Multithreaded Fine-Grained Asynchronous BSP for Integer Sorting with LCI and OpenMP
Pith reviewed 2026-06-29 20:59 UTC · model grok-4.3
The pith
A multithreaded fine-grained asynchronous BSP using OpenMP and LCI outperforms traditional bulk-synchronous MPI for irregular integer sorting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
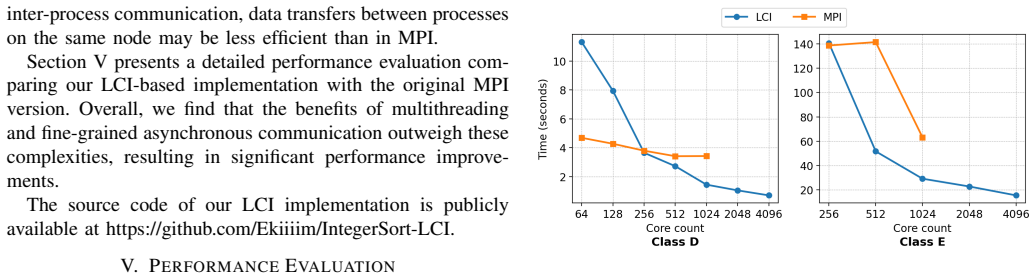
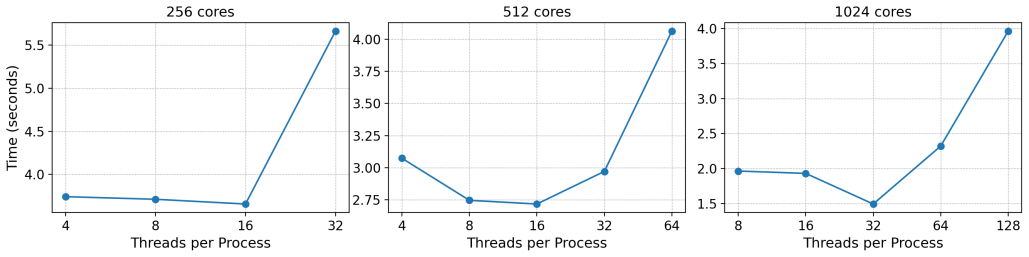
The central claim is that multithreaded FA-BSP, by replacing synchronous MPI collectives with OpenMP threads and LCI zero-copy active messages, enables efficient overlap and load balancing, significantly outperforming traditional bulk-synchronous MPI implementations on the integer sort benchmark.
What carries the argument
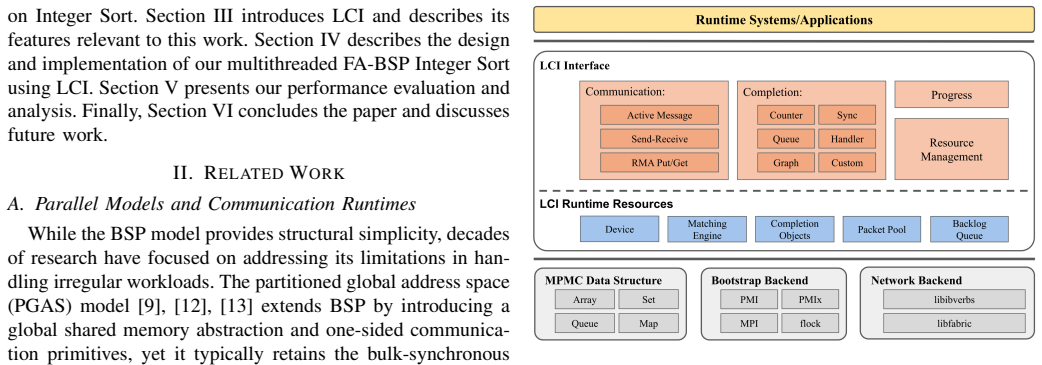
Multithreaded FA-BSP model that uses OpenMP for threading and LCI for fine-grained asynchronous active messages to replace synchronous collectives.
If this is right
- Multithreaded FA-BSP provides a scalable solution for irregular scientific applications.
- Efficient computation-communication overlap reduces idle times in unbalanced workloads.
- The approach retains the original irregular distribution to test load balancing rigorously.
- OpenMP multithreading allows full exploitation of multicore architectures beyond one-process-per-core.
Where Pith is reading between the lines
- This design might extend to other communication-heavy irregular algorithms such as graph traversals or particle simulations.
- Careful management of thread contention could be necessary when scaling to higher thread counts per core.
- Integrating this with other runtime systems could further improve performance on heterogeneous clusters.
Load-bearing premise
That introducing OpenMP threads and LCI active messages will provide overlap and balancing without adding significant new synchronization or contention overheads on multicore hardware.
What would settle it
Running the multithreaded FA-BSP and traditional MPI versions on the same multicore hardware with the NAS IS benchmark and finding no performance improvement or higher overhead in the multithreaded version.
Figures
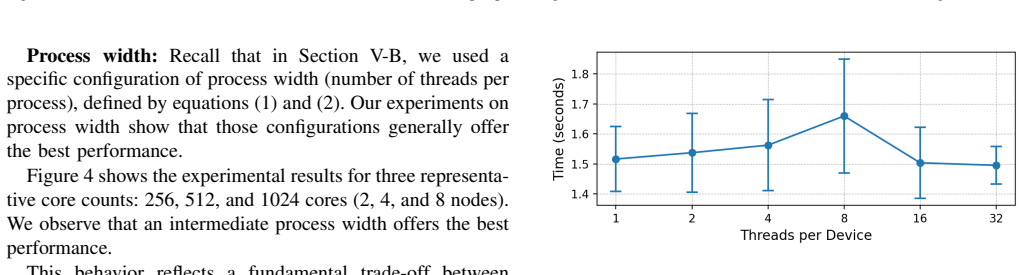
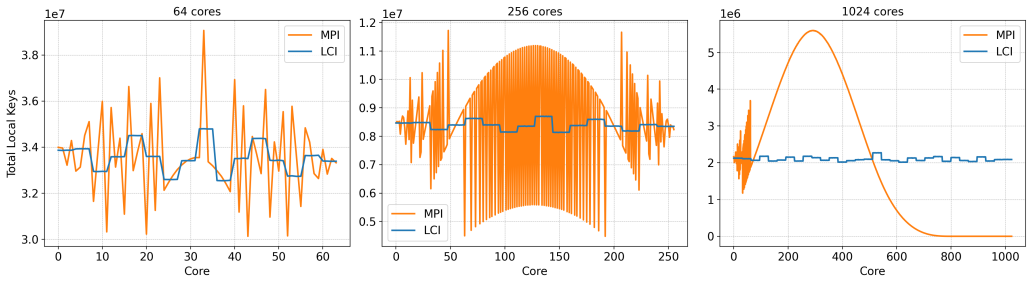
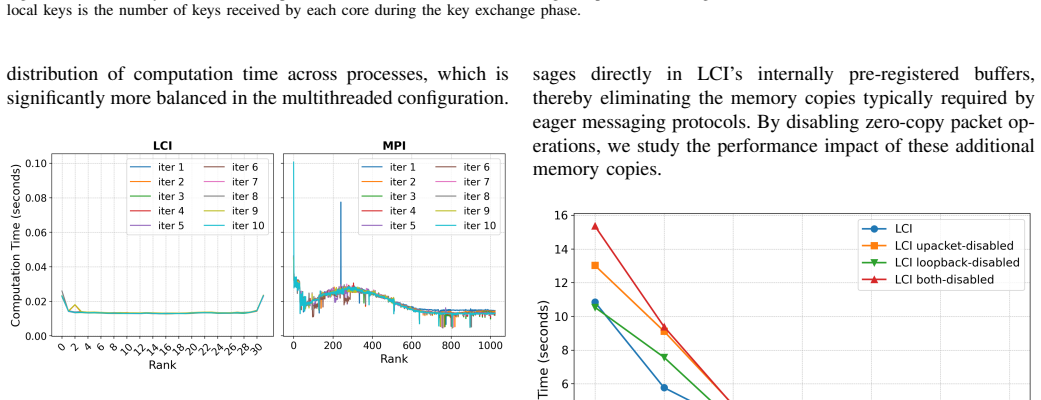
read the original abstract
The bulk synchronous parallel (BSP) model struggles with irregular workloads due to rigid global communication. While fine-grained asynchronous BSP (FA-BSP) improves overlap, existing implementations typically rely on a limiting one-process-per-core model. This paper proposes a multithreaded FA-BSP approach combining Lightweight Communication Interface (LCI) and OpenMP to fully exploit multicore architectures. We evaluate this design using the NAS Parallel Benchmark Integer Sort (IS), retaining the original irregular Gaussian distribution to rigorously test load balancing. By replacing synchronous MPI collectives with OpenMP multithreading and LCI's fine-grained, zero-copy active messages, we enable efficient computation-communication overlap. Our evaluation demonstrates that multithreaded FA-BSP significantly outperforms traditional bulk-synchronous MPI implementations, offering a scalable solution for irregular scientific applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multithreaded fine-grained asynchronous BSP (FA-BSP) that combines LCI's zero-copy active messages with OpenMP threading to replace synchronous MPI collectives, enabling better computation-communication overlap on multicore nodes for irregular workloads. It evaluates the design on the NAS IS benchmark while preserving the original Gaussian key distribution to test load balancing, and claims that this yields significant outperformance over traditional bulk-synchronous MPI implementations.
Significance. If the performance claims are substantiated with quantitative data, the work would provide a concrete demonstration of how fine-grained messaging and multithreading can improve scalability for irregular scientific codes without abandoning the BSP model. Retaining the original irregular distribution for the NAS IS tests is a positive design choice that directly addresses load-balancing concerns.
major comments (2)
- [Abstract] Abstract: the central claim that 'our evaluation demonstrates that multithreaded FA-BSP significantly outperforms traditional bulk-synchronous MPI implementations' is unsupported by any numerical results, baselines, hardware details, run counts, or error bars, which is load-bearing for the paper's main empirical contribution.
- [Proposed design] Proposed design paragraph: the assumption that OpenMP multithreading plus LCI active messages will deliver overlap 'without introducing new synchronization or contention costs' is stated but not analyzed, measured, or bounded, leaving the viability of the one-process-per-core replacement unverified.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated the scale (number of nodes/cores) at which the claimed outperformance was observed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to strengthen the empirical support and design analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'our evaluation demonstrates that multithreaded FA-BSP significantly outperforms traditional bulk-synchronous MPI implementations' is unsupported by any numerical results, baselines, hardware details, run counts, or error bars, which is load-bearing for the paper's main empirical contribution.
Authors: We agree that the abstract's performance claim requires concrete backing to be fully substantiated. In the revised version, we will augment the abstract with specific quantitative results from the NAS IS evaluations (including speedup values, hardware platform details, run counts, and error bars) drawn from the evaluation section, while preserving the original claim's scope. revision: yes
-
Referee: [Proposed design] Proposed design paragraph: the assumption that OpenMP multithreading plus LCI active messages will deliver overlap 'without introducing new synchronization or contention costs' is stated but not analyzed, measured, or bounded, leaving the viability of the one-process-per-core replacement unverified.
Authors: We acknowledge that the design description would benefit from explicit analysis of synchronization and contention. We will expand the proposed design section to include a discussion of OpenMP threading interactions with LCI active messages, along with measurements or analytical bounds on any added costs, to better verify the multithreaded approach. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical implementation and benchmark evaluation of a multithreaded FA-BSP design using LCI active messages and OpenMP on the NAS IS integer sort benchmark. No equations, parameters, or mathematical derivations appear in the provided text; the central claims rest on direct performance comparisons between the proposed approach and traditional MPI BSP. There are no self-citations, fitted inputs, or ansatzes that reduce the result to its own inputs by construction. The argument is self-contained as an engineering substitution evaluated on retained irregular workloads.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CHARM++: A portable concurrent object oriented system based on C++,
L. V . Kale and S. Krishnan, “CHARM++: A portable concurrent object oriented system based on C++,”ACM SIGPLAN Notices, vol. 28, no. 10, pp. 91–108, 1993-10-01. [Online]. Available: https://dl.acm.org/doi/10.1145/167962.165874
-
[2]
HPX - The C++ standard library for parallelism and concurrency,
H. Kaiseret al., “HPX - The C++ standard library for parallelism and concurrency,”Journal of Open Source Software, vol. 5, no. 53, p. 2352, 2020
2020
-
[3]
Legion: Expressing locality and independence with logical regions,
M. Bauer, S. Treichler, E. Slaughter, and A. Aiken, “Legion: Expressing locality and independence with logical regions,” inSC’12: Proceedings of the International Conference on High Performance Computing, Net- working, Storage and Analysis, 2012-11, pp. 1–11
2012
-
[4]
A fine-grained asynchronous bulk synchronous parallelism model for PGAS applications,
S. R. Paul, A. Hayashi, K. Chen, Y . Elmougy, and V . Sarkar, “A fine-grained asynchronous bulk synchronous parallelism model for PGAS applications,”Journal of Computational Science, vol. 69, p. 102014, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1877750323000741
2023
-
[5]
Give MPI threading a fair chance: A study of multithreaded MPI designs,
T. Patinyasakdikul, D. Eberius, G. Bosilca, and N. Hjelm, “Give MPI threading a fair chance: A study of multithreaded MPI designs,” in 2019 IEEE International Conference on Cluster Computing (CLUSTER), 2019, pp. 1–11
2019
-
[6]
Lessons learned on MPI+threads communication,
R. Zambre and A. Chandramowlishwaran, “Lessons learned on MPI+threads communication,” inProceedings of the International Con- ference on High Performance Computing, Networking, Storage and Analysis, ser. SC ’22. IEEE Press, 2022, pp. 1–16
2022
-
[7]
Examining MPI and its extensions for asynchronous multithreaded communication,
J. Yan, M. Snir, and Y . Guo, “Examining MPI and its extensions for asynchronous multithreaded communication,” inRecent Advances in the Message Passing Interface, ser. EuroMPI/USA ’25. Springer Nature Switzerland, 2025
2025
-
[8]
MPI: a message passing interface,
MPI Forum, “MPI: a message passing interface,” in1993 ACM/IEEE Conference on Supercomputing (SC93). ACM, Dec. 1993, pp. 878–883. [Online]. Available: https://dl.acm.org/doi/10.1145/169627.169855
-
[9]
Introducing OpenSHMEM: SHMEM for the PGAS community,
B. Chapman, T. Curtis, S. Pophale, S. Poole, J. Kuehn, C. Koelbel, and L. Smith, “Introducing OpenSHMEM: SHMEM for the PGAS community,” inProceedings of the Fourth Conference on Partitioned Global Address Space Programming Model, ser. PGAS ’10. New York, NY , USA: Association for Computing Machinery, 2010. [Online]. Available: https://doi.org/10.1145/2020...
-
[10]
LCI: a lightweight communication interface for efficient asynchronous multithreaded communication,
J. Yan and M. Snir, “LCI: a lightweight communication interface for efficient asynchronous multithreaded communication,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1043–1059. [Online]. Available: https://doi.o...
-
[11]
NAS parallel benchmarks,
N. P. Benchmarks, “NAS parallel benchmarks,”CG and IS, 2006
2006
-
[12]
T. El-Ghazawi and L. Smith, “UPC: Unified parallel C,” inProceedings of the 2006 ACM/IEEE Conference on Supercomputing, ser. SC ’06. New York, NY , USA: Association for Computing Machinery, 2006, p. 27–es. [Online]. Available: https://doi.org/10.1145/1188455.1188483
-
[13]
UPC++: A high- performance communication framework for asynchronous computation,
J. Bachan, S. B. Baden, S. Hofmeyr, M. Jacquelin, A. Kamil, D. Bonachea, P. H. Hargrove, and H. Ahmed, “UPC++: A high- performance communication framework for asynchronous computation,” in2019 IEEE International Parallel and Distributed Processing Sympo- sium (IPDPS), 2019, pp. 963–973
2019
-
[14]
Gluon-async: A bulk-asynchronous system for distributed and heterogeneous graph analytics,
R. Dathathri, G. Gill, L. Hoang, V . Jatala, K. Pingali, V . K. Nandivada, H.-V . Dang, and M. Snir, “Gluon-async: A bulk-asynchronous system for distributed and heterogeneous graph analytics,” in2019 28th Interna- tional Conference on Parallel Architectures and Compilation Techniques (PACT), 2019, pp. 15–28
2019
-
[15]
D. Bonachea and P. H. Hargrove, “GASNet-EX: A high-performance, portable communication library for Exascale,” inLanguages and Compilers for Parallel Computing: 31st International Workshop (LCPC 2018). Springer, 2018, pp. 138–158. [Online]. Available: https://doi.org/10.1007/978-3-030-34627-0 11
-
[16]
Understanding the communication needs of asynchronous many-task systems–a case study of HPX+LCI,
J. Yan, H. Kaiser, and M. Snir, “Understanding the communication needs of asynchronous many-task systems–a case study of HPX+LCI,”arXiv preprint arXiv:2503.12774, 2025
-
[17]
Improving the scaling of an asynchronous many-task runtime with a lightweight communication engine,
O. Mor, G. Bosilca, and M. Snir, “Improving the scaling of an asynchronous many-task runtime with a lightweight communication engine,” inProceedings of the 52nd International Conference on Parallel Processing, ser. ICPP ’23. Association for Computing Machinery, 2023, pp. 153–162. [Online]. Available: https://dl.acm.org/doi/10.1145/3605573.3605642
-
[18]
OpenSHMEM performance and potential: A NPB experimental study,
S. Pophale, R. Nanjegowda, T. Curtis, B. Chapman, H. Jin, S. Poole, and J. Kuehn, “OpenSHMEM performance and potential: A NPB experimental study,” inProceedings of the 6th Conference on Partitioned Global Address Space Programming Models (PGAS’12). Citeseer, 2012
2012
-
[19]
ISx: A scalable integer sort for co-design in the exascale era,
U. Hanebutte and J. Hemstad, “ISx: A scalable integer sort for co-design in the exascale era,” in2015 9th International Conference on Partitioned Global Address Space Programming Models, 2015, pp. 102–104
2015
-
[20]
A study of the bucket-exchange pattern in the PGAS model using the ISx integer sort mini-application,
J. Hemstad, U. R. Hanebutte, B. Harshbarger, and B. L. Chamberlain, “A study of the bucket-exchange pattern in the PGAS model using the ISx integer sort mini-application,” inPGAS Applications Workshop (PAW) at SC16, 2016
2016
-
[21]
ActorISx: Exploiting asynchrony for scalable high-performance integer sort,
Y . Elmougy, S. P. Singhal, A. Hayashi, and V . Sarkar, “ActorISx: Exploiting asynchrony for scalable high-performance integer sort,” in 2025 IEEE 25th International Symposium on Cluster, Cloud and Internet Computing Workshops (CCGridW), 2025, pp. 1–4
2025
-
[22]
NAS parallel benchmarks,
N. A. S. N. Division, “NAS parallel benchmarks,” 2026. [Online]. Available: https://www.nas.nasa.gov/software/npb.html
2026
-
[23]
Anvil - system architecture and experiences from deployment and early user operations,
X. C. Song, P. Smith, R. Kalyanam, X. Zhu, E. Adams, K. Colby, P. Finnegan, E. Gough, E. Hillery, R. Irvine, A. Maji, and J. St. John, “Anvil - system architecture and experiences from deployment and early user operations,” inPractice and Experience in Advanced Research Computing 2022: Revolutionary: Computing, Connections, You, ser. PEARC ’22. New York, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.