Entropy-Regularized Certainty-Equivalent Bellman Policies for Risk-Sensitive Market Making
Pith reviewed 2026-06-29 23:17 UTC · model grok-4.3
The pith
An entropy-regularized Bellman operator applies log-sum-exp directly to certainty-equivalent scores for risk-sensitive market making and converges to the continuous-time value at rate O(h + λ(1 + |log λ|)).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce an exact discrete entropy-regularized Bellman operator that applies log-sum-exp regularization to deterministic-action certainty-equivalent scores, rather than to a risk-neutral one-step reward. This distinction is essential because the exponential certainty equivalent does not commute with quote randomization. For time step h and entropy parameter λ, we prove uniform convergence to the unregularized continuous-time risk-sensitive value at rate O(h + λ(1 + |log λ|)). We also prove certainty-equivalent performance bounds for the induced Gibbs policies under a fresh-sampling relaxed implementation, in which quote marks are sampled at potential fill events rather than frozen over a
What carries the argument
The exact discrete entropy-regularized Bellman operator that applies log-sum-exp regularization to the certainty-equivalent scores of deterministic quote actions.
If this is right
- The discrete values converge uniformly to the continuous-time risk-sensitive value at the stated rate.
- Gibbs policies obtained from the operator satisfy explicit certainty-equivalent performance bounds under fresh sampling.
- Under the quadratic growth condition the policies concentrate around the unregularized optimal quote set.
- A cheaper Hamiltonian-Gibbs proxy achieves the same order of performance bound as the exact operator.
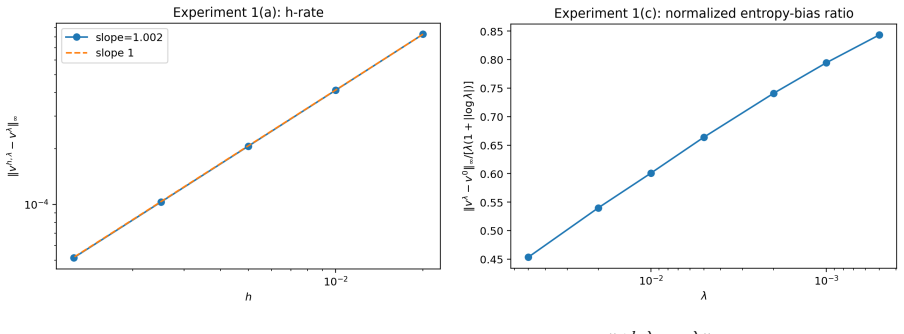
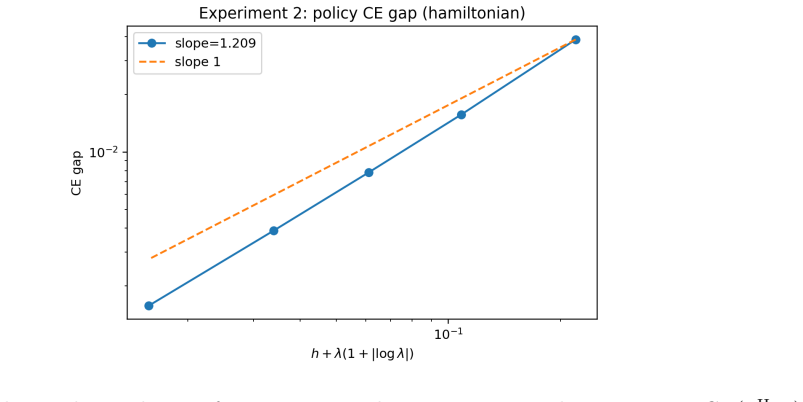
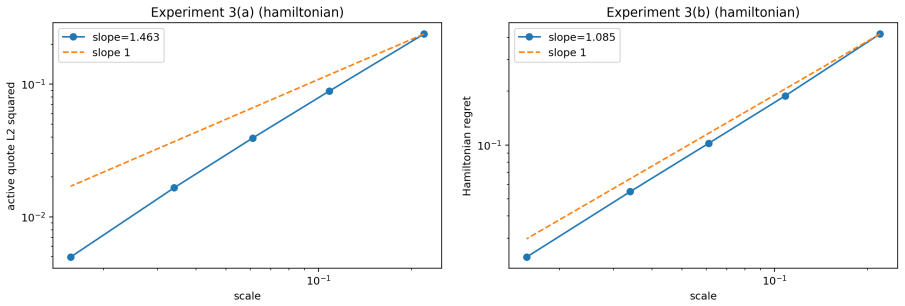
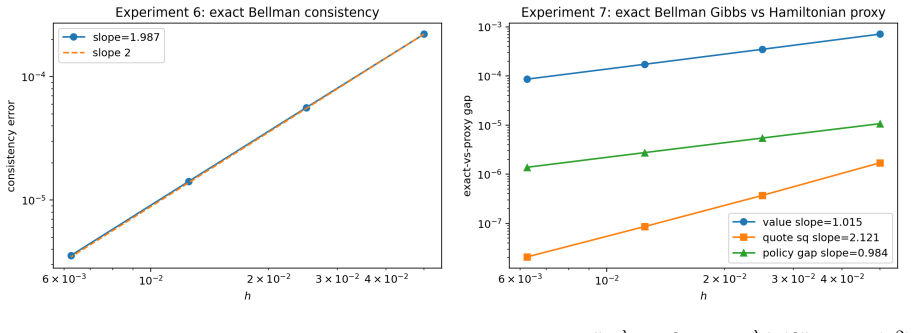
- Numerical experiments in the Avellaneda-Stoikov model confirm the predicted scalings for error, bias, gap, concentration, and proxy consistency.
Where Pith is reading between the lines
- The same non-commutativity argument suggests that entropy regularization should be applied to certainty equivalents in other exponential-utility control problems beyond market making.
- Fresh sampling of quotes at fill times may be worth testing in live high-frequency systems where freezing quotes for fixed intervals is costly.
- The quadratic growth condition on the Hamiltonian points to a robustness property that could be checked in models with different order-arrival specifications.
- The lower-cost proxy could serve as a practical starting point for online policy improvement when exact Bellman updates are too expensive.
Load-bearing premise
A quadratic growth condition on the Hamiltonian in the quote coordinates is required for the regularized policies to concentrate around the optimal quote set.
What would settle it
A controlled simulation in which the value gap between the discrete regularized operator and the continuous-time limit fails to shrink proportionally to h when λ is held fixed and small would falsify the claimed convergence rate.
Figures
read the original abstract
We study a finite-inventory risk-sensitive market making problem in which a dealer controls bid and ask quotes, faces Brownian midprice risk, and receives liquidity-taking orders through point processes with quote-dependent intensities. The objective is the certainty equivalent induced by exponential utility with terminal and running inventory penalties. We introduce an exact discrete entropy-regularized Bellman operator that applies log-sum-exp regularization to deterministic-action certainty-equivalent scores, rather than to a risk-neutral one-step reward. This distinction is essential because the exponential certainty equivalent does not commute with quote randomization. For time step \(h\) and entropy parameter \(\lambda\), we prove uniform convergence to the unregularized continuous-time risk-sensitive value at rate \[ O\bigl(h+\lambda(1+|\log\lambda|)\bigr). \] We also prove certainty-equivalent performance bounds for the induced Gibbs policies under a fresh-sampling relaxed implementation, in which quote marks are sampled at potential fill events rather than frozen over a time step. Under a quadratic growth condition on the Hamiltonian in the relevant quote coordinates, these policies concentrate around the unregularized optimal quote set. Finally, we show that a lower-cost Hamiltonian-Gibbs proxy satisfies a certainty-equivalent performance bound of the same order as the exact Bellman Gibbs policy. Numerical experiments in an Avellaneda--Stoikov specification support the predicted scaling for discretization error, entropy bias, policy gap, quote concentration, and exact-versus-proxy consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies finite-inventory risk-sensitive market making under exponential utility with Brownian midprice risk and quote-dependent point-process intensities. It introduces an exact discrete entropy-regularized Bellman operator that regularizes deterministic-action certainty-equivalent scores (rather than risk-neutral rewards), proves uniform convergence of the discrete value to the continuous-time limit at rate O(h + λ(1 + |log λ|)), derives certainty-equivalent performance bounds for the induced Gibbs policies under a fresh-sampling implementation, and shows that these policies concentrate around the optimal quote set when the Hamiltonian satisfies a quadratic growth condition in the quote coordinates. A lower-cost Hamiltonian-Gibbs proxy is also analyzed, and numerical experiments in an Avellaneda-Stoikov specification are used to illustrate the predicted scalings for discretization error, entropy bias, policy gap, and quote concentration.
Significance. If the quadratic-growth assumption holds in the model, the work supplies a rigorous discrete-time approximation framework for risk-sensitive market making with explicit non-asymptotic rates and a clear separation between the entropy-regularized operator and the non-commuting certainty equivalent. The exact operator construction and the numerical confirmation of the scaling laws are concrete strengths. The concentration and performance-bound claims, however, rest on an external modeling assumption whose validity for the exponential-utility objective and intensity functions is not established in the manuscript.
major comments (2)
- [Abstract / concentration theorem] Abstract and the statement of the concentration theorem: the claim that the Gibbs policies concentrate around the unregularized optimal quote set is conditioned on a quadratic growth condition on the Hamiltonian in the relevant quote coordinates. No verification or proof is supplied that this condition is satisfied by the point-process intensities or the exponential-utility Hamiltonian in the Avellaneda-Stoikov specification (or in general), rendering the concentration result conditional on an unexamined modeling assumption.
- [Performance bounds / fresh-sampling implementation] Performance-bound section (fresh-sampling relaxed implementation): the certainty-equivalent bounds are derived under the fresh-sampling scheme in which quotes are re-sampled at potential fill events. It is not shown that the same bounds continue to hold, or degrade gracefully, when the more common fixed-quote implementation over each time step h is used instead; this implementation detail is load-bearing for the practical relevance of the bounds.
minor comments (2)
- [Convergence theorem] Notation for the entropy parameter λ and time step h is introduced in the abstract but the precise functional dependence of the O(·) constants on model primitives (intensity bounds, volatility, inventory penalties) is not stated explicitly in the convergence theorem.
- [Numerical experiments] The numerical experiments section would benefit from an explicit table or plot showing the measured exponent of the discretization error versus h and the entropy bias versus λ to allow direct comparison with the predicted O(h + λ(1+|log λ|)) rate.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the positive comments on the exact discrete entropy-regularized Bellman operator, the convergence rates, and the numerical experiments. We address the two major comments below.
read point-by-point responses
-
Referee: [Abstract / concentration theorem] Abstract and the statement of the concentration theorem: the claim that the Gibbs policies concentrate around the unregularized optimal quote set is conditioned on a quadratic growth condition on the Hamiltonian in the relevant quote coordinates. No verification or proof is supplied that this condition is satisfied by the point-process intensities or the exponential-utility Hamiltonian in the Avellaneda-Stoikov specification (or in general), rendering the concentration result conditional on an unexamined modeling assumption.
Authors: The concentration theorem is explicitly stated under the quadratic growth condition on the Hamiltonian, which is a standard modeling assumption for such concentration results to hold. We agree that an analytical verification for the specific intensities and utility in the Avellaneda-Stoikov model is not provided. In the revised manuscript, we will add a remark discussing the condition's plausibility for exponential intensities and bounded inventory, supported by the numerical evidence of quote concentration in Section 5. This addresses the concern without altering the conditional nature of the result. revision: partial
-
Referee: [Performance bounds / fresh-sampling implementation] Performance-bound section (fresh-sampling relaxed implementation): the certainty-equivalent bounds are derived under the fresh-sampling scheme in which quotes are re-sampled at potential fill events. It is not shown that the same bounds continue to hold, or degrade gracefully, when the more common fixed-quote implementation over each time step h is used instead; this implementation detail is load-bearing for the practical relevance of the bounds.
Authors: We acknowledge that the performance bounds are derived specifically for the fresh-sampling implementation, which facilitates the application of the entropy-regularized operator at event times. The fixed-quote implementation, while more common in practice, introduces additional approximation due to quote freezing over the interval h. In the revision, we will include a discussion of this distinction and argue that for small h the performance gap is controlled by the discretization error term O(h), though a full extension of the bounds to fixed quotes is beyond the current scope. This clarifies the practical relevance. revision: partial
- Analytical proof that the quadratic growth condition holds for the Hamiltonian in the Avellaneda-Stoikov specification with exponential utility.
Circularity Check
No significant circularity; derivation self-contained under external assumptions
full rationale
The paper constructs its own discrete entropy-regularized Bellman operator from first principles, proves uniform convergence of the value function at the stated rate directly from that operator, and derives policy concentration and performance bounds under an explicitly stated quadratic growth assumption on the Hamiltonian. This assumption is introduced as a modeling hypothesis rather than derived or fitted within the paper, and the non-commutativity argument for certainty equivalents is independent of it. No self-citations, self-definitional loops, fitted inputs relabeled as predictions, or renamings of known results appear in the derivation chain. The claims reduce to standard analysis of the introduced operator plus the external assumption, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- entropy parameter λ
- time step h
axioms (1)
- domain assumption Quadratic growth condition on the Hamiltonian in the relevant quote coordinates
Reference graph
Works this paper leans on
-
[1]
Thomas Ho and Hans R. Stoll. Optimal dealer pricing under transactions and return uncertainty. Journal of Financial Economics, 9(1):47–73, 1981. doi: 10.1016/0304-405X(81)90020-9
-
[2]
High-frequency trading in a limit order book.Quantitative Finance, 8(3):217–224, 2008
Marco Avellaneda and Sasha Stoikov. High-frequency trading in a limit order book.Quantitative Finance, 8(3):217–224, 2008. doi: 10.1080/14697680701381228
-
[3]
Olivier Gu´ eant, Charles-Albert Lehalle, and Joaquin Fernandez-Tapia. Dealing with the inventory risk: A solution to the market making problem.Mathematics and Financial Economics, 7(4):477–507, 2013. doi: 10.1007/s11579-012-0087-0
-
[4]
Cam- bridge University Press, 2015
´Alvaro Cartea, Sebastian Jaimungal, and Jos´ e Penalva.Algorithmic and High-Frequency Trading. Cam- bridge University Press, 2015. 19
2015
-
[5]
Ziebart, J
Brian D. Ziebart, J. Andrew Bagnell, and Anind K. Dey. Modeling interaction via the principle of maximum causal entropy. InProceedings of the 27th International Conference on Machine Learning, pages 1255–1262, 2010
2010
-
[6]
A theory of regularized markov decision processes
Matthieu Geist, Bruno Scherrer, and Olivier Pietquin. A theory of regularized markov decision processes. InProceedings of the 36th International Conference on Machine Learning, pages 2160–2169, 2019
2019
-
[7]
Soft actor-critic: Off-policy maxi- mum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maxi- mum entropy deep reinforcement learning with a stochastic actor. InProceedings of the 35th Interna- tional Conference on Machine Learning, pages 1861–1870, 2018
2018
-
[8]
High-frequency market-making with inventory constraints and directional bets, 2012
Pietro Fodra and Mauricio Labadie. High-frequency market-making with inventory constraints and directional bets, 2012
2012
-
[9]
´Alvaro Cartea, Sebastian Jaimungal, and Jason Ricci. Buy low, sell high: A high frequency trading perspective.SIAM Journal on Financial Mathematics, 5(1):415–444, 2014. doi: 10.1137/130911196
-
[10]
´Alvaro Cartea and Yixuan Wang. Market making with alpha signals.International Journal of Theo- retical and Applied Finance, 23(3):2050016, 2020. doi: 10.1142/S0219024920500168
-
[11]
´Alvaro Cartea and Leandro S´ anchez-Betancourt. The shadow price of latency: Improving intraday fill ratios in foreign exchange markets.SIAM Journal on Financial Mathematics, 12(1):254–294, 2021. doi: 10.1137/19M1258888
-
[12]
Figueroa-L´ opez, Chuyi Yu, and Yi Zhang
Jonathan Ch´ avez-Casillas, Jos´ e E. Figueroa-L´ opez, Chuyi Yu, and Yi Zhang. Adaptive optimal market making strategies with inventory liquidation cost, 2024
2024
-
[13]
Wiley, 1990
Peter Whittle.Risk-Sensitive Optimal Control. Wiley, 1990
1990
-
[14]
Wendell H. Fleming and William M. McEneaney. Risk-sensitive control on an infinite time horizon. SIAM Journal on Control and Optimization, 33(6):1881–1915, 1995. doi: 10.1137/S0363012993258720
-
[15]
Tomasz R. Bielecki and Stanley R. Pliska. Risk-sensitive dynamic asset management.Applied Mathe- matics and Optimization, 39(3):337–360, 1999. doi: 10.1007/s002459900110
-
[16]
Taming the noise in reinforcement learning via soft updates
Roy Fox, Ari Pakman, and Naftali Tishby. Taming the noise in reinforcement learning via soft updates. InProceedings of the Thirty-Second Conference on Uncertainty in Artificial Intelligence, pages 202–211, 2016
2016
-
[17]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. InProceedings of the 34th International Conference on Machine Learning, pages 1352–1361, 2017
2017
-
[18]
Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020
Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou. Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020
2020
-
[19]
Exploratory hjb equations and their convergence
Wenpin Tang, Yuming Paul Zhang, and Xun Yu Zhou. Exploratory hjb equations and their convergence. SIAM Journal on Control and Optimization, 60(6):3191–3216, 2022. doi: 10.1137/21M1448185
-
[20]
Yanwei Jia and Xun Yu Zhou.q-learning in continuous time.Journal of Machine Learning Research, 24(161):1–61, 2023
2023
-
[21]
Yanwei Jia. Continuous-time risk-sensitive reinforcement learning via quadratic variation penalty.Ap- plied Mathematics and Optimization, 93:58, 2026. doi: 10.1007/s00245-026-10412-4
-
[22]
Risk-sensitiveq-learning in continuous time with application to dynamic portfolio selection, 2025
Chuhan Xie. Risk-sensitiveq-learning in continuous time with application to dynamic portfolio selection, 2025. 20
2025
-
[23]
Reconciling discrete-time mixed policies and continuous-time relaxed controls in reinforcement learning and stochastic control, 2025
Ren´ e Carmona and Mathieu Lauri` ere. Reconciling discrete-time mixed policies and continuous-time relaxed controls in reinforcement learning and stochastic control, 2025
2025
-
[24]
Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning, 2025
Yanwei Jia, Du Ouyang, and Yufei Zhang. Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning, 2025
2025
-
[25]
Discretization error from regularized reinforcement learning to continuous-time stochastic control, 2026
Huyˆ en Pham, Yuming Paul Zhang, and Yuhua Zhu. Discretization error from regularized reinforcement learning to continuous-time stochastic control, 2026
2026
-
[26]
Market making via rein- forcement learning
Thomas Spooner, John Fearnley, Rahul Savani, and Andreas Koukorinis. Market making via rein- forcement learning. InProceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, pages 434–442, 2018
2018
-
[27]
Reinforcement learning for high-frequency market making
Ye-Sheen Lim and Denise Gorse. Reinforcement learning for high-frequency market making. InPro- ceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, pages 521–526, 2018
2018
-
[28]
Robust market making via adversarial reinforcement learning, 2020
Thomas Spooner and Rahul Savani. Robust market making via adversarial reinforcement learning, 2020
2020
-
[29]
Jialun Cao, David ˇSiˇ ska, Lukasz Szpruch, and Tanut Treetanthiploet. Logarithmic regret in the ergodic avellaneda–stoikov market making model.SIAM Journal on Financial Mathematics, 2026. doi: 10. 48550/arXiv.2409.02025. Forthcoming
-
[30]
Reinforcement learning in high-frequency market making, 2024
Yuheng Zheng and Zihan Ding. Reinforcement learning in high-frequency market making, 2024
2024
-
[31]
Resolving latency and inventory risk in market making with reinforcement learning, 2025
Junzhe Jiang, Chang Yang, Xinrun Wang, Zhiming Li, Xiao Huang, and Bo Li. Resolving latency and inventory risk in market making with reinforcement learning, 2025
2025
-
[32]
Deep reinforcement learning in non-markov market-making.Risks, 13(3):40, 2025
Luca Lalor and Anatoliy Swishchuk. Deep reinforcement learning in non-markov market-making.Risks, 13(3):40, 2025. doi: 10.3390/risks13030040
-
[33]
Reinforcement learning-based market making as a stochastic control on non-stationary limit order book dynamics, 2025
Rafael Zimmer and Oswaldo Luiz do Valle Costa. Reinforcement learning-based market making as a stochastic control on non-stationary limit order book dynamics, 2025
2025
-
[34]
Wasserstein robust market making via entropy regularization, 2025
Zhou Fang and Arie Israel. Wasserstein robust market making via entropy regularization, 2025. A Auxiliary Estimates for the Market-Making Model Throughout the appendices,Cdenotes a finite constant depending only on T, Q, γ, σ, Λ, δ, δ,Φ, η, m −, m+, and on theC 1-bounds of Λa,Λ b on [δ, δ]. Its value may change from line to line, but it is independent ofh...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.