From Item-Only to Query-Item: Query-Conditioned Generative Search with QGS in Quark
Pith reviewed 2026-06-29 20:47 UTC · model grok-4.3
The pith
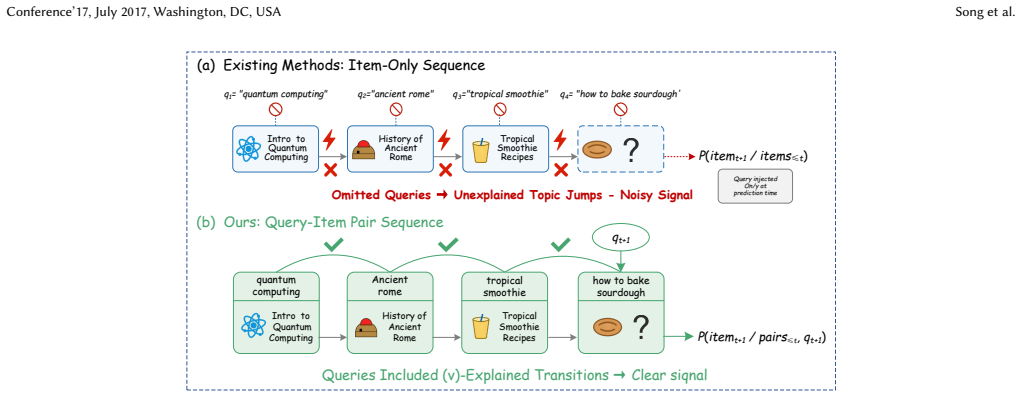
Encoding each search interaction as a query-item pair lets generative models predict the next item conditioned on the active query, removing noise from query switches in user histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
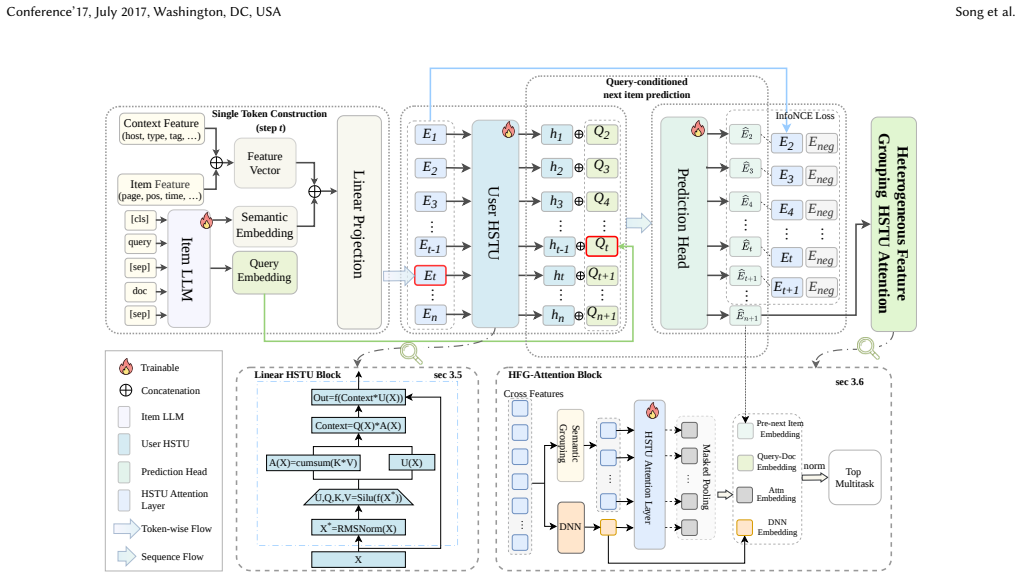
QGS encodes each interaction as a (query, item) pair token and trains with a query-conditioned next-item objective. The prediction target therefore shifts from the noisy marginal P(item_{t+1}|context_{<=t}) to the cleaner conditional P(item_{t+1}|context_{<=t}, query_{t+1}), directly removing the semantic discontinuity introduced by query switches. A Linear HSTU encoder reduces per-layer cost from quadratic to linear in sequence length, and HFG-Attention fuses heterogeneous engineered features into the same generative representation.
What carries the argument
The query-conditioned next-item objective on (query, item) pair tokens, which replaces a marginal next-item predictor with an explicit conditioning on the target query while preserving long-range history through linear recurrence.
If this is right
- Cleaner supervision targets improve ranking quality on query-driven search traffic.
- Linear recurrence removes the quadratic barrier that previously limited generative models to short histories.
- Hand-crafted features can be retained inside the generative framework rather than treated as a separate input stream.
- Production deployment produces measurable lifts in click-through rate, click-search ratio, and session duration.
Where Pith is reading between the lines
- The same conditioning trick could be tested in session-based recommendation domains that also contain abrupt topic changes.
- Linear recurrence encoders might be swapped into other attention-based ranking stacks that currently hit latency walls on long user histories.
- Explicit query tokens may reduce the amount of separate query-rewriting or intent-classification logic needed upstream of ranking.
- If query-item pairing proves stable, the approach could be extended to multi-turn conversational search where each turn supplies its own conditioning query.
Load-bearing premise
That the semantic discontinuity from query switches is the dominant source of noise in flattened sequences and that adding explicit query conditioning cleans the signal without introducing new pairing biases or alignment problems.
What would settle it
Measure ranking quality separately on segments of logs that contain query switches versus segments that do not; if the conditional model shows no relative gain on the switch segments, the central claim does not hold.
Figures
read the original abstract
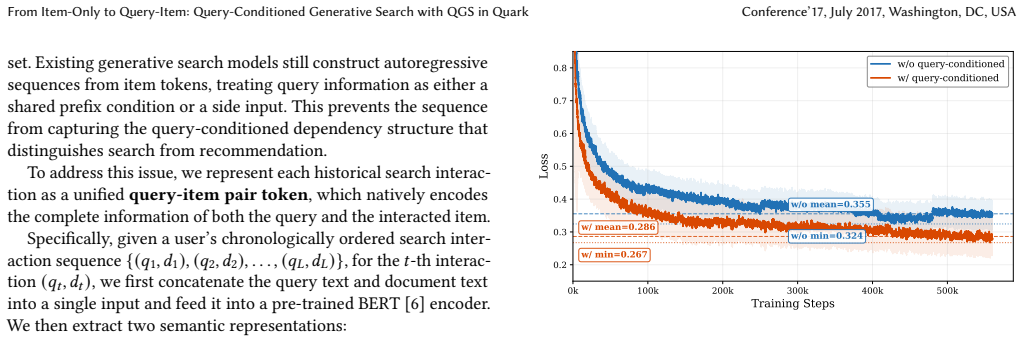
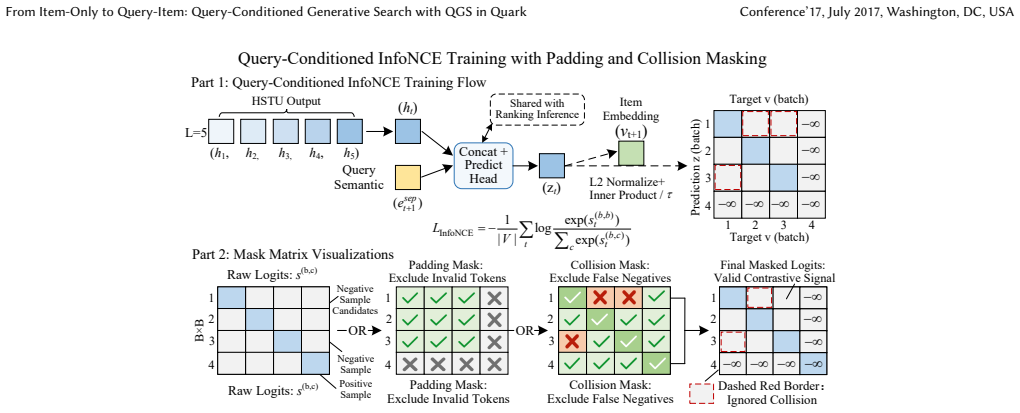
Generative sequence models have shown strong results in recommendation. Applying them to search ranking is more challenging. Search behavior is inherently query-driven. Each query switch introduces a sharp topic shift in the user's interaction history. Existing generative methods flatten queries and items into a single token sequence. They do not distinguish query boundaries. This causes the model to mix different query intents into one prediction target, resulting in noisy supervision. We present Query-Conditioned Generative Search (QGS). QGS encodes each interaction as a (query, item) pair token. It trains with a query-conditioned next-item objective. The prediction target changes from a noisy marginal P(item_{t+1}|context_{<=t}) to a clean conditional P(item_{t+1}|context_{<=t}, query_{t+1}). This directly removes the semantic discontinuity caused by query switches. Encoding long interaction histories with standard attention has quadratic cost. This is impractical under strict online latency budgets. We introduce a Linear HSTU encoder. It replaces full attention with causal linear recurrence. Per-layer complexity drops from O(L^2) to O(L) with no loss in ranking quality. Traditional search ranking depends on hand-crafted features like text-matching scores, statistical signals, and behavioral features. We propose HFG-Attention to preserve them in the generative framework. It organizes heterogeneous features into semantic groups and fuses them through a dedicated attention block. This bridges sparse engineered signals with dense sequential representations. QGS is deployed in the ranking module of Quark Search, a major commercial search engine in China. Online A/B tests show statistically significant gains: +0.62% CTR, +0.38% Click-Search Ratio, and +3.55% PV Duration over the production deep learning baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that flattening queries and items into a single token sequence in generative recommenders mixes intents across query switches, producing noisy supervision under the marginal P(item_{t+1}|context_{<=t}). QGS instead encodes each interaction as a (query, item) pair token and trains a query-conditioned objective targeting the cleaner conditional P(item_{t+1}|context_{<=t}, query_{t+1}). The manuscript also introduces a Linear HSTU encoder (O(L) causal recurrence) and HFG-Attention for heterogeneous features, and reports that the full system, deployed in Quark Search, yields statistically significant online A/B lifts (+0.62% CTR, +0.38% Click-Search Ratio, +3.55% PV Duration) over the prior production baseline.
Significance. If the query-conditioning change can be shown to deliver the claimed reduction in semantic discontinuity, the work would supply a concrete modeling adjustment for applying generative sequence models to query-driven search. The real-world deployment and online A/B results constitute a practical strength; the paper also ships an O(L) encoder that preserves ranking quality under latency constraints.
major comments (1)
- [Online A/B Tests] The central claim that the query-conditioned objective directly replaces a noisy marginal with a clean conditional (and thereby removes semantic discontinuity) is load-bearing, yet the reported online gains come from a single A/B test of the bundled system. No ablation is described that holds the Linear HSTU encoder and HFG-Attention fixed while toggling only the (query, item) pair encoding and query-conditioned loss.
minor comments (2)
- [Model Description] Dataset statistics, training details, and hyper-parameter settings for the offline experiments are not provided in the sections describing the model.
- [QGS Formulation] Notation for the tokenization of (query, item) pairs and the exact form of the query-conditioned loss should be formalized with equations rather than prose description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the value of the online deployment results. We address the concern about isolating the query-conditioned objective below.
read point-by-point responses
-
Referee: [Online A/B Tests] The central claim that the query-conditioned objective directly replaces a noisy marginal with a clean conditional (and thereby removes semantic discontinuity) is load-bearing, yet the reported online gains come from a single A/B test of the bundled system. No ablation is described that holds the Linear HSTU encoder and HFG-Attention fixed while toggling only the (query, item) pair encoding and query-conditioned loss.
Authors: We agree that the reported online A/B results reflect the full QGS system rather than an isolated change to the pair encoding and query-conditioned loss. The manuscript motivates this change as the primary mechanism for reducing semantic discontinuity, but does not include a controlled ablation that holds the Linear HSTU encoder and HFG-Attention fixed. To address this gap, we will add offline ablation experiments in the revised manuscript. These experiments will compare the original item-only generative baseline against the query-item pair encoding with the query-conditioned objective while keeping the encoder architecture and feature fusion block unchanged, using both public datasets and internal logs. This will provide direct evidence for the contribution of the modeling change. revision: yes
Circularity Check
No significant circularity; modeling choice and empirical results are self-contained
full rationale
The paper introduces a new encoding scheme and training objective as a deliberate design decision, with the change from marginal to conditional prediction target presented as a direct consequence of distinguishing query boundaries. No mathematical derivations, equations, or fitted parameters are shown that reduce to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner. Claims rest on the deployed system's A/B test outcomes rather than any self-referential fitting or renaming of known results. This is the normal case of a non-circular systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
-
[4]
Aradhye, Glenn D
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chan- dra, Hrishikesh B. Aradhye, Glenn D. Anderson, Gregory S. Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Girishkumar Shah. 2016. Wide & Deep Learning for Recommender Systems.Proceedings of the 1st Workshop on Deep Learning ...
2016
-
[5]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment.ArXivabs/2502.18965 (2025). https://api.semanticscholar.org/CorpusID:276617997
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[7]
Albert Gu and Tri Dao. 2023. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. ArXivabs/1703.04247 (2017). https://api.semanticscholar.org/CorpusID:970388
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al . 2025. Mtgr: Industrial- scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5731–5738
2025
-
[10]
Tongwen Huang, Zhiqi Zhang, and Junlin Zhang. 2019. FiBiNET: combining fea- ture importance and bilinear feature interaction for click-through rate prediction. InProceedings of the 13th ACM conference on recommender systems. 169–177
2019
-
[11]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[12]
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret
-
[13]
InInternational conference on machine learning
Transformers are rnns: Fast autoregressive transformers with linear atten- tion. InInternational conference on machine learning. PMLR, 5156–5165
- [14]
-
[15]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Leon Derczynski, et al. 2023. Rwkv: Reinventing rnns for the transformer era. InFindings of the association for computational linguistics: EMNLP 2023. 14048–14077
2023
-
[17]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
2020
-
[18]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan H Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q Tran, Jonah Saber, et al. 2023. Rec- ommender systems with generative retrieval. InAdvances in Neural Information Processing Systems, Vol. 36
2023
-
[19]
Arthur Satouf, Yuxuan Zong, Habiboulaye Amadou Boubacar, Pablo Piantanida, and Benjamin Piwowarski. 2026. QUESTER: Query Specification for Genera- tive Keyword-Based Retrieval. InFindings of the Association for Computational Linguistics: EACL 2026. 5957–5968
2026
-
[20]
Teng Shi, Jun Xu, Xiao Zhang, Xiaoxue Zang, Kai Zheng, Yang Song, and Enyun Yu. 2025. GenSAR: Unifying Balanced Search and Recommendation with Genera- tive Retrieval. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 124–134. doi:10.1145/3705328.3748071
-
[21]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self- attentive neural networks. InProceedings of the 28th ACM international conference on information and knowledge management. 1161–1170
2019
-
[22]
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jiany- ong Wang, and Furu Wei. 2023. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Yubao Tang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Shihao Liu, Shuaiqiang Wang, Dawei Yin, and Xueqi Cheng. 2025. Generative retrieval for book search. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 2606–2617
2025
-
[24]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[25]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. InProceedings of the ADKDD’17. 1–7
2017
-
[26]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the web conference 2021. 1785–1797
2021
-
[27]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, Yin-Hua Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Genera- tive Recommendations.ArXivabs/2402.17152 (2024). https://api.semanticscholar. org/CorpusID:268033327
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Biao Zhang and Rico Sennrich. 2019. Root mean square layer normalization. Advances in neural information processing systems32 (2019)
2019
-
[29]
Peitian Zhang, Zheng Liu, Yujia Zhou, Zhicheng Dou, Fangchao Liu, and Zhao Cao. 2024. Generative retrieval via term set generation. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval. 458–468
2024
-
[30]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1–14
2024
-
[31]
Guorui Zhou, Cheng-Ning Song, Xiaoqiang Zhu, Xiao Ma, Yanghui Yan, Xi- Wang Dai, Han Zhu, Junqi Jin, Han Li, and Kun Gai. 2017. Deep Interest Network for Click-Through Rate Prediction.Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining(2017). https://api.semanticscholar.org/CorpusID:1637394
2017
-
[32]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. 2025. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6309–6316
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.