Rethinking Continual Learning for Speech and Audio: A Representation-Centric Taxonomy and Open Problems
Pith reviewed 2026-06-30 00:11 UTC · model grok-4.3
The pith
Continual learning for speech and audio is fundamentally about preserving and evolving shared representation structure rather than retaining isolated task knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Modern speech foundation models use highly entangled, continuous representations that jointly encode linguistic, speaker, and paralinguistic factors in a shared latent space. Continual learning is therefore about preserving and evolving this shared representation structure rather than retaining isolated task knowledge. The paper introduces a taxonomy that organizes CL methods according to how underlying representation geometry evolves under non-stationary acoustic conditions, identifies key mismatches with current assumptions, and outlines open challenges.
What carries the argument
A representation-centric taxonomy that organizes continual learning according to how underlying representation geometry evolves under non-stationary acoustic conditions.
If this is right
- CL methods must shift focus from task-isolated retention to shared representation structure preservation.
- The new taxonomy classifies existing and future methods by how representation geometry changes.
- Standard CL assumptions conflict with the entangled latent spaces of speech foundation models.
- Several open challenges arise for research once the representation-centered view is adopted.
Where Pith is reading between the lines
- The taxonomy may help researchers design regularization terms that explicitly track geometry changes across acoustic shifts.
- Similar representation-structure arguments could apply to continual learning in other modalities that use entangled foundation models.
- Direct measurements of latent geometry metrics before and after updates could serve as new evaluation criteria for speech CL.
Load-bearing premise
Modern speech foundation models operate over highly entangled, continuous representations that jointly encode linguistic, speaker, and paralinguistic factors within a shared latent space.
What would settle it
An experiment that measures whether continual learning methods preserving representation geometry outperform methods focused only on retaining isolated task performance when speech foundation models encounter distribution shifts.
Figures
read the original abstract
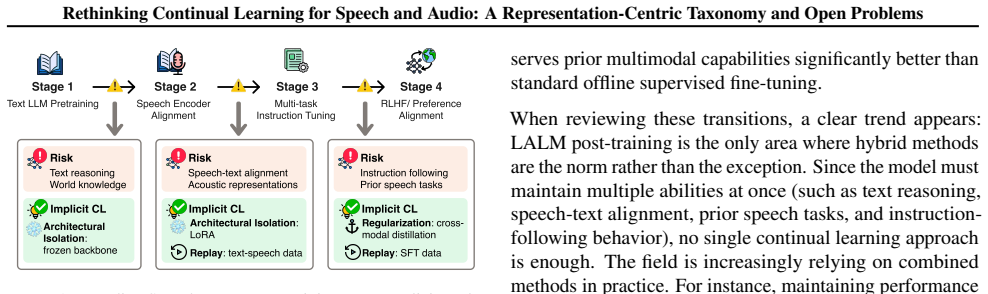
Speech and audio systems operate in inherently non-stationary environments, yet continual learning (CL) research in this domain, especially in the foundation model era, remains fragmented that fail to account for the coupled, geometry-sensitive nature of acoustic representations. Modern speech foundation models operate over highly entangled, continuous representations that jointly encode linguistic, speaker, and paralinguistic factors within a shared latent space. CL is therefore fundamentally about preserving and evolving shared representation structure rather than retaining isolated task knowledge. In this work, we revisit CL for speech from a representation-centered perspective, and introduce a new taxonomy that organizes CL according to how underlying representation geometry evolves under non-stationary acoustic conditions. We further identify key mismatches between current CL assumptions and speech foundation model behavior, and finally outline a set of open challenges and future research directions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that continual learning (CL) for speech and audio must be reframed around the evolution of shared representation geometry in modern foundation models, whose latent spaces entangle linguistic, speaker, and paralinguistic factors. It introduces a taxonomy that classifies CL approaches according to how representation geometry changes under non-stationary acoustic conditions, identifies mismatches between conventional CL assumptions and speech foundation-model behavior, and enumerates open challenges for future work.
Significance. If the taxonomy proves coherent and actionable, the work could usefully reorganize a fragmented literature by directing attention to geometry-preserving mechanisms rather than task-isolated buffers. The representation-centric lens is a coherent reframing that aligns with known properties of self-supervised speech models; explicit credit is due for surfacing open problems that follow directly from the premise of entangled continuous representations.
major comments (1)
- [Abstract] Abstract: the assertion that 'CL is therefore fundamentally about preserving and evolving shared representation structure rather than retaining isolated task knowledge' is presented as a direct logical consequence of entangled representations, yet the manuscript supplies no formal argument, counter-example analysis, or comparison to task-centric CL formulations that would establish this as a general principle rather than a perspective.
minor comments (2)
- [Abstract] Abstract, sentence 2: 'remains fragmented that fail to account' is grammatically incomplete; rephrase for clarity (e.g., 'remains fragmented and fails to account').
- [Abstract] Title vs. Abstract: 'representation-centric' (title) versus 'representation-centered' (abstract) should be standardized for consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for minor revision. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'CL is therefore fundamentally about preserving and evolving shared representation structure rather than retaining isolated task knowledge' is presented as a direct logical consequence of entangled representations, yet the manuscript supplies no formal argument, counter-example analysis, or comparison to task-centric CL formulations that would establish this as a general principle rather than a perspective.
Authors: We agree that the abstract states the claim without supplying a formal argument, counter-example, or direct comparison to task-centric formulations. The manuscript is a perspective and taxonomy paper whose core claim follows from the documented properties of entangled representations in speech foundation models (as reviewed in the introduction and Section 2, with supporting citations). We do not intend the statement as a formally proven general principle. We will revise the abstract to qualify the phrasing explicitly as a perspective arising from the representation-centric premise (e.g., replacing 'is therefore fundamentally' with 'we argue is fundamentally'), thereby aligning the wording with the non-formal character of the work. revision: yes
Circularity Check
No circularity: conceptual taxonomy without derivations or self-referential reductions
full rationale
This is a perspective and taxonomy paper that organizes existing CL methods by representation-geometry evolution under non-stationary conditions. The abstract and described structure contain no equations, no fitted parameters, no predictions derived from subsets of data, and no load-bearing self-citations that justify uniqueness theorems or ansatzes. The central claim (CL concerns preserving shared representation structure) is presented as a direct consequence of the stated premise about entangled foundation-model representations; it does not reduce to a definitional loop, a renamed empirical pattern, or an imported result whose only support is prior work by the same authors. The contribution is therefore self-contained as a reframing exercise rather than a derivation that collapses to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AFT: An exemplar-free class incremental learning method for en- vironmental sound classification
Chen, X., Chen, X., Weng, Z., and Xiao, Y . AFT: An exemplar-free class incremental learning method for en- vironmental sound classification. InICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),
2026
-
[2]
Chu, Y ., Xu, J., Yang, Q., Wei, H., Wei, X., Guo, Z., Leng, Y ., Lv, Y ., He, J., Lin, J., et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
d., Bai, R., Gu, Z., Likhomanenko, T., Jaitly, N., and Aldeneh, Z
Cuervo, S., Seto, S., Seyssel, M. d., Bai, R., Gu, Z., Likhomanenko, T., Jaitly, N., and Aldeneh, Z. Clos- ing the Gap Between Text and Speech Understanding in LLMs.ArXiv, abs/2510.13632, oct
-
[4]
doi: 10.1609/aaai.v39i15.33770. De Lange, M., Aljundi, R., Masana, M., Parisot, S., Jia, X., Leonardis, A., Slabaugh, G., and Tuytelaars, T. A continual learning survey: Defying forgetting in classifi- cation tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385,
-
[5]
Frascaroli, E., Panariello, A., Buzzega, P., Bonicelli, L., Porrello, A., and Calderara, S. Clip with generative latent replay: a strong baseline for incremental learning.arXiv preprint arXiv:2407.15793,
-
[6]
Domain Expan- sion in DNN-Based Acoustic Models for Robust Speech Recognition.2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp
Ghorbani, S., Khorram, S., and Hansen, J. Domain Expan- sion in DNN-Based Acoustic Models for Robust Speech Recognition.2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 107–113, oct
2019
-
[7]
Hsiao, C.-Y ., Lu, K.-H., Chang, K.-W., Yang, C.-K., Chen, W.-C., and Lee, H.-y. Analyzing Mitigation Strategies for Catastrophic Forgetting in End-to-End Training of Spoken Language Models.ArXiv, abs/2505.17496, may
-
[8]
doi: 10.1073/pnas.1611835114. Li, C., Zhou, K., and Wang, L. PACE: Pretrained audio continual learning,
-
[9]
doi: 10.1007/978-3-319-46493-0
-
[10]
A Parameter-efficient Language Extension Framework for Multilingual ASR.ArXiv, abs/2406.06329, jun
Liu, W., Hou, J., Yang, D., Cao, M., and Lee, T. A Parameter-efficient Language Extension Framework for Multilingual ASR.ArXiv, abs/2406.06329, jun
-
[11]
and Xiao, Y
Peng, T. and Xiao, Y . Dark Experience for Incremental Key- word Spotting.ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, sep
2025
-
[12]
A practitioner’s guide to continual multimodal pretraining.arXiv preprint arXiv:2408.14471,
Roth, K., Udandarao, V ., Dziadzio, S., Prabhu, A., Cherti, M., Vinyals, O., H´enaff, O., Albanie, S., Bethge, M., and Akata, Z. A practitioner’s guide to continual multimodal pretraining.arXiv preprint arXiv:2408.14471,
-
[13]
Closing the Modality Reasoning Gap for Speech Large Language Models
Shenfeld, I., Pari, J., and Agrawal, P. RL’s Razor: why on-policy reinforcement learning forgets less. InNon- Euclidean Foundation Models: Advancing AI Beyond Euclidean Frameworks. Wang, C., Lu, H., Zhang, X., Liu, S., Lu, Y ., Li, J., and Wu, Z. Closing the Modality Reasoning Gap for Speech Large Language Models.ArXiv, abs/2601.05543, jan
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Cross-modal Knowl- edge Distillation for Speech Large Language Models
5 Rethinking Continual Learning for Speech and Audio: A Representation-Centric Taxonomy and Open Problems Wang, E., Li, Q., Tang, Z., and Jia, Y . Cross-modal Knowl- edge Distillation for Speech Large Language Models. ArXiv, abs/2509.14930, sep 2025a. Wang, G., Zhao, J., Yang, H., Qi, G., Wu, T., and Haffari, G. Continual speech learning with fused speech...
-
[15]
Xiao, Y ., Holden, E.-J., and Dang, T. Adapting where it matters: Depth-aware adaptation for efficient multilingual speech recognition in low-resource languages. InACL 2026, 2026a. Xiao, Y ., Mahmudi, A., Thieberger, N., Ambikairajah, E., Holden, E.-J., and Dang, T. Continual Adaptation for Pacific Indigenous Speech Recognition, mar 2026b. Xu, T., Huang, ...
-
[16]
S., and Lee, H.-y
Yang, C.-K., Ho, N. S., and Lee, H.-y. Towards holistic evaluation of large audio-language models: A compre- hensive survey. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 10155–10181,
2025
-
[17]
To- wards Lifelong Learning of Multilingual Text-to-Speech Synthesis.ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp
Yang, M., Ding, S., Chen, T., Wang, T., and Wang, Z. To- wards Lifelong Learning of Multilingual Text-to-Speech Synthesis.ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8022–8026, oct
2022
-
[18]
Yuen, K. C., Yip, J., and Siong, C. E. Continual Learn- ing with Embedding Layer Surgery and Task-wise Beam Search using Whisper.ArXiv, abs/2501.07875, jan
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.