Adaptive KV Cache Reuse for Fast Long-Context LLM Serving
Pith reviewed 2026-06-30 17:21 UTC · model grok-4.3
The pith
CacheTune recovers cross-attention in non-prefix KV reuse by recomputing only frequency-critical tokens and overlapping I/O with computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
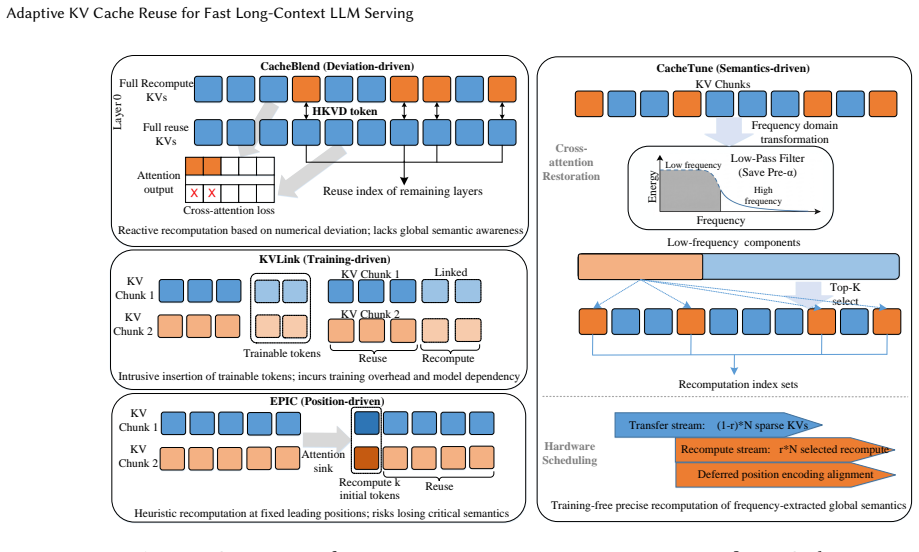
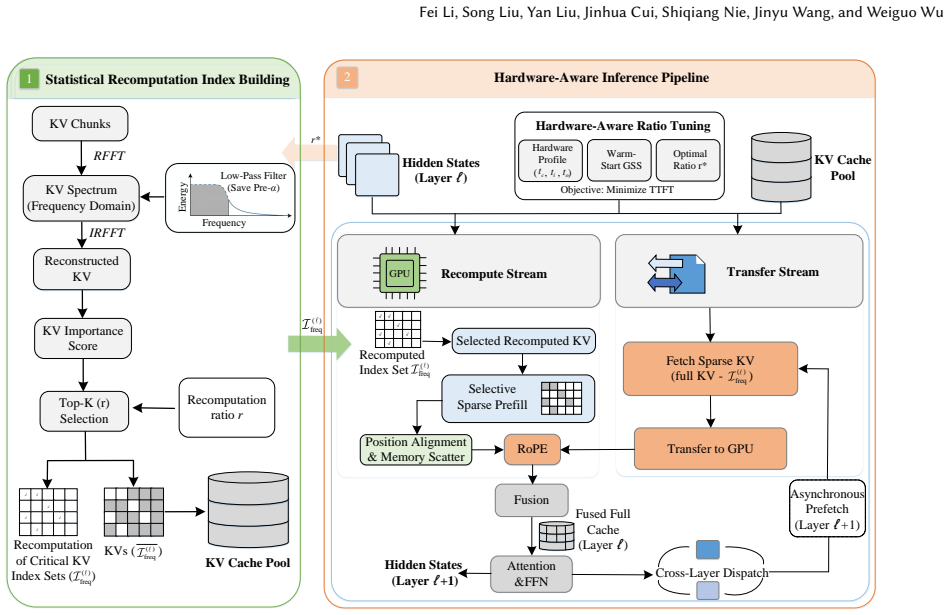
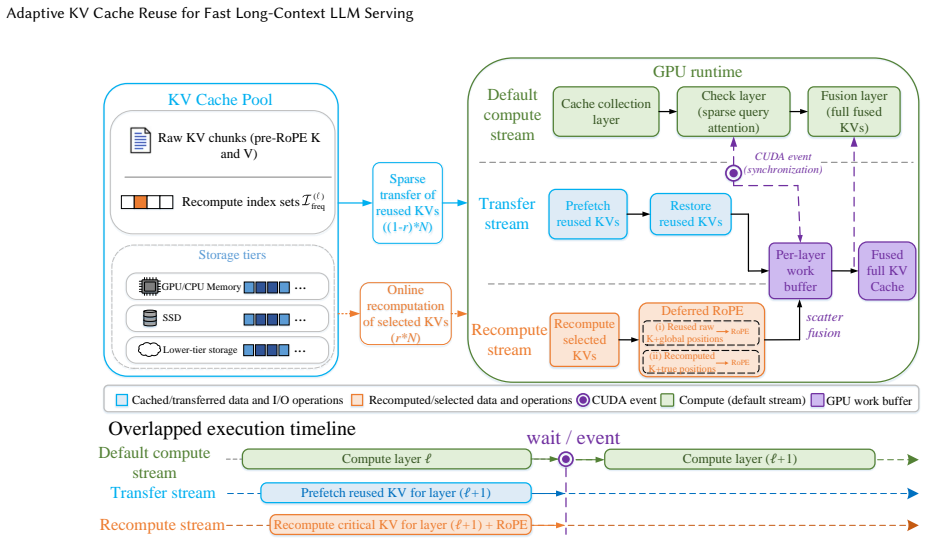
CacheTune identifies the KV pairs most critical to cross-attention recovery through offline frequency-domain analysis, selectively recomputes only those semantic-critical tokens online, and reuses the rest while applying sparse KV transfer, multi-stream asynchronous overlap, deferred positional-encoding recovery, and hardware-aware adaptive recomputation-ratio tuning to balance compute and data movement across heterogeneous cache pools.
What carries the argument
frequency-guided selective recomputation of semantic-critical tokens together with sparse transfer and multi-stream asynchronous overlap
If this is right
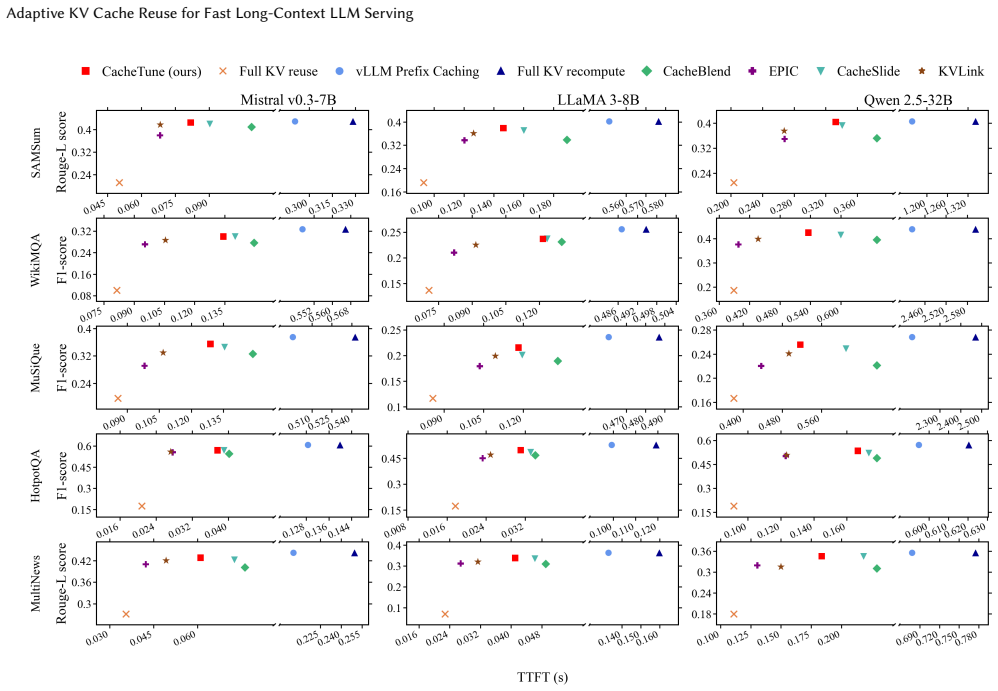
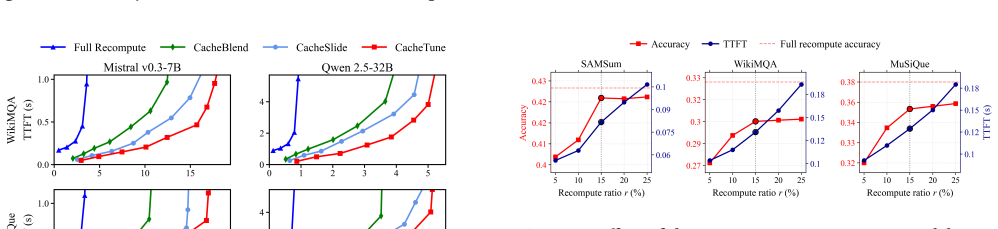
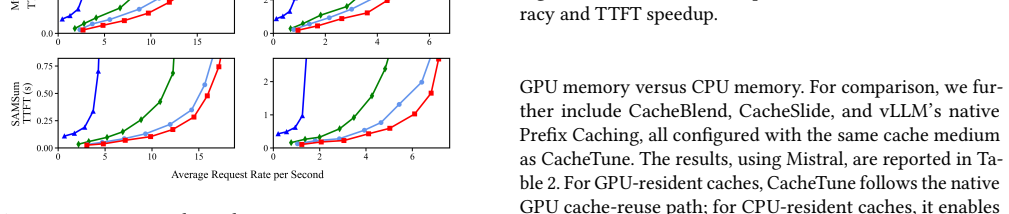
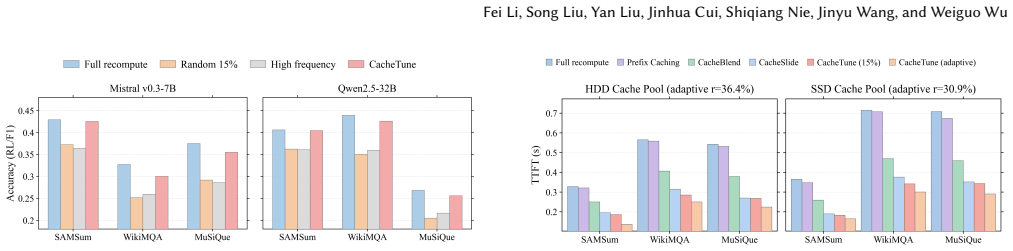
- TTFT drops by 3.72x-4.86x and throughput rises by 3.93x-6.21x on mainstream LLMs with quality close to full recompute.
- The same speedups hold when reusable KV data resides on SSD or HDD instead of GPU memory.
- Non-prefix KV reuse becomes practical without forcing strict prefix alignment between requests.
- Hardware-specific tuning automatically balances recomputation ratio against I/O cost for different storage tiers.
Where Pith is reading between the lines
- The offline frequency ranking could be refreshed periodically on representative workloads rather than once per model.
- The same selective-recompute logic might apply to other attention patterns such as grouped-query or multi-query attention.
- If frequency signatures prove stable across similar tasks, the analysis step could move online with modest overhead.
- Extending the method to dynamic context lengths would require testing whether the critical-token set changes smoothly with input size.
Load-bearing premise
Frequency-domain analysis performed offline can reliably identify the KV pairs whose selective recomputation restores cross-chunk global attention relationships sufficiently to avoid quality degradation in non-prefix reuse scenarios.
What would settle it
Run CacheTune on a non-prefix long-context task and observe whether its generation quality metrics fall measurably below those of full recompute while TTFT remains lower.
Figures
read the original abstract
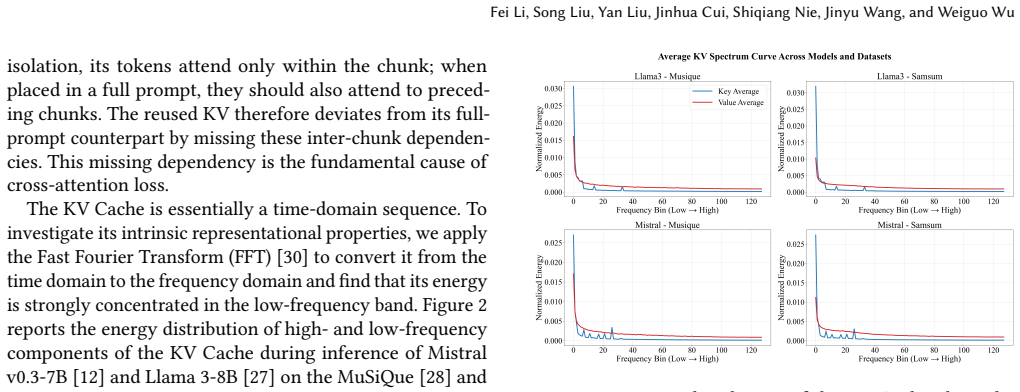
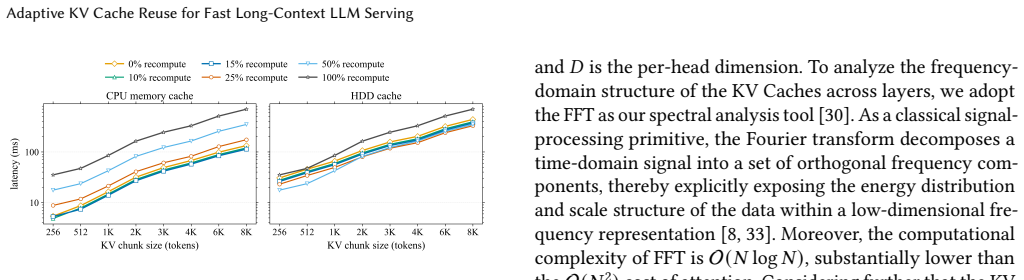
In long-context Large Language Model (LLM) inference, the Time-To-First-Token (TTFT) latency incurred by the prefill stage has become the foremost bottleneck limiting interactive performance and deployment cost. KV Cache reuse offers a direct path to reduce redundant prefill, yet traditional prefix caching applies only to strict-prefix scenarios; directly reusing KV Cache in non-prefix settings breaks the cross-chunk global attention relationships and causes significant degradation in generation quality. When reusable KV Cache is offloaded to GPU-external cache pools, I/O overheads across heterogeneous hardware tiers further emerge as a new TTFT bottleneck. Efficient non-prefix KV Cache reuse therefore requires both semantic-consistency recovery and compute-I/O co-optimization. This paper presents CacheTune, a frequency-guided and hardware-aware KV Cache reuse system for long-context LLM serving. CacheTune first identifies, offline, the KV pairs most critical to cross-attention recovery through frequency-domain analysis, and then selectively recomputes only these semantic-critical tokens online while reusing the remaining KVs. To turn this semantic selection into end-to-end latency reduction, CacheTune further combines sparse KV transfer, multi-stream asynchronous overlap, deferred positional-encoding recovery, and hardware-aware adaptive recomputation-ratio tuning to balance computation and data movement across heterogeneous cache pools. Evaluations on mainstream LLMs and long-context tasks show that CacheTune achieves 3.72x-4.86x TTFT speedup and 3.93x-6.21x higher throughput while maintaining generation quality close to full recompute. Even when caches are offloaded to I/O-bound SSD/HDD storage, CacheTune sustains 2.34x-2.36x TTFT speedup through adaptive recomputation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CacheTune, a frequency-guided and hardware-aware KV cache reuse system for long-context LLM serving. It performs offline frequency-domain analysis to identify critical KV pairs for selective recomputation in non-prefix reuse scenarios (to recover cross-chunk attention), then applies sparse KV transfer, multi-stream asynchronous overlap, deferred positional-encoding recovery, and hardware-aware adaptive recomputation-ratio tuning to co-optimize compute and I/O across GPU and external storage tiers. The abstract reports 3.72x-4.86x TTFT speedup, 3.93x-6.21x higher throughput, and 2.34x-2.36x TTFT speedup under SSD/HDD offload, while claiming generation quality close to full recompute.
Significance. If the frequency-domain selection reliably recovers necessary cross-chunk attention relationships without quality loss and the I/O-compute optimizations deliver the reported gains across models and tasks, the work would be a practical contribution to efficient long-context serving, particularly for heterogeneous memory hierarchies. The empirical speedups and the explicit handling of non-prefix reuse plus offloading are notable strengths if substantiated by rigorous experiments.
major comments (2)
- [Abstract] Abstract: the central claim that offline frequency-domain analysis identifies a sparse subset of KV pairs whose selective recomputation suffices to restore cross-chunk global attention relationships (and thereby preserve quality) is load-bearing for all reported speedups and quality results, yet the abstract supplies neither derivation, necessity/sufficiency argument, nor ablation evidence that the selected pairs align with semantic dependencies rather than signal-like properties; this directly engages the stress-test concern and prevents evaluation of soundness.
- [Abstract] Abstract: concrete speedups (3.72x-4.86x TTFT, 3.93x-6.21x throughput) and quality preservation are stated without any reference to experimental setup, models, datasets, baselines, statistical significance, or quality metrics (e.g., perplexity vs. task accuracy), rendering the claims impossible to assess; this is a load-bearing omission for an empirical systems paper.
minor comments (1)
- [Abstract] Abstract: the description of 'adaptive recomputation-ratio tuning' is introduced without indicating whether the ratio is a free parameter or derived parameter-free from hardware characteristics.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract. We address each major comment below and indicate where revisions to the manuscript will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that offline frequency-domain analysis identifies a sparse subset of KV pairs whose selective recomputation suffices to restore cross-chunk global attention relationships (and thereby preserve quality) is load-bearing for all reported speedups and quality results, yet the abstract supplies neither derivation, necessity/sufficiency argument, nor ablation evidence that the selected pairs align with semantic dependencies rather than signal-like properties; this directly engages the stress-test concern and prevents evaluation of soundness.
Authors: The abstract is intentionally concise. The frequency-domain analysis, including the mathematical derivation showing how selected frequency components recover cross-chunk attention relationships, the necessity/sufficiency argument, and evidence that the pairs align with semantic dependencies (via attention correlation and ablation), appears in Section 3.2. Section 5.3 presents ablations confirming quality preservation relative to full recompute. We will revise the abstract to add a one-sentence reference to the offline frequency-guided selection and its grounding in attention recovery. revision: yes
-
Referee: [Abstract] Abstract: concrete speedups (3.72x-4.86x TTFT, 3.93x-6.21x throughput) and quality preservation are stated without any reference to experimental setup, models, datasets, baselines, statistical significance, or quality metrics (e.g., perplexity vs. task accuracy), rendering the claims impossible to assess; this is a load-bearing omission for an empirical systems paper.
Authors: We agree that the abstract would benefit from additional context for immediate assessment. We will revise it to name the evaluated models, long-context benchmarks, quality metrics (perplexity and task accuracy), and note that speedups are relative to the non-reuse baseline with results averaged across runs. Full experimental details, including statistical reporting, remain in Sections 4 and 5. revision: yes
Circularity Check
No circularity: empirical systems paper with measured speedups
full rationale
The paper describes CacheTune as an engineering system that performs offline frequency-domain analysis to select KV pairs for selective recomputation, then applies hardware-aware optimizations (sparse transfer, async overlap, etc.) and reports measured TTFT/throughput gains on benchmarks. No equations, fitted parameters, or self-citations are presented that would make the reported speedups reduce by construction to quantities defined inside the method; the performance numbers are external empirical outcomes. The frequency-selection step is an algorithmic heuristic whose correctness is evaluated by quality metrics, not derived tautologically from the reuse policy itself. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive recomputation ratio
Forward citations
Cited by 1 Pith paper
-
Shattering the Autoregressive Curse: Dynamic Epistemic Entropy Orchestrated Erasable Reinforcement Learning for LLMs
E³RL uses dynamic thresholds on epistemic entropy from autoregressive cross-entropy to enable erasable RL in LLM reasoning, reporting 5.349% and 6.514% gains on AIME for 4B and 8B models over prior SOTA.
Reference graph
Works this paper leans on
-
[1]
Shubham Agarwal, Sai Sundaresan, Subrata Mitra, Debabrata Ma- hapatra, Archit Gupta, Rounak Sharma, Nirmal Joshua Kapu, Tong Yu, and Shiv Saini. 2025. Cache-craft: Managing chunk-caches for efficient retrieval-augmented generation.Proceedings of the ACM on Management of Data3, 3 (2025), 1–28
2025
-
[2]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al . 2024. Longbench: A bilingual, multitask benchmark for long context under- standing. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). 3119–3137
2024
-
[3]
Debendra Das Sharma, Robert Blankenship, and Daniel Berger. 2024. An Introduction to the Compute Express Link (CXL) Interconnect. ACM Comput. Surv.56, 11, Article 290 (July 2024), 37 pages. doi:10. 1145/3669900
2024
-
[4]
Alexander Richard Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir Radev. 2019. Multi-news: A large-scale multi-document summariza- tion dataset and abstractive hierarchical model. InProceedings of the 57th annual meeting of the association for computational linguistics. 1074–1084
2019
-
[5]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. {Cost- Efficient} large language model serving for multi-turn conversations with {CachedAttention}. In2024 USENIX annual technical conference (USENIX ATC 24). 111–126
2024
-
[6]
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandel- wal, and Lin Zhong. 2024. Prompt cache: Modular attention reuse for low-latency inference.Proceedings of Machine Learning and Systems6 (2024), 325–338
2024
-
[7]
Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Aleksander Wawer
-
[8]
InProceedings of the 2nd Workshop on New Frontiers in Summarization
SAMSum corpus: A human-annotated dialogue dataset for abstractive summarization. InProceedings of the 2nd Workshop on New Frontiers in Summarization. 70–79
-
[9]
Ziwei He, Meng Yang, Minwei Feng, Jingcheng Yin, Xinbing Wang, Jingwen Leng, and Zhouhan Lin. 2023. Fourier transformer: Fast long range modeling by removing sequence redundancy with fft operator. InFindings of the Association for Computational Linguistics: ACL 2023. 8954–8966
2023
-
[10]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics. 6609–6625
2020
-
[11]
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie. 2025. EPIC: Efficient Position-Independent Caching for Serving Large Language Models. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 (Proceedings of Machine Learning ...
2025
-
[12]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Qwen2.5-Coder Technical Report.CoRRabs/2409.12186 (2024). arXiv:2409.12186 doi:10.48550/ARXIV.2409.12186
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12186 2024
-
[13]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bam- ford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bres- sand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Re- nard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.CoRRabs/231...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
- [14]
-
[15]
2019.Algorithms for optimization
Mykel J Kochenderfer and Tim A Wheeler. 2019.Algorithms for optimization. Mit Press
2019
-
[16]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[17]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[18]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 155–172
2024
-
[19]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al . 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[20]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[21]
Song Liu, Fei Li, Chenyu Zhao, Qin Xia, Shiqiang Nie, Jinyu Wang, and Weiguo Wu. 2026. FDSR: Efficient Model Training via Adaptive Tensor Quantization Based on Frequency Domain Division and Similarity Data Reuse.ACM Trans. Archit. Code Optim.(April 2026). doi:10.1145/ 3802593Just Accepted
2026
-
[22]
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaot- ing Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, et al
- [23]
-
[24]
Yang Liu, Yunfei Gu, Liqiang Zhang, Chentao Wu, Guangtao Xue, Jie Li, Minyi Guo, Junhao Hu, and Jie Meng. 2026. CacheSlide: Unlocking Cross Position-Aware KV Cache Reuse for Accelerating LLM Serving. In24th USENIX Conference on File and Storage Technologies (FAST 26). 83–99
2026
-
[25]
Yuhan Liu, Hanchen Li, Kuntai Du, Jiayi Yao, Yihua Cheng, Yuyang Huang, Shan Lu, Michael Maire, Henry Hoffmann, Ari Holtzman, et al
-
[26]
CacheGen: KV cache compression and streaming for fast large language model serving, 2023
Cachegen: Fast context loading for language model applications. 13 Fei Li, Song Liu, Yan Liu, Jinhua Cui, Shiqiang Nie, Jinyu Wang, and Weiguo Wu arXiv preprint arXiv:2310.07240(2023)
-
[27]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. 2024. Mooncake: A kvcache-centric disaggregated architecture for llm serv- ing.ACM Transactions on Storage(2024)
2024
-
[28]
Zebin Ren, Krijn Doekemeijer, Tiziano De Matteis, Christian Pinto, Radu Stoica, and Animesh Trivedi. 2025. An i/o characterizing study of offloading llm models and kv caches to nvme ssd. InProceedings of the 5th Workshop on Challenges and Opportunities of Efficient and Performant Storage Systems. 23–33
2025
-
[29]
Minseok Seo, Jungi Hyun, Seongho Jeong, Xuan Truong Nguyen, Hyuk-Jae Lee, and Hyokeun Lee. 2025. OASIS: Outlier-Aware KV Cache Clustering for Scaling LLM Inference in CXL Memory Systems. IEEE Computer Architecture Letters(2025)
2025
-
[30]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. 2023. Flexgen: High-throughput generative inference of large language models with a single gpu. InInternational Conference on Machine Learning. PMLR, 31094–31116
2023
-
[31]
Llama Team. 2024. The Llama 3 Herd of Models.CoRRabs/2407.21783 (2024). arXiv:2407.21783 doi:10.48550/ARXIV.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[32]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. MuSiQue: Multihop Questions via Single-hop Ques- tion Composition.Transactions of the Association for Computational Linguistics10 (2022), 539–554
2022
-
[33]
Guanchu Wang, Zirui Liu, Zhimeng Jiang, Ninghao Liu, Na Zou, and Xia Hu. 2023. Division: memory efficient training via dual activation precision. InInternational Conference on Machine Learning. PMLR, 36036–36057
2023
-
[34]
2012.Discrete-time signal processing: an algebraic approach
Darrell Williamson. 2012.Discrete-time signal processing: an algebraic approach. Springer Science & Business Media
2012
-
[35]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. InThe Twelfth International Conference on Learning Represen- tations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=NG7sS51zVF
2024
- [36]
-
[37]
Kai Xu, Minghai Qin, Fei Sun, Yuhao Wang, Yen-Kuang Chen, and Fengbo Ren. 2020. Learning in the frequency domain. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1740–1749
2020
-
[38]
Bin Yang, Qiuyu Leng, Jun Zeng, and Zhenhua Wu. 2025. CacheClip: Accelerating RAG with Effective KV Cache Reuse.arXiv preprint arXiv:2510.10129(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
-
[40]
In: Proceedings of the 2018 Conference on Empirical Methods in Natu- ral Language Processing
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - Novem- ber 4, 2018, Ellen Riloff,...
-
[41]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. Cacheblend: Fast large language model serving for rag with cached knowledge fusion. InProceedings of the twentieth European conference on computer systems. 94–109
2025
-
[42]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.https://openreview.net/forum?id=WE_vluYUL-X
2023
-
[43]
Lu Ye, Ze Tao, Yong Huang, and Yang Li. 2024. Chunkattention: Efficient self-attention with prefix-aware kv cache and two-phase partition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 11608–11620
2024
-
[44]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured lan- guage model programs.Advances in neural information processing systems37 (2024), 62557–62583
2024
-
[45]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210. 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.