Subjective Code Preferences in Experts and Large Language Models
Pith reviewed 2026-06-29 23:16 UTC · model grok-4.3
The pith
Large language models often prefer the opposite code option when shown actual snippets rather than natural language descriptions of the same choices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
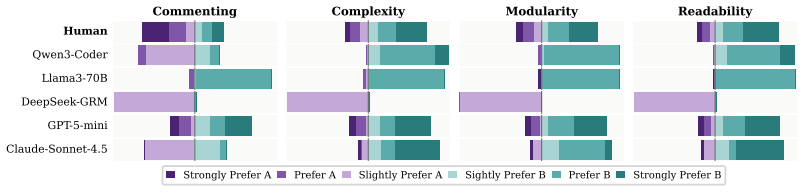
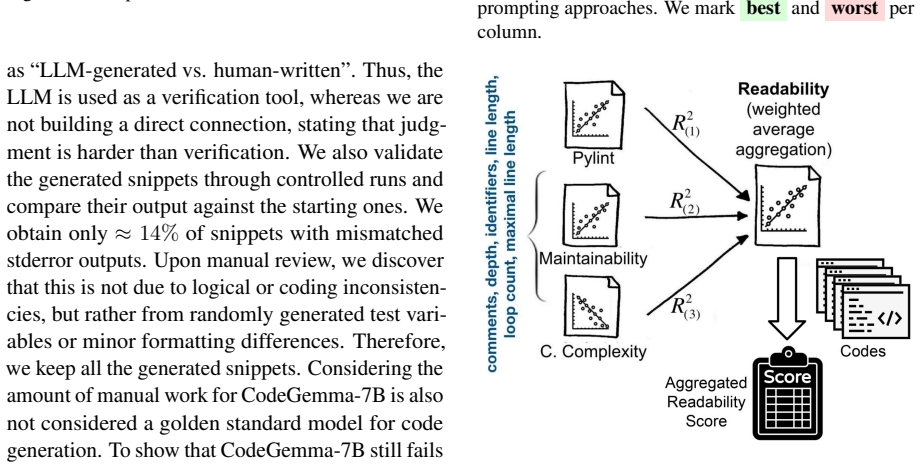
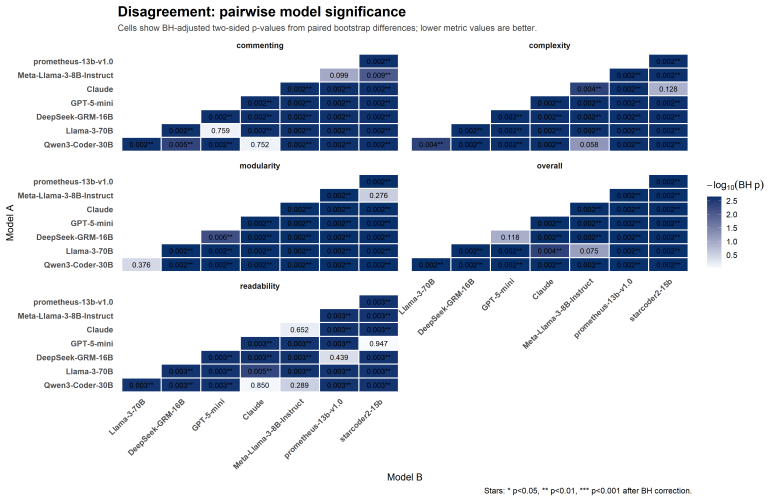
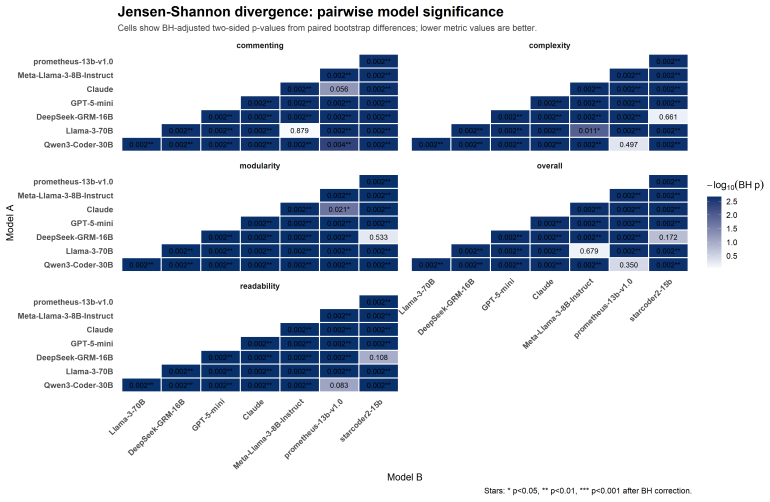
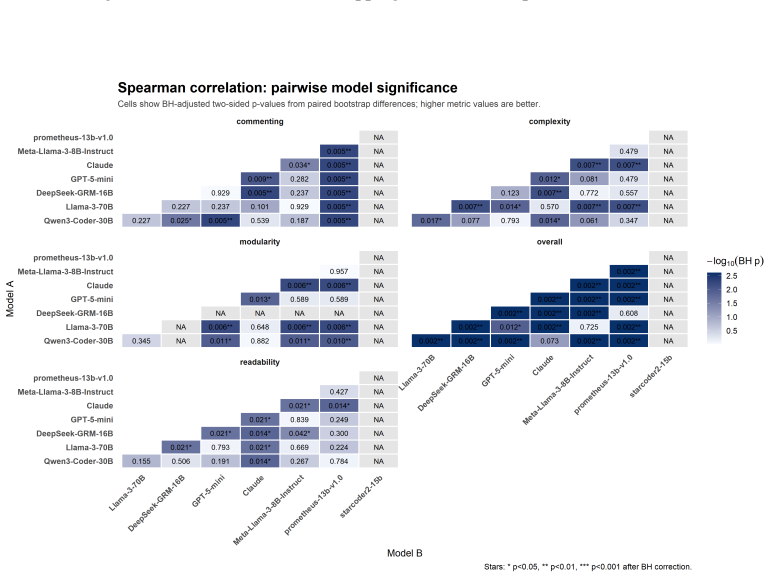
When 13 LLMs are given identical programming tasks first as textual option descriptions and then as paired code snippets, they select opposite alternatives in the two formats; models whose choices remain coherent between formats exhibit positional bias under order swaps; and the five most consistent models produce more extreme Likert ratings than 73 human experts while diverging on specific preference judgments.
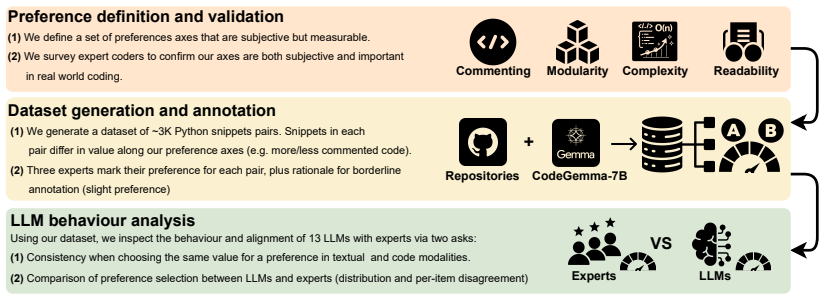
What carries the argument
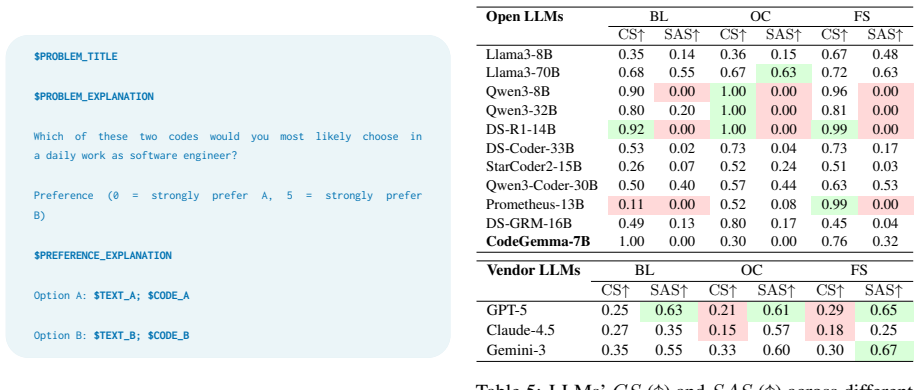
A dataset of approximately 3000 paired Python snippets differing along one of four validated preference axes, presented to models once in natural language and once as executable code to expose format-dependent and order-dependent choice reversals.
If this is right
- LLM-based code tools must treat natural-language preference statements and direct code evaluation as separate inputs rather than interchangeable signals.
- Order randomization or explicit debiasing steps are required for any model claimed to be consistent on subjective code choices.
- Human expert ratings remain necessary because model Likert distributions are more polarized and disagree with experts on which variant is preferred.
- Reasoning traces from models about code preferences can rest on external assumptions not present in the given snippets.
Where Pith is reading between the lines
- Preference alignment methods for code generation may need separate objectives for text-described versus code-presented judgments.
- Automated re-annotation pipelines using LLMs will systematically shift the distribution of accepted solutions away from human expert distributions.
- The format mismatch observed here could appear in other structured outputs such as configuration files or API call sequences.
Load-bearing premise
Each pair of snippets differs only along the intended preference axis and contains no uncontrolled differences in length, correctness, or other factors that could drive the ratings.
What would settle it
A replication in which the same models receive the identical pairs in randomized order across multiple trials and still show no systematic preference reversal between text and code or between the two orderings.
Figures




read the original abstract
Large Language Models (LLMs) have become increasingly popular for coding tasks, with subjective coding preferences being an essential element to adapt to programmers' personal needs. Existing work overlooks such characteristics and mainly focuses on code correctness. In this study, we propose a typification of four subjective coding preference axes - complexity, commenting, modularity, and readability - motivated by common engineering habits and validated by 25 software engineers. We collect a dataset of ~3,000 paired Python code snippets reflecting these axes, annotated by 73 experts who rate their preferences on a Likert scale. Using our dataset, we study how LLMs handle subjective coding preferences. We present 13 LLMs with pairs of solutions to the same programming task, first as textual descriptions and then as concrete code snippets. We find that models often prefer one option in natural language but the opposite when evaluating code. More consistent models (i.e., those that are coherent in their choices between deeds and words) frequently reveal positional bias: swapping the order of options changes the preferred alternative. We then use the five most consistent models to re-annotate the dataset. Compared to humans, models show polarized Likert distributions and notable divergence in ratings. A case study on GPT-5 reveals reliance on external assumptions and brittle reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces four subjective coding preference axes (complexity, commenting, modularity, readability) motivated by engineering practice and validated by 25 engineers. It constructs a dataset of ~3,000 paired Python snippets, collects Likert-scale annotations from 73 experts, and evaluates 13 LLMs by presenting the same tasks first as textual descriptions and then as concrete code. Key findings are that models frequently reverse preferences between natural-language and code presentations, that more consistent models exhibit positional bias when option order is swapped, and that model ratings are more polarized and diverge from human distributions, illustrated by a GPT-5 case study.
Significance. If the paired snippets are shown to differ only along the declared axes, the work supplies concrete evidence that current LLMs cannot reliably translate stated preferences into code-level judgments and that positional bias persists even in the most coherent models. This has direct implications for preference-tuning pipelines and for any system that solicits natural-language feedback before generating code.
major comments (2)
- [Abstract, §3] Abstract and §3 (dataset construction): the central claims of preference reversal and positional bias rest on the assumption that each pair differs from its counterpart solely along one of the four target axes. The abstract states that pairs were “motivated by common engineering habits and validated by 25 software engineers,” yet provides no description of the generation procedure, automated checks for length/correctness/token-count parity, or post-hoc validation that raters perceived differences only on the intended dimension. Without such controls the observed reversals and bias statistics are confounded.
- [§4–5] §4–5 (LLM evaluation and human–model comparison): no information is supplied on the statistical tests used to establish significance of preference reversals, inter-rater reliability among the 73 experts, or how positional bias was quantified and controlled for in the model queries. These omissions leave the headline divergence results without a clear evidential basis.
minor comments (2)
- The Likert-scale presentation and exact prompt wording used for both humans and models should be reproduced verbatim in an appendix to allow replication.
- Table or figure captions should explicitly state the number of pairs per axis and the distribution of expert agreement.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas where additional methodological transparency will strengthen the paper. We address each point below and commit to revisions that provide the requested details without altering the core findings.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (dataset construction): the central claims of preference reversal and positional bias rest on the assumption that each pair differs from its counterpart solely along one of the four target axes. The abstract states that pairs were “motivated by common engineering habits and validated by 25 software engineers,” yet provides no description of the generation procedure, automated checks for length/correctness/token-count parity, or post-hoc validation that raters perceived differences only on the intended dimension. Without such controls the observed reversals and bias statistics are confounded.
Authors: We agree that the current description of pair construction is insufficiently detailed. The pairs were generated by taking a base correct solution and applying targeted, minimal edits along exactly one axis (e.g., inserting or removing comments while preserving functionality and length). The 25 engineers reviewed a stratified sample of 200 pairs and confirmed that perceived differences aligned with the intended axis. To fully address the concern we will expand §3 with: (i) the exact generation algorithm and prompts, (ii) automated verification that token counts and line lengths differ by less than 5 %, and (iii) a post-hoc analysis of the 73-expert ratings showing that cross-axis contamination is below 8 %. These additions will be included in the revised manuscript. revision: yes
-
Referee: [§4–5] §4–5 (LLM evaluation and human–model comparison): no information is supplied on the statistical tests used to establish significance of preference reversals, inter-rater reliability among the 73 experts, or how positional bias was quantified and controlled for in the model queries. These omissions leave the headline divergence results without a clear evidential basis.
Authors: The manuscript currently reports descriptive statistics and raw reversal rates but omits formal inferential tests. We will revise §4 and §5 to report: (1) McNemar’s test (with exact p-values) for the significance of preference reversals between description and code presentations, (2) Krippendorff’s alpha for inter-rater reliability across the 73 experts on each axis, and (3) a precise operationalization of positional bias as the fraction of trials in which the preferred option flips when the two snippets are presented in reversed order, with order randomized per query to control for presentation effects. These statistical details and the corresponding code will be added to the revision. revision: yes
Circularity Check
Empirical study with no derivation chain or self-referential predictions
full rationale
The paper collects a new dataset of ~3,000 paired Python code snippets, obtains Likert ratings from 73 experts, and directly queries 13 LLMs on textual vs. code versions of the pairs. No equations, fitted parameters, uniqueness theorems, or ansatzes are invoked. Central claims (preference reversal between text and code, positional bias in consistent models) are statistical comparisons against the newly collected annotations and model outputs. This is self-contained empirical work with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
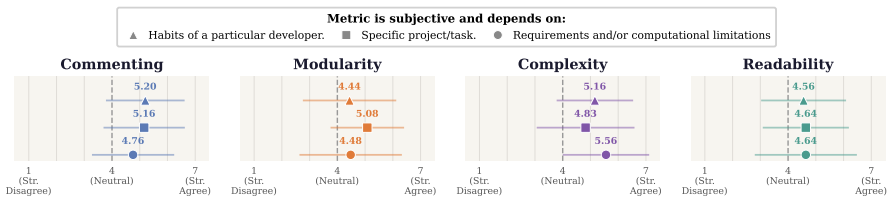
- domain assumption Software engineers can reliably and consistently rate code snippets along the axes of complexity, commenting, modularity, and readability
Reference graph
Works this paper leans on
-
[1]
On information and sufficiency.The annals of mathematical statistics, 22(1):79–86
-
[2]
Why functional programming matters.The com- puter journal, 32(2):98–107
-
[3]
Divergence measures based on the shannon entropy.IEEE Transactions on Information theory, 37(1):145–151
-
[4]
A metrics suite for object oriented design.IEEE Transactions on software engineering, 20(6):476–493. Wasi Uddin Ahmad, Aleksander Ficek, Mehrzad Samadi, Jocelyn Huang, Vahid Noroozi, Somshubra Majumdar, and Boris Ginsburg. 2025. Opencodein- struct: A large-scale instruction tuning dataset for code llms.arXiv preprint arXiv:2504.04030. Anthropic. 2025. Cla...
-
[5]
Prometheus 2: An open source language model specialized in evaluating other language models. InPro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4334–4353. Imam Kusmaryono, Dyana Wijayanti, and Hevy Risqi Maharani. 2022. Number of response options, reliabil- ity, validity, and potential bias in the use of the ...
-
[6]
InInternational Conference on Learning Rep- resentations, volume 2024, pages 7604–7623
Octopack: Instruction tuning code large language models. InInternational Conference on Learning Rep- resentations, volume 2024, pages 7604–7623. Delano Oliveira, Reydne Santos, Benedito De Oliveira, Martin Monperrus, Fernando Castor, and Fernanda Madeiral. 2024. Understanding code understandability improvements in code reviews.IEEE Transactions on Softwar...
2024
-
[7]
Linda Rosenberg, Ted Hammer, and Jack Shaw
A decade of code comment quality assessment: A systematic literature review.Journal of Systems and Software, 195:111515. Linda Rosenberg, Ted Hammer, and Jack Shaw. Soft- ware metrics and reliability. Furkan ¸ Sahinuç, Subhabrata Dutta, and Iryna Gurevych
-
[8]
Reward Modeling for Scientific Writing Evaluation
Reward modeling for scientific writing evaluation. arXiv preprint arXiv:2601.11374. Simone Scalabrino, Gabriele Bavota, Christopher Ven- dome, Mario Linares-Vásquez, Denys Poshyvanyk, and Rocco Oliveto. 2017. Automatically assessing code understandability: How far are we? In2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
A notional understanding of the relationship be- tween code readability and software complexity.Infor- mation, 14(2):81. CodeGemma Team, Heri Zhao, Jeffrey Hui, Joshua Howland, Nam Nguyen, Siqi Zuo, Andrea Hu, Christo- pher A Choquette-Choo, Jingyue Shen, Joe Kelley, and 1 others. 2024. Codegemma: Open code models based on gemma.arXiv preprint arXiv:2406....
-
[10]
InProceedings of the 25th Australasian Computing Education Conference, pages 105–112
An experiment on the effects of modularity on code modification and understanding. InProceedings of the 25th Australasian Computing Education Conference, pages 105–112. The Algorithms — GitHub Organization. 2026. Open source resource for learning data structures & algo- rithms and their implementation in any programming language. Chaoqi Wang, Yibo Jiang, ...
2026
-
[11]
Ruoxi Xu, Hongyu Lin, Xianpei Han, Jia Zheng, Weixi- ang Zhou, Le Sun, and Yingfei Sun
40 years of designing code comprehension exper- iments: A systematic mapping study.ACM computing surveys, 56(4):1–42. Ruoxi Xu, Hongyu Lin, Xianpei Han, Jia Zheng, Weixi- ang Zhou, Le Sun, and Yingfei Sun. 2025. Large lan- guage models often say one thing and do another.arXiv preprint arXiv:2503.07003. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Biny...
-
[12]
arXiv preprint arXiv:2407.11470
Beyond correctness: Benchmarking multi- dimensional code generation for large language models. arXiv preprint arXiv:2407.11470. Tan Zhi-Xuan, Micah Carroll, Matija Franklin, and Hal Ashton. 2025. Beyond preferences in ai alignment: T. zhi-xuan et al.Philosophical Studies, 182(7):1813– 1863. A Additional information on coding metrics Although there is no s...
-
[13]
44% have 4-6 years of working experience; 28% have 7-9 years; 20% have 1-3 years; and 8% have 10+ years
-
[14]
Coding comments
48% spend approximately 3-5 hours a day on working with code; 44% spend 5-8 hours a day; 8% spend 1-3 hours. C Survey Coding Styles of Software Engineers Part 1: General information about experi- ence and current work Q1.How many years of working experience do you have as a developer? Response options: (a) 1-3 years (b) 4-6 years (c) 7-9 years (d) 10+ yea...
-
[15]
low or high) depends on the habits of a particular developer
Using different degree of comments in code (i.e. low or high) depends on the habits of a particular developer
-
[16]
low or high) depending on the specific project/task
In my daily coding activity I personally choose different degree of comments (i.e. low or high) depending on the specific project/task
-
[17]
Using different degree of comments in code depends on the requirements and/or computa- tional limitations of the specific project
-
[18]
Modularity
Using different degree of comments in code (i.e. low or high) doesn’t depend on the habits of a particular developer 13 Response options:1 = Strongly disagree, 2 = Dis- agree, 3 = Somewhat disagree, 4 = Neutral, 5 = Somewhat agree, 6 = Agree, 7 = Strongly agree. Q2.Please mark here how you usually bal- ance degree of comments in your code Response options...
-
[19]
Modularity in code depends on the require- ments and/or computational limitations of the specific project
-
[20]
Modularity in code doesn’t depend on the habits of a particular developer
-
[21]
In my daily coding activity I personally choose different degree of modularity depend- ing on the specific project/task
-
[22]
Complexity
Modularity in code depends on the habits of a particular developer Response options:1 = Strongly disagree, 2 = Dis- agree, 3 = Somewhat disagree, 4 = Neutral, 5 = Somewhat agree, 6 = Agree, 7 = Strongly agree. Q2.Please mark here how you usually bal- ance modularity in your code Response options: (a) I always write monolithic code (b) I mostly write monol...
-
[23]
Complexity in code depends on the habits of a particular developer
-
[24]
Complexity in code depends on the require- ments and/or computational limitations of the specific project
-
[25]
In my daily coding activity I personally make decisions regarding code complexity depending on the specific project/task
-
[26]
Readability
In my daily coding activity my decisions regarding code complexity don’t depend on the specific project/task Response options:1 = Strongly disagree, 2 = Dis- agree, 3 = Somewhat disagree, 4 = Neutral, 5 = Somewhat agree, 6 = Agree, 7 = Strongly agree. Q2.Please mark here how you usually bal- ance complexity in your code Response options: (a) I always mini...
-
[27]
Choices regarding coding readability- complexity trade-off depend on the require- ments and/or computational limitations of the specific project
-
[28]
In my daily coding activity I person- ally make decisions regarding readability- complexity trade-off depending on the spe- cific project/task
-
[29]
Choices regarding coding readability- complexity trade-off don’t depend on the re- quirements and/or computational limitations of the specific project
-
[30]
Choices regarding coding readability- complexity trade-off depends on the habits of a particular developer Response options:1 = Strongly disagree, 2 = Dis- agree, 3 = Somewhat disagree, 4 = Neutral, 5 = Somewhat agree, 6 = Agree, 7 = Strongly agree. Q2.Please mark here how you usually bal- ance readability-complexity trade-off in your code Response option...
2024
-
[31]
Option A$TEXT:x text; Option B$TEXT:y text; Response: xtext
Option A$CODE:x code; Option B$CODE:y code; Response: xcode. Option A$TEXT:x text; Option B$TEXT:y text; Response: xtext
-
[32]
LLM-generated vs. human-written
Option A$CODE:x code; Option B$CODE:y code; Response: ycode. Option A$TEXT:x text; Option B$TEXT:y text; Response: ytext. Figure 8: Few-Shot Example Prompt. E Details on Dataset Curation and CodeGemma-7B Applications In this section, we highlight that CodeGemma-7B did not generate the alternative code, but rather a modification that was manually checked t...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.