From Head to Tail: Asymmetric Knowledge Transfer in Long-tail Recommendation with Generative Semantic IDs
Pith reviewed 2026-05-25 03:52 UTC · model grok-4.3
The pith
AKT-Rec directs knowledge from head to tail items via semantic clusters to handle data imbalance in recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
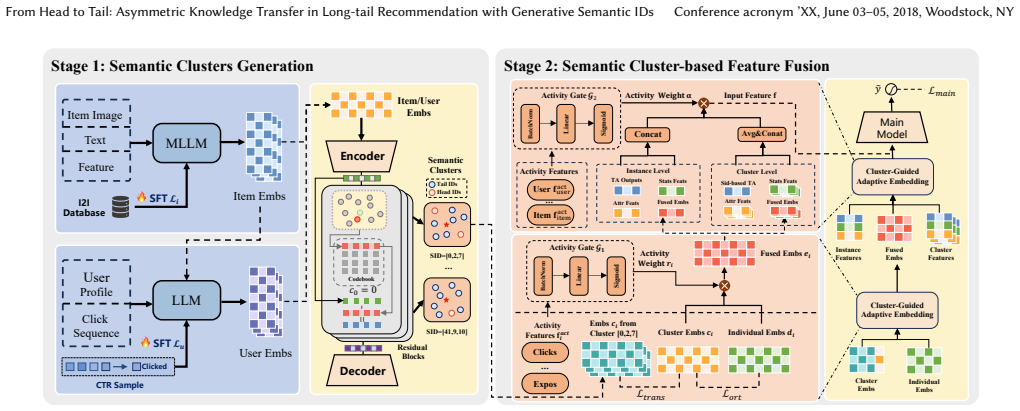
The paper claims that decomposing item and user representations into cluster-level and individual embeddings, combined with an asymmetric contrastive objective and activity-aware gating, enables beneficial knowledge transfer from head to tail IDs while limiting harmful reverse signals, and that hierarchical aggregation of parallel feature views further improves predictions across activity levels when the representations are obtained from LLM-aligned multimodal features discretized by RQ-VAE.
What carries the argument
Cluster-Guided Adaptive Embedding, which splits each ID into a shared cluster embedding and an individual embedding and uses asymmetric contrastive loss plus activity-aware gating to control head-to-tail transfer.
If this is right
- Tail-item representations improve while head-item representations remain stable or strengthen.
- Low-activity samples receive more accurate predictions through adaptive fusion of feature views.
- Semantic clusters derived from content allow collaborative signals to propagate across similar but infrequently observed items.
- The same discretization step reduces the need for separate content and ID embedding tables.
Where Pith is reading between the lines
- The same cluster decomposition could be applied to other ranking tasks that exhibit extreme popularity skew, such as content feed ranking.
- Because semantic IDs are generated once and then reused, the method may lower memory cost for very large item catalogs compared with per-item embeddings.
- If the asymmetry holds, one could test whether the same head-to-tail pattern appears in user-side long-tail modeling rather than only item-side.
Load-bearing premise
Noisy signals from tail IDs harm head ID representations, and the asymmetric contrastive objective with gating can direct useful transfer in one direction without creating new harms.
What would settle it
A controlled ablation on the same dataset in which the asymmetric contrastive term or the activity-aware gate is removed and head-item AUC or GAUC shows no gain or a drop relative to the full model.
Figures
read the original abstract
Long-tail recommendation in real-world e-commerce platforms remains challenging due to severe data imbalance. Existing methods often struggle to combine content-based multimodal features with collaborative signals. Many of these methods also ignore an important asymmetry in knowledge transfer between head and tail IDs: noisy signals from tail IDs can hurt representation learning for head IDs. This paper presents AKT-Rec, a framework for Asymmetric Knowledge Transfer in long-tail Recommendation that uses LLM-generated semantic IDs. AKT-Rec uses Multimodal LLMs (MLLMs) with supervised fine-tuning to align content representations with collaborative information for both items and users, producing semantic representations. It then discretizes these representations into semantic IDs with a Residual-Quantized VAE (RQ-VAE), which yields semantic clusters of similar entities. AKT-Rec has two main components: (1) Cluster-Guided Adaptive Embedding, which decomposes each ID representation into a cluster-level embedding that captures shared semantics and an individual embedding. Through an asymmetric contrastive objective and an activity-aware gating mechanism, this module directs knowledge transfer from head to tail IDs. (2) Hierarchical Feature Aggregation, which builds parallel feature views and adaptively fuses them to optimize predictions for samples with varying activity levels. Extensive experiments on a large-scale industrial dataset and online A/B testing on the Alibaba Tmall platform demonstrate the effectiveness of AKT-Rec. AKT-Rec improves offline performance by 0.35% in AUC and 1.53% in GAUC, outperforming several competitive baselines. In online A/B testing, AKT-Rec achieves a 2.76% increase in CTR and a 3.47% increase in GMV, validating its utility in real-world production environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AKT-Rec, a framework for long-tail recommendation that generates semantic IDs via supervised fine-tuning of multimodal LLMs followed by RQ-VAE discretization. It introduces a Cluster-Guided Adaptive Embedding module that decomposes representations into cluster-level and individual embeddings, using an asymmetric contrastive objective and activity-aware gating to direct knowledge transfer from head to tail items while protecting head representations from noisy tail signals. A Hierarchical Feature Aggregation component adaptively fuses parallel feature views. Experiments on a large-scale industrial dataset report gains of 0.35% AUC and 1.53% GAUC over baselines, with online A/B testing on Alibaba Tmall showing 2.76% CTR and 3.47% GMV lifts.
Significance. If the reported gains are robust, the work offers a concrete industrial-scale demonstration of semantic-ID-based long-tail handling that integrates multimodal content with collaborative signals via explicit asymmetry mechanisms. The online A/B results supply independent corroboration of the offline deltas, which strengthens the practical claim. The combination of generative semantic IDs, cluster-guided decomposition, and activity-aware gating is a distinctive contribution that could be adopted in other imbalanced recommendation settings.
minor comments (3)
- [Abstract] The abstract states performance deltas but supplies no information on the number or identity of baselines, the train/validation/test split protocol, or any statistical testing; these details should appear explicitly in §4 or §5 to allow readers to assess whether the 0.35% AUC lift is within expected variance.
- [Method (Cluster-Guided Adaptive Embedding)] The description of the asymmetric contrastive objective does not specify the temperature hyper-parameter or the exact positive/negative sampling strategy across head/tail clusters; adding the precise loss equation and sampling pseudocode would improve reproducibility.
- [Experiments (Online A/B Testing)] Figure captions and axis labels for the online A/B results should include the exact test duration, traffic split, and confidence intervals to match standard industrial reporting practice.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of AKT-Rec and the recommendation for minor revision. The referee's summary correctly identifies the core technical contributions, including MLLM-based semantic ID generation, RQ-VAE discretization, cluster-guided adaptive embeddings with asymmetric contrastive transfer, activity-aware gating, and hierarchical aggregation, as well as the offline and online empirical results.
Circularity Check
No significant circularity; empirical framework with independent validation
full rationale
The paper describes an applied recommendation architecture (semantic IDs via RQ-VAE, cluster-guided embeddings, asymmetric contrastive loss, activity-aware gating, hierarchical aggregation) and reports empirical gains from offline metrics and online A/B testing on Alibaba Tmall. No equations, derivations, or first-principles predictions appear that reduce by construction to fitted parameters or self-citations; the central claims are experimental outcomes rather than derived quantities.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AKT-Rec uses ... asymmetric InfoNCE objective Ltrans = λ1 Linfo(chead_i, sg(ctail_i)) + λ2 Linfo(ctail_i, sg(chead_i)) ... activity-aware gating ... Hierarchical Feature Aggregation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RQ-VAE ... semantic IDs ... cluster-level embedding ... individual embedding
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jinheon Baek, Nirupama Chandrasekaran, Silviu Cucerzan, Allen Herring, and Sujay Kumar Jauhar. 2024. Knowledge-augmented large language models for per- sonalized contextual query suggestion. InProceedings of the ACM Web Conference
work page 2024
-
[2]
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. 2019. Class- balanced loss based on effective number of samples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9268–9277
work page 2019
- [3]
-
[4]
Yingpeng Du, Di Luo, Rui Yan, Xiaopei Wang, Hongzhi Liu, Hengshu Zhu, Yang Song, and Jie Zhang. 2024. Enhancing job recommendation through llm-based generative adversarial networks. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 8363–8371
work page 2024
-
[5]
Manisha Jangid and Rakesh Kumar. 2025. Deep learning approaches to address cold start and long tail challenges in recommendation systems: a systematic review.Multimedia Tools and Applications84, 5 (2025), 2293–2325
work page 2025
-
[6]
Jian Jia, Yipei Wang, Yan Li, Honggang Chen, Xuehan Bai, Zhaocheng Liu, Jian Liang, Quan Chen, Han Li, Peng Jiang, et al. 2025. LEARN: Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Appli- cation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 11861–11869
work page 2025
- [7]
-
[8]
Jingjing Li, Ke Lu, Zi Huang, and Heng Tao Shen. 2017. Two birds one stone: on both cold-start and long-tail recommendation. InProceedings of the 25th ACM international conference on Multimedia. 898–906
work page 2017
-
[9]
Jialun Liu, Yifan Sun, Chuchu Han, Zhaopeng Dou, and Wenhui Li. 2020. Deep representation learning on long-tailed data: A learnable embedding augmentation perspective. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2970–2979
work page 2020
-
[10]
Siyi Liu and Yujia Zheng. 2020. Long-tail session-based recommendation. In Proceedings of the 14th ACM conference on recommender systems. 509–514
work page 2020
-
[11]
Sichun Luo, Chen Ma, Yuanzhang Xiao, and Linqi Song. 2023. Improving long-tail item recommendation with graph augmentation. InProceedings of the 32nd ACM international conference on information and knowledge management. 1707–1716
work page 2023
-
[12]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of- experts. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1930–1939
work page 2018
-
[13]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
work page 2020
-
[14]
Bingjun Qin, Zhenhua Huang, Xing Tian, Yunwen Chen, and Wenguang Wang
-
[15]
GACRec: Generative adversarial contrastive learning for improved long-tail item recommendation.Knowledge-Based Systems300 (2024), 112146
work page 2024
-
[16]
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, and Tat-Seng Chua. 2024. Language models encode collaborative signals in recommendation. (2024)
work page 2024
-
[17]
Xiang-Rong Sheng, Feifan Yang, Litong Gong, Biao Wang, Zhangming Chan, Yujing Zhang, Yueyao Cheng, Yong-Nan Zhu, Tiezheng Ge, Han Zhu, et al
-
[18]
InProceedings of the 33rd ACM International Conference on Information and Knowledge Management
Enhancing taobao display advertising with multimodal representations: Challenges, approaches and insights. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 4858–4865
-
[19]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Maksims Volkovs, Guangwei Yu, and Tomi Poutanen. 2017. Dropoutnet: Ad- dressing cold start in recommender systems.Advances in neural information processing systems30 (2017)
work page 2017
-
[21]
Chunyu Wei, Jian Liang, Di Liu, Zehui Dai, Mang Li, and Fei Wang. 2023. Meta graph learning for long-tail recommendation. InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining. 2512–2522
work page 2023
-
[22]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Jun- feng Wang, Dawei Yin, and Chao Huang. 2024. Llmrec: Large language models with graph augmentation for recommendation. InProceedings of the 17th ACM international conference on web search and data mining. 806–815
work page 2024
- [23]
-
[24]
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. 2024. GME: Improving Universal Multimodal Retrieval by Multimodal LLMs. arXiv:2412.16855 [cs.CL] http://arxiv.org/abs/2412.16855
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Qian Zhao, Zhengwei Wu, Zhiqiang Zhang, and Jun Zhou. 2023. Long-tail augmented graph contrastive learning for recommendation. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 387–403
work page 2023
-
[26]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068. Presenter Bio Chenyi Yanis an Algorithm Engineer at Alibaba Group, wh...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.