Kavier: Exploring Performance, Sustainability, and Efficiency of LLM Ecosystems under Inference through Cache-Aware Discrete-Event Simulation
Pith reviewed 2026-06-29 23:24 UTC · model grok-4.3
The pith
Kavier is the first cache-aware discrete-event simulator for LLM ecosystems under inference, built on a synthesized reference architecture to predict performance, sustainability, and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
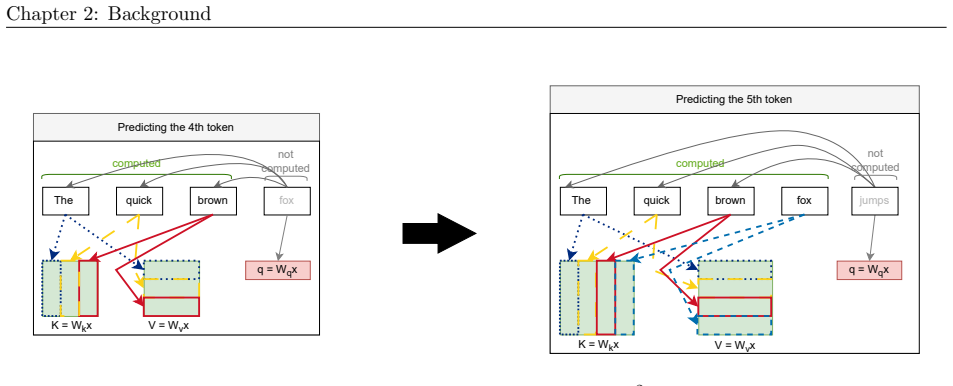
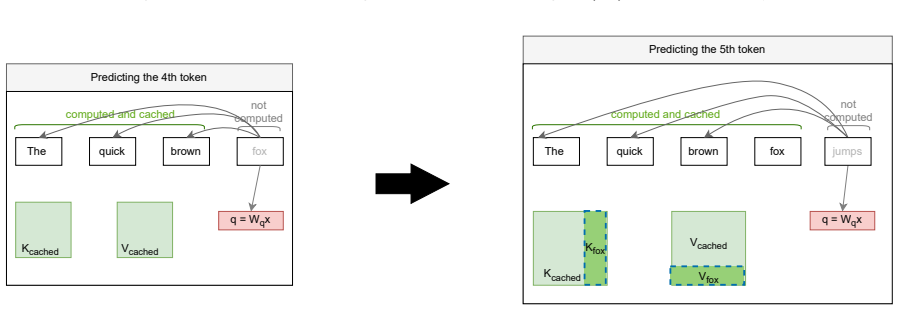
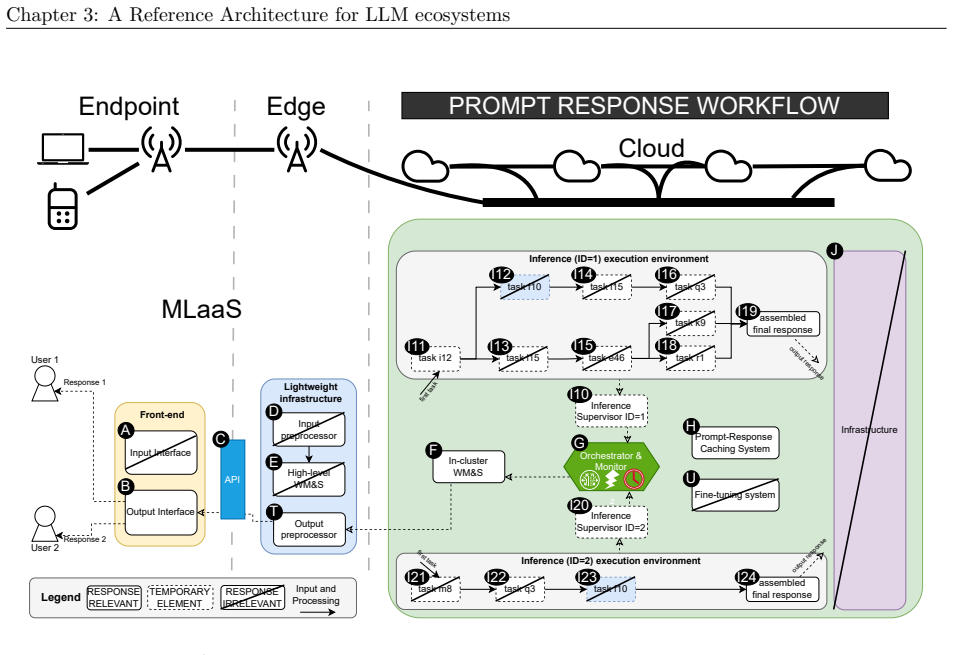
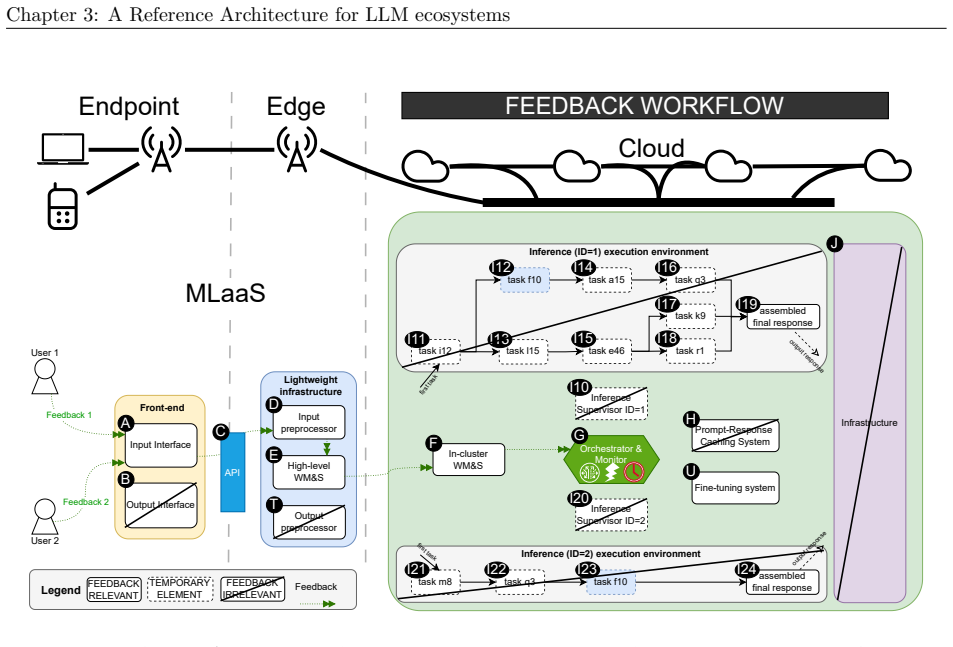
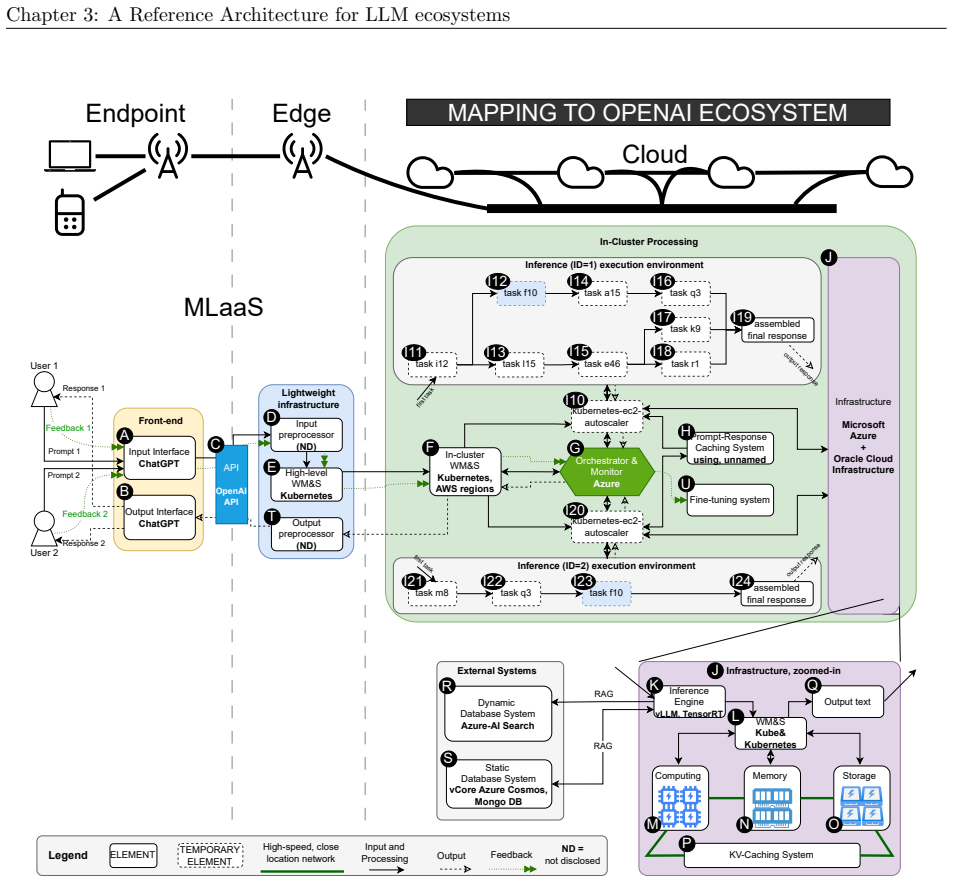
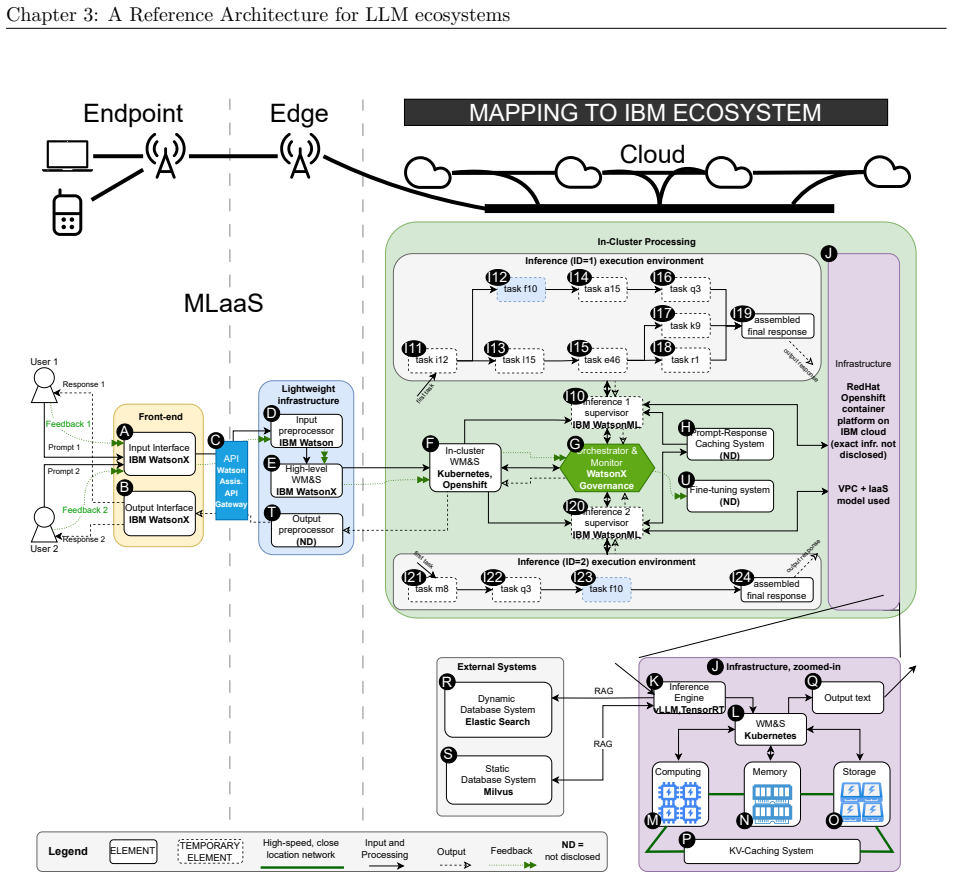
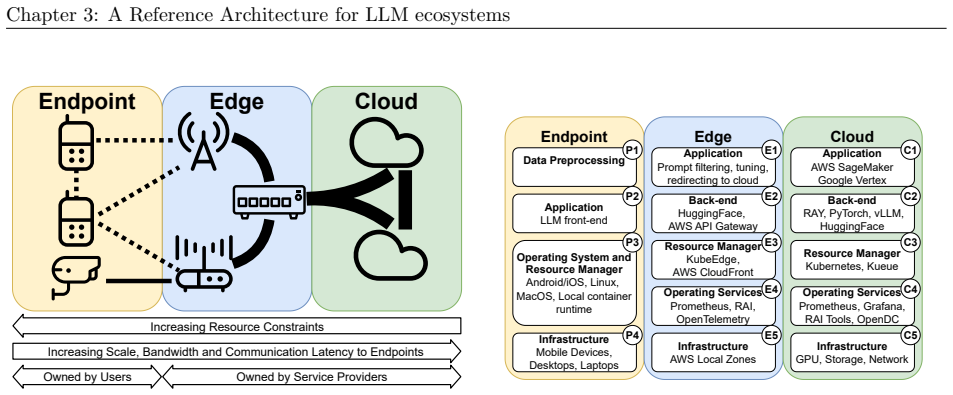
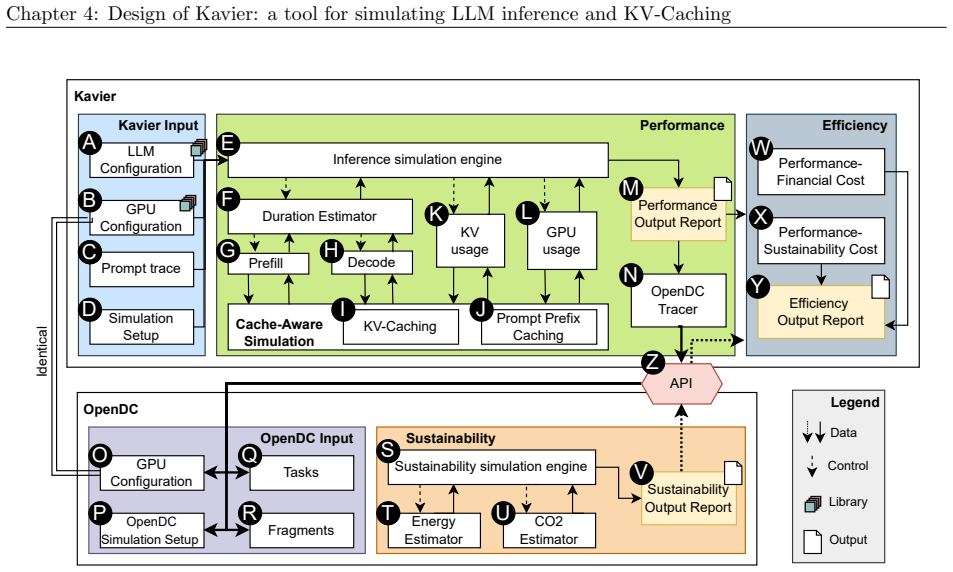
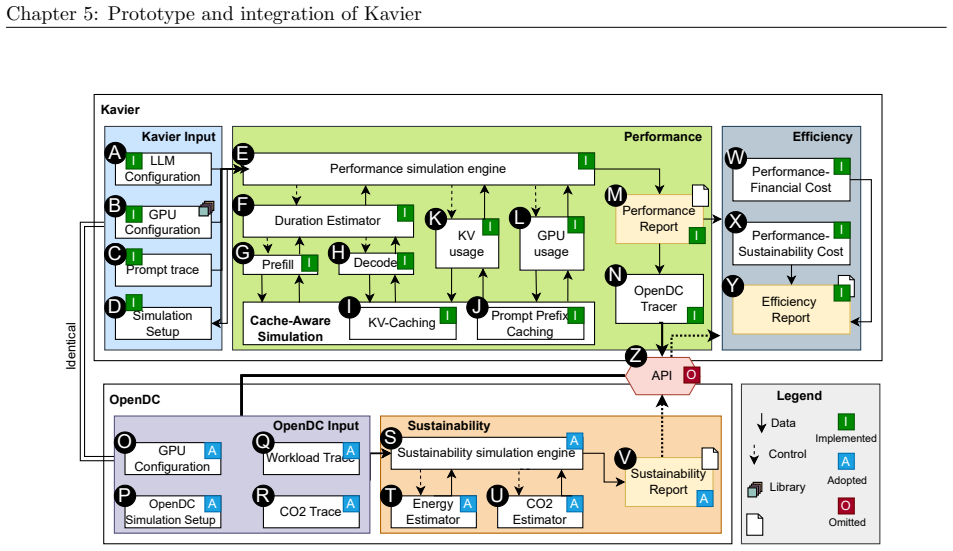
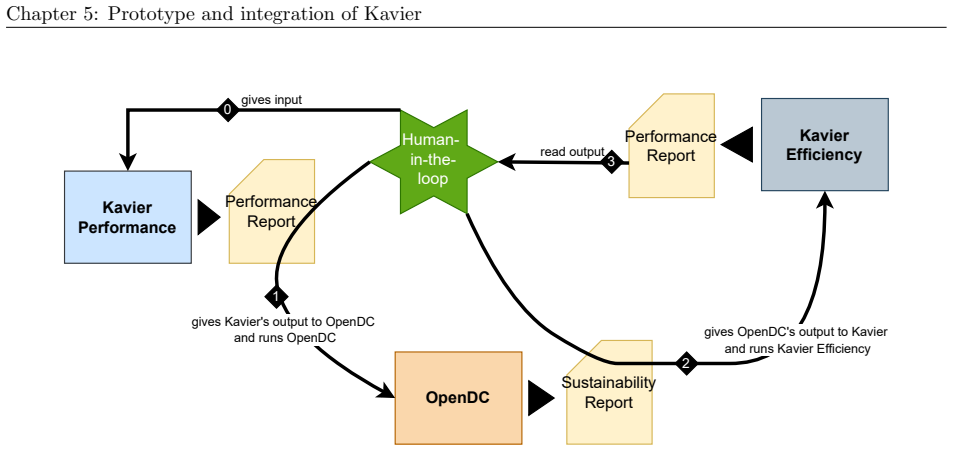
We synthesize a reference architecture of LLM ecosystems under inference and, adhering to it, design Kavier as the first simulation instrument able to predict the performance, sustainability, and efficiency of such ecosystems through discrete-event and cache-aware simulation focusing on KV-Caching and prompt prefix caching policies.
What carries the argument
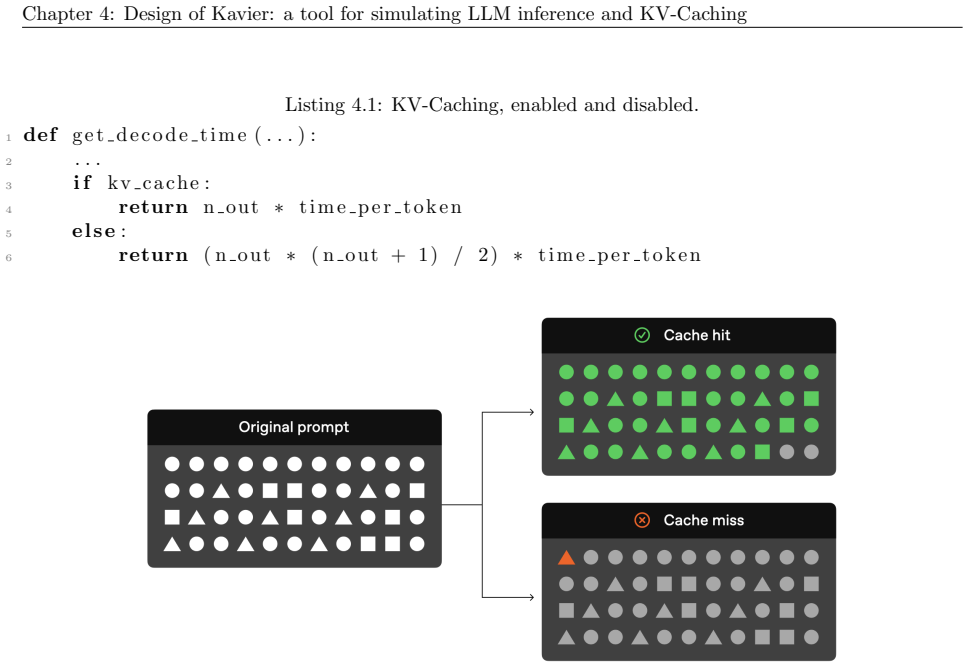
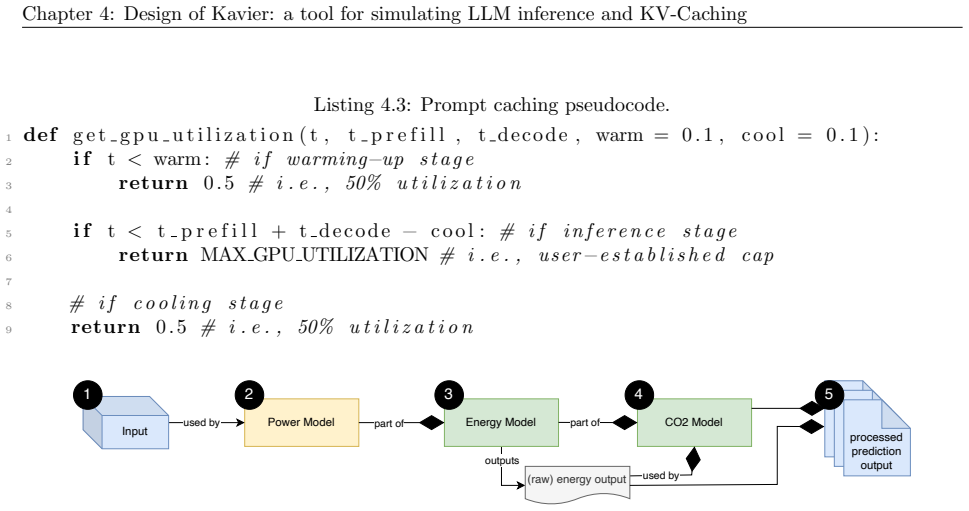
Kavier's cache-aware discrete-event simulation engine, which models KV-caching and prompt prefix caching policies within the synthesized reference architecture of LLM inference ecosystems.
If this is right
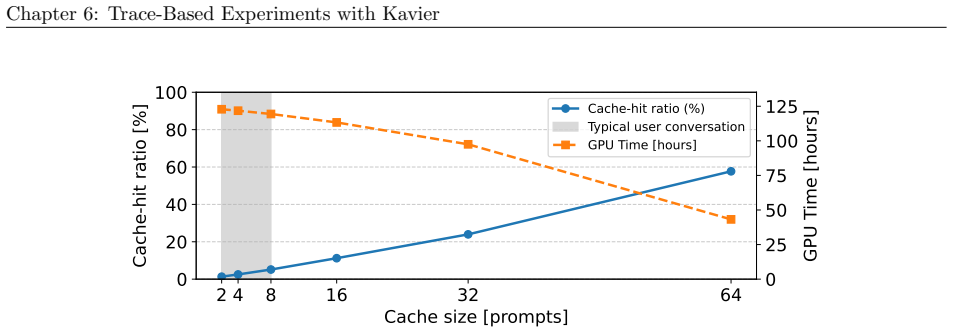
- Operators can compare the performance of different KV-Caching policies using the simulator.
- Analyses of performance, sustainability, and efficiency under various prefix caching policies become feasible at scale.
- Massive-scale simulations of LLM ecosystems can be conducted efficiently to predict behavior.
- Prediction of LLM ecosystems occurs in a time, performance, and cost-efficient manner.
Where Pith is reading between the lines
- If accurate, Kavier could serve as the basis for digital twins that optimize live LLM deployments in real time.
- The same simulation approach might extend to modeling training workloads or other AI system components.
- Quantified sustainability predictions could help compare the environmental costs of different inference setups.
Load-bearing premise
The synthesized reference architecture accurately represents real LLM ecosystems under inference, and the cache-aware discrete-event model in Kavier faithfully captures the behavior of KV-caching and prompt prefix caching without post-hoc adjustments.
What would settle it
Running Kavier on a specific workload and caching policy, then comparing its predicted metrics like latency, throughput, and energy use against measurements taken from an equivalent real-world LLM inference system.
Figures



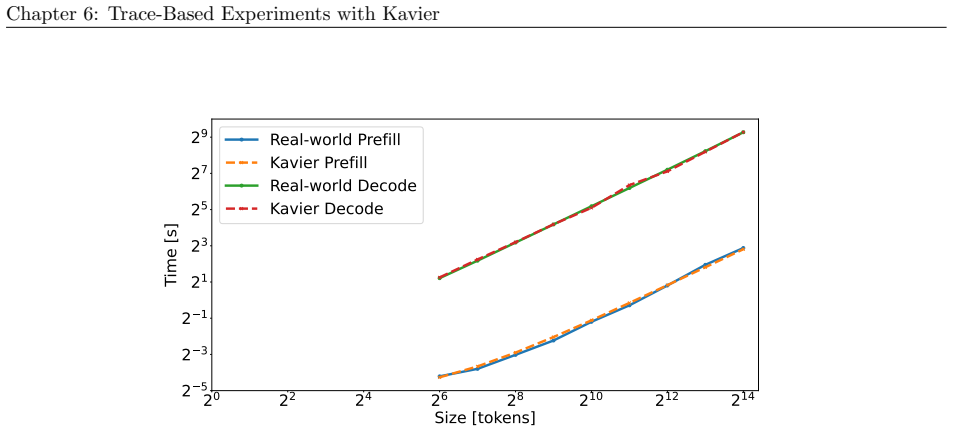
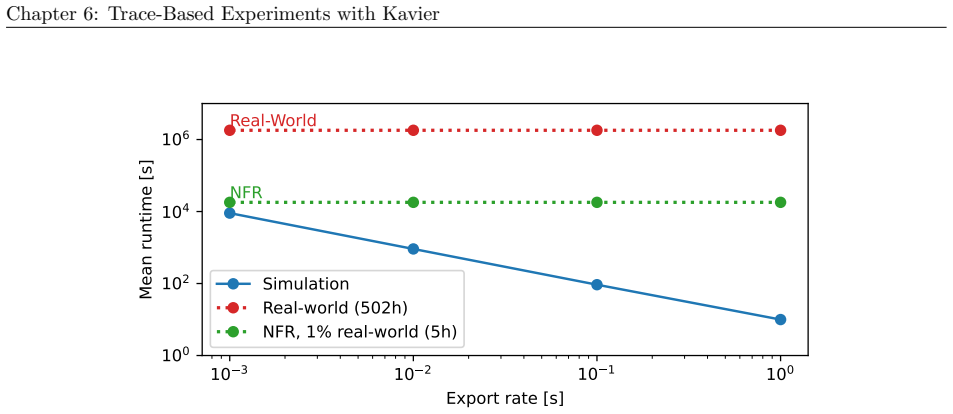
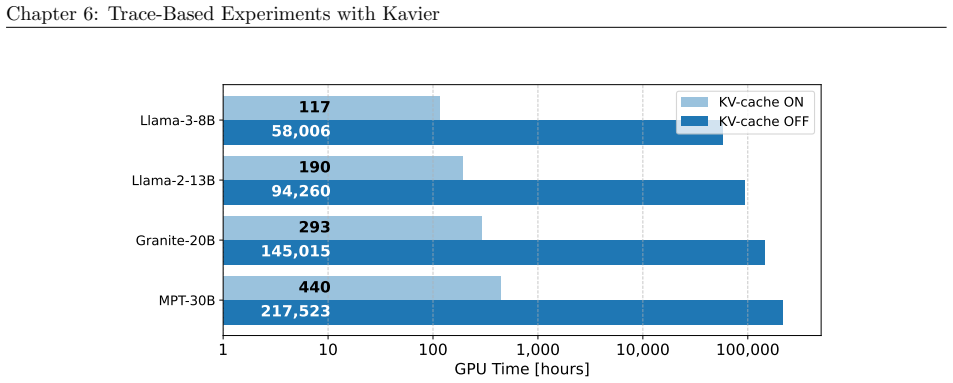

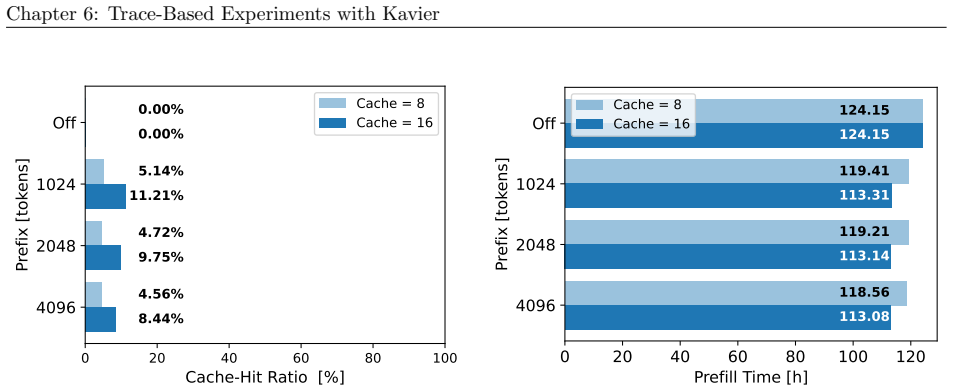

read the original abstract
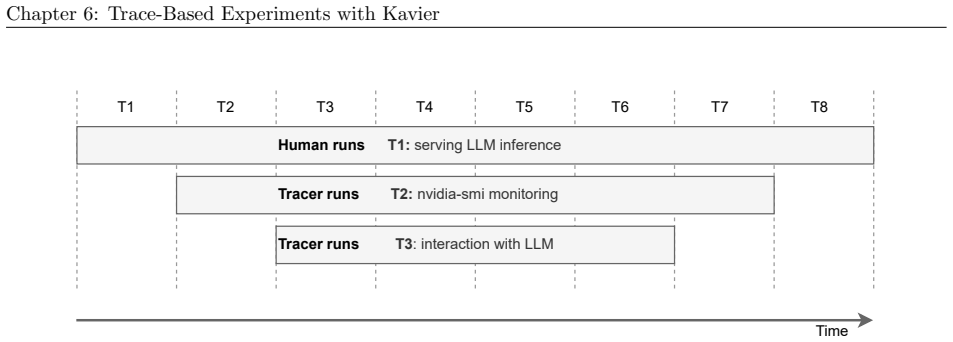
Large Language Models (LLMs) are widely used by our increasingly digitalized society, but raise sustainability, performance, and financial concerns, especially as inference workloads grow. To improve the design and operation of LLM ecosystems, we envision simulators and simulation-based digital twins becoming primary decision-making tools. LLM ecosystems leverage many heterogeneous components, making simulation a non-trivial, yet critical operation. The simulation challenge is exacerbated by the absence of a comprehensive reference architecture of LLM ecosystems; the lack of such a conceptual model can be costly and could misguide the designers and engineers. Without a reference architecture, even the most experienced stakeholders could tinker in researching, engineering, or maintaining LLM ecosystems. In this work, we bring a three-fold contribution to the scientific community. Firstly, we synthesize, propose, and validate a reference architecture (RA) of LLM ecosystems under inference. Then, adhering to the reference architecture, we design Kavier, the first simulation instrument able to predict the performance, sustainability, and efficiency of LLM ecosystems under inference, through discrete-event and cache-aware simulation, focusing on Key-Value-(KV-)Caching and prompt prefix caching policies. Through experiments with a Kavier prototype and real-world traces, (i) we measure the accuracy of Kavier and its performance in massive-scale simulations, (ii) we compare the performance of different KV-Caching policies, and (iii) we analyze the performance, sustainability, and efficiency of LLM ecosystems under various prefix caching policies. Overall, we show that Kavier enables operators, researchers, and engineers to predict LLM ecosystems in a time, performance, and cost-efficient way.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript synthesizes and validates a reference architecture for LLM ecosystems under inference, introduces Kavier as a discrete-event cache-aware simulator focused on KV-caching and prompt prefix caching, and reports prototype experiments with real-world traces that measure simulator accuracy, compare KV-caching policies, and analyze performance/sustainability/efficiency under varying prefix caching policies.
Significance. If the reference architecture and simulator are shown to faithfully reproduce real LLM inference dynamics, Kavier would offer a practical tool for operators to explore design trade-offs in performance, sustainability, and cost without repeated physical deployments.
major comments (2)
- [Abstract] Abstract: the central claim that Kavier is validated and its accuracy measured via real-world traces is unsupported because the manuscript supplies no description of the validation procedure, comparison metrics, error bars, held-out testing, or quantitative results.
- [Validation and Experiments sections] Validation and Experiments sections: the fidelity of the synthesized reference architecture and the discrete-event KV-cache model to real systems is asserted without concrete evidence of calibration-free reproduction of timing, hit rates, or resource usage, which is load-bearing for all downstream claims about predictive capability.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive major comments. We agree that the validation claims require substantially more explicit description and evidence to be credible. We will revise the manuscript to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Kavier is validated and its accuracy measured via real-world traces is unsupported because the manuscript supplies no description of the validation procedure, comparison metrics, error bars, held-out testing, or quantitative results.
Authors: We agree the abstract's claim is not supported by sufficient detail in the current text. In revision we will (a) expand the abstract to avoid overclaiming and (b) add a dedicated subsection in Experiments that fully describes the validation procedure, the exact comparison metrics used, error bars or confidence intervals, any held-out testing protocol, and the quantitative accuracy results obtained against the real-world traces. revision: yes
-
Referee: [Validation and Experiments sections] Validation and Experiments sections: the fidelity of the synthesized reference architecture and the discrete-event KV-cache model to real systems is asserted without concrete evidence of calibration-free reproduction of timing, hit rates, or resource usage, which is load-bearing for all downstream claims about predictive capability.
Authors: We accept that the current manuscript asserts fidelity without presenting the required concrete evidence. In the revised version we will augment the Validation and Experiments sections with direct comparisons (timing, cache hit rates, and resource usage) between Kavier outputs and the real systems, explicitly stating whether the reproduction is calibration-free and reporting the quantitative discrepancies observed. revision: yes
Circularity Check
No significant circularity; new simulator constructed from synthesized RA and validated externally
full rationale
The paper synthesizes a reference architecture for LLM ecosystems, then builds Kavier as a discrete-event cache-aware simulator adhering to that RA, and validates accuracy against real-world traces. No equations, fitted parameters, self-citations, or ansatzes are shown that reduce any prediction or result to the inputs by construction. The central claim is the creation and evaluation of a new instrument rather than a closed derivation loop, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Early chatgpt user portrait through the lens of data,
Y. Deng, N. Zhao, and X. Huang, “Early chatgpt user portrait through the lens of data,” in2023 IEEE International Conference on Big Data (BigData), pp. 4770–4775, IEEE, 2023
2023
-
[2]
The highest number below 100 that does not contain the digit 9 is 95
L. Zheng, W.-L. Chiang, Y. Sheng, T. Li, S. Zhuang, Z. Wu, Y. Zhuang, Z. Li, Z. Lin, E. P. Xing,et al., “Lmsys-chat-1m: A large-scale real-world llm conversation dataset,”arXiv preprint arXiv:2309.11998, 2023
-
[3]
The studychat dataset: Student dialogues with chatgpt in an artificial intelligence course,
H. McNichols and A. Lan, “The studychat dataset: Student dialogues with chatgpt in an artificial intelligence course,”arXiv preprint arXiv:2503.07928, 2025. 104
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.