Information-Theoretic Reliability is Robust to Analytic Choice: A 24-Specification Multiverse on Public Cognitive Test-Retest Data
Pith reviewed 2026-06-29 23:33 UTC · model grok-4.3
The pith
Information-theoretic reliability measure does not rescue cognitive tasks from the reliability paradox across 24 analytic variants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
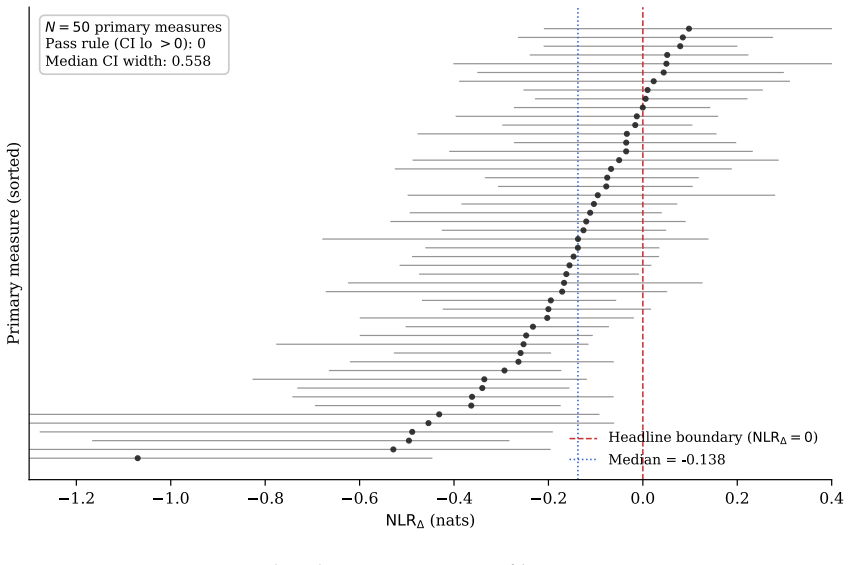
On these two public datasets, replacing or augmenting ICC with an information-theoretic reliability measure does not rescue cognitive tasks from the reliability paradox. The robust null is invariant to the analytic choices examined here.
What carries the argument
NLRΔ, defined as the difference between empirically estimated mutual information and the analytic Gaussian baseline implied by the test-retest correlation.
If this is right
- The companion ICC(2,1) analysis recovers the classical reliability paradox pattern.
- Zero of 50 primary measures exceed the headline rule under NLRΔ.
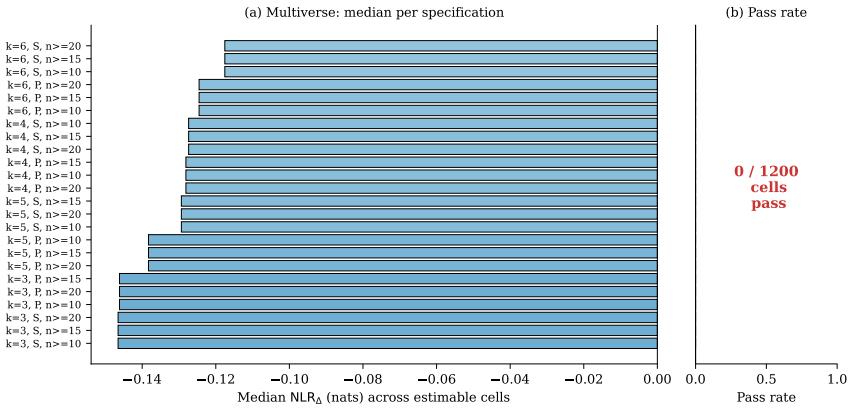
- The 24-specification multiverse yields zero of 1,200 estimable cells passing the headline rule.
- The full pipeline, raw-data hashes, and claim contracts are released to enable exact replication on other datasets.
Where Pith is reading between the lines
- If the Gaussian baseline is retained, alternative estimators of mutual information or different reference distributions could be tested to see whether they alter the sign of NLRΔ.
- The result raises the question of whether the reliability paradox is better addressed by redesigning tasks or by shifting the unit of analysis away from single-task scores.
- Exact replication contracts make it straightforward to apply the same multiverse to clinical or developmental samples where individual differences may be larger.
Load-bearing premise
The chosen headline rule and the Gaussian baseline in the definition of NLRΔ are the appropriate standards for deciding whether a reliability measure rescues tasks from the paradox.
What would settle it
A replication on the same tasks and datasets in which at least one primary measure yields NLRΔ above the headline rule under the identical pre-specified pipeline and multiverse.
Figures
read the original abstract
Background. The reliability paradox describes the empirical observation that cognitive tasks producing robust group-level effects often yield poor between-individual reliability. Existing approaches rely predominantly on the intraclass correlation coefficient (ICC), which captures only linear, second-moment dependence between test and retest. Methods. We introduce a normalized, information-theoretic complement to ICC, NLR{\Delta}, defined as the difference between empirically estimated mutual information and the analytic Gaussian baseline implied by the test-retest correlation. We pair NLR{\Delta} with ICC(2,1), bias-corrected and accelerated (BCa) bootstrap intervals, Benjamini-Hochberg false discovery rate (FDR) control, and a 24-cell multiverse over the KSG nearest-neighbour parameter, correlation method, and minimum-sample threshold. The full pipeline is governed by pre-specified claim contracts, content-addressed provenance, and SHA-256-verified raw data ingestion, and is released as the MixMind Reliability Framework. Results. Across 50 estimable primary measures from the Flanker, Stroop, Stop-Signal, Go/No-Go, and Posner task families, the median NLR{\Delta} is -0.138 nats, with interquartile range [-0.257, -0.034]. Zero of 50 primary measures exceed the headline rule. The companion ICC(2,1) analysis recovers the classical reliability paradox pattern, and the 24-specification multiverse yields 0 of 1,200 estimable cells passing the headline rule. Conclusions. On these two public datasets, replacing or augmenting ICC with an information-theoretic reliability measure does not rescue cognitive tasks from the reliability paradox. The robust null is invariant to the analytic choices examined here. We release the full pipeline, raw-data hashes, and contracts to enable exact replication and extension to other datasets and tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NLRΔ, an information-theoretic reliability measure defined as empirical mutual information minus the Gaussian baseline implied by test-retest correlation. Using pre-specified claim contracts, BCa bootstrap, FDR control, and a 24-cell multiverse over KSG k, correlation method, and minimum-sample threshold on two public cognitive datasets (Flanker, Stroop, Stop-Signal, Go/No-Go, Posner families), it reports median NLRΔ = -0.138 nats with zero of 50 primary measures (and zero of 1,200 multiverse cells) exceeding the headline rule. It concludes that neither ICC nor NLRΔ rescues tasks from the reliability paradox and releases the full pipeline with provenance.
Significance. If the central null holds after addressing the scope of the multiverse, the result would indicate that information-theoretic extensions do not resolve the reliability paradox on these datasets, reinforcing that the paradox is robust to the examined analytic variations. The pre-specified contracts, content-addressed provenance, SHA-256 data verification, and public release of the MixMind Reliability Framework are clear strengths that support reproducibility and extension.
major comments (2)
- [Abstract, Results, Conclusions] Abstract, Results, and Conclusions: The claim that 'the robust null is invariant to the analytic choices examined here' rests on a 24-specification multiverse that varies only KSG nearest-neighbour parameter k, correlation method, and minimum-sample threshold. The Gaussian baseline in the definition of NLRΔ and the exact headline rule used to decide passage are held fixed and not subjected to the same invariance test. Because the headline result is that zero of 1,200 cells pass, altering the baseline (e.g., to a rank-based or permutation null) or the threshold could change the count of passing cells and directly affect the robustness conclusion.
- [Methods] Methods (definition of NLRΔ): NLRΔ is constructed as estimated MI minus the analytic Gaussian MI implied by the observed test-retest correlation. The manuscript must confirm that both the Gaussian baseline choice and the headline rule were fixed in the pre-specified claim contracts prior to seeing the data, rather than selected post-hoc to produce the reported null; otherwise the invariance claim is weakened.
minor comments (2)
- [Notation] Notation: clarify whether 'nats' refers to natural units throughout and ensure consistent use of Δ versus other symbols in equations and figures.
- [Results] Table/figure presentation: ensure all 24 multiverse cells are explicitly tabulated or visualized so readers can verify the zero-pass count without relying solely on summary statistics.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important scope considerations for our invariance claim and the need for explicit confirmation of pre-specification. We respond point-by-point below, with revisions where they strengthen the manuscript without altering its core findings.
read point-by-point responses
-
Referee: [Abstract, Results, Conclusions] Abstract, Results, and Conclusions: The claim that 'the robust null is invariant to the analytic choices examined here' rests on a 24-specification multiverse that varies only KSG nearest-neighbour parameter k, correlation method, and minimum-sample threshold. The Gaussian baseline in the definition of NLRΔ and the exact headline rule used to decide passage are held fixed and not subjected to the same invariance test. Because the headline result is that zero of 1,200 cells pass, altering the baseline (e.g., to a rank-based or permutation null) or the threshold could change the count of passing cells and directly affect the robustness conclusion.
Authors: We agree that the multiverse varies only the estimation parameters (KSG k, correlation method, minimum-sample threshold) and holds the Gaussian baseline and headline rule fixed. These fixed elements are definitional: the Gaussian baseline implements the direct comparison to the linear second-moment dependence captured by ICC, and the headline rule operationalizes the test of whether any measure 'rescues' tasks from the paradox at a non-negligible level. Our conclusions explicitly qualify the claim as applying to 'the analytic choices examined here,' which does not extend to alternative baselines or thresholds. To make this scope clearer, we will revise the Conclusions and add a brief Methods paragraph noting that the multiverse targets estimation variability while the baseline and rule remain part of the pre-specified NLRΔ definition. revision: partial
-
Referee: [Methods] Methods (definition of NLRΔ): NLRΔ is constructed as estimated MI minus the analytic Gaussian MI implied by the observed test-retest correlation. The manuscript must confirm that both the Gaussian baseline choice and the headline rule were fixed in the pre-specified claim contracts prior to seeing the data, rather than selected post-hoc to produce the reported null; otherwise the invariance claim is weakened.
Authors: Both the Gaussian baseline (analytic MI under bivariate normality given the observed correlation) and the headline rule were fixed in the pre-specified claim contracts before any data were examined. These contracts, together with the full pipeline code and SHA-256 data hashes, are released publicly with the MixMind Reliability Framework. The Gaussian baseline was chosen a priori to provide a direct information-theoretic counterpart to ICC; the headline rule was set to test practical rescue from the paradox. No post-hoc adjustment occurred. We will add an explicit sentence in Methods confirming this pre-specification for these two elements. revision: yes
Circularity Check
No circularity: empirical results on public data are data-dependent, not forced by definition
full rationale
The paper defines NLRΔ explicitly as empirical mutual information minus the analytic Gaussian MI implied by the observed test-retest correlation, then reports the empirical distribution of this quantity (median -0.138 nats) across 50 measures from two public datasets. Zero of 50 primary measures and zero of 1,200 multiverse cells exceed the headline rule. This outcome is an observation on external data under the stated specifications; it is not equivalent to the inputs by construction, nor does any step reduce to a fitted parameter renamed as prediction or to a self-citation chain. The multiverse varies KSG k, correlation method, and minimum-sample threshold as described, and the conclusion is scoped to those choices. The derivation chain is therefore self-contained against the public benchmarks.
Axiom & Free-Parameter Ledger
free parameters (3)
- KSG nearest-neighbour parameter k
- Correlation method
- Minimum-sample threshold
axioms (2)
- domain assumption Mutual information can be reliably estimated via the KSG nearest-neighbour method on the given sample sizes.
- domain assumption The Gaussian mutual information implied by the Pearson or Spearman correlation is the appropriate analytic baseline.
invented entities (1)
-
NLRΔ
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B, 57 0 (1): 0 289--300, 1995. doi:10.1111/j.2517-6161.1995.tb02031.x
-
[2]
Clark, Linette Lawlor-Savage, and Vina M
Cameron M. Clark, Linette Lawlor-Savage, and Vina M. Goghari. The C ogmed working memory training program does not improve general cognition or fluid intelligence in healthy older adults. PLOS ONE, 12 0 (3): 0 e0173458, 2017. doi:10.1371/journal.pone.0173458
-
[3]
Peter E. Clayson. The psychometric upgrade psychophysiology needs. Psychophysiology, 61 0 (3): 0 e14522, 2024. doi:10.1111/psyp.14522
-
[4]
Cover and Joy A
Thomas M. Cover and Joy A. Thomas. Elements of Information Theory. Wiley-Interscience, 2nd edition, 2006
2006
-
[5]
Thomas J. DiCiccio and Bradley Efron. Bootstrap confidence intervals. Statistical Science, 11 0 (3): 0 189--228, 1996. doi:10.1214/ss/1032280214
-
[6]
Local likelihood estimation.Journal of the American Statistical Association, 82:559–567, 1987
Bradley Efron. Better bootstrap confidence intervals. Journal of the American Statistical Association, 82 0 (397): 0 171--185, 1987. doi:10.1080/01621459.1987.10478410
-
[7]
A. Zeynep Enkavi, Ian W. Eisenberg, Patrick G. Bissett, Gina L. Mazza, David P. MacKinnon, Lisa A. Marsch, and Russell A. Poldrack. Large-scale analysis of test-retest reliabilities of self-regulation measures. Proceedings of the National Academy of Sciences, 116 0 (12): 0 5472--5477, 2019. doi:10.1073/pnas.1818430116
-
[8]
Efficient estimation of mutual information for strongly dependent variables
Shuyang Gao, Greg Ver Steeg, and Aram Galstyan. Efficient estimation of mutual information for strongly dependent variables. In Proceedings of the 18th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 38 of Proceedings of Machine Learning Research, pages 277--286. PMLR, 2015. URL http://proceedings.mlr.press/v38/gao15.pdf
2015
-
[9]
Kvam, Louis H
Nathaniel Haines, Peter D. Kvam, Louis H. Irving, Colin Smith, Theodore P. Beauchaine, Mark A. Pitt, Woo-Young Ahn, and Brandon M. Turner. Theoretically informed generative models can advance the psychological and brain sciences: L essons from the reliability paradox. Psychological Methods, 2023. Advance online publication
2023
-
[10]
The reliability paradox: W hy robust cognitive tasks do not produce reliable individual differences
Craig Hedge, Georgina Powell, and Petroc Sumner. The reliability paradox: W hy robust cognitive tasks do not produce reliable individual differences. Behavior Research Methods, 50 0 (3): 0 1166--1186, 2018. doi:10.3758/s13428-017-0935-1
-
[11]
Povilas Karvelis and Andreea O. Diaconescu. Clarifying the reliability paradox: P oor measurement reliability attenuates group differences. Frontiers in Psychology, 16: 0 1592658, 2025. doi:10.3389/fpsyg.2025.1592658
-
[12]
Terry K. Koo and Mae Y. Li. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. Journal of Chiropractic Medicine, 15 0 (2): 0 155--163, 2016. doi:10.1016/j.jcm.2016.02.012
-
[13]
Alexander Kraskov, Harald St\"ogbauer, and Peter Grassberger. Estimating mutual information. Physical Review E, 69 0 (6): 0 066138, 2004. doi:10.1103/PhysRevE.69.066138
-
[14]
Talira Kucina, Lisa Wells, Ian Lewis, Kristy de Salas, Annette Kohl, Matthew A. Palmer, James D. Sauer, Dora Matzke, Eugene Aidman, and Andrew Heathcote. Calibration of cognitive tests to address the reliability paradox for decision-conflict tasks. Nature Communications, 14 0 (1): 0 2234, 2023. doi:10.1038/s41467-023-37777-2
-
[15]
Kenneth O. McGraw and S. P. Wong. Forming inferences about some intraclass correlation coefficients. Psychological Methods, 1 0 (1): 0 30--46, 1996. doi:10.1037/1082-989X.1.1.30
-
[16]
Sam Parsons, Anne-Wil Kruijt, and Elaine Fox. Psychological science needs a standard practice of reporting the reliability of cognitive-behavioral measurements. Advances in Methods and Practices in Psychological Science, 2 0 (4): 0 378--395, 2019. doi:10.1177/2515245919879695
-
[17]
Brian C. Ross. Mutual information between discrete and continuous data sets. PLOS ONE, 9 0 (2): 0 e87357, 2014. doi:10.1371/journal.pone.0087357
-
[18]
Claude E. Shannon. A mathematical theory of communication. Bell System Technical Journal, 27 0 (3): 0 379--423, 1948. doi:10.1002/j.1538-7305.1948.tb01338.x
-
[19]
Patrick E. Shrout and Joseph L. Fleiss. Intraclass correlations: U ses in assessing rater reliability. Psychological Bulletin, 86 0 (2): 0 420--428, 1979. doi:10.1037/0033-2909.86.2.420
-
[20]
Increasing transparency through a multiverse analysis
Sara Steegen, Francis Tuerlinckx, Andrew Gelman, and Wolf Vanpaemel. Increasing transparency through a multiverse analysis. Perspectives on Psychological Science, 11 0 (5): 0 702--712, 2016. doi:10.1177/1745691616658637
-
[21]
Mutual information reliability for latent class analysis
Chun Wang and Jeffrey Douglas. Mutual information reliability for latent class analysis. Educational and Psychological Measurement, 78 0 (6): 0 943--964, 2018. doi:10.1177/0013164417728571
-
[22]
MixMind Reliability Framework: Information-Theoretic Reliability Estimation for Cognitive Tasks
Maria Westrin. MixMind Reliability Framework: Information-Theoretic Reliability Estimation for Cognitive Tasks . Software, Zenodo, May 2026. doi:10.5281/zenodo.20207371. URL https://github.com/Maria-hub-Westrin/Maria-hub-Westrin-mixmind-reliability-framework. Software version 2.0.0, Result version v1.2.2
-
[23]
Improving the reliability of cognitive task measures: A narrative review
Samuel Zorowitz and Yael Niv. Improving the reliability of cognitive task measures: A narrative review. Biological Psychiatry: Cognitive Neuroscience and Neuroimaging, 8 0 (8): 0 789--797, 2023. doi:10.1016/j.bpsc.2023.02.004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.