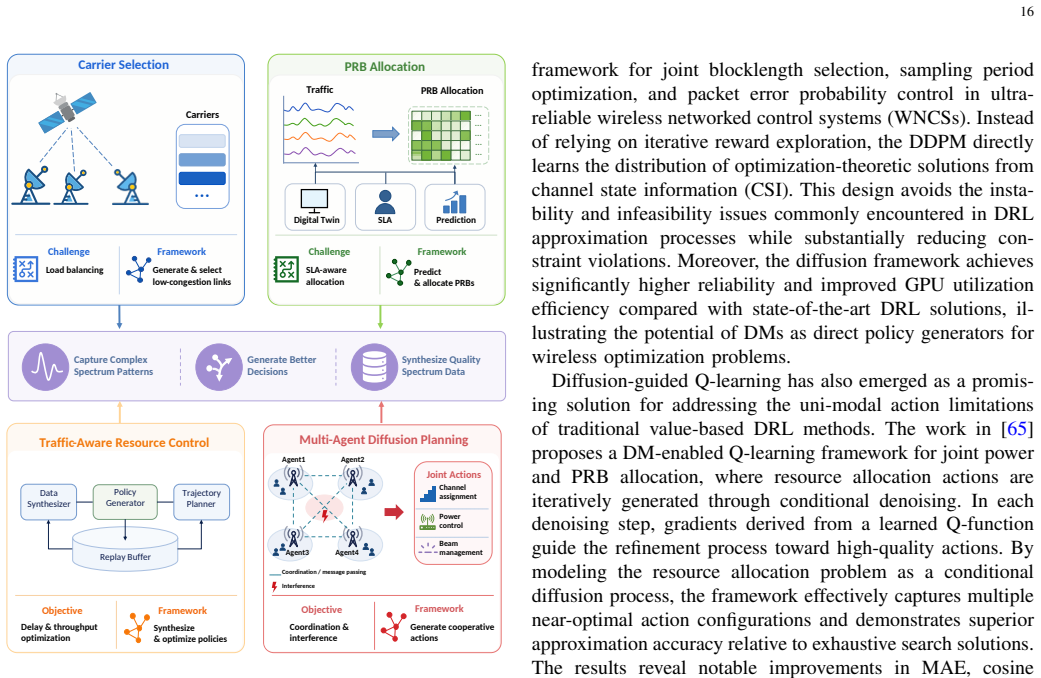
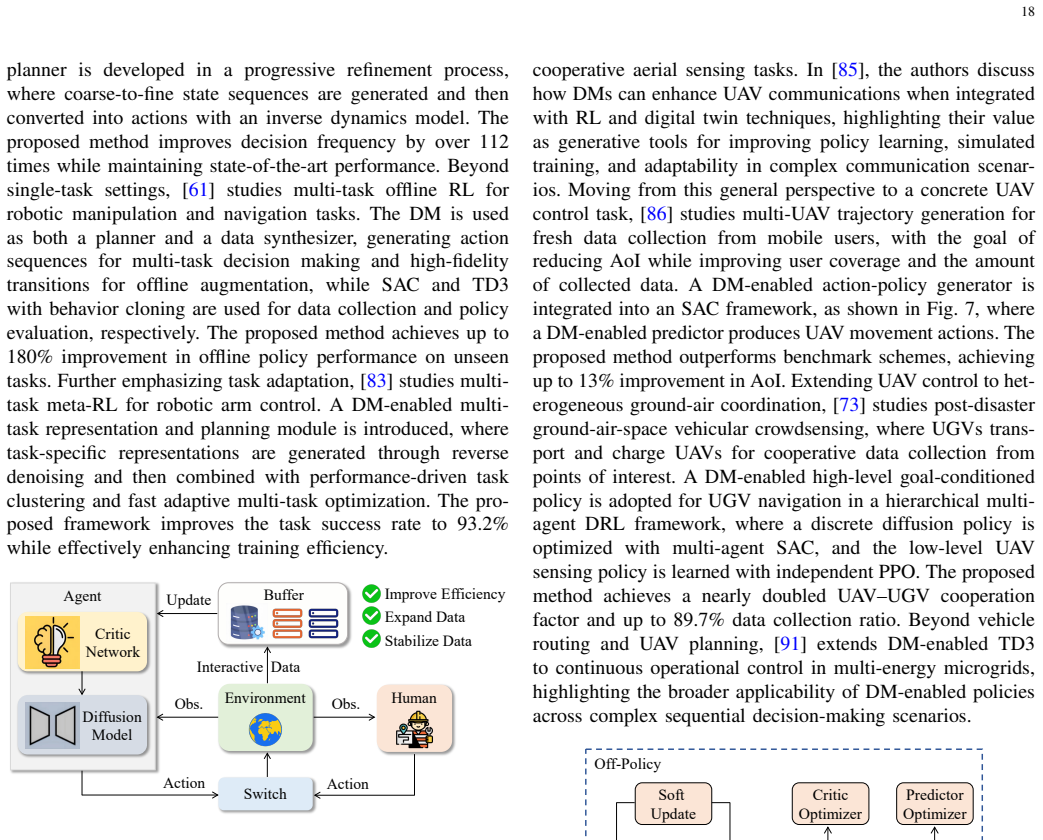
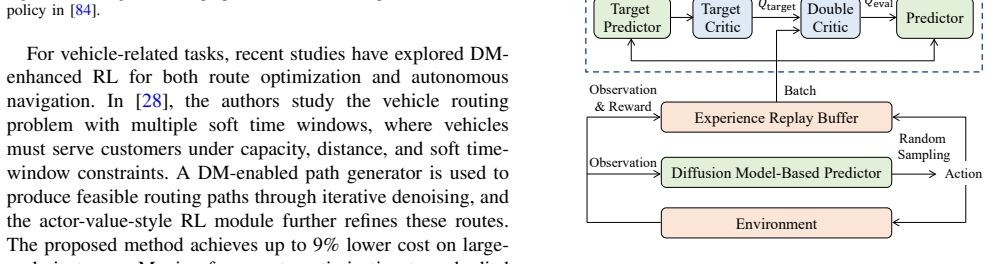
From Denoising to Decision Making: A Survey on Diffusion Model-Enabled Deep Reinforcement Learning for Wireless Networks
Pith reviewed 2026-06-29 20:47 UTC · model grok-4.3
The pith
Diffusion models integrated with deep reinforcement learning capture multimodal action structures to improve wireless resource management decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The integration of diffusion models and deep reinforcement learning opens a new research direction in which DM-enabled policies substantially enhance decision quality by capturing the complex, discontinuous, and multimodal action structures inherent in wireless resource management.
What carries the argument
DM-enabled DRL policies that generate actions via a denoising process to represent multimodal distributions instead of unimodal ones.
If this is right
- DM-DRL algorithms can be applied to computation offloading in mobile edge computing systems to handle heterogeneous user demands.
- UAV-assisted and vehicular networks gain improved adaptability through policies that explore multimodal action spaces.
- Wireless resource allocation and physical-layer security problems benefit from better modeling of discontinuous decision boundaries.
- AIGC-driven systems and robotics planning tasks see enhanced performance from generative action sampling.
Where Pith is reading between the lines
- Scalability of the denoising process may need approximation techniques for real-time wireless control loops.
- Similar multimodal policy benefits could appear in other sequential decision domains such as power systems or autonomous driving.
- Hybrid training that combines DMs with existing DRL exploration bonuses might reduce sample complexity further.
Load-bearing premise
Conventional DRL methods are fundamentally limited by unimodal policies and inefficient exploration, and diffusion models can reliably overcome these limitations in wireless settings.
What would settle it
A head-to-head empirical comparison in which standard DRL methods match or exceed DM-enabled variants on wireless tasks such as resource allocation or offloading while using less computation.
Figures
read the original abstract
Deep reinforcement learning (DRL) has long been a promising solution for sequential resource management in wireless networks. However, conventional DRL methods are fundamentally limited by their reliance on unimodal policy distributions, inefficient exploration in high-dimensional action spaces, and poor adaptability to dynamic and heterogeneous environments. Meanwhile, diffusion models (DMs) as one of the most powerful families of generative AI have demonstrted remarkable capabilities in modeling complex, multi-modal data distributions across diverse domains. The integration of DMs and DRL has opened a new and rapidly growing research direction, in which DM-enabled policies substantially enhance decision quality by capturing the complex, discontinuous, and multimodal action structures inherent in wireless resource management. In this paper, we present a comprehensive survey of DM-enabled DRL algorithms and their applications for various issues in wireless networks. Particularly, we first provide the theoretical background of DM and present different DM-enabled DRL algorithms. We then systematically review applications of DM-enabled DRL for across computation offloading in mobile edge computing, UAV-assisted, vehicular, and AIGC-driven systems, as well as wireless resource allocation, physical-layer security, and robotics and UAV planning. We conclude the paper by higlight future research directions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey paper examines the integration of diffusion models (DMs) with deep reinforcement learning (DRL) for wireless network resource management. It posits that conventional DRL methods are limited by unimodal policy distributions, inefficient exploration, and poor adaptability, while DMs enable modeling of complex, multimodal, and discontinuous action spaces, thereby substantially improving decision quality. The manuscript covers DM theoretical background, DM-enabled DRL algorithms, and applications in areas including mobile edge computing offloading, UAV-assisted systems, vehicular networks, AIGC-driven systems, wireless resource allocation, physical-layer security, and robotics/UAV planning, concluding with future research directions.
Significance. If the survey delivers a balanced, evidence-based synthesis of the cited works rather than restating individual claims, it could usefully map an emerging intersection between generative models and wireless DRL, highlighting algorithmic patterns and open problems in a fast-growing area. The paper's value would rest on whether it identifies consistent performance patterns, failure modes, or conditions under which DM advantages materialize across the reviewed wireless scenarios.
major comments (2)
- [Abstract] Abstract: The claim that 'DM-enabled policies substantially enhance decision quality by capturing the complex, discontinuous, and multimodal action structures' is asserted as established fact and used to structure the survey, yet the described organization (background, algorithms, applications) provides no indication of a meta-analysis, aggregated performance metrics, or critical assessment of when these advantages hold versus fail across the cited papers.
- [Abstract] Abstract (limitations paragraph): The statement that conventional DRL methods are 'fundamentally limited' by unimodal policies and inefficient exploration is presented without reference to specific counter-examples or successful DRL deployments in wireless settings that would justify the 'fundamental' qualifier; this framing underpins the motivation for the entire survey.
minor comments (2)
- [Abstract] Abstract: Typo 'demonstrted' should be 'demonstrated'.
- [Abstract] Abstract: Typo 'higlight' should be 'highlight'.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our survey. We address the two major comments on the abstract below and will revise the manuscript to qualify the claims more carefully while preserving the survey's focus on synthesizing the emerging literature.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'DM-enabled policies substantially enhance decision quality by capturing the complex, discontinuous, and multimodal action structures' is asserted as established fact and used to structure the survey, yet the described organization (background, algorithms, applications) provides no indication of a meta-analysis, aggregated performance metrics, or critical assessment of when these advantages hold versus fail across the cited papers.
Authors: We agree that the abstract phrasing presents the performance benefits too definitively. As a survey, the manuscript reviews and organizes existing works rather than conducting a new meta-analysis or aggregating raw performance metrics across papers (which would require data not publicly available in most cited studies). We will revise the abstract to state that DM-enabled policies 'have demonstrated potential to enhance' decision quality in the reviewed literature, and we will add a brief discussion in the introduction or conclusion noting the current lack of cross-paper comparative benchmarks and the conditions under which advantages appear most consistent. revision: yes
-
Referee: [Abstract] Abstract (limitations paragraph): The statement that conventional DRL methods are 'fundamentally limited' by unimodal policies and inefficient exploration is presented without reference to specific counter-examples or successful DRL deployments in wireless settings that would justify the 'fundamental' qualifier; this framing underpins the motivation for the entire survey.
Authors: The word 'fundamentally' is too strong and does not adequately acknowledge successful conventional DRL applications in wireless networks. We will change the wording to 'face significant challenges, including' unimodal policies and inefficient exploration in high-dimensional settings, and we will include citations to both limitation-highlighting papers and representative successful DRL deployments in the revised introduction to provide balanced motivation. revision: yes
Circularity Check
No significant circularity: survey aggregates external literature without self-referential derivations
full rationale
This is a survey paper reviewing DM-enabled DRL methods and applications in wireless networks. The abstract and structure present background, algorithms, and applications drawn from cited external works. No new equations, fitted parameters, or derivations are introduced that reduce by construction to the paper's own inputs. Claims of enhancement are framed as summaries of the surveyed literature rather than internally derived results. No self-citation chains, ansatzes, or uniqueness theorems are invoked in a load-bearing manner within the paper itself. The paper is self-contained as a review against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optimizing aigc services by prompt engineering and edge computing: A generative diffusion model-based contract theory approach,
D. Ye, S. Cai, H. Du, J. Kang, Y . Liu, R. Yu, and D. Niyato, “Optimizing aigc services by prompt engineering and edge computing: A generative diffusion model-based contract theory approach,”IEEE Transactions on Vehicular Technology, vol. 74, no. 1, pp. 571–586, 2024
2024
-
[2]
A survey of mobile edge computing for the metaverse: Architectures, applications, and challenges,
Y . Wang and J. Zhao, “A survey of mobile edge computing for the metaverse: Architectures, applications, and challenges,” in2022 IEEE 8th international conference on collaboration and internet computing (CIC). IEEE, 2022, pp. 1–9
2022
-
[3]
Edgeshard: Efficient llm inference via collaborative edge computing,
M. Zhang, X. Shen, J. Cao, Z. Cui, and S. Jiang, “Edgeshard: Efficient llm inference via collaborative edge computing,”IEEE Internet of Things Journal, vol. 12, no. 10, pp. 13 119–13 131, 2024
2024
-
[4]
Mobility-aware multi-hop task offloading for autonomous driving in vehicular edge computing and networks,
L. Liu, M. Zhao, M. Yu, M. A. Jan, D. Lan, and A. Taherkordi, “Mobility-aware multi-hop task offloading for autonomous driving in vehicular edge computing and networks,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 2, pp. 2169–2182, 2022
2022
-
[5]
Unmanned- aerial-vehicle-aided integrated sensing and computation with mobile- edge computing,
N. Huang, C. Dou, Y . Wu, L. Qian, B. Lin, and H. Zhou, “Unmanned- aerial-vehicle-aided integrated sensing and computation with mobile- edge computing,”IEEE Internet of Things Journal, vol. 10, no. 19, pp. 16 830–16 844, 2023
2023
-
[6]
Playing Atari with Deep Reinforcement Learning
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[7]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforce- ment learning. arxiv 2015,”arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
2018
-
[9]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Multi-agent actor-critic for mixed cooperative-competitive envi- ronments,
R. Lowe, Y . I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mor- datch, “Multi-agent actor-critic for mixed cooperative-competitive envi- ronments,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[11]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inInternational conference on machine learning. pmlr, 2015, pp. 2256–2265
2015
-
[12]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
2020
-
[13]
Diffusion models in vision: A survey,
F.-A. Croitoru, V . Hondru, R. T. Ionescu, and M. Shah, “Diffusion models in vision: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 9, pp. 10 850–10 869, 2023
2023
-
[14]
A survey of diffusion models in natural language processing,
H. Zou, Z. M. Kim, and D. Kang, “A survey of diffusion models in natural language processing,”arXiv preprint arXiv:2305.14671, 2023
-
[15]
A survey of multimodal controllable diffusion models,
R. Jiang, G.-C. Zheng, T. Li, T.-R. Yang, J.-D. Wang, and X. Li, “A survey of multimodal controllable diffusion models,”Journal of Computer Science and Technology, vol. 39, no. 3, pp. 509–541, 2024
2024
-
[16]
An integrated communication and computing scheme for wi-fi networks based on generative ai and reinforcement learning,
X. Du and X. Fang, “An integrated communication and computing scheme for wi-fi networks based on generative ai and reinforcement learning,” inGLOBECOM 2024-2024 IEEE Global Communications Conference. IEEE, 2024, pp. 2009–2014
2024
-
[17]
Computation- offloading optimization for satellite edge computing via diffusion and lyapunov-based deep reinforcement learning,
Z. Rao, Z. Zhu, Y . Yao, Y . Xu, Y . Cheng, and H. Du, “Computation- offloading optimization for satellite edge computing via diffusion and lyapunov-based deep reinforcement learning,”IEEE Internet of Things Journal, 2025
2025
-
[18]
Dmais: Diffusion model-based scheduling in edge-cloud systems,
Z. Wang, M. Ding, Y . Zhao, C. Qiu, Q. Ye, and X. Wang, “Dmais: Diffusion model-based scheduling in edge-cloud systems,” inGLOBE- COM 2024 - 2024 IEEE Global Communications Conference, 2024, pp. 4612–4617
2024
-
[19]
Diffusion-based reinforcement learning for edge-enabled ai-generated content services,
H. Du, Z. Li, D. Niyato, J. Kang, Z. Xiong, H. Huang, and S. Mao, “Diffusion-based reinforcement learning for edge-enabled ai-generated content services,”IEEE Transactions on Mobile Computing, vol. 23, no. 9, pp. 8902–8918, 2024
2024
-
[20]
Enhancing llm qos through cloud-edge collaboration: A diffusion-based multi-agent reinforcement learning approach,
Z. Yao, Z. Tang, W. Yang, and W. Jia, “Enhancing llm qos through cloud-edge collaboration: A diffusion-based multi-agent reinforcement learning approach,”IEEE Transactions on Services Computing, 2025
2025
-
[21]
Diffusion-based multi-agent reinforcement learning for semantic ve- hicular edge computing,
Y . Yang, W. Ma, W. Sun, J. He, Y . Fu, C. Yuen, and Y . Zhang, “Diffusion-based multi-agent reinforcement learning for semantic ve- hicular edge computing,”IEEE Transactions on Services Computing, 2025
2025
-
[22]
X. Zhang and J. Yu, “Improve the training efficiency of drl for wireless communication resource allocation: The role of generative diffusion models,”arXiv preprint arXiv:2502.07211, 2025
-
[23]
Uplink rsma in leo satellite communications: A perspective from generative artificial intelligence,
K. Wang, X. Wang, N. Zhao, X. Yang, H. Fang, and D. Niyato, “Uplink rsma in leo satellite communications: A perspective from generative artificial intelligence,”IEEE Transactions on Vehicular Technology, 2025
2025
-
[24]
Carrier aggregation, load balanc- ing, and backhauling in non-terrestrial networks: Generative diffusion model-based optimization,
F. Khoramnejad and E. Hossain, “Carrier aggregation, load balanc- ing, and backhauling in non-terrestrial networks: Generative diffusion model-based optimization,”IEEE Transactions on Wireless Communi- cations, 2025
2025
-
[25]
Multi- objective aerial collaborative secure communication optimization via generative diffusion model-enabled deep reinforcement learning,
C. Zhang, G. Sun, J. Li, Q. Wu, J. Wang, D. Niyato, and Y . Liu, “Multi- objective aerial collaborative secure communication optimization via generative diffusion model-enabled deep reinforcement learning,”IEEE Transactions on Mobile Computing, 2024
2024
-
[26]
Uav- enabled secure data collection and energy transfer in iot via diffusion model-enhanced deep reinforcement learning,
S. Liang, M. Yin, W. Xie, Z. Sun, J. Li, J. Wang, and H. Du, “Uav- enabled secure data collection and energy transfer in iot via diffusion model-enhanced deep reinforcement learning,”IEEE Internet of Things Journal, 2024
2024
-
[27]
Diffusion model enhanced deep reinforcement learning for traffic control in 6g networks,
H. Shi, R. Wang, C. Pan, F. Gao, H. Tang, and L. Chen, “Diffusion model enhanced deep reinforcement learning for traffic control in 6g networks,”IEEE Communications Magazine, vol. 63, no. 7, pp. 41–47, 2025
2025
-
[28]
A combined diffusion model and reinforcement learning approach for solving the vehicle routing problem with multiple soft time windows,
Y . Qiao, J. Miao, and X. Huang, “A combined diffusion model and reinforcement learning approach for solving the vehicle routing problem with multiple soft time windows,”IEEE Access, 2025
2025
-
[29]
Enhancing deep reinforcement learning: A tutorial on generative diffusion models in network optimization,
H. Du, R. Zhang, Y . Liu, J. Wang, Y . Lin, Z. Li, D. Niyato, J. Kang, Z. Xiong, S. Cuiet al., “Enhancing deep reinforcement learning: A tutorial on generative diffusion models in network optimization,”IEEE Communications Surveys & Tutorials, vol. 26, no. 4, pp. 2611–2646, 2024
2024
-
[30]
Diffusion models for future networks and communications: A comprehensive survey,
N. C. Luong, N. D. Hai, D. Van Le, H. T. Nguyen, T.-H. Vu, T. Huynh- The, R. Zhang, N. D. D. Anh, D. Niyato, M. Di Renzoet al., “Diffusion models for future networks and communications: A comprehensive survey,”arXiv preprint arXiv:2508.01586, 2025
-
[31]
Generative diffusion models for wireless networks: Fundamental, architecture, and state-of-the-art,
D. Fan, R. Meng, X. Xu, Y . Liu, G. Nan, C. Feng, S. Han, S. Gao, B. Xu, D. Niyatoet al., “Generative diffusion models for wireless networks: Fundamental, architecture, and state-of-the-art,”IEEE Com- munications Surveys & Tutorials, 2026
2026
-
[32]
Diffusion models for reinforcement learning: A survey,
Z. Zhu, H. Zhao, H. He, Y . Zhong, S. Zhang, H. Guo, T. Chen, and W. Zhang, “Diffusion models for reinforcement learning: A survey,” arXiv preprint arXiv:2311.01223, 2023
-
[33]
Diffusion models for wireless communications,
M. Letafati, S. Ali, and M. Latva-aho, “Diffusion models for wireless communications,”arXiv preprint arXiv:2310.07312, 2023
-
[34]
Applications of deep reinforcement learning in communications and networking: A survey,
N. C. Luong, D. T. Hoang, S. Gong, D. Niyato, P. Wang, Y .-C. Liang, and D. I. Kim, “Applications of deep reinforcement learning in communications and networking: A survey,”IEEE communications surveys & tutorials, vol. 21, no. 4, pp. 3133–3174, 2019
2019
-
[35]
Toward autonomous multi-uav wireless network: A survey of reinforcement 21 learning-based approaches,
Y . Bai, H. Zhao, X. Zhang, Z. Chang, R. Jäntti, and K. Yang, “Toward autonomous multi-uav wireless network: A survey of reinforcement 21 learning-based approaches,”IEEE Communications Surveys & Tutori- als, vol. 25, no. 4, pp. 3038–3067, 2023
2023
-
[36]
A survey on drl based uav communications and networking: Drl fun- damentals, applications and implementations,
W. Zhao, S. Cui, W. Qiu, Z. He, Z. Liu, X. Zheng, B. Mao, and N. Kato, “A survey on drl based uav communications and networking: Drl fun- damentals, applications and implementations,”IEEE Communications Surveys & Tutorials, 2025
2025
-
[37]
A. Alwarafy, M. Abdallah, B. S. Ciftler, A. Al-Fuqaha, and M. Hamdi, “Deep reinforcement learning for radio resource allocation and man- agement in next generation heterogeneous wireless networks: A sur- vey,”arXiv preprint arXiv:2106.00574, 2021
-
[38]
Deep reinforcement learning in edge networks: Challenges and future directions,
A. Hazra, V . M. R. Tummala, N. Mazumdar, D. K. Sah, and M. Ad- hikari, “Deep reinforcement learning in edge networks: Challenges and future directions,”Physical Communication, vol. 66, p. 102460, 2024
2024
-
[39]
Score-Based Generative Modeling through Stochastic Differential Equations
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,”arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[40]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” 2022. [Online]. Available: https://arxiv.org/abs/2207.12598
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Z. Wang, J. J. Hunt, and M. Zhou, “Diffusion policies as an expres- sive policy class for offline reinforcement learning,”arXiv preprint arXiv:2208.06193, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Diffusion actor-critic with entropy reg- ulator,
Y . Wang, L. Wang, Y . Jiang, W. Zou, T. Liu, X. Song, W. Wang, L. Xiao, J. Wu, J. Duanet al., “Diffusion actor-critic with entropy reg- ulator,”Advances in Neural Information Processing Systems, vol. 37, pp. 54 183–54 204, 2024
2024
-
[43]
Qos- aware multi-aigc service orchestration at edges: An attention-diffusion- aided drl method,
Y . Liu, S. Li, X. Lin, X. Chen, G. Li, Y . Liu, B. Liao, and J. Li, “Qos- aware multi-aigc service orchestration at edges: An attention-diffusion- aided drl method,”IEEE Transactions on Cognitive Communications and Networking, 2025
2025
-
[44]
Towards multi- task generative-ai edge services with an attention-based diffusion drl approach,
Y . Liu, X. Lin, S. Li, G. Li, Q. Mao, and J. Li, “Towards multi- task generative-ai edge services with an attention-based diffusion drl approach,” in2024 9th IEEE International Conference on Smart Cloud (SmartCloud), 2024, pp. 60–65
2024
-
[45]
Diffusion- based reinforcement learning for cooperative offloading and resource allocation in multi-uav assisted edge-enabled metaverse,
Z. Zhang, J. Wang, J. Chen, H. Fu, Z. Tong, and C. Jiang, “Diffusion- based reinforcement learning for cooperative offloading and resource allocation in multi-uav assisted edge-enabled metaverse,”IEEE Trans- actions on Vehicular Technology, 2025
2025
-
[46]
Diffusion model and digital twin enhanced deep reinforcement learning for radio resource management in ran slicing,
S. Xiong, S. He, G. Chen, C. Zhang, and Y . Huang, “Diffusion model and digital twin enhanced deep reinforcement learning for radio resource management in ran slicing,” in2025 IEEE Wireless Communications and Networking Conference (WCNC), 2025, pp. 1–6
2025
-
[47]
Accelerating ai-generated content collaborative inference via transfer reinforcement learning in dynamic edge networks,
M. Tian, Z. Liu, C. Hou, C. Qiu, X. Wang, D. Niyato, and V . C. Leung, “Accelerating ai-generated content collaborative inference via transfer reinforcement learning in dynamic edge networks,”IEEE Transactions on Cloud Computing, 2025
2025
-
[48]
Addressing function approxi- mation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approxi- mation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
2018
-
[49]
W. Xie, G. Sun, J. Wang, H. Du, J. Kang, K. Huang, and V . Le- ung, “Multi-objective aerial irs-assisted isac optimization via gen- erative ai-enhanced deep reinforcement learning,”arXiv preprint arXiv:2502.10687, 2025
work page internal anchor Pith review arXiv 2025
-
[50]
Joint computing offloading and resource allo- cation in mec-enabled iot: A diffusion-based reinforcement learning approach,
H. Cao and B. Xiao, “Joint computing offloading and resource allo- cation in mec-enabled iot: A diffusion-based reinforcement learning approach,” in2024 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2024, pp. 890–896
2024
-
[51]
Generative ai-aided reinforcement learning for computation offloading and privacy protection in vr-based multi-access edge computing,
F. You, H. Du, J. Kang, W. Ni, D. Niyato, and A. Jamalipour, “Generative ai-aided reinforcement learning for computation offloading and privacy protection in vr-based multi-access edge computing,” in 2024 IEEE Smart World Congress (SWC), 2024, pp. 2209–2214
2024
-
[52]
Dnn task assignment in uav networks: A generative ai enhanced multi-agent reinforcement learning approach,
X. Tang, Q. Chen, W. Weng, B. Liao, J. Wang, X. Cao, and X. Li, “Dnn task assignment in uav networks: A generative ai enhanced multi-agent reinforcement learning approach,”IEEE Internet of Things Journal, 2025
2025
-
[53]
X. Tang, Q. Chen, W. Weng, C. Jin, Z. Liu, J. Wang, G. Sun, X. Li, and D. Niyato, “Task assignment and exploration optimization for low altitude uav rescue via generative ai enhanced multi-agent reinforcement learning,”arXiv preprint arXiv:2504.13554, 2025
-
[54]
Monotonic value function factorisation for deep multi- agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi- agent reinforcement learning,”Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020
2020
-
[55]
Diffusion-based deep reinforcement learning for resource man- agement in connected construction equipment networks: A hierarchical framework,
P. Ning, H. Wang, T. Tang, J. Zhang, H. Du, D. Niyato, and F. R. Yu, “Diffusion-based deep reinforcement learning for resource man- agement in connected construction equipment networks: A hierarchical framework,”IEEE Transactions on Wireless Communications, 2025
2025
-
[56]
K. Meng, S. Zhang, R. Li, X. Meng, C. Wang, M. Lei, and Z. Zhao, “Multi-agent conditional diffusion model with mean field communication as wireless resource allocation planner,”arXiv preprint arXiv:2510.22969, 2025
-
[57]
Dnn partitioning, task offloading, and resource allocation in dynamic vehicular networks: A lyapunov-guided diffusion-based reinforcement learning approach,
Z. Liu, H. Du, J. Lin, Z. Gao, L. Huang, S. Hosseinalipour, and D. Niyato, “Dnn partitioning, task offloading, and resource allocation in dynamic vehicular networks: A lyapunov-guided diffusion-based reinforcement learning approach,”IEEE Transactions on Mobile Com- puting, 2024
2024
-
[58]
Planning with diffusion for flexible behavior synthesis,
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” inInternational Conference on Machine Learning, 2022. [Online]. Available: https: //api.semanticscholar.org/CorpusID:248965046
2022
-
[59]
Dif- fuserlite: Towards real-time diffusion planning,
Z. Dong, J. Hao, Y . Yuan, F. Ni, Y . Wang, P. Li, and Y . Zheng, “Dif- fuserlite: Towards real-time diffusion planning,”Advances in Neural Information Processing Systems, vol. 37, pp. 122 556–122 583, 2024
2024
-
[60]
Crossway diffu- sion: Improving diffusion-based visuomotor policy via self-supervised learning,
X. Li, V . Belagali, J. Shang, and M. S. Ryoo, “Crossway diffu- sion: Improving diffusion-based visuomotor policy via self-supervised learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 16 841–16 849
2024
-
[61]
Diffusion model is an effective planner and data synthesizer for multi-task reinforcement learning,
H. He, C. Bai, K. Xu, Z. Yang, W. Zhang, D. Wang, B. Zhao, and X. Li, “Diffusion model is an effective planner and data synthesizer for multi-task reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 64 896–64 917, 2023
2023
-
[62]
Dual-circulation generative ai for optimizing resource allocation in multi-granularity heterogeneous federated learning,
W. He, H. Yao, X. Ren, T. Ouyang, Z. Xiong, Y . He, and Y . Liu, “Dual-circulation generative ai for optimizing resource allocation in multi-granularity heterogeneous federated learning,”IEEE Transactions on Cognitive Communications and Networking, 2025
2025
-
[63]
Dress: Diffusion reasoning-based reward shaping scheme for intelligent networks,
F. You, H. Du, X. Hou, Y . Ren, and K. Huang, “Dress: Diffusion reasoning-based reward shaping scheme for intelligent networks,”arXiv preprint arXiv:2503.07433, 2025
-
[64]
Drl optimization tra- jectory generation via wireless network intent-guided diffusion models for resource allocation,
J. Wu, X. Fang, D. Niyato, J. Wang, and J. Wang, “Drl optimization tra- jectory generation via wireless network intent-guided diffusion models for resource allocation,”IEEE Internet of Things Journal, 2025
2025
-
[65]
Diffusion-rl for scalable resource allocation for 6g networks,
S. Nouri, M. K. Motalleb, and V . Shah-Mansouri, “Diffusion-rl for scalable resource allocation for 6g networks,”arXiv preprint arXiv:2506.07880, 2025
-
[66]
Diffusion model based resource allocation strategy in ultra-reliable wireless networked control systems,
A. B. Darabi and S. Coleri, “Diffusion model based resource allocation strategy in ultra-reliable wireless networked control systems,”IEEE Communications Letters, 2024
2024
-
[67]
Integrating failures in robot skill acquisition with offline action-sequence diffusion rl,
H. Wang, L. Qi, and Y . Sun, “Integrating failures in robot skill acquisition with offline action-sequence diffusion rl,” inICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[68]
Enhancing qoe in collaborative edge systems with feed- back diffusion generative scheduling,
C. Xu, J. Guo, Y . Liang, H. Zou, J. Zeng, H. Dai, W. Jia, J. Cao, and T. Wang, “Enhancing qoe in collaborative edge systems with feed- back diffusion generative scheduling,”IEEE Transactions on Mobile Computing, 2025
2025
-
[69]
Trust model-based consensus optimization for vehicle platooning networks: A novel deep reinforcement learning approach with genai,
H. Chen, X. Fu, Q. Yuan, Z. Zhuang, J. Kang, Z. Liu, J. Wang, and D. Niyato, “Trust model-based consensus optimization for vehicle platooning networks: A novel deep reinforcement learning approach with genai,”IEEE Transactions on Intelligent Transportation Systems, 2025
2025
-
[70]
Diffusion-based reinforcement learning for dynamic uav-assisted ve- hicle twins migration in vehicular metaverses,
Y . Tong, J. Kang, J. Chen, M. Xu, G. Li, W. Zhang, and X. Yan, “Diffusion-based reinforcement learning for dynamic uav-assisted ve- hicle twins migration in vehicular metaverses,” inGLOBECOM 2024- 2024 IEEE Global Communications Conference. IEEE, 2024, pp. 5156–5161
2024
-
[71]
Continuous deep q- learning with model-based acceleration,
S. Gu, T. Lillicrap, I. Sutskever, and S. Levine, “Continuous deep q- learning with model-based acceleration,” inInternational conference on machine learning. PMLR, 2016, pp. 2829–2838
2016
-
[72]
Decentralized request dispatch for edge-clouds: a diffusion-based reinforcement learning paradigm,
Y . Peng, H. Peng, and W. Wang, “Decentralized request dispatch for edge-clouds: a diffusion-based reinforcement learning paradigm,”IEEE Transactions on Services Computing, 2025
2025
-
[73]
Energy-efficient ground-air-space vehicular crowdsensing by hierarchical multi-agent deep reinforcement learning with diffusion models,
Y . Zhao, C. H. Liu, T. Yi, G. Li, and D. Wu, “Energy-efficient ground-air-space vehicular crowdsensing by hierarchical multi-agent deep reinforcement learning with diffusion models,”IEEE Journal on Selected Areas in Communications, 2024
2024
-
[74]
X. Wang, H. Du, L. Feng, and K. Huang, “Energy-efficient rsma- enabled low-altitude mec optimization via generative ai-enhanced deep reinforcement learning,”arXiv preprint arXiv:2507.12910, 2025
-
[75]
A priority-aware ai-generated content resource allocation method for multi-uav aided metaverse,
Z. Zhang, J. Wang, J. Chen, Z. Fang, C. Jiang, and Z. Han, “A priority-aware ai-generated content resource allocation method for multi-uav aided metaverse,” in2025 IEEE Wireless Communications and Networking Conference (WCNC). IEEE, 2025, pp. 1–6
2025
-
[76]
Generative diffusion-based contract design for efficient ai twin 22 migration in vehicular embodied ai networks,
Y . Zhong, J. Kang, J. Wen, D. Ye, J. Nie, D. Niyato, X. Gao, and S. Xie, “Generative diffusion-based contract design for efficient ai twin 22 migration in vehicular embodied ai networks,”IEEE Transactions on Mobile Computing, 2025
2025
-
[77]
Adaptive dig- ital twin-assisted 3c management for qoe-driven msvs: A gai-based drl approach,
X. Huang, X. Qin, M. Li, C. Huang, and X. Shen, “Adaptive dig- ital twin-assisted 3c management for qoe-driven msvs: A gai-based drl approach,”IEEE Transactions on Cognitive Communications and Networking, 2024
2024
-
[78]
Ai-generated network design: A diffusion model-based learning approach,
Y . Huang, M. Xu, X. Zhang, D. Niyato, Z. Xiong, S. Wang, and T. Huang, “Ai-generated network design: A diffusion model-based learning approach,”IEEE Network, vol. 38, no. 3, pp. 202–209, 2023
2023
-
[79]
Enhanced secure beamforming for irs-assisted iot communication using a generative diffusion model-enabled optimization approach,
J. Zhang, Z. Liu, X. Feng, H. Yang, and S. Liang, “Enhanced secure beamforming for irs-assisted iot communication using a generative diffusion model-enabled optimization approach,”IEEE Internet of Things Journal, 2025
2025
-
[80]
Generative diffusion model-based deep reinforcement learning for uplink rate-splitting multiple access in leo satellite networks,
X. Wang, K. Wang, D. Zhang, J. Li, M. Zhou, and T. Hämäläinen, “Generative diffusion model-based deep reinforcement learning for uplink rate-splitting multiple access in leo satellite networks,” in2024 IEEE Symposium on Computers and Communications (ISCC). IEEE, 2024, pp. 1–8
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.