Resident KV Claims: A Conformance Contract for Future Reuse under Active KV Pressure
Pith reviewed 2026-06-30 14:15 UTC · model grok-4.3
The pith
Resident KV claims bind future-reuse intent to a materialization predicate and convert unreported resident loss into scheduler-visible active refusal with direct attribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
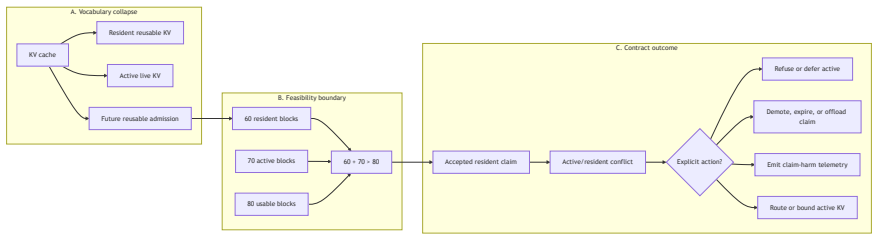
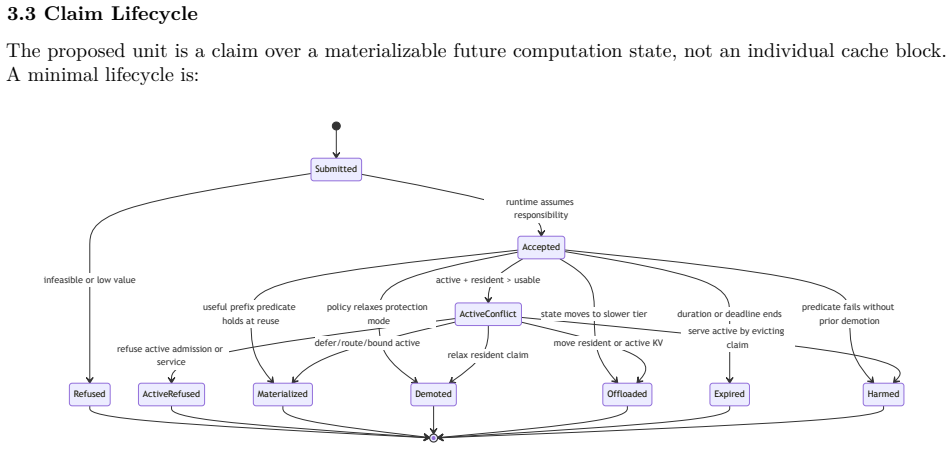
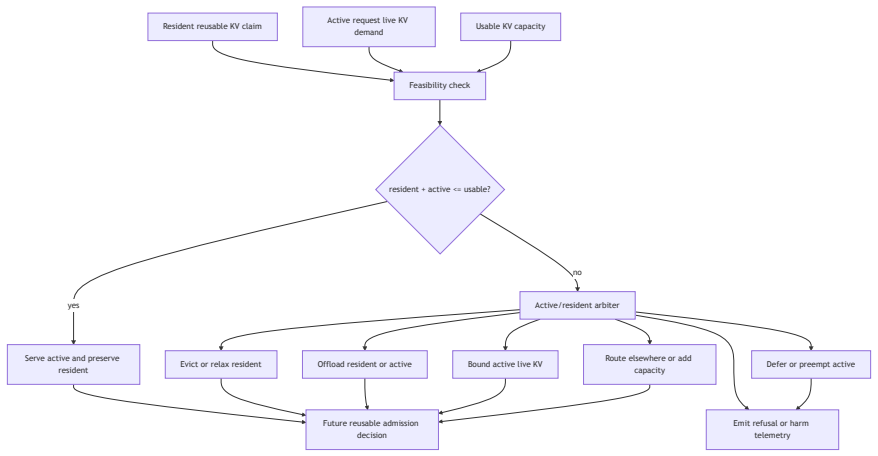
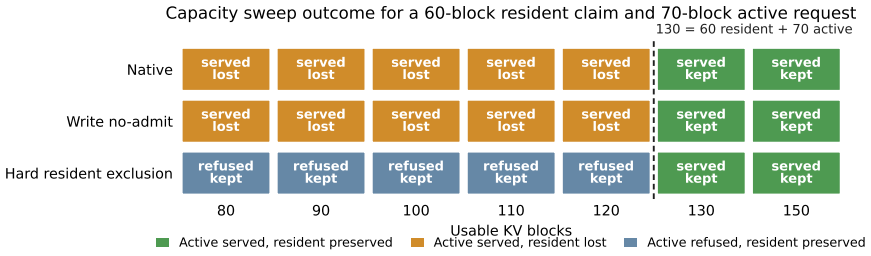
Resident KV claims are a conformance contract that binds future-reuse intent to a materialization predicate, lifecycle state, active/resident feasibility outcome, and claim-level telemetry. In controlled vLLM allocator probes where a 60-block resident claim and a 70-block active prefill exceed an 80-block usable KV pool, hard protected claims turn the prior failure mode of active allocation evicting residents into scheduler-visible active refusal with direct blocking-claim attribution. The result supplies a runtime contract that makes ordinary eviction, soft priority, write no-admit, accepted hard claims, materialization failure, demotion, expiry, and active refusal distinguishable and recon
What carries the argument
The resident KV claim, a conformance contract attaching future-reuse intent to materialization predicate, lifecycle state, feasibility outcome, and telemetry so that active/resident conflicts produce explicit, attributable scheduler outcomes.
If this is right
- Write no-admit still permits active allocation to evict residents from the shared pool.
- Hard protected resident claims produce scheduler-visible active refusal instead of silent loss.
- Claim-level telemetry and the litmus suite allow reconstruction of which distinct outcome occurred.
- The contract distinguishes ordinary eviction, soft priority, write no-admit, materialization failure, demotion, expiry, and active refusal.
Where Pith is reading between the lines
- Schedulers could use the new refusal signals to prioritize or queue requests differently when resident claims are present.
- The same contract structure could be applied to other shared memory pools that mix reusable and live allocations.
- Portable implementation would require allocator interfaces to expose the materialization predicate and telemetry without allocator-specific extensions.
Load-bearing premise
The materialization predicate, lifecycle state, and claim-level telemetry can be implemented portably across allocators without introducing new failure modes or significant overhead.
What would settle it
Execute the vLLM litmus suite on an 80-block KV pool with a 60-block hard resident claim and 70-block active prefill; the claim is falsified if the active request is admitted and evicts the resident without producing a scheduler-visible refusal or blocking-claim attribution.
Figures
read the original abstract
KV-cache reuse mechanisms increasingly expose priority, duration, offload, routing hints, scheduler modes, and event streams. These mechanisms help preserve reusable prefixes, but they do not by themselves define a portable contract for accepted future-reuse state when resident KV and active live KV cannot both fit. We introduce resident KV claims, a conformance contract that binds future-reuse intent to a materialization predicate, lifecycle state, active/resident feasibility outcome, and claim-level telemetry. In controlled vLLM allocator probes, a 60-block resident claim and a 70-block active prefill exceed an 80-block usable KV pool. Write no-admit prevents the active request from becoming future reusable state, but it still allows active allocation to evict residents from the shared pool. A minimal vLLM prototype shows that hard protected resident claims convert this failure mode into scheduler-visible active refusal with direct blocking-claim attribution. The result is not a production speedup or a new cache-replacement algorithm. It is a runtime contract that turns unreported resident loss into reconstructable active/resident arbitration. A companion MicroRuntime and vLLM litmus suite distinguish ordinary eviction, soft priority, write no-admit, accepted hard claims, materialization failure, demotion, expiry, active refusal, and trace-level outcome reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes resident KV claims as a conformance contract for future KV-cache reuse under active pressure in systems such as vLLM. The contract includes a materialization predicate, lifecycle state, active/resident feasibility outcome, and claim-level telemetry. Using controlled probes in a minimal vLLM prototype, it demonstrates that hard protected resident claims transform a write-no-admit eviction scenario involving a 60-block resident claim and 70-block active prefill in an 80-block pool into a scheduler-visible active refusal with blocking-claim attribution. The work also introduces a MicroRuntime and vLLM litmus suite to distinguish between various outcomes including ordinary eviction, soft priority, write no-admit, accepted hard claims, materialization failure, demotion, expiry, active refusal, and trace-level outcome reconstruction. The contribution is explicitly scoped as a runtime contract rather than a production algorithm.
Significance. If the central claim holds, the resident KV claims contract would provide a structured, portable mechanism to handle conflicts between resident and active KV under memory pressure, converting unreported resident loss into explicit, reconstructable arbitration. This addresses limitations in existing KV-cache reuse mechanisms that provide various hints but lack a defined conformance contract for accepted future-reuse state. The prototype offers concrete evidence in one allocator, and the litmus suite supports verification of different scenarios. A strength is the clear scoping of the result and the focus on making failure modes distinguishable.
major comments (1)
- [Abstract] Abstract: The abstract claims that the minimal vLLM prototype shows conversion of the failure mode to scheduler-visible refusal, but supplies no quantitative data, error bars, or details of the experimental setup and number of probes, which undermines the ability to assess the reliability and generality of this outcome for the central claim.
minor comments (2)
- [Abstract] The example numbers (60-block, 70-block, 80-block) are given without specifying the units or the exact configuration of the usable KV pool, which could be clarified for readers.
- The manuscript would benefit from a dedicated section describing the implementation of the hard protected claims in the prototype to allow replication.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of major revision. The single major comment is addressed below. We agree that the abstract requires additional detail on the experimental probes to strengthen the presentation of the conformance contract demonstration.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract claims that the minimal vLLM prototype shows conversion of the failure mode to scheduler-visible refusal, but supplies no quantitative data, error bars, or details of the experimental setup and number of probes, which undermines the ability to assess the reliability and generality of this outcome for the central claim.
Authors: We agree the abstract would benefit from explicit details on the probe setup. The reported outcome uses deterministic, controlled allocator probes in the minimal vLLM prototype (with the MicroRuntime) to exercise the resident KV claim contract under the specific 60-block resident / 70-block active / 80-block pool configuration. Because the tests are designed to produce a single, reproducible outcome for each litmus case rather than statistical measurements, error bars do not apply. We will revise the abstract to state the number of probes executed for the reported scenario and to briefly characterize the MicroRuntime environment. The litmus suite itself provides the mechanism for assessing generality across the enumerated outcome categories (ordinary eviction, write-no-admit, active refusal, etc.). This change will be made in the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes a conformance contract definition (resident KV claims) with associated states and telemetry, then reports behavior observed in a minimal vLLM prototype. No equations, fitted parameters, or derivation steps appear in the provided text. The central claim is scoped to the contract's ability to make certain failure modes scheduler-visible; this is presented as a definitional and observational result rather than a reduction of any output to prior fitted inputs or self-citation chains. The work is self-contained against external benchmarks with no load-bearing self-references or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption KV-cache reuse mechanisms expose priority, duration, offload, routing hints, scheduler modes, and event streams that can be extended with a conformance contract
invented entities (1)
-
resident KV claim
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon et al., “Efficient Memory Management for Large Language Model Serving with PagedAt- tention,” arXiv, https://arxiv.org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
vLLM prefix caching documentation, https://docs.vllm.ai/en/v0.17.0/design/prefix_caching/
-
[3]
[RFC]: Context-Aware KV-Cache Retention API (Prioritized Evictions),
vLLM issue “[RFC]: Context-Aware KV-Cache Retention API (Prioritized Evictions),” https://github.c om/vllm-project/vllm/issues/37003
-
[4]
Introducing New KV Cache Reuse Optimizations in NVIDIA TensorRT-LLM,
NVIDIA Developer Blog, “Introducing New KV Cache Reuse Optimizations in NVIDIA TensorRT-LLM,” https://developer.nvidia.com/blog/introducing-new-kv-cache-reuse-optimizations-in-nvidia-tensorrt-llm/
-
[5]
TensorRT-LLM KV cache documentation, https://nvidia.github.io/TensorRT-LLM/features/kvcache.h tml
-
[6]
TensorRT-LLM useful runtime flags documentation, https://nvidia.github.io/TensorRT-LLM/performa nce/performance-tuning-guide/useful-runtime-flags.html
-
[7]
SGLang HiCache design documentation, https://docs.sglang.io/docs/advanced_features/hicache_desi gn
-
[8]
SGLang server arguments documentation, https://docs.sglang.io/docs/advanced_features/server_arg uments
-
[9]
NVIDIA Dynamo agentic workflow documentation, https://docs.nvidia.com/dynamo/dev/user-guides/a gents
-
[10]
NVIDIA Dynamo SGLang agentic workload documentation, https://docs.nvidia.com/dynamo/dev/bac kends/sg-lang/agentic-workloads
-
[11]
Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live
H. Li et al., “Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live,” arXiv, https://arxiv.org/abs/2511.02230
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
InInternational Conference on Learning Representations, volume 2024, pages 39578–39601
Z. Pan et al., “KVFlow: Efficient Prefix Caching for Accelerating LLM-Based Multi-Agent Workflows,” arXiv, https://arxiv.org/abs/2507.07400
-
[13]
Pie: A Programmable Serving System for Emerging LLM Applications,
In Gim et al., “Pie: A Programmable Serving System for Emerging LLM Applications,” SOSP 2025 / arXiv, https://arxiv.org/abs/2510.24051
-
[14]
Marconi: Prefix Caching for the Era of Hybrid LLMs,
Rui Pan et al., “Marconi: Prefix Caching for the Era of Hybrid LLMs,” Proceedings of Machine Learning and Systems 7 (MLSys 2025), https://proceedings.mlsys.org/paper_files/paper/2025/hash/7c180af017258d 239bac6248d1eb26ac-Abstract-Conference.html . 18
2025
-
[15]
vLLM x Mooncake: KV Cache-Centric Disaggregated Architecture for LLM Serv- ing,
vLLM project blog, “vLLM x Mooncake: KV Cache-Centric Disaggregated Architecture for LLM Serv- ing,” https://vllm.ai/blog/2026-05-06-mooncake-store . Appendix A: Reproducibility Inventory This inventory records the public, commit-pinned artifacts used by the manuscript. Claims in the paper are tied to the public repositories, generated artifact files, and...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.