Ultra-Low-Bitrate Mel-Spectrogram-based Neural Speech Coding with Flow-Matching-based Refinement and Vocoding-driven Reconstruction
Pith reviewed 2026-06-29 19:42 UTC · model grok-4.3
The pith
FMelCodec reconstructs natural speech at 250 bps by coding mel-spectrograms with a single VQ codebook, refining them via conditional flow matching, and vocoding the result.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
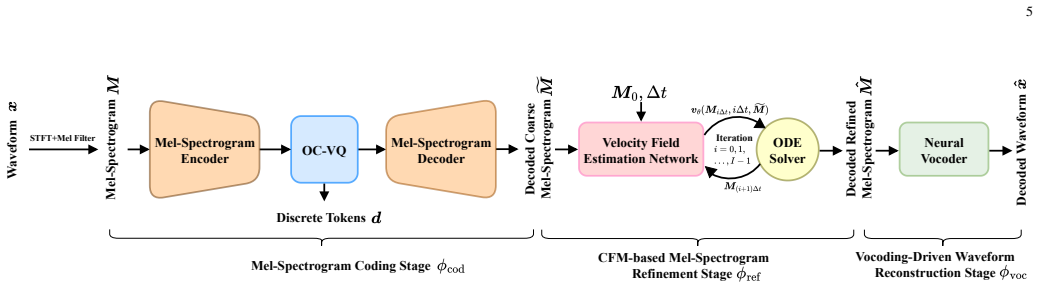
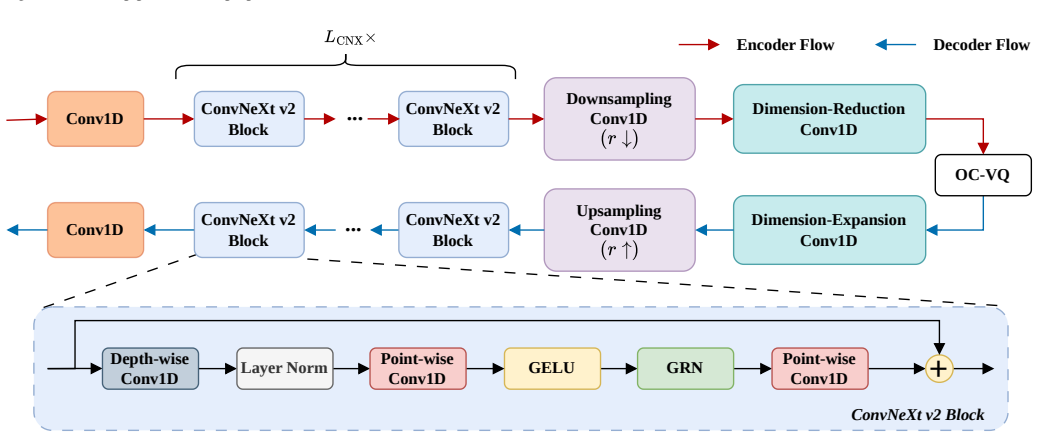
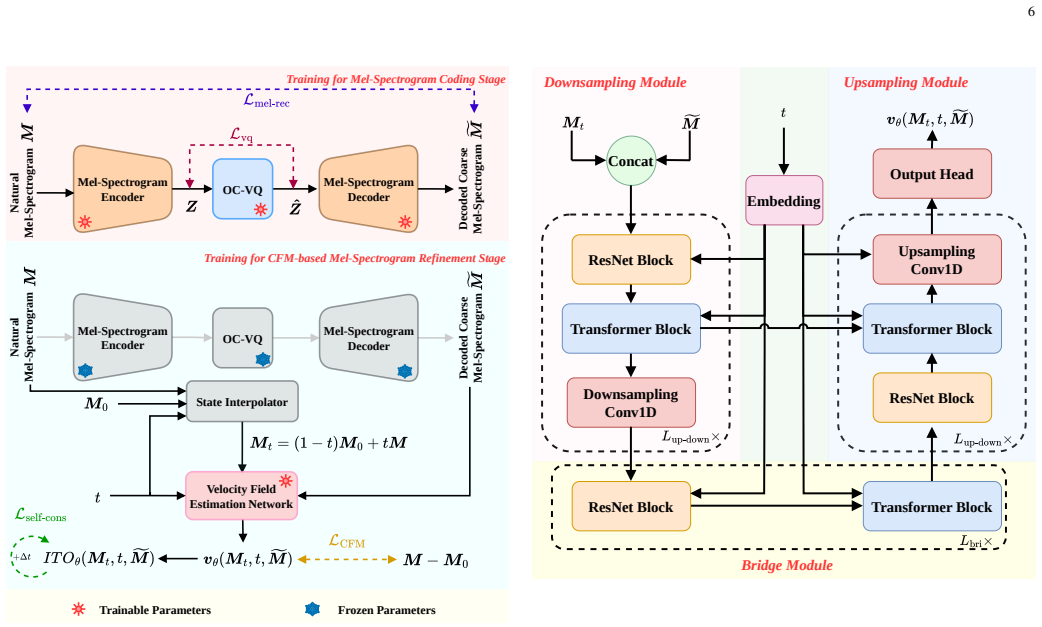
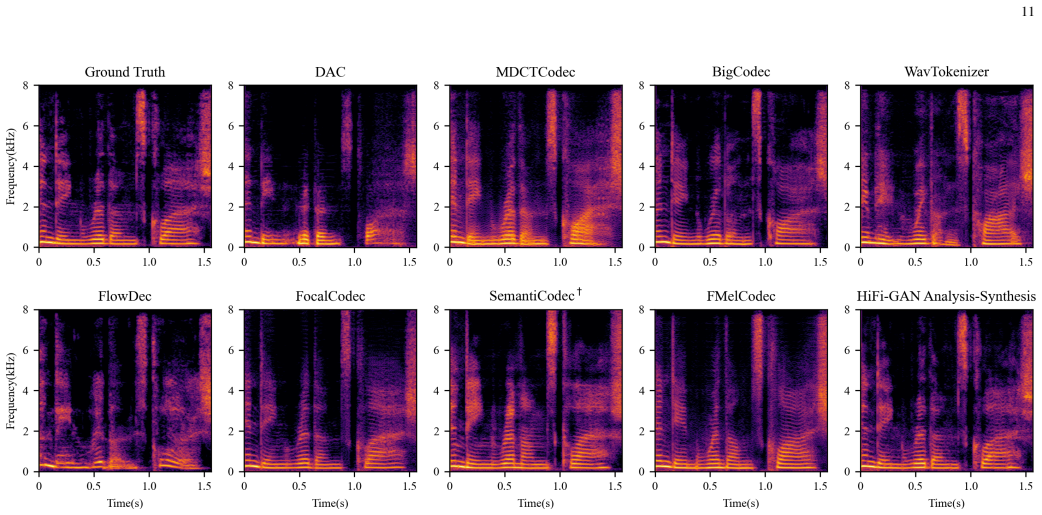
The CRR framework (mel-spectrogram coding with aggressive VQ and clustering, CFM-based refinement via a velocity-field estimator and self-consistency training, and vocoder-driven waveform reconstruction) produces higher-quality speech and speaker similarity at 250 bps for 16 kHz and 750 bps for 48 kHz while using lower computational and model complexity than existing ultra-low-bitrate codecs.
What carries the argument
The conditional flow matching refinement stage, which estimates a velocity field to correct the mel-spectrogram output by the vector-quantized decoder before vocoding.
If this is right
- Speech remains intelligible and speaker-consistent at bitrates well below those of conventional codecs.
- The refinement stage improves both quality metrics and speaker similarity without large added cost.
- Model size and inference compute stay lower than competing neural codecs at the same bitrate.
- The same pipeline works for both 16 kHz and 48 kHz sampling rates.
Where Pith is reading between the lines
- The self-consistency training that allows fewer flow-matching steps could lower latency for real-time applications.
- If the clustering trick generalizes, similar single-codebook designs might help other extreme-compression generative tasks.
- The mel-spectrogram domain plus refinement might transfer to coding music or environmental audio at comparable bitrates.
Load-bearing premise
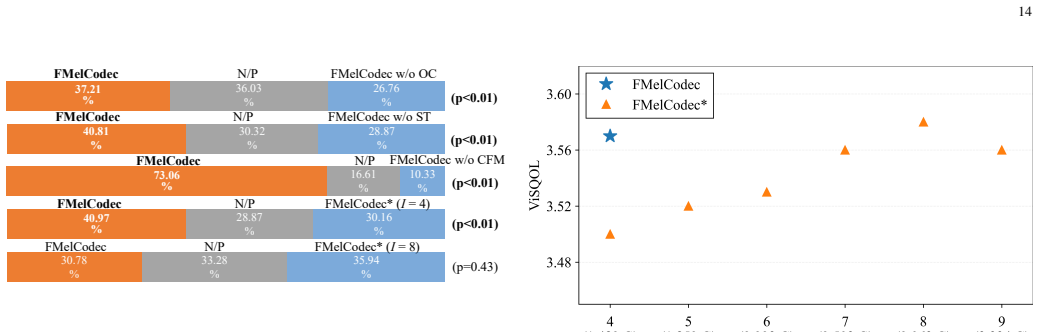
The online clustering strategy prevents codebook collapse and keeps the 1024-entry codebook diverse enough for usable reconstruction at the 640x compression ratio.
What would settle it
Subjective listening tests at 250 bps in which FMelCodec receives equal or lower mean opinion scores and speaker similarity ratings than the strongest baseline codec.
Figures
read the original abstract
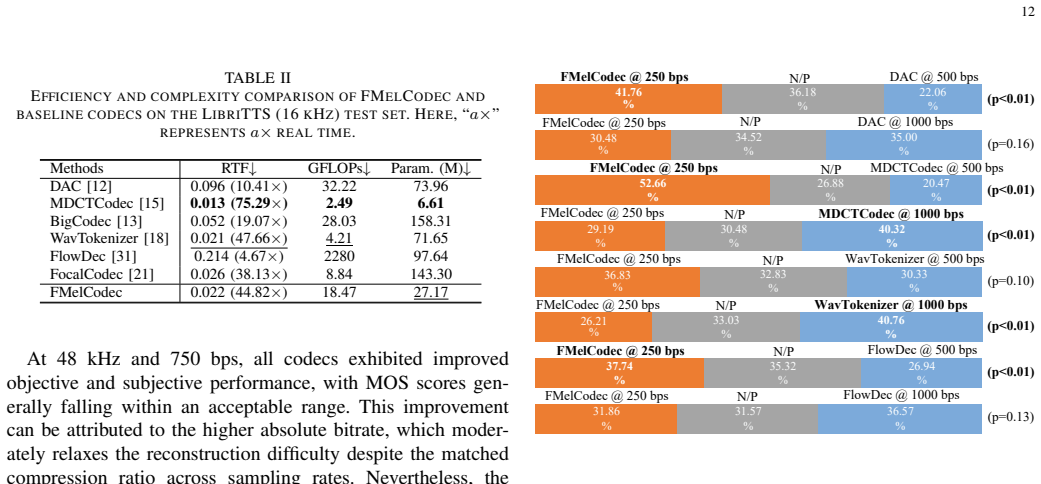
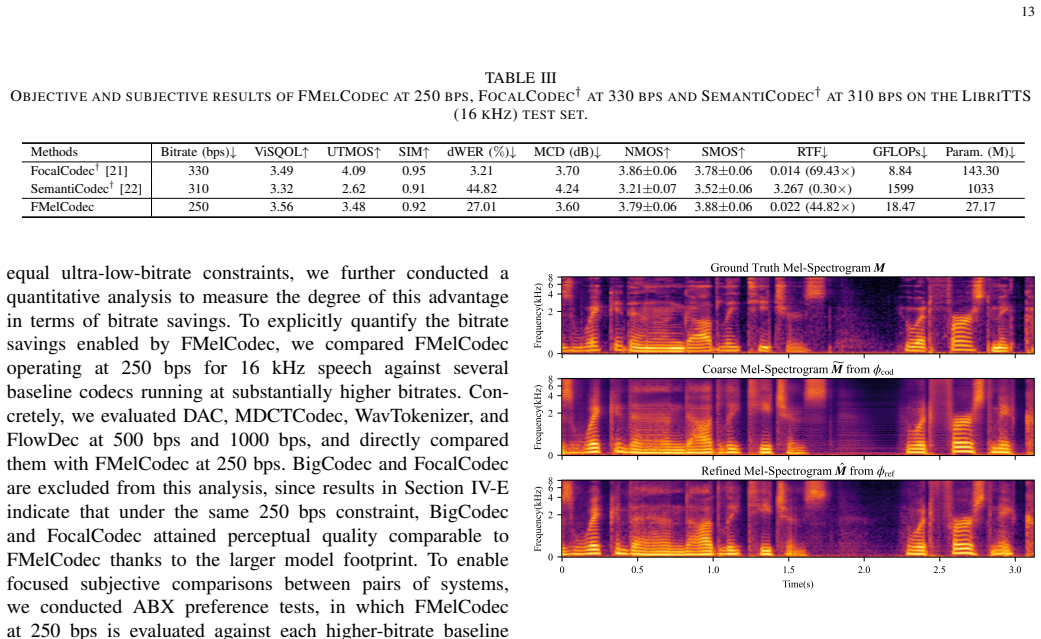
Ultra-low-bitrate speech coding is pivotal for bandwidth-constrained communication and deep compression, yet maintaining naturalness and speaker identity at such extreme bit budgets remains challenging due to pronounced information loss and quantization instability. To this end, we propose FMelCodec, an ultra-low-bitrate neural speech codec in the mel-spectrogram domain, cast as a three-stage coding-refinement-reconstruction (CRR) framework that can operate at as low as 250 bps. In the CRR framework, the front-end mel-spectrogram coding stage employs a highly aggressive 640x compression/decompression encoder-decoder structure with a single 1024-entry VQ codebook, coupled with an online clustering strategy that reassigns underused codewords to prevent codebook collapse and preserve codebook diversity. The subsequent conditional flow matching (CFM)-based mel-spectrogram refinement stage leverages a lightweight velocity-field estimator and CFM-based solver to refine the codec-degraded mel-spectrogram produced by the preceding decoder, and adopts a self-consistency training scheme that supports fewer iterative inference steps for the purpose of reducing computational overhead. Finally, the vocoding-driven waveform reconstruction stage employs a HiFi-GAN vocoder to faithfully reconstruct waveform from the refined mel-spectrogram. Experiments conducted on two datasets spanning two sampling rates show that, under ultra-low-bitrate constraints of 250 bps for 16 kHz and 750 bps for 48 kHz, both objective and subjective evaluations consistently demonstrate that FMelCodec achieves higher speech reconstruction quality and speaker similarity, while incurring lower computational and model complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FMelCodec, a three-stage CRR neural speech codec operating at 250 bps (16 kHz) and 750 bps (48 kHz). The front-end uses a 640x-compressed mel-spectrogram encoder-decoder with a single 1024-entry VQ codebook plus online clustering to avoid collapse; this is followed by a lightweight conditional flow-matching refinement stage with self-consistency training and a final HiFi-GAN vocoder. The central claim is that the system yields higher objective and subjective reconstruction quality and speaker similarity than prior methods while using lower model and computational complexity, validated on two datasets at the two sampling rates.
Significance. If the performance claims and the effectiveness of the online clustering at 640x compression are substantiated, the work would provide a concrete demonstration that aggressive single-codebook VQ plus flow-matching refinement can sustain usable naturalness and identity at bitrates previously considered marginal, with potential relevance to bandwidth-constrained speech transmission.
major comments (2)
- [front-end mel-spectrogram coding stage] Abstract and front-end mel-spectrogram coding stage: the assertion that the online clustering strategy 'prevents codebook collapse and preserve[s] codebook diversity' at the 640x compression ratio (25 codes/sec from a 1024-entry codebook) is presented without any supporting measurements (codeword utilization histograms, entropy statistics, or ablation removing the reassignment). This premise is load-bearing for the 250 bps claim, because collapse would render the subsequent CFM and HiFi-GAN stages unable to recover the reported quality.
- [Abstract] Abstract: the claim that 'both objective and subjective evaluations consistently demonstrate that FMelCodec achieves higher speech reconstruction quality and speaker similarity' is stated without any numerical values, baseline names, dataset sizes, or significance tests. The absence of these data prevents independent assessment of whether the reported gains are real or merely consistent with the weakest-assumption premise above.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments below and will make the necessary revisions to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [front-end mel-spectrogram coding stage] Abstract and front-end mel-spectrogram coding stage: the assertion that the online clustering strategy 'prevents codebook collapse and preserve[s] codebook diversity' at the 640x compression ratio (25 codes/sec from a 1024-entry codebook) is presented without any supporting measurements (codeword utilization histograms, entropy statistics, or ablation removing the reassignment). This premise is load-bearing for the 250 bps claim, because collapse would render the subsequent CFM and HiFi-GAN stages unable to recover the reported quality.
Authors: We agree that the manuscript as submitted does not include explicit supporting measurements (such as codeword utilization histograms, entropy statistics, or an ablation removing the reassignment) for the online clustering strategy. This is a valid concern given the aggressive compression ratio. In the revised manuscript we will add these analyses in the front-end coding stage section to substantiate the claim that the strategy prevents collapse and maintains diversity. revision: yes
-
Referee: [Abstract] Abstract: the claim that 'both objective and subjective evaluations consistently demonstrate that FMelCodec achieves higher speech reconstruction quality and speaker similarity' is stated without any numerical values, baseline names, dataset sizes, or significance tests. The absence of these data prevents independent assessment of whether the reported gains are real or merely consistent with the weakest-assumption premise above.
Authors: The abstract is written to remain concise while summarizing the key contributions and outcomes. We acknowledge that the current wording lacks specific numerical values, baseline names, and dataset details. In the revision we will incorporate a small number of representative objective metrics and baseline references into the abstract (subject to length constraints) and will explicitly direct readers to the experimental section for full tables, dataset sizes, and any statistical significance tests performed. revision: partial
Circularity Check
No significant circularity; claims rest on empirical evaluations
full rationale
The paper describes a three-stage CRR framework (mel-spectrogram VQ coding with online clustering, CFM refinement, HiFi-GAN reconstruction) and supports its performance claims solely through objective/subjective experiments on two datasets at 250/750 bps. No equations, derivations, or self-citations are presented that reduce any reported gain to a fitted parameter, self-definition, or prior author result by construction. The online clustering strategy is introduced as an engineering choice whose success is asserted via experimental outcomes rather than mathematical equivalence to the input data or model. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- VQ codebook size
- Compression ratio
axioms (2)
- domain assumption Conditional flow matching with self-consistency training can refine codec-degraded mel-spectrograms while supporting reduced inference steps
- domain assumption Online clustering prevents codebook collapse under extreme quantization
Reference graph
Works this paper leans on
-
[1]
High-quality, low-delay music coding in the opus codec,
J.-M. Valin, G. Maxwell, T. B. Terriberry, and K. V os, “High-quality, low-delay music coding in the opus codec,” inAudio Engineering Society Convention 135. Audio Engineering Society, 2013
2013
-
[2]
Overview of the EVS codec architecture,
M. Dietz, M. Multrus, V . Eksler, V . Malenovsky, E. Norvell, H. Pobloth, L. Miao, Z. Wang, L. Laaksonen, A. Vasilacheet al., “Overview of the EVS codec architecture,” inProc. ICASSP, 2015, pp. 5698–5702
2015
-
[3]
Generative speech coding with predictive variance regularization,
W. B. Kleijn, A. Storus, M. Chinen, T. Denton, F. S. Lim, A. Luebs, J. Skoglund, and H. Yeh, “Generative speech coding with predictive variance regularization,” inProc. ICASSP, 2021, pp. 6478–6482
2021
-
[4]
Universal discrete-domain speech enhancement,
F. Liu, Y . Ai, Y .-X. Lu, R.-C. Zheng, H.-P. Du, and Z.-H. Ling, “Universal discrete-domain speech enhancement,”IEEE Transactions on Audio, Speech and Language Processing, vol. 34, pp. 285–298, 2026
2026
-
[5]
Speech enhancement using continuous embeddings of neural audio codec,
H. Li, J. Q. Yip, T. Fan, and E. S. Chng, “Speech enhancement using continuous embeddings of neural audio codec,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[6]
Neural codec language models are zero-shot text to speech synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural codec language models are zero-shot text to speech synthesizers,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 705–718, 2025
2025
-
[7]
V ALL-E2: Neural codec language models are human parity zero-shot text to speech synthesizers,
S. Chen, S. Liu, L. Zhou, Y . Liu, X. Tan, J. Li, S. Zhao, Y . Qian, and F. Wei, “V ALL-E2: Neural codec language models are human parity zero-shot text to speech synthesizers,”arXiv preprint arXiv:2406.05370, 2024
-
[8]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
SoundStream: An End-to-End Neural Audio Codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “SoundStream: An End-to-End Neural Audio Codec,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2022
2022
-
[10]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Transactions on Machine Learning Research, 2023
2023
-
[11]
Generative adversarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” in Proc. NeurIPS, vol. 27, 2014
2014
-
[12]
High- fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High- fidelity audio compression with improved rvqgan,” inProc. NeurIPS, vol. 36, 2024
2024
-
[13]
BigCodec: Pushing the limits of low-bitrate neural speech codec,
D. Xin, X. Tan, S. Takamichi, and H. Saruwatari, “BigCodec: Pushing the limits of low-bitrate neural speech codec,”arXiv preprint arXiv:2409.05377, 2024
-
[14]
APCodec: A neural audio codec with parallel amplitude and phase spectrum encoding and decoding,
Y . Ai, X.-H. Jiang, Y .-X. Lu, H.-P. Du, and Z.-H. Ling, “APCodec: A neural audio codec with parallel amplitude and phase spectrum encoding and decoding,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 3256–3269, 2024
2024
-
[15]
MDCTCodec: A lightweight MDCT-based neural audio codec towards high sampling rate and low bitrate scenarios,
X.-H. Jiang, Y . Ai, R.-C. Zheng, H.-P. Du, Y .-X. Lu, and Z.-H. Ling, “MDCTCodec: A lightweight MDCT-based neural audio codec towards high sampling rate and low bitrate scenarios,” inProc. SLT, 2024, pp. 540–547
2024
-
[16]
A streamable neural audio codec with residual scalar-vector quantization for real-time communication,
X.-H. Jiang, Y . Ai, R.-C. Zheng, and Z.-H. Ling, “A streamable neural audio codec with residual scalar-vector quantization for real-time communication,”IEEE Signal Processing Letters, vol. 32, pp. 1645– 1649, 2025
2025
-
[17]
Spectral codecs: Spectrogram-based audio codecs for high quality speech synthesis,
R. Langman, A. Juki ´c, K. Dhawan, N. R. Koluguri, and B. Ginsburg, “Spectral codecs: Spectrogram-based audio codecs for high quality speech synthesis,”arXiv preprint arXiv:2406.05298, 2024
-
[18]
WavTokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Liet al., “WavTokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,” inProc. ICLR, 2025
2025
-
[19]
Scaling transformers for low-bitrate high-quality speech coding,
J. D. Parker, A. Smirnov, J. Pons, C. Carr, Z. Zukowski, Z. Evans, and X. Liu, “Scaling transformers for low-bitrate high-quality speech coding,” inThe Thirteenth International Conference on Learning Representations
-
[20]
TS3-Codec: Transformer-based simple streaming single codec,
H. Wu, N. Kanda, S. Emre Eskimez, and J. Li, “TS3-Codec: Transformer-based simple streaming single codec,” inProc. Interspeech, 2025, pp. 604–608
2025
-
[21]
FocalCodec: Low-bitrate speech coding via focal modulation networks,
L. Della Libera, F. Paissan, C. Subakan, and M. Ravanelli, “FocalCodec: Low-bitrate speech coding via focal modulation networks,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[22]
Semanticodec: An ultra low bitrate semantic audio codec for general sound,
H. Liu, X. Xu, Y . Yuan, M. Wu, W. Wang, and M. D. Plumbley, “Semanticodec: An ultra low bitrate semantic audio codec for general sound,”IEEE Journal of Selected Topics in Signal Processing, vol. 18, no. 8, pp. 1448–1461, 2024
2024
-
[23]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inProc. ICLR, 2023
2023
-
[24]
FlowMAC: Conditional flow matching for audio coding at low bit rates,
N. Pia, M. Strauss, M. Multrus, and B. Edler, “FlowMAC: Conditional flow matching for audio coding at low bit rates,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[25]
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” inProc. NeurIPS, vol. 33, 2020, pp. 17 022–17 033
2020
-
[26]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[27]
Generative de-quantization for neural speech codec via latent diffusion,
H. Yang, I. Jang, and M. Kim, “Generative de-quantization for neural speech codec via latent diffusion,” inProc. ICASSP. IEEE, 2024, pp. 1251–1255
2024
-
[28]
From discrete tokens to high-fidelity audio using multi- band diffusion,
R. San Roman, Y . Adi, A. Deleforge, R. Serizel, G. Synnaeve, and A. D ´efossez, “From discrete tokens to high-fidelity audio using multi- band diffusion,”Advances in neural information processing systems, vol. 36, pp. 1526–1538, 2023
2023
-
[29]
Matcha- TTS: A fast tts architecture with conditional flow matching,
S. Mehta, R. Tu, J. Beskow, ´E. Sz ´ekely, and G. E. Henter, “Matcha- TTS: A fast tts architecture with conditional flow matching,” inProc. ICASSP, 2024, pp. 11 341–11 345. 16
2024
-
[30]
FlowSE: Efficient and high-quality speech enhancement via flow matching,
Z. Wang, Z. Liu, X. Zhu, Y . Zhu, M. Liu, J. Chen, L. Xiao, C. Weng, and L. Xie, “FlowSE: Efficient and high-quality speech enhancement via flow matching,” inProc. Interspeech, 2025, pp. 4858–4862
2025
-
[31]
FlowDec: A flow-based full-band general audio codec with high perceptual quality,
S. Welker, M. Le, R. T. Chen, W.-N. Hsu, T. Gerkmann, A. Richard, and Y .-C. WU, “FlowDec: A flow-based full-band general audio codec with high perceptual quality,” inProc. ICLR, 2025
2025
-
[32]
Mucodec: Ultra low-bitrate music codec,
Y . Xu, H. Chen, J. Yu, W. Tan, R. Gu, S. Lei, Z. Lin, and Z. Wu, “Mucodec: Ultra low-bitrate music codec,”arXiv preprint arXiv:2409.13216, 2024
-
[33]
ConvNeXt v2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “ConvNeXt v2: Co-designing and scaling convnets with masked autoencoders,” inProc. CVPR, 2023, pp. 16 133–16 142
2023
-
[34]
FreeV: Free Lunch For V ocoders Through Pseudo Inversed Mel Filter,
Y . Lv, H. Li, Y . Yan, J. Liu, D. Xie, and L. Xie, “FreeV: Free Lunch For V ocoders Through Pseudo Inversed Mel Filter,” inProc. Interspeech, 2024, pp. 3869–3873
2024
-
[35]
APNet2: High-quality and high-efficiency neural vocoder with direct prediction of amplitude and phase spectra,
H.-P. Du, Y .-X. Lu, Y . Ai, and Z.-H. Ling, “APNet2: High-quality and high-efficiency neural vocoder with direct prediction of amplitude and phase spectra,” inProc. NCMMSC, 2023, pp. 66–80
2023
-
[36]
V ocos: Closing the gap between time-domain and fourier- based neural vocoders for high-quality audio synthesis,
H. Siuzdak, “V ocos: Closing the gap between time-domain and fourier- based neural vocoders for high-quality audio synthesis,” inProc. ICLR, 2024
2024
-
[37]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449– 12 460, 2020
2020
-
[38]
Online clustered codebook,
C. Zheng and A. Vedaldi, “Online clustered codebook,” inProc. ICCV, 2023, pp. 22 798–22 807
2023
-
[39]
ERVQ: Enhanced residual vector quantization with intra-and-inter-codebook optimization for neural audio codecs,
R.-C. Zheng, H.-P. Du, X.-H. Jiang, Y . Ai, and Z.-H. Ling, “ERVQ: Enhanced residual vector quantization with intra-and-inter-codebook optimization for neural audio codecs,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 2539–2550, 2025
2025
-
[40]
Single-codec: Single-codebook speech codec towards high- performance speech generation,
H. Li, L. Xue, H. Guo, X. Zhu, Y . Lv, L. Xie, Y . Chen, H. Yin, and Z. Li, “Single-codec: Single-codebook speech codec towards high- performance speech generation,” inProc. Interspeech, 2024, pp. 3390– 3394
2024
-
[41]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[42]
Generating diverse high-fidelity images with vq-vae-2,
A. Razavi, A. Van den Oord, and O. Vinyals, “Generating diverse high-fidelity images with vq-vae-2,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[43]
Identity mappings in deep residual networks,
K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,”Computer Vision–ECCV 2016, vol. 9908, pp. 630–645, 2016
2016
-
[44]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[45]
BigVGAN: A universal neural vocoder with large-scale training,
S. G. Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “BigVGAN: A universal neural vocoder with large-scale training,” inProc. ICLR, 2023
2023
-
[46]
Grad- TTS: A diffusion probabilistic model for text-to-speech,
V . Popov, I. V ovk, V . Gogoryan, T. Sadekova, and M. Kudinov, “Grad- TTS: A diffusion probabilistic model for text-to-speech,” inProc. ICML, 2021, pp. 8599–8608
2021
-
[47]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text-to-speech,” arXiv preprint arXiv:1904.02882, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[48]
CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),
J. Yamagishi, C. Veaux, K. MacDonaldet al., “CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),”University of Edinburgh. The Centre for Speech Technology Research (CSTR), pp. 271–350, 2019
2019
-
[49]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. ICLR, 2017
2017
-
[50]
WavLM: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[51]
ViSQOL v3: An open source production ready objective speech and audio metric,
M. Chinen, F. S. Lim, J. Skoglund, N. Gureev, F. O’Gorman, and A. Hines, “ViSQOL v3: An open source production ready objective speech and audio metric,” inProc. QoMEX, 2020, pp. 1–6
2020
-
[52]
UTMOS: UTokyo-SaruLab System for V oiceMOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oiceMOS Challenge 2022,” inProc. Interspeech, 2022, pp. 4521–4525
2022
-
[53]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProc. ICML, 2023, pp. 28 492–28 518
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.