Same Ranking, Different Winner: How Scoring Targets Shape LLM Memory Benchmarks
Pith reviewed 2026-06-30 15:16 UTC · model grok-4.3
The pith
Switching the scoring target in LLM memory benchmarks changes nDCG on most queries and can reverse which system ranks highest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
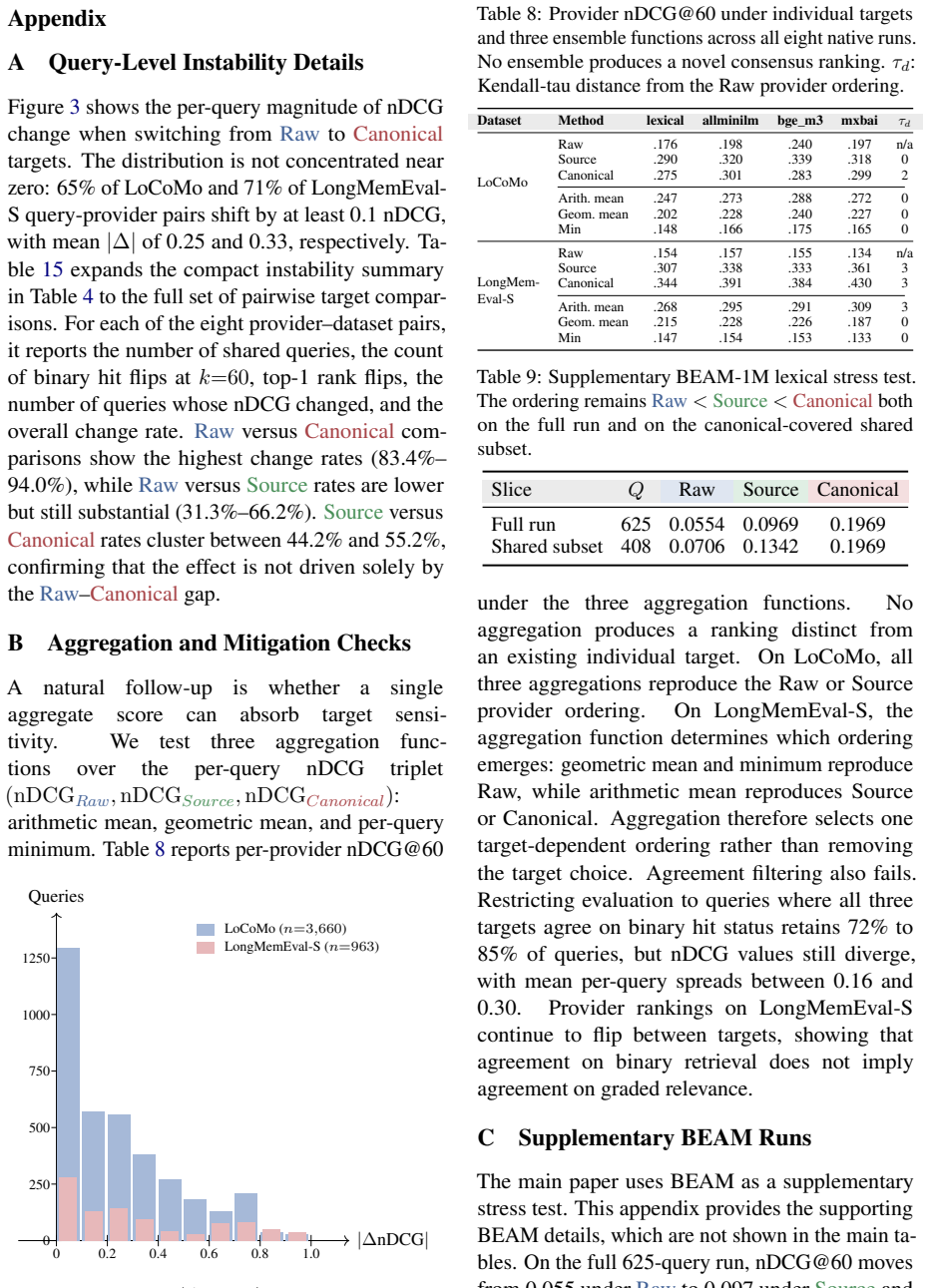
Switching only the credited target changes nDCG on 83.4--94.0 percent of shared queries, flips target orderings on Mem0 and MemoryOS transfer runs, and reverses parser-density recommendations, revealing target noninvariance where conclusions about memory architectures can silently flip with a single benchmark-design choice.
What carries the argument
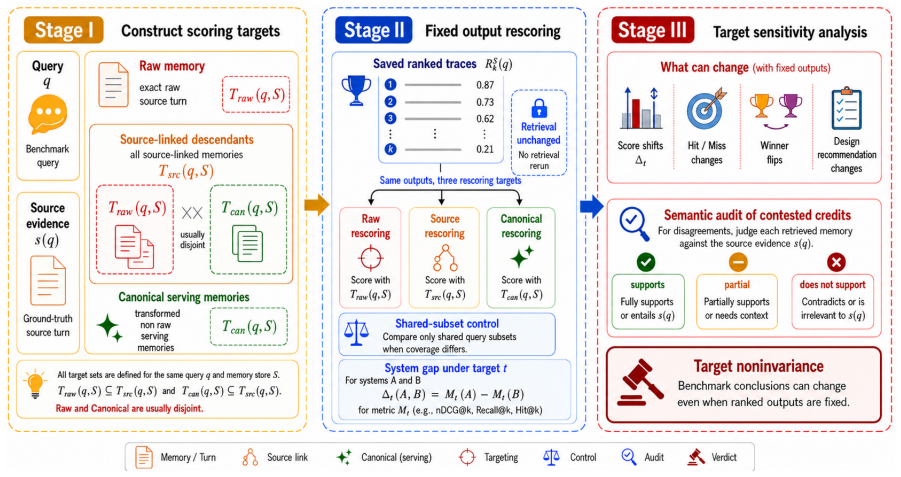
TIAP, a fixed-output audit that rescores saved ranked outputs under three targets—Raw, Source, and Canonical—without rerunning retrieval.
If this is right
- nDCG changes on 83.4-94.0 percent of shared queries when the target switches
- Target orderings flip on Mem0 and MemoryOS transfer runs
- Parser-density recommendations reverse with the target change
- Conclusions about memory architectures can flip from one benchmark-design choice
Where Pith is reading between the lines
- Papers should report results under all three targets to show robustness
- The noninvariance finding may apply to other retrieval settings that store derived content from the same source
- Standardizing a default target across the field could reduce hidden variability in comparisons
Load-bearing premise
The 1,902-case semantic audit accurately measures when relaxed source-linked credit is justified.
What would settle it
Re-scoring the same ranked outputs under different targets and finding no material change in nDCG or system orderings on the majority of queries.
Figures

read the original abstract
Conversational-memory systems increasingly transform dialogue history into facts, summaries, timelines, and other source-linked descendants, so a single source turn can coexist with several derived memories in the same retrieval index. This raises an underspecified evaluation question: which stored form should receive retrieval credit? We show that this scoring-target choice is often left implicit and can materially change benchmark conclusions. We present TIAP, a fixed-output audit that rescores saved ranked outputs under three targets -- Raw, Source, and Canonical -- without rerunning retrieval. On LoCoMo and LongMemEval-S, switching only the credited target changes nDCG on 83.4--94.0 percent of shared queries, flips target orderings on Mem0 and MemoryOS transfer runs, and reverses parser-density recommendations. A 1,902-case semantic audit further shows that relaxed source-linked credit is fully justified only 29.2 percent of the time, despite high rubric reliability in a validation subset. These results reveal target noninvariance: conclusions about memory architectures can silently flip with a single benchmark-design choice. Conversational-memory papers should therefore define and report the scoring target explicitly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that scoring-target choice (Raw, Source, Canonical) in conversational-memory retrieval benchmarks is often implicit yet materially affects outcomes: on LoCoMo and LongMemEval-S, switching targets alters nDCG on 83.4–94.0% of shared queries, reverses system orderings for Mem0 and MemoryOS, and flips parser-density recommendations. It introduces TIAP, a fixed-output rescoring procedure, and reports a 1,902-case semantic audit finding that relaxed source-linked credit is fully justified only 29.2% of the time (with high rubric reliability noted only on a validation subset). The central conclusion is that memory-architecture papers must explicitly define and report the scoring target.
Significance. If the audit and rescoring results hold, the work identifies a previously under-examined source of non-invariance in LLM memory evaluation that can silently invert benchmark conclusions. The fixed-output TIAP design is a methodological strength, enabling direct target comparison without re-execution or additional model calls. The concrete percentages and use of standard nDCG provide clear, falsifiable evidence of the effect size.
major comments (2)
- [description of the 1,902-case semantic audit] The central claim that relaxed source-linked credit is 'fully justified only 29.2 percent of the time' rests on the 1,902-case semantic audit. The manuscript states high rubric reliability only for a validation subset and supplies no information on sampling procedure for the 1,902 cases, labeling protocol (single annotator vs. multiple, adjudication rules), or overlap between the audit set and the validation subset. Without these details the 29.2% figure cannot be treated as a stable population estimate and the supporting argument for target non-invariance remains unanchored.
- [results on Mem0 and MemoryOS transfer runs] The abstract reports that target switching 'flips target orderings on Mem0 and MemoryOS transfer runs' and 'reverses parser-density recommendations,' yet the manuscript provides no table or section that lists the exact nDCG values or rank positions under each target for these specific systems. This omission makes it impossible to verify the magnitude and direction of the reported flips.
minor comments (2)
- [TIAP method] The three targets (Raw, Source, Canonical) are introduced without an explicit formal definition or pseudocode; a short table or equation block would improve reproducibility.
- [experimental setup] The manuscript does not state the total number of queries in the original LoCoMo and LongMemEval-S sets or the exact overlap size used for the 'shared queries' percentage, which would help readers assess selection bias.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable comments. Below we respond to each major comment and indicate the planned revisions to the manuscript.
read point-by-point responses
-
Referee: [description of the 1,902-case semantic audit] The central claim that relaxed source-linked credit is 'fully justified only 29.2 percent of the time' rests on the 1,902-case semantic audit. The manuscript states high rubric reliability only for a validation subset and supplies no information on sampling procedure for the 1,902 cases, labeling protocol (single annotator vs. multiple, adjudication rules), or overlap between the audit set and the validation subset. Without these details the 29.2% figure cannot be treated as a stable population estimate and the supporting argument for target non-invariance remains unanchored.
Authors: We agree that the manuscript should have included more details on the semantic audit to support the 29.2% claim. The referee is correct that without information on sampling, labeling protocol, and overlap, the figure's stability cannot be fully assessed from the text alone. We will revise the manuscript by adding a new subsection under the audit description that specifies the sampling procedure, labeling protocol (including number of annotators and any adjudication), and the overlap between the 1,902-case set and the validation subset. This will allow readers to better evaluate the result. revision: yes
-
Referee: [results on Mem0 and MemoryOS transfer runs] The abstract reports that target switching 'flips target orderings on Mem0 and MemoryOS transfer runs' and 'reverses parser-density recommendations,' yet the manuscript provides no table or section that lists the exact nDCG values or rank positions under each target for these specific systems. This omission makes it impossible to verify the magnitude and direction of the reported flips.
Authors: We acknowledge the omission noted by the referee. While the abstract and main text describe the flips in system orderings for Mem0 and MemoryOS, we did not include a table with the precise nDCG values and rank positions under each scoring target. We will add such a table to the results section in the revised manuscript to enable verification of the reported effects. revision: yes
Circularity Check
No circularity; empirical rescoring of fixed outputs under standard nDCG
full rationale
The paper applies three fixed scoring targets (Raw, Source, Canonical) to pre-existing ranked retrieval outputs via TIAP and reports nDCG changes plus a separate 1,902-case semantic audit yielding the 29.2% justification rate. These are direct, non-parametric measurements on held-fixed data; no equations, predictions, or central claims reduce by construction to fitted parameters, self-citations, or ansatzes imported from prior work. The audit is presented as an independent count rather than a derived or self-defined quantity. No load-bearing self-citation chains or uniqueness theorems appear in the abstract or described method.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math nDCG is an appropriate metric for comparing ranked retrieval outputs
Reference graph
Works this paper leans on
-
[1]
Minimal test collections for retrieval evalua- tion. InProceedings of the 29th Annual International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, pages 268–275. Howard Chen, Ramakanth Pasunuru, Jason Weston, and Asli Celikyilmaz. 2023. Walking down the mem- ory maze: Beyond context limit through interactive reading.arXiv pre...
-
[2]
Sangyeop Kim, Yohan Lee, Sanghwa Kim, Hyunjong Kim, and Sungzoon Cho
Memory OS of AI agent. Sangyeop Kim, Yohan Lee, Sanghwa Kim, Hyunjong Kim, and Sungzoon Cho. 2025. Pre-storage reason- ing for episodic memory: Shifting inference burden to memory for personalized dialogue. InFindings of the Association for Computational Linguistics: EMNLP 2025. Kuang-Huei Lee, Xinyun Chen, Hiroki Furuta, John Canny, and Ian Fischer. 2024...
-
[3]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Christopher D. Manning, Prabhakar Raghavan, and Hin- rich Schütze. 2008.Introduction to Information Re- trieval. Cambridge University Press. Kai Tzu-iunn Ong, ...
2008
-
[4]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as operating sys- tems.arXiv preprint arXiv:2310.08560. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative agents: Interactive simu- lacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–2...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8416–8439
In prospect and retrospect: Reflective mem- ory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8416–8439. Mohammad Tavakoli, Alireza Salemi, Carrie Ye, Mo- hamed Abdalla, Hamed Zamani, and J. Ross Mitchell
-
[6]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
Beyond a million tokens: Benchmarking and enhancing long-term memory in LLMs. InThe Four- teenth International Conference on Learning Repre- sentations. Nandan Thakur, Nils Reimers, Andreas Rücklé, Ab- hishek Srivastava, and Iryna Gurevych. 2021. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. InProceedings of the...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Transforms memory?Does the system or benchmark produce non-raw representa- tions, such as extracted facts, summaries, or knowledge-graph entries, from raw conversa- tion turns?
-
[8]
Reports retrieval unit?Is the scored unit formally defined?
-
[9]
Reports target mapping?Is there a docu- mented mapping from scored items to source conversation evidence?
-
[10]
Retrieval units are described at the architectural level in most papers, but only LoCoMo explicitly labels and separately evaluates distinct unit types
Specifies descendant credit?When one source turn produces multiple stored items, does the paper specify which descendants re- ceive credit? Findings.All 11 papers create transformed mem- ory representations. Retrieval units are described at the architectural level in most papers, but only LoCoMo explicitly labels and separately evaluates distinct unit typ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.