Me, Myself, and My Voice: Exploring Cultural and Linguistic Identity in AAC AI-generated Voices
Pith reviewed 2026-06-30 13:01 UTC · model grok-4.3
The pith
AAC users experience deeper identity alignment from culturally matched AI voices than from accent or language matching alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The study demonstrates that for people using AAC systems, a voice that aligns with their cultural identity extends beyond reproducing accent or language; it engages with feelings of belonging, self-recognition, and the experience of being heard as one's authentic self, as revealed through participant responses to personalized voice candidates.
What carries the argument
A custom tool that elicits cultural markers through guided questions and generates personalized AI-generated voice candidates for participants to evaluate.
If this is right
- Non-binary, transgender, and non-US-born AAC users rate their current voice support for identity alignment lower than other groups.
- Voices designed with cultural markers lead to reflections on personal identity and agency during interviews.
- Current AI voice technologies do not fully address the cultural aspects of voice identity for AAC users.
- Accessible methods for users to specify cultural voice preferences can improve representation in speech-generating devices.
Where Pith is reading between the lines
- Designers of assistive voice technologies might benefit from incorporating similar elicitation methods to better serve diverse users.
- Testing these voices in real-world social settings could reveal impacts on communication effectiveness and social inclusion.
- Similar approaches could apply to voice design for other groups with identity-related communication needs.
Load-bearing premise
The guided questions accurately identify cultural markers that will be perceived by users as representative when translated into generated voices.
What would settle it
If participants in a controlled test rate the tool-generated voices as no more culturally aligned than voices matched only by accent or randomly selected, the finding that cultural alignment runs deeper would be challenged.
Figures

read the original abstract
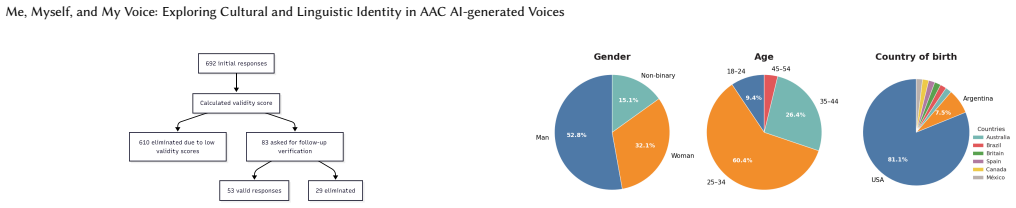
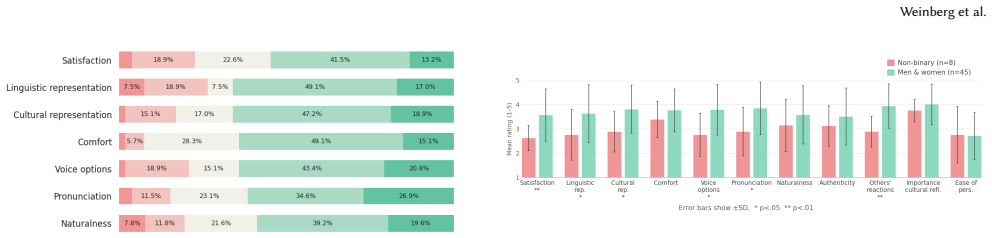
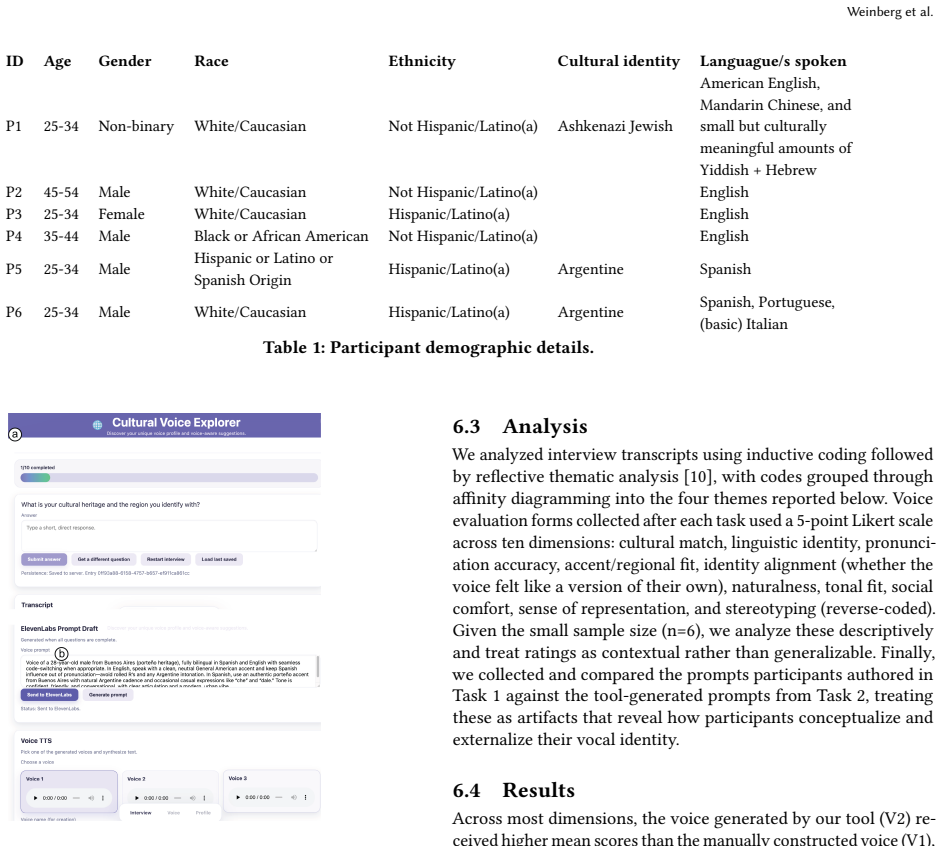
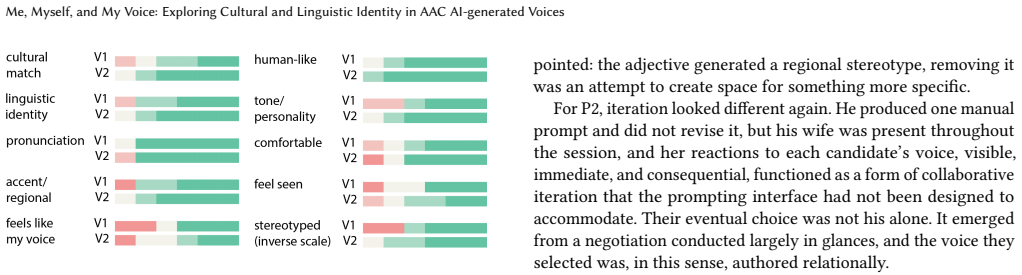
Voice is a central element of identity. We recognize people by their voice, and we uniquely express who we are with it. For people who rely on augmentative and alternative communication~(AAC) systems, such as speech-generating devices~(SGD), the device's voice becomes an identity marker others associate with them. Yet, it is hard to find a voice that truly aligns with one's identity both linguistically and culturally. Although modern AI-generated voices can reproduce diverse accents and speaking styles, AAC users still lack accessible ways to articulate how they want an identity-aligned voice to sound like. We first conducted a survey of AAC users (across eight countries) to characterize current voice representation, finding that non-binary, transgender, and non-US-born respondents rated their current voice support identity alignment consistently lower than other respondents. To examine how AAC users respond to voices designed to reflect their cultural identity, we built a tool that elicits cultural markers through guided questions and generates personalized voice candidates for participants to hear and reflect on. After participants heard the voices, we interviewed them to examine what it means for a voice to feel culturally representative, how they interpreted voices with cultural connotations, and how these voices shaped their sense of identity and agency. Our findings show that cultural voice alignment runs deeper than accent or language alone; it touches on belonging, self-recognition, and what it means to be heard as who you are.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a survey of AAC users across eight countries showing lower identity alignment ratings for non-binary, transgender, and non-US-born respondents compared to others. It describes development of a custom tool that elicits cultural markers through guided questions to produce personalized AI-generated voice candidates. Interviews with participants who heard these voices then explore perceptions of cultural representation, leading to the claim that cultural voice alignment extends beyond accent or language to include belonging, self-recognition, and agency.
Significance. If substantiated, the work makes a meaningful contribution to HCI and accessibility research by shifting focus from technical voice synthesis to sociocultural dimensions of identity in AAC systems. The mixed-methods design, combining a multi-country survey with targeted interviews, offers user-centered insights that could guide more inclusive voice design practices. The custom tool represents an innovative attempt to bridge user input with generative AI, though its effectiveness requires further substantiation.
major comments (2)
- [Tool Development and Voice Generation (Methods)] The interview-based findings on belonging and self-recognition rest on the unvalidated assumption that the custom tool's guided questions produce voices that faithfully render the elicited cultural markers. The manuscript provides no pilot testing, expert review, or fidelity assessment (e.g., quantitative comparison of input markers to output voice parameters or user perception checks) to confirm this mapping. This is load-bearing for the central claim, as interview themes could instead reflect reactions to generation artifacts.
- [Survey Results] Survey results on group differences in identity alignment ratings lack reported sample sizes, recruitment details, response rates, or the specific statistical tests and effect sizes used for comparisons. These omissions undermine evaluation of whether the reported disparities are robust enough to support the subsequent design of the tool and interviews.
minor comments (2)
- [Abstract] The abstract would benefit from including participant numbers for both the survey and interviews to provide immediate context for the scale of the study.
- [Interview Analysis (Methods)] Interview analysis methods (e.g., thematic analysis approach, coding process, or inter-rater reliability if applicable) are not described, which affects transparency of how themes on cultural representation were derived.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. We have carefully considered each point and provide point-by-point responses below, noting revisions where appropriate.
read point-by-point responses
-
Referee: [Tool Development and Voice Generation (Methods)] The interview-based findings on belonging and self-recognition rest on the unvalidated assumption that the custom tool's guided questions produce voices that faithfully render the elicited cultural markers. The manuscript provides no pilot testing, expert review, or fidelity assessment (e.g., quantitative comparison of input markers to output voice parameters or user perception checks) to confirm this mapping. This is load-bearing for the central claim, as interview themes could instead reflect reactions to generation artifacts.
Authors: We acknowledge that the manuscript does not report formal pilot testing, expert review, or quantitative fidelity assessments of the custom tool. As an exploratory study, the tool was designed iteratively to facilitate user reflection on cultural identity in voice generation, and the interview data captures participants' subjective perceptions of the generated voices. However, we agree that this assumption is important to address. In revision, we will expand the Methods section to detail the tool's development process, including how questions were derived from the survey findings and any informal validation steps taken during interviews. We will also add a limitations subsection explicitly noting the absence of formal fidelity checks and discussing how this affects interpretation of the findings. This represents a partial revision as we cannot retroactively add new empirical validation data. revision: partial
-
Referee: [Survey Results] Survey results on group differences in identity alignment ratings lack reported sample sizes, recruitment details, response rates, or the specific statistical tests and effect sizes used for comparisons. These omissions undermine evaluation of whether the reported disparities are robust enough to support the subsequent design of the tool and interviews.
Authors: We apologize for the omission of these methodological details in the submitted manuscript. The survey involved AAC users recruited through international organizations and online communities in eight countries. We will revise the manuscript to include the exact sample size, detailed recruitment procedures, response rates, and a full description of the statistical methods, including the tests applied for group comparisons and associated effect sizes. This will strengthen the transparency and allow better evaluation of the survey findings. revision: yes
Circularity Check
No significant circularity; empirical findings from survey and interviews stand independently
full rationale
The paper reports results from a survey of AAC users and subsequent interviews after exposure to a custom tool that generates voice candidates. No equations, fitted parameters, derivations, or self-citations appear in the load-bearing claims. The central findings (cultural alignment involving belonging and self-recognition) are presented as emerging from participant reflections on the generated voices rather than being defined into existence or forced by prior self-referential results. The absence of validation for the tool's mapping is a potential correctness issue but does not constitute circularity under the specified patterns, as the work does not reduce any prediction or claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-reported feelings from interviews reliably reflect users' sense of cultural identity alignment with voices.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. https://www.sciencedirect.com/topics/social-sciences/linguistic-identity
- [2]
-
[3]
Dhruv Agarwal, Mor Naaman, and Aditya Vashistha. 2025. AI suggestions homogenize writing toward western styles and diminish cultural nuances. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–21
2025
-
[4]
Seyedeh Zahra Asghari, Sajjad Farashi, Saeid Bashirian, and Ensiyeh Jenabi
-
[5]
Distinctive prosodic features of people with autism spectrum disorder: a systematic review and meta-analysis study.Scientific reports11, 1 (2021), 23093
2021
-
[6]
Susan Baxter, Pam Enderby, Philippa Evans, and Simon Judge. 2012. Bar- riers and facilitators to the use of high-technology augmentative and alter- native communication devices: a systematic review and qualitative synthe- sis. 47, 2 (2012), 115–129. doi:10.1111/j.1460-6984.2011.00090.x _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1460-6984.2...
-
[7]
Susan Baxter, Pam Enderby, Philippa Evans, and Simon Judge. 2012. Barriers and facilitators to the use of high-technology augmentative and alternative com- munication devices: a systematic review and qualitative synthesis.International Journal of Language & Communication Disorders47, 2 (2012), 115–129
2012
-
[8]
Su Lin Blodgett, Solon Barocas, Hal Daumé Iii, and Hanna Wallach. 2020. Lan- guage (technology) is power: A critical survey of “bias” in NLP. InProceedings of the 58th annual meeting of the association for computational linguistics. 5454–5476
2020
-
[9]
James Bonnamy, Bethany Carr, Michelle D Lazarus, and Clifford Connell. 2025. Survey sabotage: Insights into reducing the risk of fraudulent responses in online surveys.Anatomical sciences education18, 8 (2025), 767–773
2025
-
[10]
Richard Cave and Steven Bloch. 2021. Voice banking for people living with motor neurone disease: Views and expectations.International Journal of Language & Communication Disorders56, 1 (2021), 116–129
2021
-
[11]
Victoria Clarke and Virginia Braun. 2017. Thematic analysis.The journal of positive psychology12, 3 (2017), 297–298
2017
-
[12]
Humphrey Curtis, Ying Hei Lau, and Timothy Neate. 2024. Breaking Badge: Augmenting Communication with Wearable AAC Smartbadges and Displays. In Proceedings of the CHI Conference on Human Factors in Computing Systems. 1–25
2024
-
[13]
Humphrey Curtis, Timothy Neate, and Carlota Vazquez Gonzalez. 2022. State of the art in AAC: A systematic review and taxonomy. InProceedings of the 24th International ACM SIGACCESS Conference on Computers and Accessibility. 1–22
2022
-
[14]
Andreea Danielescu, Sharone A Horowit-Hendler, Alexandria Pabst, Ken- neth Michael Stewart, Eric M Gallo, and Matthew Peter Aylett. 2023. Creating inclusive voices for the 21st century: A non-binary text-to-speech for conversa- tional assistants. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–17
2023
-
[15]
Stephanie Feyne. 2015. Typology of interpreter-mediated discourse that affects perceptions of the identity of Deaf professionals. InSigned language interpretation and translation research: Selected papers from the first international symposium. 49–70
2015
-
[16]
Power Users
Kate Glazko, JunHyeok Cha, Aaleyah Lewis, Ben Kosa, Brianna L Wimer, Andrew Zheng, Yiwei Zheng, and Jennifer Mankoff. 2025. Autoethnographic Insights from Neurodivergent GAI “Power Users”. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–19
2025
-
[17]
Tom Griffiths, Katherine Broomfield, Laura Hrastelj, Simon Judge, and Jonathan Toogood. 2025. AI, communication aids and the challenge of authentic authorship–Whose line is it anyway‽.Journal of Enabling Technologies19, 2 (2025), 102–112
2025
-
[18]
Tom Griffiths, Rohan Slaughter, and Annalu Waller. 2024. Use of artificial intelli- gence (AI) in augmentative and alternative communication (AAC): community consultation on risks, benefits and the need for a code of practice.Journal of Enabling Technologies18, 4 (2024), 232–247
2024
-
[19]
DJ Higginbotham, Katrina Fulcher, and Jennifer Seale. 2016. Time and timing in interactions involving individuals with ALS, their unimpaired partners and their speech generating devices.The silent partner(2016), 199–229
2016
-
[20]
D Jeffery Higginbotham and David P Wilkins. 2013. Slipping through the timestream: Social issues of time and timing in augmented interactions. In Constructing (in) competence. Psychology Press, 49–82
2013
- [21]
-
[22]
Kathryn Irish and Jessica Saba. 2023. Bots are the new fraud: A post-hoc explo- ration of statistical methods to identify bot-generated responses in a corrupt data set.Personality and Individual Differences213 (2023), 112289
2023
-
[23]
I Don’t Trust it, but I Use it
Jazette Johnson, Aaleyah Lewis, Jennifer Mankoff, and Olivia Banner. 2026. “I Don’t Trust it, but I Use it”: Navigating Trust, Privacy, and Identity in Disabled People’s Use of Generative AI. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–17
2026
-
[24]
Simon Judge and Gillian Townend. 2013. Perceptions of the design of voice output communication aids.International Journal of Language & Communication Disorders48, 4 (2013), 366–381
2013
-
[25]
Kowe Kadoma, Priyal Shrivastava, and Mor Naaman. 2026. Lost in Transcription: Subtitle Errors in Automatic Speech Recognition Reduce Speaker and Content Evaluations. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–11
2026
-
[26]
At times avuncular and cantankerous, with the reflexes of a mongoose
Shaun K Kane, Meredith Ringel Morris, Ann Paradiso, and Jon Campbell. 2017. " At times avuncular and cantankerous, with the reflexes of a mongoose" Under- standing Self-Expression through Augmentative and Alternative Communication Devices. InProceedings of the 2017 acm conference on computer supported cooper- ative work and social computing. 1166–1179
2017
-
[27]
Allison Koenecke, Andrew Nam, Emily Lake, Joe Nudell, Minnie Quartey, Zion Mengesha, Connor Toups, John R Rickford, Dan Jurafsky, and Sharad Goel. 2020. Racial disparities in automated speech recognition.Proceedings of the national academy of sciences117, 14 (2020), 7684–7689
2020
-
[28]
Joanne McCann and Sue Peppé. 2003. Prosody in autism spectrum disorders: a critical review.International Journal of Language & Communication Disorders38, 4 (2003), 325–350
2003
-
[29]
It’s not a representation of me
Shira Michel, Sufi Kaur, Sarah Elizabeth Gillespie, Jeffrey Gleason, Christo Wilson, and Avijit Ghosh. 2025. “It’s not a representation of me”: Examining Accent Bias and Digital Exclusion in Synthetic AI Voice Services. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). Association for Computing Machinery, ...
-
[30]
Timothy Bunnell, and Rupal Patel
Timothy Mills, H. Timothy Bunnell, and Rupal Patel. 2014. Towards Per- sonalized Speech Synthesis for Augmentative and Alternative Communica- tion. 30, 3 (2014), 226–236. doi:10.3109/07434618.2014.924026 _eprint: https://doi.org/10.3109/07434618.2014.924026
-
[31]
Jemina Napier, Robert Skinner, Alys Young, and Rosemary Oram. 2020. Mediating identities: Sign language interpreter perceptions on trust and representation. Journal of Applied Linguistics and Professional Practice14, 1 (2020), 75–95
2020
-
[32]
Esther Nathanson. 2017. Native voice, self-concept and the moral case for personalized voice technology.Disability and rehabilitation39, 1 (2017), 73–81
2017
-
[33]
Camille Noufi, Lloyd May, and Jonathan Berger. 2023. Context, Perception, Production: A Model of Vocal Persona.PsyArXiv. July28 (2023)
2023
-
[34]
Camille Noufi, Lloyd May, and Jonathan Berger. 2023. The role of vocal persona in natural and synthesized speech. In2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 1–4
2023
-
[35]
Jennifer S Pardo. 2012. Reflections on phonetic convergence: Speech perception does not mirror speech production.Language and Linguistics Compass6, 12 (2012), 753–767
2012
-
[36]
Bryony Payne, Nadine Lavan, Sarah Knight, and Carolyn McGettigan. 2021. Perceptual prioritization of self-associated voices. 112, 3 (2021), 585–610. doi:10.1111/bjop.12479 _eprint: https://bpspsychub.onlinelibrary.wiley.com/doi/pdf/10.1111/bjop.12479
-
[37]
Mahika Phutane and Aditya Vashistha. 2025. Disability Across Cultures: A Human-Centered Audit of Ableism in Western and Indic LLMs. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 8. 2000–2014
2025
-
[38]
Jamie Preece, Emma Sullivan, Fin Tams-Gray, and Graham Pullin. 2024. Making my voice and owning its future.Medical Humanities(2024)
2024
-
[39]
Graham Pullin and Shannon Hennig. 2015. 17 ways to say yes: Toward nuanced tone of voice in AAC and speech technology.Augmentative and Alternative Communication31, 2 (2015), 170–180
2015
-
[40]
Graham Pullin, Jutta Treviranus, Rupal Patel, and Jeff Higginbotham. 2017. De- signing interaction, voice, and inclusion in AAC research.Augmentative and Alternative Communication33, 3 (2017), 139–148
2017
-
[41]
Camryn Terblanche, Tyler T Schnoor, Michal Harty, and Benjamin V Tucker. 2025. The development of synthetic child speech in three South African languages. Augmentative and Alternative Communication41, 4 (2025), 333–344. Weinberg et al
2025
-
[42]
Camryn Claire Terblanche, Michelle Pascoe, and Michal Harty. 2025. Do you like my voice? Stakeholder perspectives about the acceptability of synthetic child voices in three South African languages. 60, 1 (2025), e13152. doi:10.1111/ 1460-6984.13152 _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/1460- 6984.13152
-
[43]
Camryn Claire Terblanche, Michelle Pascoe, and Michal Harty. 2025. Do you like my voice? Stakeholder perspectives about the acceptability of synthetic child voices in three South African languages.International Journal of Language & Communication Disorders60, 1 (2025), e13152
2025
-
[44]
Stephanie Valencia, Richard Cave, Krystal Kallarackal, Katie Seaver, Michael Terry, and Shaun K. Kane. 2023. “The less I type, the better”: How AI Language Models can Enhance or Impede Communication for AAC Users. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg Germany, 2023-04-19). ACM, 1–14. doi:10.1145/3544548.3581560
-
[45]
Stephanie Valencia, Jessica Huynh, Emma Y Jiang, Yufei Wu, Teresa Wan, Zixuan Zheng, Henny Admoni, Jeffrey P Bigham, and Amy Pavel. 2024. COMPA: Using Conversation Context to Achieve Common Ground in AAC. InProceedings of the CHI Conference on Human Factors in Computing Systems. 1–18
2024
-
[46]
Stephanie Valencia, Amy Pavel, Jared Santa Maria, Seunga Yu, Jeffrey P Bigham, and Henny Admoni. 2020. Conversational agency in augmentative and alterna- tive communication. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems. 1–12
2020
-
[47]
Christophe Veaux, Junichi Yamagishi, and Simon King. 2011. Voice banking and voice reconstruction for MND patients. InThe proceedings of the 13th international ACM SIGACCESS conference on Computers and accessibility. 305–306
2011
-
[48]
Christophe Veaux, Junichi Yamagishi, and Simon King. 2013. Towards person- alised synthesised voices for individuals with vocal disabilities: Voice banking and reconstruction. InProceedings of the fourth workshop on speech and language processing for assistive technologies. 107–111
2013
- [49]
- [50]
-
[51]
Tobias M Weinberg, Kowe Kadoma, Ricardo E Gonzalez Penuela, Stephanie Valencia, and Thijs Roumen. 2025. Why So Serious? Exploring Timely Humorous Comments in AAC Through AI-Powered Interfaces. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–19
2025
-
[52]
Mary Wickenden. 2011. Whose Voice is That?: Issues of Identity, Voice and Rep- resentation Arising in an Ethnographic Study of the Lives of Disabled Teenagers who use Augmentative and Alternative Communication (AAC). 31, 4 (2011). doi:10.18061/dsq.v31i4.1724
-
[53]
Junichi Yamagishi, Christophe Veaux, Simon King, and Steve Renals. 2012. Speech synthesis technologies for individuals with vocal disabilities: Voice banking and reconstruction.Acoustical Science and Technology33, 1 (2012), 1–5
2012
-
[54]
Alys Young, Rosemary Oram, and Jemina Napier. 2019. Hearing people perceiving deaf people through sign language interpreters at work: on the loss of self through interpreted communication.Journal of Applied Communication Research47, 1 (2019), 90–110
2019
-
[55]
question
J Diego Zamfirescu-Pereira, Richmond Y Wong, Bjoern Hartmann, and Qian Yang. 2023. Why Johnny can’t prompt: how non-AI experts try (and fail) to design LLM prompts. InProceedings of the 2023 CHI conference on human factors in computing systems. 1–21. A Appendix:Survey Instrument (Study 1): Part 1: Demographics •What country were you born in? [open text] •...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.