Co-Designing Graph-based Approximate Nearest Neighbor Search at Billion Scale for Processing-in-Memory
Pith reviewed 2026-06-29 19:48 UTC · model grok-4.3
The pith
Co-design of compacted index layout, pipelined scheduler, and multiplication-free kernel enables efficient graph-based ANNS on PIM at billion scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
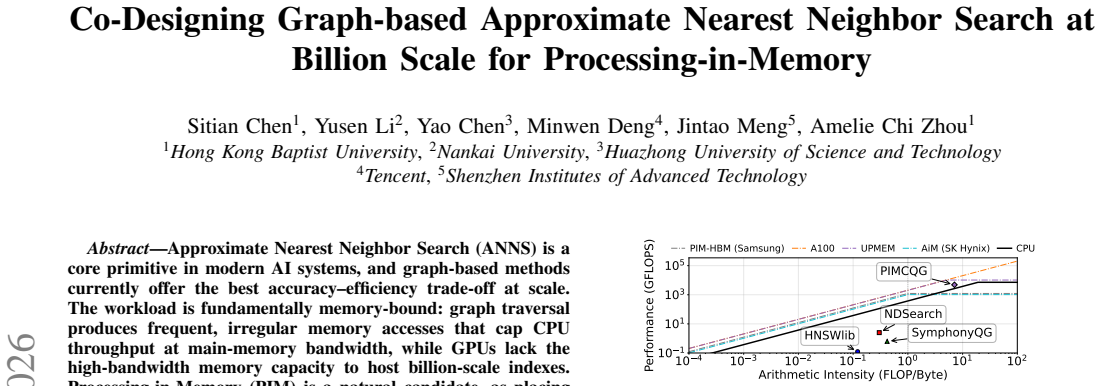
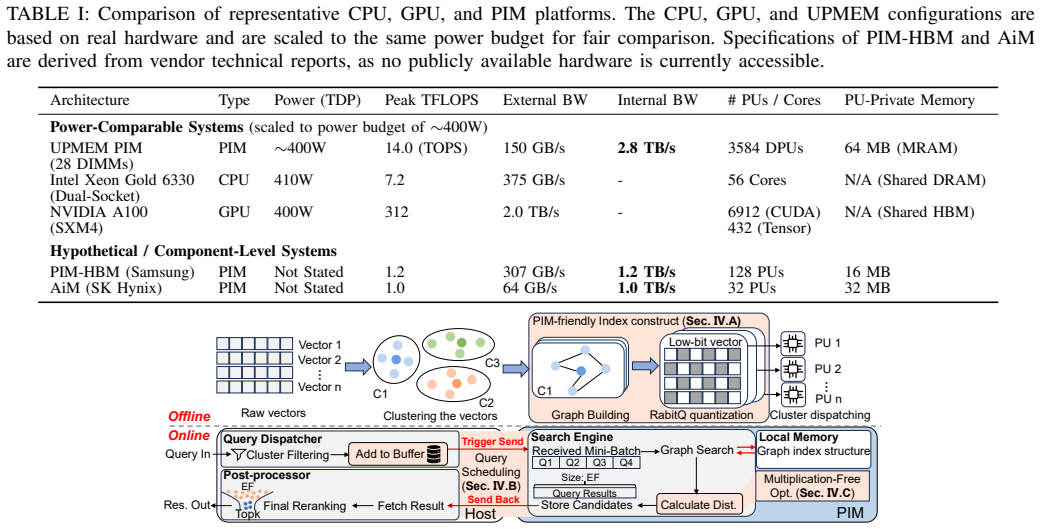
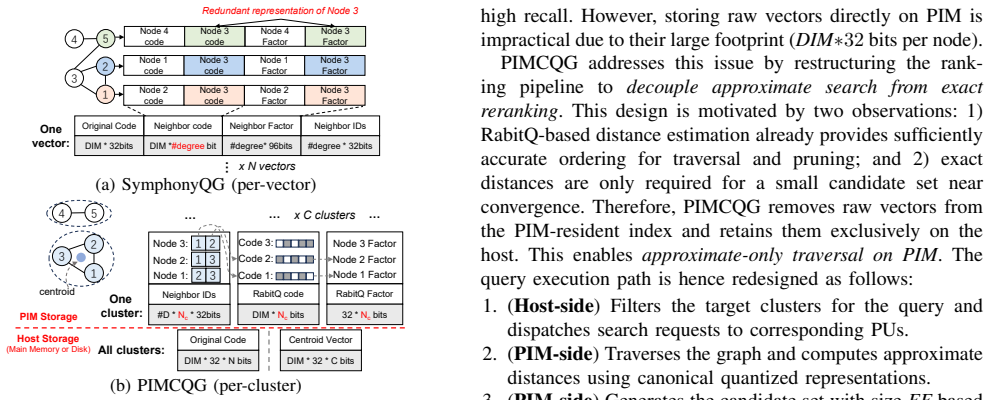
The central claim is that the three-component co-design overcomes PIM limitations of small local memories, costly inter-unit communication, host coordination overhead, and weak in-memory compute units. The compacted index layout shrinks the PIM-resident footprint by 14.5x. The asynchronous pipelined scheduler keeps the host-to-PIM interconnect saturated. The multiplication-free distance kernel loses under 0.08 percent recall. On three billion-scale benchmarks this yields up to 20x and 17.1x higher throughput than CPU and GPU baselines, 129x over prior PIM accelerators in the high-recall regime, and graceful scaling across multi-node deployments and emerging PIM architectures.
What carries the argument
The algorithm-architecture co-design of compacted index layout, asynchronous pipelined scheduler, and multiplication-free distance kernel.
If this is right
- Achieves up to 20x higher throughput than CPU baselines on billion-scale benchmarks.
- Delivers up to 17.1x higher throughput than GPU baselines.
- Outperforms prior PIM accelerators by 129x in the high-recall regime.
- Scales gracefully across multi-node deployments and emerging PIM architectures.
Where Pith is reading between the lines
- The multiplication-free kernel may reduce energy use in other memory-bound similarity tasks beyond ANNS.
- Future PIM hardware could add native support for irregular graph traversals based on the mismatches identified here.
- The compacted layout technique might extend to other graph algorithms that suffer from high memory footprint on PIM.
Load-bearing premise
The three components overcome PIM architectural mismatches of small local memory, costly communication, host overhead, and weak compute units without introducing new performance or accuracy bottlenecks.
What would settle it
Running the full design on physical PIM hardware for the three billion-scale benchmarks and measuring whether throughput reaches the reported multiples over CPU, GPU, and prior PIM baselines while recall loss stays below 0.08 percent.
Figures










read the original abstract
Approximate Nearest Neighbor Search (ANNS) is a core primitive in modern AI systems, and graph-based methods currently offer the best accuracy-efficiency trade-off at scale. The workload is fundamentally memory-bound: graph traversal produces frequent, irregular memory accesses that cap CPU throughput at main-memory bandwidth, while GPUs lack the high-bandwidth memory capacity to host billion-scale indexes. Processing-in-Memory (PIM) is a natural candidate, as placing computation next to data unlocks the abundant internal bandwidth that such bandwidth-starved workloads demand. Porting graph-based ANNS to PIM, however, exposes several architectural mismatches: each processing unit has only a small local memory, inter-unit communication is costly, host coordination adds overhead, and in-memory compute units are relatively weak -- limitations that have forced prior PIM-based ANNS designs to fall back on cluster-based indexing, whose recall ceiling is far below that of graph methods. This paper presents an algorithm-architecture co-design that overcomes these obstacles through three components: a compacted index layout that shrinks the PIM-resident memory footprint by 14.5x; an asynchronous pipelined scheduler that keeps the host-to-PIM interconnect saturated; and a multiplication-free distance kernel that loses under 0.08% recall. Across three billion-scale benchmarks, the proposed design achieves up to 20x and 17.1x higher throughput than CPU and GPU baselines, respectively, outperforms prior PIM accelerators by 129x in the high-recall regime, and scales gracefully across multi-node deployments and emerging PIM architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a co-design for graph-based ANNS on PIM at billion scale. It proposes three components to address PIM architectural mismatches: a compacted index layout that reduces the memory footprint by 14.5x, an asynchronous pipelined scheduler to keep the host-to-PIM interconnect saturated, and a multiplication-free distance kernel that incurs less than 0.08% recall loss. The design is evaluated on three billion-scale benchmarks, claiming up to 20x higher throughput than CPU baselines, 17.1x over GPU, and 129x over prior PIM accelerators in the high-recall regime, with graceful scaling in multi-node and emerging PIM setups.
Significance. If the empirical results are robust, this work is significant as it demonstrates how to adapt high-accuracy graph ANNS to PIM hardware, overcoming limitations that previously forced lower-recall cluster-based methods. The throughput gains are substantial for a memory-bound workload, and the co-design approach could influence future PIM software-hardware co-optimization for irregular access patterns in AI systems. The paper provides concrete numbers and addresses scaling, which strengthens the contribution.
minor comments (1)
- [Abstract] Abstract: The abstract states specific quantitative claims (20x, 17.1x, 129x throughput; 14.5x footprint; 0.08% recall) without referencing the corresponding evaluation sections, figures, or tables. The manuscript should cross-reference these claims to the experimental results to facilitate verification.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on co-designing graph-based ANNS for PIM at billion scale, including recognition of the 14.5x compacted index, asynchronous scheduler, and multiplication-free kernel, as well as the throughput gains and scaling results. The recommendation for minor revision is noted, and we will address any editorial or minor issues in the revised manuscript.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical hardware-software co-design for graph-based ANNS on PIM hardware. It reports measured throughput and recall numbers from three billion-scale benchmarks without any equations, derivations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs by construction. The three components (compacted index, pipelined scheduler, multiplication-free kernel) are described as engineering solutions whose performance is validated externally against CPU/GPU baselines and prior PIM designs; none of the load-bearing results are shown to be tautological or self-referential. This is the expected outcome for a systems paper whose contributions are implementation and measurement rather than mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PIM units have only small local memory, costly inter-unit communication, weak compute, and host coordination overhead that prior designs could not overcome with graph methods.
Reference graph
Works this paper leans on
-
[1]
Similarity search in the blink of an eye with compressed indices,
C. Aguerrebere, I. Bhati, M. Hildebrand, M. Tepper, and T. Willke, “Similarity search in the blink of an eye with compressed indices,”arXiv preprint arXiv:2304.04759, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.04759
-
[2]
Fafnir: Accelerating sparse gathering by using efficient near-memory intelligent reduction,
B. Asgari, R. Hadidi, J. Cao, D. E. Shim, S.-K. Lim, and H. Kim, “Fafnir: Accelerating sparse gathering by using efficient near-memory intelligent reduction,” in2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2021, pp. 908–920. [Online]. Available: https://doi.org/10.1109/HPCA51647. 2021.00080
-
[3]
Pimpam: Efficient graph pattern matching on real processing-in-memory hardware,
S. Cai, B. Tian, H. Zhang, and M. Gao, “Pimpam: Efficient graph pattern matching on real processing-in-memory hardware,”Proceedings of the ACM on Management of Data, vol. 2, no. 3, pp. 1–25, 2024. [Online]. Available: https://doi.org/10.1145/3654964
-
[4]
Drim-ann: An approximate nearest neighbor search engine based on commercial dram-pims,
M. Chen, T. Han, C. Liu, S. Liang, K. Yu, L. Dai, Z. Yuan, Y . Wang, L. Zhang, H. Liet al., “Drim-ann: An approximate nearest neighbor search engine based on commercial dram-pims,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2025, pp. 820–836. [Online]. Available: https://doi.org/10.1145...
-
[5]
Finger: Fast inference for graph-based approximate nearest neighbor search,
P. Chen, W.-C. Chang, J.-Y . Jiang, H.-F. Yu, I. Dhillon, and C.-J. Hsieh, “Finger: Fast inference for graph-based approximate nearest neighbor search,” inProceedings of the ACM Web Conference 2023, 2023, pp. 3225–3235. [Online]. Available: https://doi.org/10.1145/3543507. 3583318
-
[6]
Spann: Highly-efficient billion-scale approximate nearest neighborhood search,
Q. Chen, B. Zhao, H. Wang, M. Li, C. Liu, Z. Li, M. Yang, and J. Wang, “Spann: Highly-efficient billion-scale approximate nearest neighborhood search,”Advances in Neural Information Processing Systems, vol. 34, pp. 5199–5212, 2021. [Online]. Available: https://doi.org/10.5555/3540261.3540659
-
[7]
Approximate nearest neighbor search under neural similarity metric for large-scale recommendation,
R. Chen, B. Liu, H. Zhu, Y . Wang, Q. Li, B. Ma, Q. Hua, J. Jiang, Y . Xu, H. Denget al., “Approximate nearest neighbor search under neural similarity metric for large-scale recommendation,” in Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 2022, pp. 3013–3022. [Online]. Available: https://doi.org/10.1145/35118...
-
[8]
Upanns: Enhancing billion-scale anns efficiency with real-world pim architecture,
S. Chen, A. C. Zhou, Y . Shi, Y . Li, and X. Yao, “Upanns: Enhancing billion-scale anns efficiency with real-world pim architecture,” in SC25: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2025, pp. 1–11. [Online]. Available: https://doi.org/10.1145/3712285.3759777
-
[9]
{PIMLex}: A {High-Performance}learned index with{Processing-in-Memory},
L. Cui, K. Yang, Y . Li, G. Wang, and X. Liu, “{PIMLex}: A {High-Performance}learned index with{Processing-in-Memory},” in 23rd USENIX Conference on File and Storage Technologies (FAST 25), 2025, pp. 287–303. [Online]. Available: https://www.usenix.org/ conference/fast25/presentation/cui
2025
-
[10]
The true processing in memory accelerator,
F. Devaux, “The true processing in memory accelerator,” in2019 IEEE Hot Chips 31 Symposium (HCS). IEEE Computer Society, 2019, pp. 1–24. [Online]. Available: https://doi.org/10.1109/HOTCHIPS.2019. 8875680
-
[11]
The journey to a knowledgeable assistant with retrieval-augmented generation (rag),
X. L. Dong, “The journey to a knowledgeable assistant with retrieval-augmented generation (rag),” inProceedings of the 17th ACM International Conference on Web Search and Data Mining, 2024, pp. 4–4. [Online]. Available: https://doi.org/10.1145/3616855.3638207
-
[12]
Facebook SimSearchNet++,
Facebook, “Facebook SimSearchNet++,” https://dl.fbaipublicfiles.com/ billion-scale-ann-benchmarks/FB ssnpp database.u8bin, 2026
2026
-
[13]
Facebook AI Research, “Faiss,” https://github.com/facebookresearch/ faiss
-
[14]
C. Fu, C. Wang, and D. Cai, “High dimensional similarity search with satellite system graph: Efficiency, scalability, and unindexed query compatibility,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 8, pp. 4139–4150, 2021. [Online]. Available: https://doi.org/10.1109/TPAMI.2021.3067706
-
[15]
Fast approximate nearest neighbor search with the navigating spreading-out graph,
C. Fu, C. Xiang, C. Wang, and D. Cai, “Fast approximate nearest neighbor search with the navigating spreading-out graph,” arXiv preprint arXiv:1707.00143, 2017. [Online]. Available: https: //doi.org/10.48550/arXiv.1707.00143
-
[16]
J. Gao and C. Long, “Rabitq: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search,” Proceedings of the ACM on Management of Data, vol. 2, no. 3, pp. 1–27, 2024. [Online]. Available: https://doi.org/10.1145/3654970
-
[17]
J. G ´omez-Luna, I. El Hajj, I. Fernandez, C. Giannoula, G. F. Oliveira, and O. Mutlu, “Benchmarking a new paradigm: Experimental analysis and characterization of a real processing-in-memory system,” IEEE Access, vol. 10, pp. 52 565–52 608, 2022. [Online]. Available: https://doi.org/10.1109/ACCESS.2022.3174101
-
[18]
idec: indexable distance estimating codes for approximate nearest neighbor search,
L. Gong, H. Wang, M. Ogihara, and J. Xu, “idec: indexable distance estimating codes for approximate nearest neighbor search,”Proceedings of the VLDB Endowment, vol. 13, no. 9, 2020. [Online]. Available: https://doi.org/10.14778/3397230.3397243
-
[19]
Y . Gou, J. Gao, Y . Xu, and C. Long, “Symphonyqg: Towards symphonious integration of quantization and graph for approximate nearest neighbor search,”Proceedings of the ACM on Management of Data, vol. 3, no. 1, pp. 1–26, 2025. [Online]. Available: https://doi.org/10.1145/3709730
-
[20]
Ggnn: Graph-based gpu nearest neighbor search,
F. Groh, L. Ruppert, P. Wieschollek, and H. P. Lensch, “Ggnn: Graph-based gpu nearest neighbor search,”IEEE Transactions on Big Data, vol. 9, no. 01, pp. 267–279, 2023. [Online]. Available: https://doi.org/10.1109/TBDATA.2022.3161156
-
[21]
Pim is all you need: A cxl-enabled gpu-free system for large language model inference,
Y . Gu, A. Khadem, S. Umesh, N. Liang, X. Servot, O. Mutlu, R. Iyer, and R. Das, “Pim is all you need: A cxl-enabled gpu-free system for large language model inference,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2025, pp. 862–881. [Online]. Available: https://...
-
[22]
INRIA, “SIFT1B,” http://corpus-texmex.irisa.fr/, 2026
2026
-
[23]
{CXL- ANNS}:{Software-Hardware}collaborative memory disaggregation and computation for{Billion-Scale}approximate nearest neighbor search,
J. Jang, H. Choi, H. Bae, S. Lee, M. Kwon, and M. Jung, “{CXL- ANNS}:{Software-Hardware}collaborative memory disaggregation and computation for{Billion-Scale}approximate nearest neighbor search,” in2023 USENIX Annual Technical Conference (USENIX ATC 23), 2023, pp. 585–600. [Online]. Available: https://www.usenix.org/ conference/atc23/presentation/jang
2023
-
[24]
Diskann: Fast accurate billion-point nearest neighbor search on a single node,
S. Jayaram Subramanya, F. Devvrit, H. V . Simhadri, R. Krishnawamy, and R. Kadekodi, “Diskann: Fast accurate billion-point nearest neighbor search on a single node,”Advances in neural information processing Systems, vol. 32, 2019. [Online]. Available: https: //dl.acm.org/doi/abs/10.5555/3454287.3455520
-
[25]
Co- design hardware and algorithm for vector search,
W. Jiang, S. Li, Y . Zhu, J. de Fine Licht, Z. He, R. Shi, C. Renggli, S. Zhang, T. Rekatsinas, T. Hoefleret al., “Co- design hardware and algorithm for vector search,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2023, pp. 1–15. [Online]. Available: https://doi.org/10.1145/3581784.3607045
-
[26]
Near-memory processing in action: Accelerating personalized recommendation with axdimm,
L. Ke, X. Zhang, J. So, J.-G. Lee, S.-H. Kang, S. Lee, S. Han, Y . Cho, J. H. Kim, Y . Kwonet al., “Near-memory processing in action: Accelerating personalized recommendation with axdimm,” IEEE Micro, vol. 42, no. 1, pp. 116–127, 2021. [Online]. Available: https://doi.org/10.1109/MM.2021.3097700
-
[27]
Bang: Billion-scale approximate nearest neighbor search using a single gpu,
S. Khan, S. Singh, H. V . Simhadri, J. Veduradaet al., “Bang: Billion-scale approximate nearest neighbor search using a single gpu,”arXiv preprint arXiv:2401.11324, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.11324
-
[28]
Accelerating large- scale graph-based nearest neighbor search on a computational storage platform,
J.-H. Kim, Y .-R. Park, J. Do, S.-Y . Ji, and J.-Y . Kim, “Accelerating large- scale graph-based nearest neighbor search on a computational storage platform,”IEEE Transactions on Computers, vol. 72, no. 1, pp. 278–290,
-
[29]
Available: https://doi.org/10.1109/TC.2022.3155956
[Online]. Available: https://doi.org/10.1109/TC.2022.3155956
-
[30]
{PathWeaver}: A{High-Throughput}{Multi-GPU}system for{Graph-Based}approximate nearest neighbor search,
S. Kim, S. Park, S. U. Noh, J. Hong, T. Kwon, H. Lim, and J. Lee, “{PathWeaver}: A{High-Throughput}{Multi-GPU}system for{Graph-Based}approximate nearest neighbor search,” in2025 USENIX Annual Technical Conference (USENIX ATC 25), 2025, pp. 1501–1517. [Online]. Available: https://www.usenix.org/conference/ atc25/presentation/kim
2025
-
[31]
Cosmos: A cxl-based full in-memory system for approximate nearest neighbor search,
S. Ko, H. Shim, W. Doh, S. Yun, J. So, Y . Kwon, S.-S. Park, S.-D. Roh, M. Yoon, T. Songet al., “Cosmos: A cxl-based full in-memory system for approximate nearest neighbor search,” IEEE Computer Architecture Letters, 2025. [Online]. Available: https://doi.org/10.1109/LCA.2025.3570235 11
-
[32]
Pimbeam: Efficient regular path queries over graph database using processing-in-memory,
W. Kong, S. Zheng, Y . Hua, R. Ma, Y . Wen, G. Wang, C. Zhou, and L. Huang, “Pimbeam: Efficient regular path queries over graph database using processing-in-memory,”IEEE Transactions on Parallel and Distributed Systems, 2025. [Online]. Available: https://doi.org/10.1109/TPDS.2025.3547365
-
[33]
System architecture and software stack for gddr6-aim,
Y . Kwon, K. Vladimir, N. Kim, W. Shin, J. Won, M. Lee, H. Joo, H. Choi, G. Kim, B. Anet al., “System architecture and software stack for gddr6-aim,” in2022 IEEE Hot Chips 34 Symposium (HCS). IEEE, 2022, pp. 1–25. [Online]. Available: https://doi.org/10.1109/HCS55958.2022.9895629
-
[34]
Y .-C. Kwon, S. H. Lee, J. Lee, S.-H. Kwon, J. M. Ryu, J.-P. Son, O. Seongil, H.-S. Yu, H. Lee, S. Y . Kimet al., “25.4 a 20nm 6gb function-in-memory dram, based on hbm2 with a 1.2 tflops programmable computing unit using bank-level parallelism, for machine learning applications,” in2021 IEEE International Solid-State Circuits Conference (ISSCC), vol. 64....
-
[35]
Cost- effective llm accelerator using processing in memory technology,
H. Lee, G. Kim, D. Yun, I. Kim, Y . Kwon, and E. Lim, “Cost- effective llm accelerator using processing in memory technology,” in2024 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). IEEE, 2024, pp. 1–2. [Online]. Available: https://doi.org/10.1109/VLSITechnologyandCir46783.2024.10631397
work page doi:10.1109/vlsitechnologyandcir46783.2024.10631397 2024
-
[36]
Hnswlib - fast approximate nearest neighbor search
Leonid Boytsov Yury Malkov., “Hnswlib - fast approximate nearest neighbor search.” https://github.com/nmslib/hnswlib
-
[37]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474,
-
[38]
Available: https://proceedings.neurips.cc/paper files/ paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
2020
-
[39]
C. Li, Z. Zhou, Y . Wang, F. Yang, T. Cao, M. Yang, Y . Liang, and G. Sun, “Pim-dl: Expanding the applicability of commodity dram-pims for deep learning via algorithm-system co-optimization,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2024, pp. 879–896. [Online...
-
[40]
Scalable graph indexing using gpus for approximate nearest neighbor search,
Z. Li, X. Ke, Y . Zhu, B. Yu, B. Zheng, and Y . Gao, “Scalable graph indexing using gpus for approximate nearest neighbor search,” Proceedings of the ACM on Management of Data, vol. 3, no. 6, pp. 1–27, 2025. [Online]. Available: https://doi.org/10.1145/3769825
-
[41]
Vstore: in-storage graph based vector search accelerator,
S. Liang, Y . Wang, Z. Yuan, C. Liu, H. Li, and X. Li, “Vstore: in-storage graph based vector search accelerator,” inProceedings of the 59th ACM/IEEE Design Automation Conference, 2022, pp. 997–1002. [Online]. Available: https://doi.org/10.1145/3489517.3530560
-
[42]
Heterrag: Heterogeneous processing-in-memory acceleration for retrieval-augmented generation,
C. Liu, H. Liu, D. Chen, Y . Huang, Y . Zhang, W. Xiao, X. Liao, and H. Jin, “Heterrag: Heterogeneous processing-in-memory acceleration for retrieval-augmented generation,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 884–898. [Online]. Available: https://doi.org/10.1145/3695053.3731089
-
[43]
Accelerating personalized recommendation with cross-level near-memory processing,
H. Liu, L. Zheng, Y . Huang, C. Liu, X. Ye, J. Yuan, X. Liao, H. Jin, and J. Xue, “Accelerating personalized recommendation with cross-level near-memory processing,” inProceedings of the 50th Annual International Symposium on Computer Architecture, 2023, pp. 1–13. [Online]. Available: https://doi.org/10.1145/3579371.3589101
-
[44]
Z. Liu, W. Ni, J. Leng, Y . Feng, C. Guo, Q. Chen, C. Li, M. Guo, and Y . Zhu, “Juno: optimizing high-dimensional approximate nearest neighbour search with sparsity-aware algorithm and ray-tracing core mapping,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2024, ...
-
[45]
Y . A. Malkov and D. A. Yashunin, “Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs,”IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 4, pp. 824–836, 2018. [Online]. Available: https: //doi.org/10.1109/TPAMI.2018.2889473
-
[46]
SPACEV1B,
Microsoft, “SPACEV1B,” https://github.com/microsoft/SPTAG/tree/ main/datasets/SPACEV1B, 2026
2026
-
[47]
InIEEE 40th International Conference on Data Engineering
H. Ootomo, A. Naruse, C. Nolet, R. Wang, T. Feher, and Y . Wang, “Cagra: Highly parallel graph construction and approximate nearest neighbor search for gpus,” in2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 2024, pp. 4236–4247. [Online]. Available: https://doi.org/10.1109/icde60146.2024.00323
-
[48]
Pim-ai: A novel architecture for high-efficiency llm inference,
C. Ortega, Y . Falevoz, and R. Ayrignac, “Pim-ai: A novel architecture for high-efficiency llm inference,”arXiv preprint arXiv:2411.17309,
-
[49]
Pim-ai: A novel architecture for high-efficiency llm inference,
[Online]. Available: https://doi.org/10.48550/arXiv.2411.17309
-
[50]
PIM-HBM,
Samsung, “PIM-HBM,” https://github.com/SAITPublic/PIMSimulator
-
[51]
Gpu-native approximate nearest neighbor search with ivf-rabitq: Fast index build and search,
J. Shi, J. Gao, J. Xia, T. B. Feh ´er, and C. Long, “Gpu-native approximate nearest neighbor search with ivf-rabitq: Fast index build and search,”arXiv preprint arXiv:2602.23999, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2602.23999
-
[52]
SK Hynix, “AiM,” https://github.com/arkhadem/aim simulator
-
[53]
An efficient fpga implementation of approximate nearest neighbor search,
Y . Song, C. Liu, R. Zhang, D. Zhu, and Z. Wang, “An efficient fpga implementation of approximate nearest neighbor search,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2025. [Online]. Available: https://doi.org/10.1109/TVLSI.2025.3544342
-
[54]
Scalable billion-point approximate nearest neighbor search using {SmartSSDs},
B. Tian, H. Liu, Z. Duan, X. Liao, H. Jin, and Y . Zhang, “Scalable billion-point approximate nearest neighbor search using {SmartSSDs},” in2024 USENIX Annual Technical Conference (USENIX ATC 24), 2024, pp. 1135–1150. [Online]. Available: https://www.usenix.org/conference/atc24/presentation/tian
2024
-
[55]
B. Tian, H. Liu, Y . Tang, S. Xiao, Z. Duan, X. Liao, X. Zhang, J. Zhu, and Y . Zhang, “Fusionanns: An efficient cpu/gpu cooperative processing architecture for billion-scale approximate nearest neighbor search,”arXiv preprint arXiv:2409.16576, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2409.16576
-
[56]
Recommendation of food items for thyroid patients using content-based knn method,
V . S. Vairale and S. Shukla, “Recommendation of food items for thyroid patients using content-based knn method,” inData Science and Security: Proceedings of IDSCS 2020. Springer, 2020, pp. 71–77. [Online]. Available: https://doi.org/10.1007/978-981-15-5309-7 8
-
[57]
Accelerating graph indexing for anns on modern cpus,
M. Wang, H. Wu, X. Ke, Y . Gao, Y . Zhu, and W. Zhou, “Accelerating graph indexing for anns on modern cpus,”Proceedings of the ACM on Management of Data, vol. 3, no. 3, pp. 1–29, 2025. [Online]. Available: https://doi.org/10.1145/3725260
-
[58]
Y . Wang, S. Li, Q. Zheng, A. Chang, H. Li, and Y . Chen, “Ems-i: An efficient memory system design with specialized caching mechanism for recommendation inference,”ACM Transactions on Embedded Computing Systems, vol. 22, no. 5s, pp. 1–22, 2023. [Online]. Available: https://doi.org/10.1145/3609384
-
[59]
Y . Wang, S. Li, Q. Zheng, L. Song, Z. Li, A. Chang, Y . Chen et al., “Ndsearch: Accelerating graph-traversal-based approximate nearest neighbor search through near data processing,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 368–381. [Online]. Available: https://doi.org/10.1109/ISCA59077.2024.00035
-
[60]
Turbocharge{ANNS}on real{Processing-in-Memory} by enabling{Fine-Grained}{Per-PIM-Core}scheduling,
P. Wu, M. Xie, E. Zhao, D. Zhang, J. Wang, X. Liang, K. Ren, and Y . Chai, “Turbocharge{ANNS}on real{Processing-in-Memory} by enabling{Fine-Grained}{Per-PIM-Core}scheduling,” in2025 USENIX Annual Technical Conference (USENIX ATC 25), 2025, pp. 1223–1241. [Online]. Available: https://www.usenix.org/conference/ atc25/presentation/wu-puqing
2025
-
[61]
Proxima: Near-storage acceleration for graph-based approximate nearest neighbor search in 3d nand,
W. Xu, J. Chen, P.-K. Hsu, J. Kang, M. Zhou, S. Pinge, S. Yu, and T. Rosing, “Proxima: Near-storage acceleration for graph-based approximate nearest neighbor search in 3d nand,” IEEE Transactions on Computers, 2026. [Online]. Available: http: //doi.org/10.1109/tc.2026.3671718
-
[62]
Neighborhood Graph and Tree for Indexing High- dimensional Data
Yahoo Japan, “Neighborhood Graph and Tree for Indexing High- dimensional Data.” https://github.com/yahoojapan/NGT
-
[63]
S. Zeng, Z. Zhu, J. Liu, H. Zhang, G. Dai, Z. Zhou, S. Li, X. Ning, Y . Xie, H. Yanget al., “Df-gas: A distributed fpga-as-a-service architecture towards billion-scale graph-based approximate nearest neighbor search,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, 2023, pp. 283–296. [Online]. Available: https://doi...
-
[64]
Nl-dpe: An analog in-memory non-linear dot product engine for efficient cnn and llm inference,
L. Zhao, L. Buonanno, A. Gajjar, J. Moon, A. Natarajan, S. Serebryakov, R. M. Roth, X. Sheng, Y . Zhang, P. Faraboschiet al., “Nl-dpe: An analog in-memory non-linear dot product engine for efficient cnn and llm inference,”arXiv preprint arXiv:2511.13950, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2511.13950
-
[65]
Lazylsh: Approximate nearest neighbor search for multiple distance functions with a single index,
Y . Zheng, Q. Guo, A. K. Tung, and S. Wu, “Lazylsh: Approximate nearest neighbor search for multiple distance functions with a single index,” inProceedings of the 2016 International Conference on Management of Data, 2016, pp. 2023–2037. [Online]. Available: https://doi.org/10.1145/2882903.2882930
-
[66]
Z. Zhu, J. Liu, G. Dai, S. Zeng, B. Li, H. Yang, and Y . Wang, “Processing-in-hierarchical-memory architecture for billion- scale approximate nearest neighbor search,” in2023 60th ACM/IEEE 12 Design Automation Conference (DAC). IEEE, 2023, pp. 1–6. [Online]. Available: https://doi.org/10.1109/DAC56929.2023.10247946
-
[67]
Pyglass - Graph Library for Approximate Similarity Search
Zilliz, “Pyglass - Graph Library for Approximate Similarity Search.” https://github.com/zilliztech/pyglass. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.