero-handling frameworks capable of jointly accommodating compositional constraints, zero inflation, and the lattice nature of count data.
What carries the argument
Log-ratio transformations whose continuity assumptions conflict with discrete zero-inflated count observations, together with the adaptation of imputation procedures to the integer lattice structure of the data.
If this is right
- Imputation accuracy and stability decline when the discrete lattice nature of counts is ignored.
- Log-ratio calculations on sequencing count data produce numerical instabilities and distorted inferences without adaptation.
- Statistical conclusions about compositional structure become biased under unadjusted zero-handling methods.
- Future zero-handling methods must simultaneously respect sum constraints, zero inflation, and integer-valued observations.
Where Pith is reading between the lines
- Analyses of microbiome count tables that rely on off-the-shelf CoDA pipelines may systematically understate or overstate taxon associations until zero methods are updated for discreteness.
- The same continuity mismatch could affect abundance modeling in single-cell or ecological count data, suggesting broader testing of lattice-aware imputations.
- Software implementations could be extended to enforce integer constraints during imputation while preserving the compositional sum-to-one property.
Load-bearing premise
Violations of continuity assumptions in the log-ratio framework induce numerical instabilities and biased statistical inferences when applied to sequencing-derived compositional count data.
What would settle it
A controlled simulation on zero-inflated compositional counts that applies both standard and discretely adapted imputation, then compares resulting bias in log-ratio estimates or downstream inference accuracy, would settle whether adaptation is required.
Figures











read the original abstract
The growing use of high-throughput sequencing (HTS) has enabled the large-scale production of compositional count data, driving progress in microbiome research. However, such count data are often high-dimensional, over-dispersed, and heavily zero-inflated, and they conflict with the continuity assumptions underlying log-ratio-based compositional data analysis (CoDA), creating substantial methodological challenges. This review provides an overview of zero-handling strategies in compositional data, covering zero-tolerant transformations, imputation approaches for rounded zeros, and statistical models for essential zeros. We specifically highlight the problems that arise when applying the log-ratio framework to sequencing-derived compositional count data, where violations of continuity can induce numerical instabilities and biased statistical inferences. Motivated by these issues, we systematically examine how existing imputation strategies behave when adapted to discrete, zero-inflated count data, including an evaluation of how the discrete, lattice-valued nature of the data affects imputation performance. Overall, this review consolidates scattered methodological developments, clarifies appropriate use cases, and identifies open challenges that motivate future zero-handling frameworks capable of jointly accommodating compositional constraints, zero inflation, and the lattice nature of count data, while also providing a detailed discussion of the comparison results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reviews zero-handling strategies for high-dimensional compositional count data from high-throughput sequencing applications such as microbiome studies. It covers zero-tolerant transformations, imputation methods for rounded zeros, and statistical models for essential zeros. The review emphasizes conflicts between the continuity assumptions of log-ratio CoDA and the discrete, zero-inflated, over-dispersed nature of sequencing count data, which can cause numerical instabilities and biased inferences. It systematically examines the behavior of existing imputation strategies when adapted to such data and evaluates the effects of the lattice-valued discrete structure on imputation performance, ultimately consolidating methods, clarifying use cases, and motivating future frameworks that jointly address compositional constraints, zero inflation, and count-data lattice properties.
Significance. If the evaluation holds, the review provides a timely consolidation of scattered methodological developments in zero handling for compositional count data, which is relevant given the widespread use of HTS in microbiome research. It clarifies appropriate use cases for different strategies and identifies open challenges, potentially guiding practitioners and motivating integrated modeling approaches. The paper's strength lies in its structured overview and explicit discussion of comparison results rather than new derivations or proofs.
major comments (1)
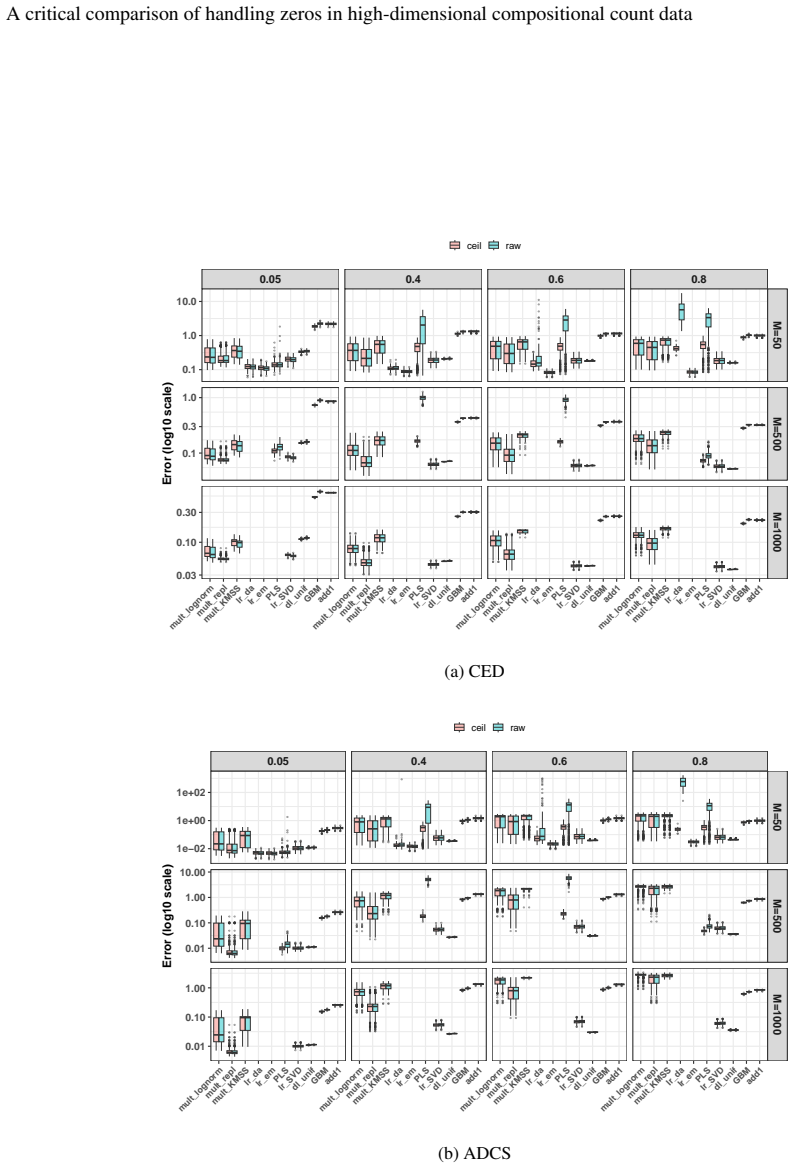
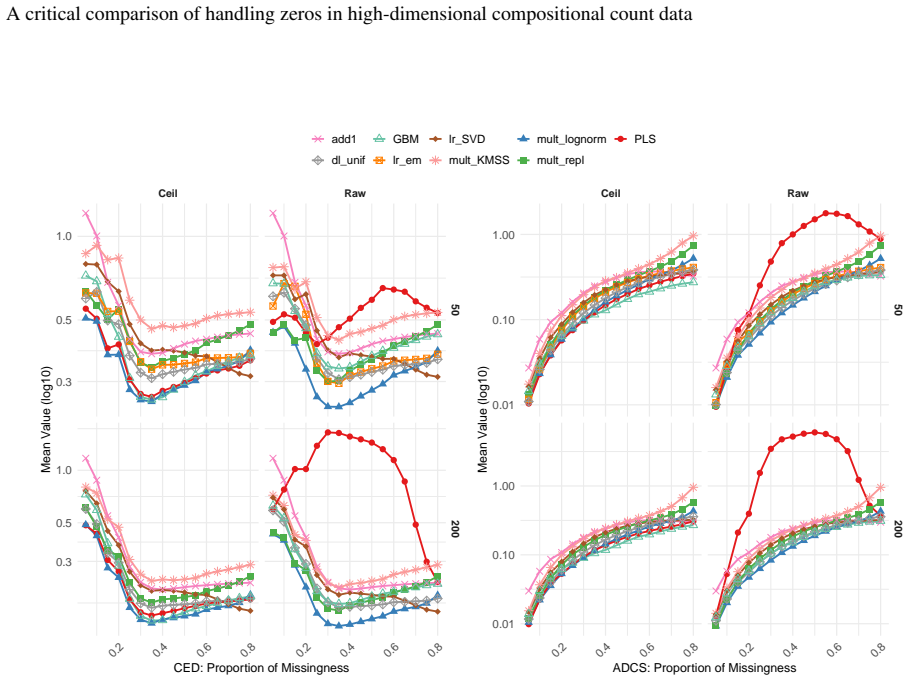
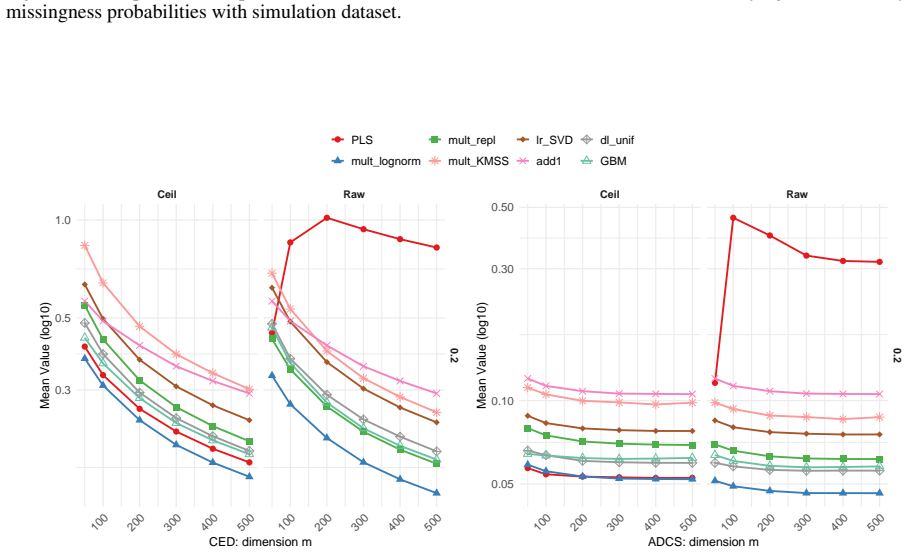
- [Abstract and evaluation section] Abstract and the section describing the evaluation of imputation strategies: the claim that existing imputation approaches must be adapted for discrete zero-inflated count data, and that this motivates new joint frameworks, rests on the stated evaluation of how the lattice-valued nature affects performance. If this evaluation consists primarily of literature synthesis without original controlled simulations (e.g., generating multinomial or negative-binomial counts with known zero patterns, applying multiple imputers, and quantifying recovery via Aitchison distance or downstream log-ratio inference error), then the necessity of adaptation is not quantitatively demonstrated and the central motivation for future frameworks is weakened.
minor comments (2)
- The abstract could more explicitly state the number of imputation methods compared and the key quantitative findings from the performance evaluation to better orient readers before the detailed discussion.
- Notation for compositional constraints and lattice properties could be introduced more consistently in early sections to aid readers unfamiliar with the intersection of CoDA and count-data models.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which recognizes the value of consolidating zero-handling methods for compositional count data. We address the major comment below and outline revisions to strengthen clarity around the nature of our evaluation.
read point-by-point responses
-
Referee: [Abstract and evaluation section] Abstract and the section describing the evaluation of imputation strategies: the claim that existing imputation approaches must be adapted for discrete zero-inflated count data, and that this motivates new joint frameworks, rests on the stated evaluation of how the lattice-valued nature affects performance. If this evaluation consists primarily of literature synthesis without original controlled simulations (e.g., generating multinomial or negative-binomial counts with known zero patterns, applying multiple imputers, and quantifying recovery via Aitchison distance or downstream log-ratio inference error), then the necessity of adaptation is not quantitatively demonstrated and the central motivation for future frameworks is weakened.
Authors: We agree that original controlled simulations would provide stronger quantitative support for the motivation. As this is a review paper, the evaluation section synthesizes and critically discusses results from existing literature studies that have performed such controlled experiments on imputation for zero-inflated count data, including assessments of performance degradation due to the discrete lattice structure (e.g., via recovery metrics and downstream inference errors). These synthesized findings consistently indicate the limitations of unadapted methods. To address the concern and avoid ambiguity, we will revise the abstract and evaluation section to explicitly characterize the evaluation as a structured literature synthesis of prior comparative studies, add specific citations to simulation-based works quantifying the effects, and clarify how this synthesis supports the call for integrated frameworks. This revision will be made without introducing new empirical results. revision: yes
Circularity Check
Review paper with no self-referential derivations or fitted predictions
full rationale
This is a review paper whose central contribution is an overview and critique of existing zero-handling strategies drawn from external literature. No new quantities are derived from the paper's own equations, fitted parameters, or self-citations in a load-bearing way; the text instead consolidates scattered methodological developments and identifies open challenges without reducing any claim to a tautological fit or self-citation chain. The evaluation of imputation strategies is presented as a synthesis of prior work rather than a closed-loop prediction, leaving the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Log-ratio transformations assume continuous data without zeros.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
violations of continuity can induce numerical instabilities and biased statistical inferences... discrete, lattice-valued nature of the data affects imputation performance
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
log-ratio framework... ALR, CLR, ILR transformations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=
Real-time segmentation of on-line handwritten arabic script , author=. Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=. 2014 , organization=
work page 2014
-
[2]
Fast classification of handwritten on-line
Kour, George and Saabne, Raid , booktitle=. Fast classification of handwritten on-line. 2014 , organization=
work page 2014
-
[3]
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications , author=. arXiv preprint arXiv:1804.09028 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Tang, M.-L. and Wu, Q. and Yang, S. and Tian, G.-L. , title =. Biometrical Journal , volume =. doi:10.1002/bimj.202000334 , year =
-
[5]
Comparison of zero replacement strategies for compositional data with large numbers of zeros , journal =. 2021 , doi =
work page 2021
-
[6]
Artificial Neural Networks to Impute Rounded Zeros in Compositional Data , booktitle =
Templ, Matthias , editor =. Artificial Neural Networks to Impute Rounded Zeros in Compositional Data , booktitle =. 2021 , publisher =
work page 2021
-
[7]
Imputation of rounded zeros for high-dimensional compositional data , journal =. 2016 , doi =
work page 2016
-
[8]
J. Palarea-Albaladejo and J. A. Martín-Fernández and A. Ruiz-Gazen and C. Thomas-Agnan , title =. Journal of Chemometrics , volume =. doi:10.1002/cem.3459 , year =
-
[9]
Schwob, M. R. and Hooten, M. B. and Calzada, N. M. , title =. Annals of Applied Statistics , year =
-
[10]
Scealy, J. L. and Welsh, A. H. , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2011 , month =
work page 2011
-
[11]
Model-based replacement of rounded zeros in compositional data: Classical and robust approaches , journal =. 2012 , issn =. doi:https://doi.org/10.1016/j.csda.2012.02.012 , url =
-
[12]
A bootstrap estimation scheme for chemical compositional data with nondetects , journal =
Javier Palarea-Albaladejo and Josep Antoni Mart. A bootstrap estimation scheme for chemical compositional data with nondetects , journal =. 2014 , month =
work page 2014
-
[13]
A modified EM alr-algorithm for replacing rounded zeros in compositional data sets , journal =. 2008 , issn =. doi:https://doi.org/10.1016/j.cageo.2007.09.015 , url =
-
[14]
A Parametric Approach for Dealing with Compositional Rounded Zeros , journal =
Javier Palarea-Albaladejo and Josep Antoni Mart. A Parametric Approach for Dealing with Compositional Rounded Zeros , journal =. 2007 , month =
work page 2007
-
[15]
Christian P. Robert , title =. Statistics and Computing , volume =. 2009 , pages =
work page 2009
-
[16]
Tanner and Wing Hung Wong , title =
Martin A. Tanner and Wing Hung Wong , title =. Journal of the American Statistical Association , volume =. 1987 , pages =
work page 1987
- [17]
-
[18]
Proceedings of CODAWORK'03 -- The 1st Compositional Data Analysis Workshop , year =
Mart. Proceedings of CODAWORK'03 -- The 1st Compositional Data Analysis Workshop , year =
-
[19]
Gerald and Tolosana-Delgado, Raimon , year=
van den Boogaart, K. Gerald and Tolosana-Delgado, Raimon , year=
- [20]
-
[21]
J. A. Martín-Fernandez and C. Barcel. Dealing with zeros and missing values in compositional data sets using nonparametric imputation , journal =. 2003 , doi =
work page 2003
-
[22]
Mathematical Geosciences , volume =
Fišerová, Eva and Hron, Karel , title =. Mathematical Geosciences , volume =. 2011 , month =
work page 2011
-
[23]
Filzmoser, Peter and Hron, Karel and Templ, Matthias , title =. 2018 , publisher =
work page 2018
-
[24]
Computational Statistics & Data Analysis , volume =
Hron, Karel and Templ, Matthias and Filzmoser, Peter , title =. Computational Statistics & Data Analysis , volume =. 2010 , doi =
work page 2010
- [25]
- [26]
-
[27]
arXiv preprint arXiv:2208.13073 , year =
Tsagris, Michail , title =. arXiv preprint arXiv:2208.13073 , year =. doi:10.48550/arXiv.2208.13073 , url =
-
[28]
Journal of the Royal Statistical Society
Adam Butler and Chris Glasbey , title =. Journal of the Royal Statistical Society. Series C (Applied Statistics) , volume =. 2008 , month =. doi:10.1111/j.1467-9876.2008.00629.x , url =
- [29]
- [30]
-
[31]
Tim R. L. Fry and Derek Chong , title =. 2005 , booktitle =
work page 2005
-
[32]
J. J. Egozcue , title =. 2009 , journal =
work page 2009
-
[33]
and Chua, Xin-Yi and McGrath, Annette , title =
Lovell, David R. and Chua, Xin-Yi and McGrath, Annette , title =. NAR Genomics and Bioinformatics , volume =. 2020 , doi =
work page 2020
-
[34]
Bayesian-multiplicative treatment of count zeros in compositional data sets , volume =
Martín-Fernández, Josep and Hron, Karel and Templ, Matthias and Filzmoser, Peter and Palarea-Albaladejo, Javier , year =. Bayesian-multiplicative treatment of count zeros in compositional data sets , volume =. Statistical Modelling , doi =
-
[35]
Bayesian tools for zero counts in compositional data , journal =
Daunis-i-Estadella, Pepus and Martín-Fernández, Josep and Palarea-Albaladejo, Javier , year =. Bayesian tools for zero counts in compositional data , journal =
-
[36]
Journal of the American Statistical Association , year =
Yanyan Zeng and Daolin Pang and Hongyu Zhao and Tao Wang , title =. Journal of the American Statistical Association , year =. doi:10.1080/01621459.2022.2044827 , url =
-
[37]
Koslovsky, Matthew , year =. A. Biometrics , doi =
- [38]
-
[39]
Zezhong Tang and Guanhua Chen , title =. Biostatistics , year =. doi:10.1093/biostatistics/kxy025 , pmid =
-
[40]
Koh and Jaeyun Kim and Qiang Li and Xiang Zhan , title =
Shuang Jiang and Guangjin Xiao and Andrew Y. Koh and Jaeyun Kim and Qiang Li and Xiang Zhan , title =. Biostatistics , year =. doi:10.1093/biostatistics/kxz050 , pmid =
-
[41]
URL https://doi.org/10.1080/ 01621459.2017.1307116
Bo Ren and Sergio Bacallado and Stefano Favaro and Susan Holmes and Lorenzo Trippa , title =. Journal of the American Statistical Association , year =. doi:10.1080/01621459.2017.1288631 , pmid =
-
[42]
The Annals of Applied Statistics , year =
Bo Ren and Sergio Bacallado and Stefano Favaro and Tommi Vatanen and Curtis Huttenhower and Lorenzo Trippa , title =. The Annals of Applied Statistics , year =
-
[43]
Frontiers in Microbiology , volume=
Compositional data analysis of microbiome and any-omics datasets: a validation of the additive logratio transformation , author=. Frontiers in Microbiology , volume=. 2021 , doi=
work page 2021
-
[44]
Gregory B. Gloor and Jean M. Macklaim and Vera Pawlowsky-Glahn and Juan Jose Egozcue , title =. Frontiers in Microbiology , volume =. 2017 , doi =
work page 2017
-
[45]
Fernandes, Andrew D and Macklaim, Jean M and Linn, Thomas G and Reid, Gregor and Gloor, Gregory B , title =. PLoS One , year =. doi:10.1371/journal.pone.0067019 , pmid =
-
[46]
Dong, Z. M. and Shang, H. L. and Hui, F. and Bruhn, A. , title =. Annals of Actuarial Science , year =
-
[47]
Bear, J. and Billheimer, D. , title =. Austrian Journal of Statistics , year =. doi:10.17713/ajs.v45i4.117 , url =
-
[48]
Stewart, C. and Field, C. , title =. Journal of Agricultural, Biological, and Environmental Statistics , year =. doi:10.1007/s13253-010-0040-8 , url =
-
[49]
Leininger, T. J. and Gelfand, A. E. and Allen, J. M. and others , title =. Journal of Agricultural, Biological, and Environmental Statistics , year =. doi:10.1007/s13253-013-0145-y , url =
-
[50]
Tsagris, M. and Stewart, C. , title =. Lobachevskii Journal of Mathematics , year =
-
[51]
Journal of Applied Statistics , year =
Chen, Jiajia and Zhang, Xiaoqin and Hron, Karel and Templ, Matthias and Li, Shengjia , title =. Journal of Applied Statistics , year =. doi:10.1080/02664763.2017.1410524 , url =
-
[52]
D. J. Stekhoven and P. Bühlmann , title =. Bioinformatics , year =. doi:10.1093/bioinformatics/btr597 , url =
-
[53]
S. van Buuren and K. Groothuis-Oudshoorn , title =. Journal of Statistical Software , year =
- [54]
-
[55]
Dorey, F. J. and Little, R. J. and Schenker, N. , title =. Statistics in Medicine , year =. doi:10.1002/sim.4780121706 , pmid =
-
[56]
Javier Palarea-Albaladejo and Josep Antoni Martín-Fernández , keywords =. zCompositions —. Chemometrics and Intelligent Laboratory Systems , volume =. 2015 , issn =. doi:https://doi.org/10.1016/j.chemolab.2015.02.019 , url =
-
[57]
Zhang, Y. and Schluter, J. and Zhang, L. and Cao, X. and Jenq, R. R. and Feng, H. and Haines, J. and Zhang, L. , title =. Computational and Structural Biotechnology Journal , year =. doi:10.1016/j.csbj.2024.11.003 , pmid =
-
[58]
A data-based power transformation for compositional data , journal =
Tsagris, Michail and Preston, Simon and Wood, Andrew , year =. A data-based power transformation for compositional data , journal =
-
[59]
Improved classification for compositional data using the -transformation , volume =
Tsagris, Michail and Preston, Simon and Wood, Andrew , year =. Improved classification for compositional data using the -transformation , volume =. Journal of Classification , doi =
-
[60]
Advances in Data Analysis and Classification , volume =
The chiPower transformation: a valid alternative to logratio transformations in compositional data analysis , author =. Advances in Data Analysis and Classification , volume =. 2024 , publisher =
work page 2024
-
[61]
Compositional Data Analysis: Theory and Applications , editor =
Matthias Templ and Karel Hron and Peter Filzmoser , title =. Compositional Data Analysis: Theory and Applications , editor =. 2011 , pages =
work page 2011
-
[62]
Conesa, Ana and Madrigal, Pedro and Tarazona, Sonia and Gomez-Cabrero, David and Cervera, Amparo and McPherson, Andrew and Szczesniak, Michal W. and Gaffney, Daniel J. and Elo, Laura L. and Zhang, Xuegong and Mortazavi, Ali , title =. Genome Biology , year =. doi:10.1186/s13059-016-0881-8 , url =
-
[63]
Nature Reviews Microbiology , year =
Pollock, Jarrod and Glendinning, Logan and Wisedchanwet, Thepakorn and Watson, Mick , title =. Nature Reviews Microbiology , year =. doi:10.1038/s41579-018-0017-5 , url =
-
[64]
Di Bella, J. M. and Bao, Y. and Gloor, G. B. and Burton, J. P. and Reid, G. , title =. Journal of Microbiological Methods , year =. doi:10.1016/j.mimet.2013.08.011 , url =
-
[65]
The Annals of Applied Statistics , volume =
Chen, Jun and Li, Hongzhe , title =. The Annals of Applied Statistics , volume =. 2013 , month =. doi:, publisher =
work page 2013
-
[66]
Kumar, M. and Brader, G. and Sessitsch, A. and M\"aki, M. and van Elsas, J. D. and Nissinen, R. , title =. Frontiers in Microbiology , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.