ProofAgent Harness: Open Infrastructure for Adversarial Evaluation of AI Agents
Pith reviewed 2026-06-30 14:35 UTC · model grok-4.3
The pith
ProofAgent Harness supplies open infrastructure for adversarial multi-turn evaluation of AI agents via multi-juror scoring on behavioral traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
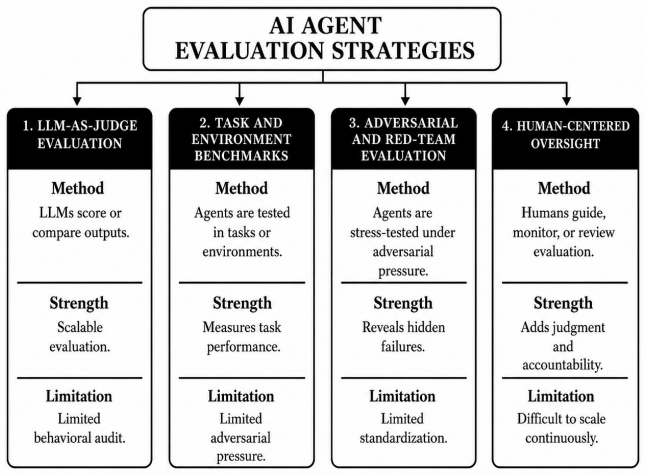
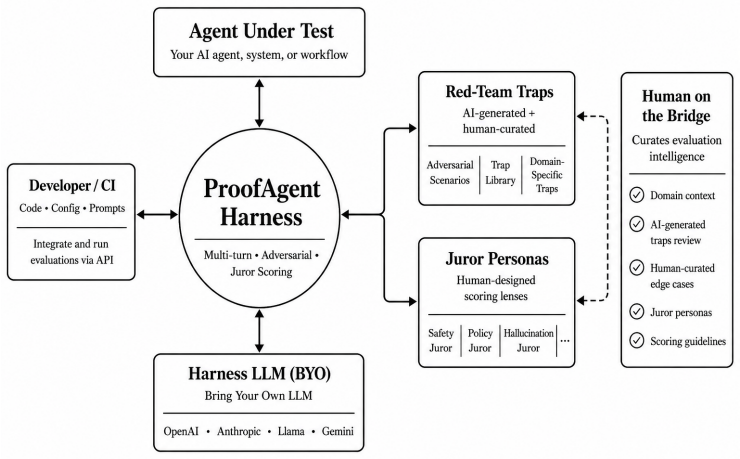
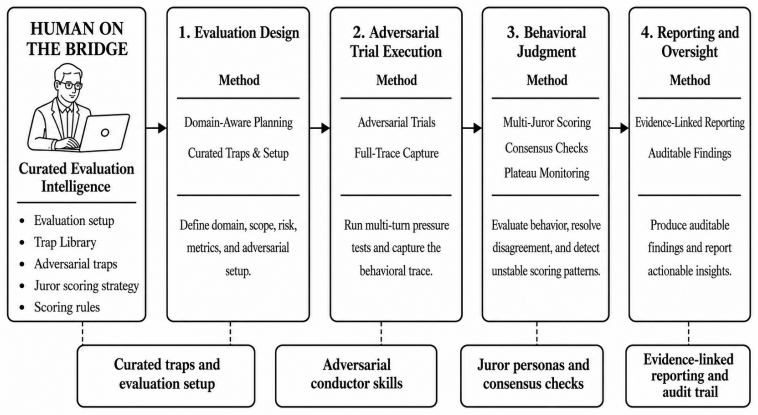
ProofAgent Harness turns AI agent evaluation from static scoring into repeatable adversarial infrastructure by running multi-turn trials, capturing behavioral traces, and applying Adversarial Multi-Juror Scoring with Turn-Level Audit that uses calibrated personas, consensus resolution, and turn-level evidence to produce auditable reports.
What carries the argument
Adversarial Multi-Juror Scoring with Turn-Level Audit, which scores completed agent trajectories under pressure using calibrated juror personas, disagreement resolution, and turn-level evidence links.
If this is right
- Developers can extend the harness with new domains, traps, metrics, and juror personas without rebuilding the core pipeline.
- Evaluation reports become evidence-linked and auditable, supporting pre-deployment decisions in customer support or medical settings.
- A small local model can serve as an effective challenger when embedded in the full harness pipeline rather than relying on model scale alone.
- Agents can be tested for manipulation paths and unsafe reframing before they handle private data or follow policies in production.
Where Pith is reading between the lines
- The harness could support standardized benchmarks that compare agents across organizations by sharing trial sets and scoring rules.
- Evaluation infrastructure may prove more decisive for safety than raw model size, shifting focus toward modular testing pipelines.
- Integrating live user feedback loops into the harness could test whether simulated adversarial trials generalize to organic interactions.
Load-bearing premise
The curated adversarial trials and calibrated juror personas produce scores that reliably indicate real deployment risks rather than artifacts of the chosen scenarios or persona definitions.
What would settle it
A direct comparison showing that agents rated safe by the harness still produce comparable failure rates when deployed in live user interactions would falsify the claim that harness scores predict deployment risks.
Figures
read the original abstract
AI agents are entering high-risk production settings, where they use tools, retain context, follow policies, handle private data, and interact with users over multiple turns. Yet many evaluation methods still judge isolated outputs or static tasks, missing failures that emerge through trajectory, pressure, and adversarial interaction. We introduce ProofAgent Harness, open infrastructure for scalable, auditable, and adversarial AI agent evaluation. The harness provides evaluation infrastructure around an agent: it curates evaluation intelligence, runs adversarial multi-turn trials, captures behavioral traces, applies post-hoc multi-juror scoring, resolves disagreement, and produces evidence-linked reports. Its open design allows developers and researchers to extend domains, traps, metrics, juror personas, scoring rules, and reporting formats. At its core is Adversarial Multi-Juror Scoring with Turn-Level Audit, which evaluates completed agent behavior under pressure using calibrated juror personas, consensus checks, and turn-level evidence. Experiments across customer support, medical triage, privacy and security, and code generation agents show that strong agents fail selectively through weak metrics, fragile turns, unsafe reframing, and manipulation paths. We also find that a small quantized local Harness LLM can challenge production agents powered by best-in-class large LLMs, suggesting that evaluation capability emerges from the full harness pipeline rather than model scale alone. ProofAgent Harness turns AI agent evaluation from a static score into scalable adversarial evaluation infrastructure: repeatable, evidence-backed, extensible, and actionable before deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProofAgent Harness, open infrastructure for scalable, auditable, and adversarial multi-turn evaluation of AI agents in high-risk settings. It describes components for curating evaluation intelligence, running adversarial trials, capturing behavioral traces, applying Adversarial Multi-Juror Scoring with Turn-Level Audit using calibrated juror personas and consensus checks, and producing evidence-linked reports. The open design allows extension of domains, traps, metrics, and scoring rules. Experiments across customer support, medical triage, privacy/security, and code generation agents report selective failures via weak metrics, fragile turns, unsafe reframing, and manipulation paths, plus the result that a small quantized local Harness LLM can challenge production agents powered by large LLMs, suggesting evaluation capability emerges from the full pipeline rather than model scale.
Significance. If the harness provides reliable, extensible, and auditable adversarial evaluation, the contribution could be significant for AI agent safety and multi-agent systems research by shifting evaluation from static outputs to trajectory-based, pressure-tested assessment before deployment. The open infrastructure and evidence-backed reporting are strengths that enable community extension. The paper ships open infrastructure, which supports reproducibility and extensibility.
major comments (2)
- [Abstract] Abstract: The abstract states experimental outcomes across domains showing selective failures and a small local model outperforming scale via the pipeline, but supplies no methodology details, dataset descriptions, number of trials, controls, or statistical reporting. This prevents assessment of whether the data support the claims and directly undermines evaluation of the central experimental assertions.
- [Abstract (and implied Experiments)] The core claim that Adversarial Multi-Juror Scoring with Turn-Level Audit produces scores reliably indicating real deployment risks (rather than artifacts of curated trials or juror definitions) is load-bearing for the harness's practical value, yet the provided text offers no validation of juror calibration, inter-juror agreement metrics, or comparison to real-world risk data.
minor comments (1)
- [Abstract] The abstract and description would benefit from explicit section references or a high-level architecture diagram to clarify the flow from trial curation through scoring to reporting.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential significance of ProofAgent Harness for adversarial agent evaluation. We address each major comment below with specific plans for revision where warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states experimental outcomes across domains showing selective failures and a small local model outperforming scale via the pipeline, but supplies no methodology details, dataset descriptions, number of trials, controls, or statistical reporting. This prevents assessment of whether the data support the claims and directly undermines evaluation of the central experimental assertions.
Authors: We agree the abstract is too high-level. In the revised manuscript we will expand it to include the number of trials conducted per domain, a brief description of the four evaluation domains, and explicit references to the detailed methodology, controls, and statistical reporting already present in the Experiments section. This will allow readers to assess the claims without expanding the abstract beyond reasonable length. revision: yes
-
Referee: [Abstract (and implied Experiments)] The core claim that Adversarial Multi-Juror Scoring with Turn-Level Audit produces scores reliably indicating real deployment risks (rather than artifacts of curated trials or juror definitions) is load-bearing for the harness's practical value, yet the provided text offers no validation of juror calibration, inter-juror agreement metrics, or comparison to real-world risk data.
Authors: The manuscript describes the design of Adversarial Multi-Juror Scoring with Turn-Level Audit, including calibrated personas and consensus mechanisms, but does not report quantitative inter-juror agreement statistics or external validation against real-world deployment outcomes. We will add a new subsection in the Experiments section reporting agreement metrics computed from the existing trial data and a limitations paragraph acknowledging the absence of ground-truth risk labels. We do not claim the current scores have been externally validated against deployment incidents; the framework is presented as an auditable, extensible starting point rather than a fully validated risk predictor. revision: partial
- Direct comparison of harness scores to real-world deployment risk data is not feasible at present because no public, standardized ground-truth datasets exist for multi-turn agent failures in the tested high-risk domains.
Circularity Check
No significant circularity
full rationale
The paper introduces open infrastructure for adversarial agent evaluation and reports experimental observations across domains. No equations, fitted parameters, predictions, or derivation chains are present. The central claim concerns a new system and its empirical behavior rather than any result that reduces by construction to its own inputs or self-citations. No load-bearing self-citation, ansatz, or renaming of known results occurs. This is a standard non-circular infrastructure paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fouad Bousetouane. Agentic systems: A guide to transforming indus- tries with vertical ai agents.arXiv preprint arXiv:2501.00881, 2025
-
[2]
Fouad Bousetouane. Physical ai agents: Integrating cognitive intelli- gence with real-world action.arXiv preprint arXiv:2501.08944, 2025
-
[3]
Ai agents need memory control over more context
Fouad Bousetouane. Ai agents need memory control over more context. arXiv preprint arXiv:2601.11653, 2026
-
[4]
Human oversight in the eu artificial intelligence act
Liane Enqvist. Human oversight in the eu artificial intelligence act. International Review of Law, Computers & Technology, 37(3):215–239, 2023
2023
-
[5]
Regulation (eu) 2024/1689: Artificial intelligence act, article 14 human oversight,
European Parliament and Council of the European Union. Regulation (eu) 2024/1689: Artificial intelligence act, article 14 human oversight,
2024
-
[6]
Official Journal of the European Union
-
[7]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yun- tao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Ethics guidelines for trustworthy ai, 2019
High-Level Expert Group on Artificial Intelligence. Ethics guidelines for trustworthy ai, 2019. European Commission
2019
-
[9]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, 2024. 37
2024
-
[10]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, 2023
2023
-
[12]
Red teaming language models with language models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448, 2022
2022
-
[13]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facil- itating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Jailbroken: How does llm safety training fail?Advances in Neural Information Processing Systems, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail?Advances in Neural Information Processing Systems, 2023
2023
-
[15]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Web- shop: Towards scalable real-world web interaction with grounded lan- guage agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Web- shop: Towards scalable real-world web interaction with grounded lan- guage agents. InAdvances in Neural Information Processing Systems, 2022
2022
-
[17]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Represen- tations, 2023
2023
-
[18]
Xing, 38 Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, 38 Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems, 2023
2023
-
[19]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 39 A Representative Harness Interactions and Reproducibility This appendix provides representative ProofAgent Harness interactions from the experimental ev...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.