SIREN: Unified Multi-Granularity Semantic Interaction for Multi-Modal Lifelong User Interest Modeling
Pith reviewed 2026-06-29 20:18 UTC · model grok-4.3
The pith
SIREN unifies multi-granularity semantic interaction to align multi-modal content with collaborative signals inside a target-conditioned transformer for lifelong user interest modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
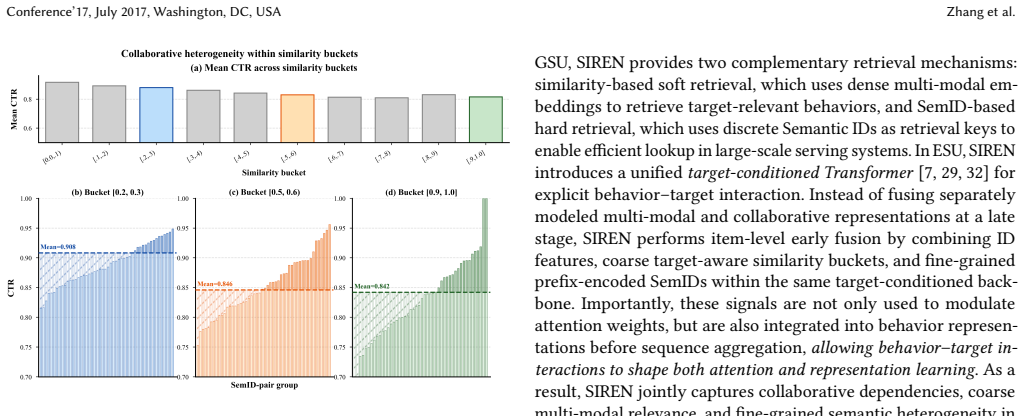
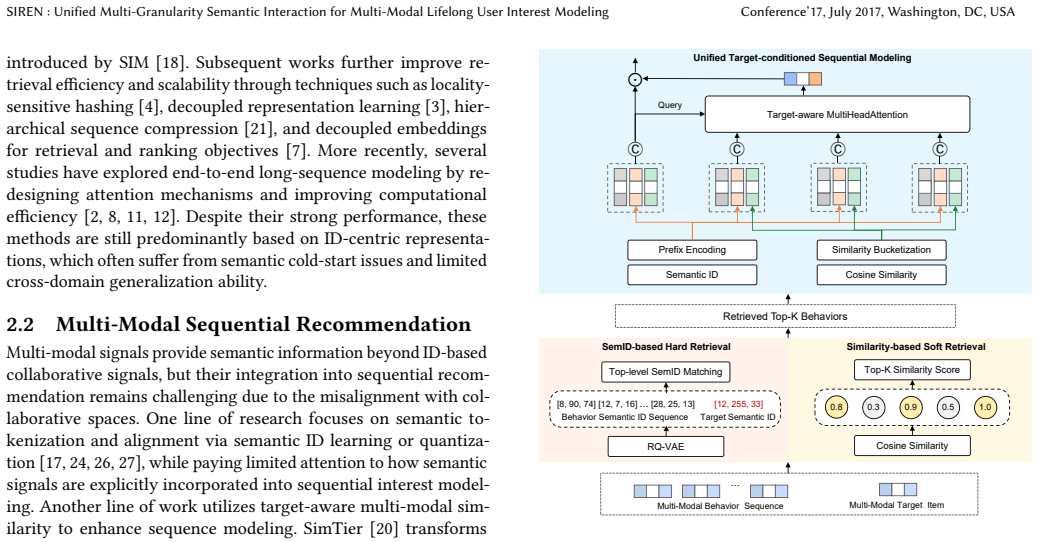
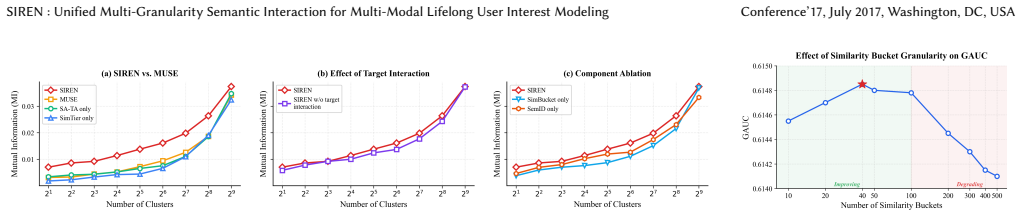
SIREN claims that explicit multi-granularity semantic interaction—via multi-modal similarity-based soft retrieval or SemID-based hard retrieval in the general stage, followed by target-aware coarse buckets and prefix-encoded SemIDs in the exact stage—enables unified processing of multi-modal and collaborative features inside the target-conditioned transformer and thereby overcomes the coarse representations produced by prior separate-modeling pipelines.
What carries the argument
multi-granularity semantic interaction that injects coarse similarity buckets and fine-grained prefix-encoded SemIDs into the target-conditioned transformer to let them interact directly with collaborative ID features
If this is right
- SIREN reaches state-of-the-art GAUC on the offline evaluation dataset.
- Online A/B tests show GMV lifts of +2.28% in Weixin Moments, +3.87% in Weixin Official Accounts, and +1.61% in Weixin Channels.
- The dual retrieval options in the General Search Unit support both effectiveness and efficient industrial serving.
- The full system has been deployed for full-traffic serving in a large-scale advertising platform since July 2025.
Where Pith is reading between the lines
- The choice between soft and hard retrieval strategies highlights a practical effectiveness-efficiency trade-off that other multi-modal sequential models could adopt.
- Semantic IDs appear to function as a shared encoding layer that reduces the need for modality-specific late fusion.
- If the granularity levels prove additive, systems could test additional intermediate bucket sizes to further refine target relevance.
Load-bearing premise
The combination of coarse similarity buckets and fine-grained SemIDs inside the target-conditioned transformer successfully aligns multi-modal and collaborative spaces without losing critical signals or introducing noise.
What would settle it
An ablation that removes the coarse buckets and prefix-encoded SemIDs from the transformer and measures whether GAUC falls below the reported state-of-the-art level would directly test whether the multi-granularity interaction supplies the claimed alignment benefit.
Figures
read the original abstract
Industrial recommender systems increasingly leverage lifelong user behavior histories and rich multi-modal content to capture evolving user preferences. However, effectively integrating multi-modal features into lifelong interest modeling remains challenging due to the inherent misalignment between multi-modal and collaborative spaces. Existing paradigms typically rely on separate modeling of multi-modal sequence and behavior sequence, and late fusion to alleviate the modality gap, which results in coarse-grained multi-modal representation and limited integration. In this paper, we propose SIREN, a unified multi-granularity semantic interaction framework for multi-modal lifelong user interest modeling. In the General Search Unit stage, we introduce two alternative retrieval strategies: multi-modal similarity-based soft retrieval for retrieval effectiveness, and Semantic ID (SemID)-based hard retrieval for efficient industrial serving. For the Exact Search Unit stage, we explicitly incorporate target-aware relevance via coarse similarity buckets and fine-grained prefix-encoded SemIDs, enabling unified interaction with collaborative ID features within the target-conditioned transformer architecture. Extensive experiments on the offline dataset demonstrate that SIREN achieves a state-of-the-art GAUC. Online A/B tests further demonstrate consistent GMV gains across multiple production scenarios, including +2.28% in Weixin Moments, +3.87% in Weixin Official Accounts, and +1.61% in Weixin Channels. From July 2025, SIREN has been fully launched for full-traffic serving in Tencent's advertising platform.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SIREN, a unified multi-granularity semantic interaction framework for multi-modal lifelong user interest modeling in industrial recommender systems. It describes a General Search Unit with two retrieval strategies (multi-modal similarity-based soft retrieval and SemID-based hard retrieval) and an Exact Search Unit that incorporates target-aware relevance via coarse similarity buckets and fine-grained prefix-encoded SemIDs inside a target-conditioned transformer. The central claims are that SIREN achieves state-of-the-art GAUC on an offline dataset and produces consistent GMV lifts (+2.28% Weixin Moments, +3.87% Official Accounts, +1.61% Channels) in online A/B tests, resulting in full-traffic deployment since July 2025.
Significance. If the performance claims are supported by properly documented experiments, the work could meaningfully advance industrial practice by providing a concrete mechanism for bridging multi-modal and collaborative feature spaces within lifelong sequence modeling without separate late-fusion stages.
major comments (1)
- [Abstract] Abstract: the central claim of SOTA GAUC and specific GMV gains is presented without any reference to baselines, dataset statistics, statistical tests, or data exclusion criteria, rendering the claim impossible to evaluate from the supplied text.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract. We agree that the abstract should better contextualize the performance claims and will revise it accordingly while respecting length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of SOTA GAUC and specific GMV gains is presented without any reference to baselines, dataset statistics, statistical tests, or data exclusion criteria, rendering the claim impossible to evaluate from the supplied text.
Authors: We acknowledge the abstract's brevity limits direct evaluation of the claims. The full manuscript details the offline experiments (Section 4) with multiple baselines, dataset statistics (user/item counts, sequence lengths), GAUC improvements, and evaluation protocol. Online A/B tests (Section 5) report GMV lifts with traffic volumes and duration; statistical significance testing is standard in our production A/B framework and described in the paper. To address the concern, we will expand the abstract to reference key baselines (e.g., prior multi-modal and lifelong models) and dataset scale while keeping it concise. Data exclusion criteria follow standard industrial practices (e.g., cold-start filtering) already noted in the experiments section. revision: yes
Circularity Check
No circularity: empirical architecture with external validation
full rationale
The manuscript presents an applied recommender architecture (SIREN) whose central claims rest on offline GAUC results and online A/B-test GMV lifts rather than any closed mathematical derivation. No equations, fitted-parameter predictions, or self-citation chains appear in the supplied text; the described retrieval strategies and target-conditioned transformer are design choices whose effectiveness is measured against held-out data and production traffic, not derived from the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. 2024. The Revolution of Multimodal Large Language Models: A Survey. InACL. 13590–13618
2024
-
[2]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, Xionghang Xie, Shiru Ren, Xiang Sun, Yaocheng Tan, Peng Xu, Yuchao Zheng, and Di Wu. 2025. LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders. InRecSys. 247–256
2025
-
[3]
Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, and Kun Gai. 2023. TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou. InKDD. 3785–3794
2023
- [4]
-
[5]
Qin Ding, Kevin Course, Linjian Ma, Jianhui Sun, Ruochen Liu, Zhao Zhu, Chunx- ing Yin, Wei Li, Dai Li, Yu Shi, Xuan Cao, Ze Yang, Han Li, Xing Liu, Bi Xue, Hongwei Li, Rui Jian, Daisy Shi He, Jing Qian, Matt Ma, Qunshu Zhang, and Rui Li. 2026. Bending the Scaling Law Curve in Large-Scale Recommendation Systems.arXiv Preprinthttps://arxiv.org/abs/2602.169...
-
[6]
Zhifang Fan, Dan Ou, Yulong Gu, Bairan Fu, Xiang Li, Wentian Bao, Xin-Yu Dai, Xiaoyi Zeng, Tao Zhuang, and Qingwen Liu. 2022. Modeling Users’ Contextu- alized Page-wise Feedback for Click-Through Rate Prediction in E-commerce Search. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. 262–270
2022
-
[7]
Ningya Feng, Junwei Pan, Jialong Wu, Baixu Chen, Ximei Wang, Qian Li, Xian Hu, Jie Jiang, and Mingsheng Long. 2025. Long-Sequence Recommendation Models Need Decoupled Embeddings. InICLR
2025
-
[8]
Lin Guan, Jia-Qi Yang, Zhishan Zhao, Beichuan Zhang, Bo Sun, Xuanyuan Luo, Jinan Ni, Xiaowen Li, Yuhang Qi, Zhifang Fan, Hangyu Wang, Qiwei Chen, Yi Cheng, Feng Zhang, and Xiao Yang. 2025. Make It Long, Keep It Fast: End- to-End 10k-Sequence Modeling at Billion Scale on Douyin.arXiv Preprint https://arxiv.org/abs/2511.06077 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Chengcheng Guo, Junda She, Kuo Cai, Shiyao Wang, Qigen Hu, Qiang Luo, Guorui Zhou, and Kun Gai. 2025. MISS: Multi-Modal Tree Indexing and Searching with Lifelong Sequential Behavior for Retrieval Recommendation. InCIKM. 5683– 5690
2025
-
[10]
Zhicheng He, Weiwen Liu, Wei Guo, Jiarui Qin, Yingxue Zhang, Yaochen Hu, and Ruiming Tang. 2023. A Survey on User Behavior Modeling in Recommender Systems. InIJCAI. ijcai.org, 6656–6664
2023
-
[11]
Ruijie Hou, Zhaoyang Yang, Ming Yu, Hongyu Lu, Zhuobin Zheng, Yu Chen, Qin- song Zeng, and Ming Chen. 2024. Cross-Domain LifeLong Sequential Modeling for Online Click-Through Rate Prediction. InKDD. 5116–5125
2024
-
[12]
Xian Hu, Ming Yue, Zhixiang Feng, Junwei Pan, Junjie Zhai, Ximei Wang, Xinrui Miao, Qian Li, Xun Liu, Shangyu Zhang, Letian Wang, Hua Lu, Zijian Zeng, Chen Cai, Wei Wang, Fei Xiong, Pengfei Xiong, Jintao Zhang, Zhiyuan Wu, Chunhui Zhang, Anan Liu, Jiulong You, Chao Deng, Yuekui Yang, Shudong Huang, Dapeng Liu, and Haijie Gu. 2025. Practice on Long Behavio...
-
[13]
Qidong Liu, Jiaxi Hu, Yutian Xiao, Xiangyu Zhao, Jingtong Gao, Wanyu Wang, Qing Li, and Jiliang Tang. 2025. Multimodal Recommender Systems: A Survey. ACM Comput. Surv.57, 2 (2025), 26:1–26:17
2025
-
[14]
Yifan Liu, Kangning Zhang, Xiangyuan Ren, Yanhua Huang, Jiarui Jin, Yingjie Qin, Ruilong Su, Ruiwen Xu, Yong Yu, and Weinan Zhang. 2024. AlignRec: Aligning and Training in Multimodal Recommendations. InCIKM. 1503–1512
2024
- [15]
-
[16]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. InICLR
2019
-
[17]
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, Changqing Qiu, Jiaqi Zhang, Xu Zhang, Zhiheng Yan, Jingming Zhang, Simin Zhang, Mingxing Wen, Zhaojie Liu, and Guorui Zhou. 2025. QARM: Quantitative Alignment Multi-Modal Recom- mendation at Kuaishou. InCIKM. 5915–5922
2025
- [18]
-
[19]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InICML. 8748–8763
2021
-
[20]
Xiang-Rong Sheng, Feifan Yang, Litong Gong, Biao Wang, Zhangming Chan, Yujing Zhang, Yueyao Cheng, Yong-Nan Zhu, Tiezheng Ge, Han Zhu, Yuning Jiang, Jian Xu, and Bo Zheng. 2024. Enhancing Taobao Display Advertising with Multimodal Representations: Challenges, Approaches and Insights. InCIKM. 4858–4865
2024
-
[21]
Zihua Si, Lin Guan, Zhongxiang Sun, Xiaoxue Zang, Jing Lu, Yiqun Hui, Xingchao Cao, Zeyu Yang, Yichen Zheng, Dewei Leng, Kai Zheng, Chenbin Zhang, Yanan Niu, Yang Song, and Kun Gai. 2024. TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou. InCIKM. 4890– 4897
2024
-
[22]
Qwen Team. 2025. Qwen3-VL Technical Report.arXiv Preprint https://arxiv.org/abs/2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Jinpeng Wang, Ziyun Zeng, Yunxiao Wang, Yuting Wang, Xingyu Lu, Tianxiang Li, Jun Yuan, Rui Zhang, Hai-Tao Zheng, and Shu-Tao Xia. 2023. MISSRec: Pre- training and Transferring Multi-modal Interest-aware Sequence Representation for Recommendation. InACM Multimedia
2023
-
[24]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. 2024. Learnable Item Tokenization for Generative Recommendation. InCIKM. 2400–2409
2024
-
[25]
Bin Wu, Feifan Yang, Zhangming Chan, Yu-Ran Gu, Jiawei Feng, Chao Yi, Xiang- Rong Sheng, Han Zhu, Jian Xu, Mang Ye, and Bo Zheng. 2025. MUSE: A Simple Yet Effective Multimodal Search-Based Framework for Lifelong User Interest Modeling.arXiv Preprinthttps://arxiv.org/abs/2512.07216 (2025)
-
[26]
Yi Xu, Moyu Zhang, Chenxuan Li, Zhihao Liao, Haibo Xing, Hao Deng, Jinxin Hu, Yu Zhang, Xiaoyi Zeng, and Jing Zhang. 2026. MMQ: Multimodal Mixture- of-Quantization Tokenization for Semantic ID Generation and User Behavioral Adaptation. InWSDM. 788–797
2026
-
[27]
Wencai Ye, Mingjie Sun, Shaoyun Shi, Peng Wang, Wenjin Wu, and Peng Jiang
-
[28]
DAS: Dual-Aligned Semantic IDs Empowered Industrial Recommender System. InCIKM. 6217–6224
-
[29]
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. 2022. SoundStream: An End-to-End Neural Audio Codec.IEEE ACM Trans. Audio Speech Lang. Process.30 (2022), 495–507
2022
-
[30]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. InICML. 58484–58509
2024
-
[31]
Carolina Zheng, Minhui Huang, Dmitrii Pedchenko, Kaushik Rangadurai, Siyu Wang, Fan Xia, Gaby Nahum, Jie Lei, Yang Yang, Tao Liu, Zutian Luo, Xiaohan Wei, Dinesh Ramasamy, Jiyan Yang, Yiping Han, Lin Yang, Hangjun Xu, Rong Jin, and Shuang Yang. 2025. Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID. InRecSys. 954–957
2025
-
[32]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click- Through Rate Prediction. InKDD
2018
-
[33]
Haolin Zhou, Junwei Pan, Xinyi Zhou, Xihua Chen, Jie Jiang, Xiaofeng Gao, and Guihai Chen. 2024. Temporal Interest Network for User Response Prediction. In WWW. 413–422. 8
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.