DiSC: Resolution-Scalable Acceleration of Diffusion Models by Exploiting Sparsity and Cached Token Reuse with Hash-based Distribution
Pith reviewed 2026-06-29 19:30 UTC · model grok-4.3
The pith
DiSC accelerates diffusion transformers by reusing cached tokens and sparsity masks on hash-distributed dense compute engines without dedicated sparse hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
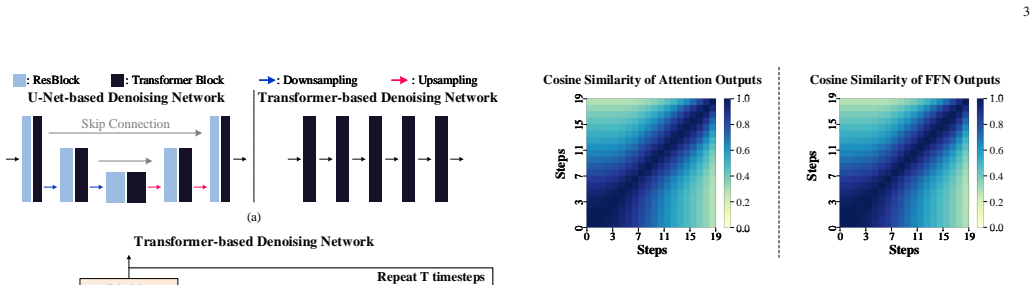
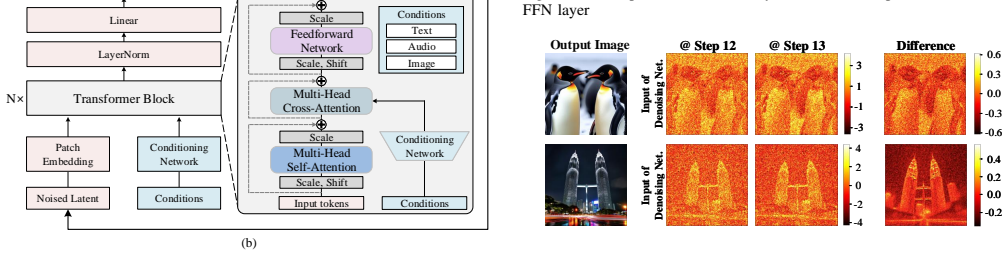
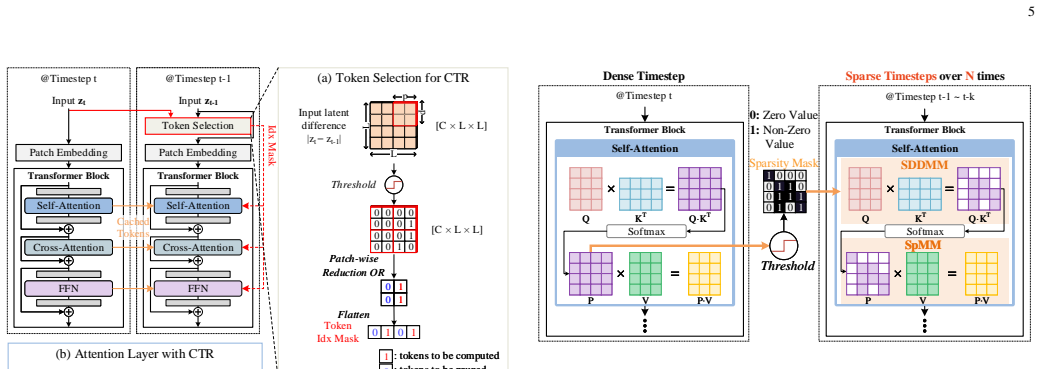
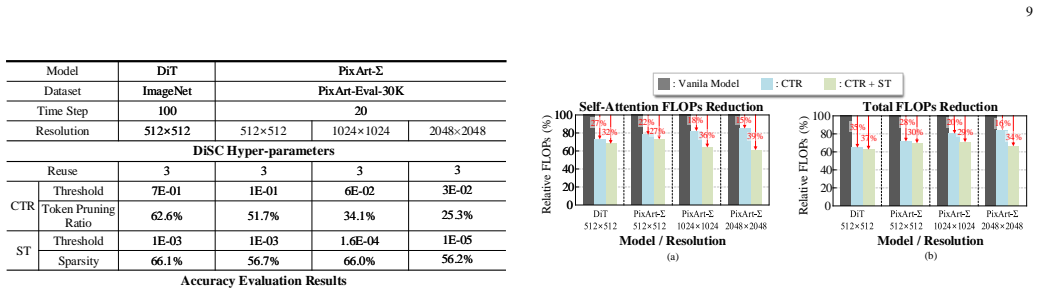
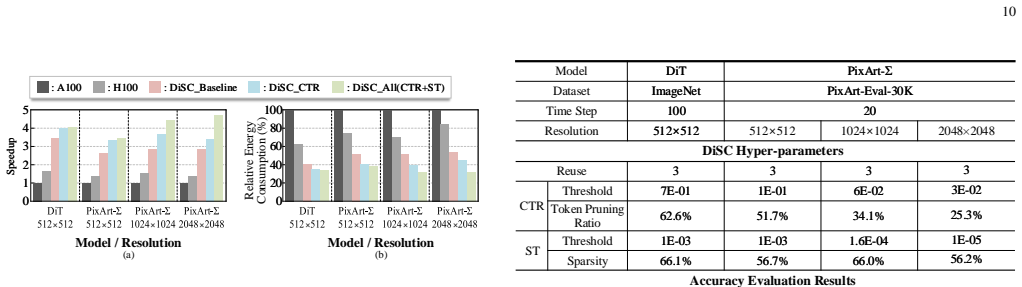
DiSC establishes that Cached Token Reuse (CTR), which converts spatial latent differences into token-level reuse decisions, combined with Softmax Thresholding and Sparsity Mask Reuse (ST), which reuses generated sparsity patterns, can be efficiently executed by a hash-based distribution over memory banks that reuses existing dense compute engines for the induced sparse operations, delivering 3.47-4.74x speedups and 46.4-68.1% energy savings over A100 and H100 GPUs on DiT and PixArt-Sigma.
What carries the argument
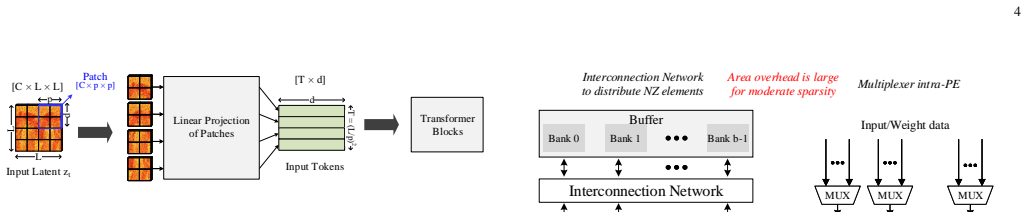
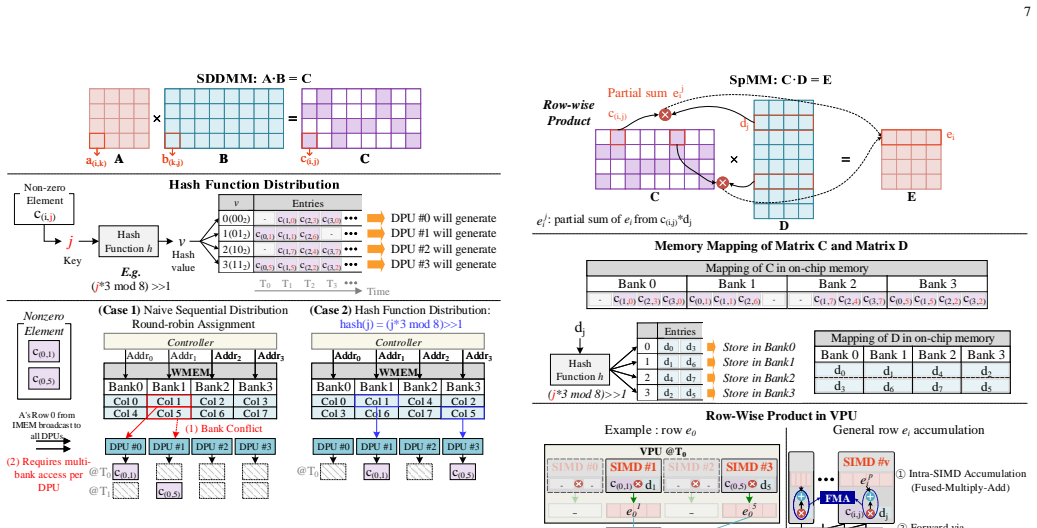
Hash-based distribution over on-chip memory banks that reuses dense compute engines for the sparse attention workload created by CTR and ST.
If this is right
- Eliminates redundant token computations in iterative denoising without per-step overhead.
- Reuses a single sparsity pattern across steps to bypass prediction costs in attention.
- Achieves resolution-scalable speedups and energy savings on transformer-based diffusion models.
- Avoids extra hardware area by mapping sparse operations onto existing dense engines via hashing.
- Yields moderate sparsity levels that fit a hybrid workload on unified dataflow.
Where Pith is reading between the lines
- The reuse decisions based on latent differences might apply to other iterative generative processes such as autoregressive image synthesis.
- Hash distribution could lower silicon area in future specialized chips for attention-heavy workloads.
- Temporal similarity exploited by ST might extend to video diffusion models where frame-to-frame coherence is high.
- Combining CTR with existing model compression methods could compound the efficiency gains beyond what the paper measures.
Load-bearing premise
Spatial variations in latent differences across denoising steps stay stable enough to support reliable token reuse decisions without visible artifacts or needing per-step mask recomputation.
What would settle it
Running the DiSC hardware on a new high-resolution diffusion model and measuring either no speedup relative to a dense baseline or visible image quality degradation from incorrect reuse decisions.
Figures





read the original abstract
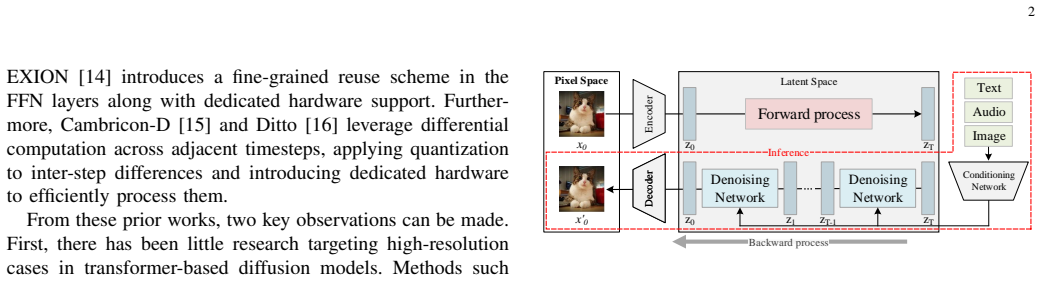
Transformer-based diffusion models offer superior scalability and performance but suffer from high computational overhead due to the iterative nature and quadratic complexity of self-attention at high resolutions. In this paper, we propose DiSC, a resolution-scalable, sparsity-aware hardware accelerator. At the software level, DiSC introduces two algorithms: Cached Token Reuse (CTR), and Softmax Thresholding with Sparsity Mask Reuse (ST). CTR introduces a mechanism that translates spatial variations in the input latent difference across steps into a token-level reuse decision, effectively eliminating redundant token computation. ST induces sparsity in attention operations by reusing a generated sparsity pattern, leveraging temporal similarity to bypass costly prediction overhead. Together, these algorithms provide resolution-scalable computational benefits and yield a moderate sparsity and hybrid dense-sparse workload. To exploit this efficiently, we design a specialized hardware architecture and unified dataflow. This architecture avoids dedicated sparsity-handling components; instead, a hash-based distribution over on-chip memory banks allows DiSC to reuse its existing compute engines for sparse operations, efficiently exploiting the induced sparsity with minimal hardware overhead. Evaluated on DiT and PixArt-Sigma, DiSC achieves 3.47-4.74x and 2.48-3.50x speedups over NVIDIA A100 and H100 GPUs, respectively, with energy savings ranging from 46.4% to 68.1%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiSC, a hardware accelerator for transformer-based diffusion models (DiT, PixArt-Sigma) that combines two software techniques—Cached Token Reuse (CTR), which maps spatial variations in latent differences across denoising steps to per-token reuse decisions, and Softmax Thresholding with Sparsity Mask Reuse (ST), which reuses attention sparsity patterns via temporal similarity—with a hash-based on-chip memory distribution that allows reuse of existing dense compute engines for the resulting hybrid dense-sparse workload. The central claim is that this co-design yields resolution-scalable speedups of 3.47-4.74× (A100) and 2.48-3.50× (H100) together with 46.4–68.1 % energy reduction.
Significance. If the empirical claims hold after the stability assumption is validated, the result would be significant for computer-architecture research on generative-model acceleration: it demonstrates that temporal reuse and moderate sparsity can be exploited without custom sparse hardware, using only a lightweight hash distribution. This is a concrete, falsifiable hardware–software co-design point that could influence both accelerator design and diffusion-model scheduling.
major comments (2)
- [CTR description (abstract and §3)] CTR description (abstract and §3): the headline speedups rest on the assumption that spatial patterns of latent differences remain sufficiently stable across steps to permit reliable token-level reuse decisions without visible artifacts or per-step mask recomputation. No reuse-frequency statistics, quality metrics (e.g., FID or perceptual scores with/without reuse), or ablation of the reuse threshold are supplied; if the pattern changes rapidly, either artifacts appear or the mask must be recomputed each step, eliminating the claimed savings. This is load-bearing for the 3.47–4.74× claim.
- [Evaluation section (§5)] Evaluation section (§5): the reported speedups and energy numbers are presented as direct measurements, yet no breakdown is given separating the contribution of CTR versus ST, nor any sensitivity analysis to the sparsity threshold or hash-distribution parameters. Without these data it is impossible to determine whether the gains are robust or specific to the two evaluated models.
minor comments (2)
- [Hardware architecture (§4)] Notation for the hash function and bank mapping is introduced without a compact equation or pseudocode; a small diagram or equation would clarify how collisions are handled.
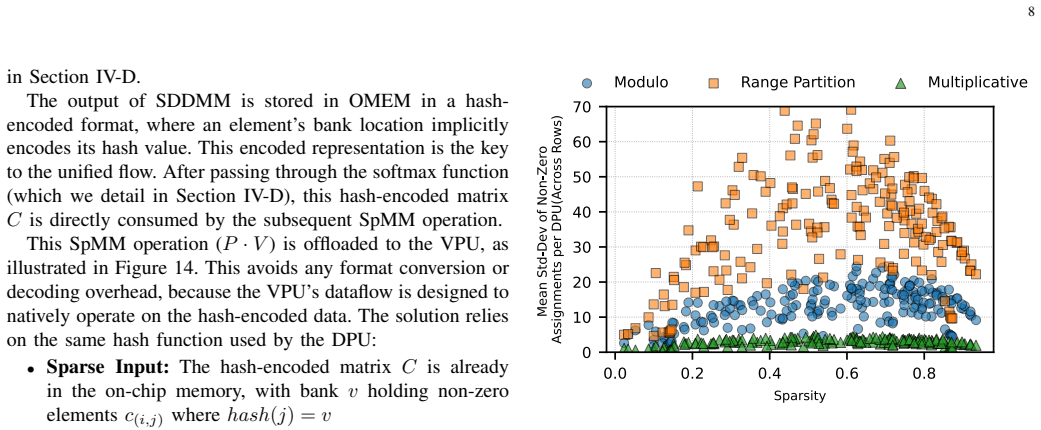
- [Abstract and §3] The abstract states “moderate sparsity” but never quantifies the achieved sparsity ratio or its variation across layers and steps; adding a table or plot would strengthen the sparsity claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional analyses where the original submission was incomplete.
read point-by-point responses
-
Referee: [CTR description (abstract and §3)] CTR description (abstract and §3): the headline speedups rest on the assumption that spatial patterns of latent differences remain sufficiently stable across steps to permit reliable token-level reuse decisions without visible artifacts or per-step mask recomputation. No reuse-frequency statistics, quality metrics (e.g., FID or perceptual scores with/without reuse), or ablation of the reuse threshold are supplied; if the pattern changes rapidly, either artifacts appear or the mask must be recomputed each step, eliminating the claimed savings. This is load-bearing for the 3.47–4.74× claim.
Authors: We agree that the stability assumption underlying CTR is central to the reported speedups and that the original manuscript lacks the requested supporting data. Although the evaluated models showed no visible artifacts, we did not report reuse-frequency statistics, FID or perceptual quality metrics comparing runs with and without CTR, or an ablation on the reuse threshold. We will add these elements—including per-step reuse rates, quality metrics, and threshold sensitivity—in the revised version to validate the assumption. revision: yes
-
Referee: [Evaluation section (§5)] Evaluation section (§5): the reported speedups and energy numbers are presented as direct measurements, yet no breakdown is given separating the contribution of CTR versus ST, nor any sensitivity analysis to the sparsity threshold or hash-distribution parameters. Without these data it is impossible to determine whether the gains are robust or specific to the two evaluated models.
Authors: We concur that the evaluation section would be strengthened by an explicit breakdown of CTR versus ST contributions and by sensitivity analysis on the sparsity threshold and hash-distribution parameters. The current results reflect the combined system on DiT and PixArt-Sigma; we will include ablations isolating each technique and parameter sweeps in the revision to demonstrate robustness beyond the two models. revision: yes
Circularity Check
No circularity; performance claims are direct measurements
full rationale
The provided abstract and description contain no equations, fitted parameters, or first-principles derivations. Speedup and energy figures are stated as empirical evaluation results on DiT and PixArt-Sigma. CTR and ST are introduced as new algorithmic mechanisms whose benefits are measured rather than predicted from prior quantities within the paper. No self-citation chains, self-definitional loops, or renamed known results appear in the load-bearing claims. The work is self-contained as an engineering design paper whose central results do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[2]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
2021
-
[3]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4195–4205
2023
-
[4]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, K. Lacey, A. Goodwin, Y . Marek, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” 2024. [Online]. Available: https://arxiv.org/abs/2403.03206
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
J. Chen, J. Yu, C. Ge, L. Yao, E. Xie, Y . Wu, Z. Wang, J. Kwok, P. Luo, H. Luet al., “Pixart-αFast training of diffusion transformer for photore- alistic text-to-image synthesis,”arXiv preprint arXiv:2310.00426, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Pixart-σWeak-to-strong training of diffusion transformer for 4k text-to-image generation,
J. Chen, C. Ge, E. Xie, Y . Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, and Z. Li, “Pixart-σWeak-to-strong training of diffusion transformer for 4k text-to-image generation,”arXiv preprint arXiv:2403.04692, 2024
-
[7]
FORA: Fast-forward caching in diffusion transformer acceleration.arXiv preprint arXiv:2407.01425,
P. Selvaraju, T. Ding, T. Chen, I. Zharkov, and L. Liang, “Fora: Fast- forward caching in diffusion transformer acceleration,”arXiv preprint arXiv:2407.01425, 2024
-
[8]
Learning-to-cache: Accel- erating diffusion transformer via layer caching,
X. Ma, G. Fang, M. Bi Mi, and X. Wang, “Learning-to-cache: Accel- erating diffusion transformer via layer caching,”Advances in Neural Information Processing Systems, vol. 37, pp. 133 282–133 304, 2024
2024
-
[9]
Deepcache: Accelerating diffusion models for free,
X. Ma, G. Fang, and X. Wang, “Deepcache: Accelerating diffusion models for free,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 15 762–15 772
2024
-
[10]
arXiv preprint arXiv:2410.05317 (2024)
C. Zou, X. Liu, T. Liu, S. Huang, and L. Zhang, “Accelerating dif- fusion transformers with token-wise feature caching,”arXiv preprint arXiv:2410.05317, 2024
-
[11]
Accelerating diffusion transformers with dual feature caching,
C. Zou, E. Zhang, R. Guo, H. Xu, C. He, X. Hu, and L. Zhang, “Accelerating diffusion transformers with dual feature caching,”arXiv preprint arXiv:2412.18911, 2024
-
[12]
Huanpeng Chu, Wei Wu, Guanyu Fen, and Yutao Zhang
Z. Chen, K. Li, Y . Jia, L. Ye, and Y . Ma, “Accelerating diffusion transformer via increment-calibrated caching with channel- aware singular value decomposition,” 2025. [Online]. Available: https://arxiv.org/abs/2505.05829
-
[13]
DiTFastattn: Attention compression for diffusion transformer models,
Z. Yuan, H. Zhang, L. Pu, X. Ning, L. Zhang, T. Zhao, S. Yan, G. Dai, and Y . Wang, “DiTFastattn: Attention compression for diffusion transformer models,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=51HQpkQy3t
2024
-
[14]
Exion: Exploiting inter-and intra-iteration output sparsity for diffusion models,
J. Heo, A. Putra, J. Yoon, S. Yune, H. Lee, J.-H. Kim, and J.-Y . Kim, “Exion: Exploiting inter-and intra-iteration output sparsity for diffusion models,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 324–337
2025
-
[15]
Cambricon-d: Full-network differential acceleration for diffusion models,
W. Kong, Y . Hao, Q. Guo, Y . Zhao, X. Song, X. Li, M. Zou, Z. Du, R. Zhang, C. Liuet al., “Cambricon-d: Full-network differential acceleration for diffusion models,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 903–914
2024
-
[16]
Ditto: Accel- erating diffusion model via temporal value similarity,
S. Kim, H. Lee, W. Cho, M. Park, and W. W. Ro, “Ditto: Accel- erating diffusion model via temporal value similarity,”arXiv preprint arXiv:2501.11211, 2025
-
[17]
Aˆ 3: Accelerating attention mechanisms in neural networks with approximation,
T. J. Ham, S. J. Jung, S. Kim, Y . H. Oh, Y . Park, Y . Song, J.-H. Park, S. Lee, K. Park, J. W. Leeet al., “Aˆ 3: Accelerating attention mechanisms in neural networks with approximation,” in2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020, pp. 328–341
2020
-
[18]
Spatten: Efficient sparse attention architecture with cascade token and head pruning,
H. Wang, Z. Zhang, and S. Han, “Spatten: Efficient sparse attention architecture with cascade token and head pruning,” in2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2021, pp. 97–110
2021
-
[19]
Elsa: Hardware-software co-design for efficient, lightweight self- attention mechanism in neural networks,
T. J. Ham, Y . Lee, S. H. Seo, S. Kim, H. Choi, S. J. Jung, and J. W. Lee, “Elsa: Hardware-software co-design for efficient, lightweight self- attention mechanism in neural networks,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 692–705
2021
-
[20]
Fact: Ffn-attention co-optimized transformer architecture with eager correlation prediction,
Y . Qin, Y . Wang, D. Deng, Z. Zhao, X. Yang, L. Liu, S. Wei, Y . Hu, and S. Yin, “Fact: Ffn-attention co-optimized transformer architecture with eager correlation prediction,” inProceedings of the 50th Annual International Symposium on Computer Architecture, 2023, pp. 1–14
2023
-
[21]
Cache me if you can: Accelerating diffusion models through block caching,
F. Wimbauer, B. Wu, E. Schoenfeld, X. Dai, J. Hou, Z. He, A. Sanakoyeu, P. Zhang, S. Tsai, J. Kohleret al., “Cache me if you can: Accelerating diffusion models through block caching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 6211–6220
2024
-
[22]
Vitcod: Vision transformer acceleration via dedicated algorithm and accelerator co-design,
H. You, Z. Sun, H. Shi, Z. Yu, Y . Zhao, Y . Zhang, C. Li, B. Li, and Y . Lin, “Vitcod: Vision transformer acceleration via dedicated algorithm and accelerator co-design,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2023, pp. 273–286
2023
-
[23]
Sanger: A co-design framework for enabling sparse attention using reconfigurable architecture,
L. Lu, Y . Jin, H. Bi, Z. Luo, P. Li, T. Wang, and Y . Liang, “Sanger: A co-design framework for enabling sparse attention using reconfigurable architecture,” inMICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, 2021, pp. 977–991
2021
-
[24]
Hammer: Hardware-friendly approximate computing for self-attention with mean-redistribution and linearization,
S. Lee, R. Hwang, J. Park, and M. Rhu, “Hammer: Hardware-friendly approximate computing for self-attention with mean-redistribution and linearization,”IEEE Computer Architecture Letters, vol. 22, no. 1, pp. 13–16, 2023
2023
-
[25]
Matraptor: A sparse-sparse matrix multiplication accelerator based on row-wise product,
N. Srivastava, H. Jin, J. Liu, D. Albonesi, and Z. Zhang, “Matraptor: A sparse-sparse matrix multiplication accelerator based on row-wise product,” in2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020, pp. 766–780
2020
-
[26]
Gamma: Leveraging gustavson’s algorithm to accelerate sparse matrix multiplication,
G. Zhang, N. Attaluri, J. S. Emer, and D. Sanchez, “Gamma: Leveraging gustavson’s algorithm to accelerate sparse matrix multiplication,” in Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2021, pp. 687–701
2021
-
[27]
Outerspace: An outer product based sparse matrix multiplication accelerator,
S. Pal, J. Beaumont, D.-H. Park, A. Amarnath, S. Feng, C. Chakrabarti, H.-S. Kim, D. Blaauw, T. Mudge, and R. Dreslinski, “Outerspace: An outer product based sparse matrix multiplication accelerator,” in 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2018, pp. 724–736
2018
-
[28]
Sigma: A sparse and irregular gemm ac- celerator with flexible interconnects for dnn training,
E. Qin, A. Samajdar, H. Kwon, V . Nadella, S. Srinivasan, D. Das, B. Kaul, and T. Krishna, “Sigma: A sparse and irregular gemm ac- celerator with flexible interconnects for dnn training,” in2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020, pp. 58–70
2020
-
[29]
Scnn: An accelerator for compressed-sparse convolutional neural networks,
A. Parashar, M. Rhu, A. Mukkara, A. Puglielli, R. Venkatesan, B. Khailany, J. Emer, S. W. Keckler, and W. J. Dally, “Scnn: An accelerator for compressed-sparse convolutional neural networks,”ACM SIGARCH computer architecture news, vol. 45, no. 2, pp. 27–40, 2017
2017
-
[30]
Trapezoid: A versatile accelerator for dense and sparse matrix multiplications,
Y . Yang, J. S. Emer, and D. Sanchez, “Trapezoid: A versatile accelerator for dense and sparse matrix multiplications,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 931–945
2024
-
[31]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” inIn NeurIPS, 2012, 5
2012
-
[32]
Pixart-eval-30k dataset,
PixArt, “Pixart-eval-30k dataset,” https://huggingface.co/datasets/ PixArt-alpha/PixArt-Eval-30K, 2024
2024
-
[33]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[34]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
J. Hessel, A. Holtzman, M. Forbes, R. L. Bras, and Y . Choi, “Clipscore: A reference-free evaluation metric for image captioning,”arXiv preprint arXiv:2104.08718, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
The gem5 simulator,
N. Binkert, B. Beckmann, G. Black, S. K. Reinhardt, A. Saidi, A. Basu, J. Hestness, D. R. Hower, T. Krishna, S. Sardashtiet al., “The gem5 simulator,”ACM SIGARCH computer architecture news, vol. 39, no. 2, pp. 1–7, 2011
2011
-
[36]
Ramulator 2.0: A modern, modular, and extensible dram simulator,
H. Luo, Y . C. Tu ˘grul, F. N. Bostancı, A. Olgun, A. G. Ya ˘glıkc ¸ı, and O. Mutlu, “Ramulator 2.0: A modern, modular, and extensible dram simulator,”IEEE Computer Architecture Letters, vol. 23, no. 1, pp. 112– 116, 2024
2024
-
[37]
Nvidia a100 tensor core gpu datasheet,
NVIDIA Corporation, “Nvidia a100 tensor core gpu datasheet,” https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/ pdf/nvidia-a100-datasheet-nvidia-us-2188504-web.pdf, May 2022
2022
-
[38]
Design compiler,
Synopsys, “Design compiler,” https://www.synopsys.com/ implementation-and-signoff/rtl-synthesis-test/dc-ultra.html, n.d
-
[39]
Fine-grained dram: Energy-efficient dram for extreme bandwidth systems,
M. O’Connor, N. Chatterjee, A. Agrawal, D. Lee, S. W. Keckler, J. Wilson, and W. J. Dally, “Fine-grained dram: Energy-efficient dram for extreme bandwidth systems,” inMICRO-50: 50th Annual IEEE/ACM International Symposium on Microarchitecture, 2017, pp. 41–54
2017
-
[40]
Cacti 7: New tools for interconnect exploration in innovative off-chip memories,
R. Balasubramonian, A. B. Kahng, N. Muralimanohar, A. Shafiee, and V . Srinivas, “Cacti 7: New tools for interconnect exploration in innovative off-chip memories,”ACM Transactions on Architecture and Code Optimization (TACO), vol. 14, no. 2, pp. 1–25, 2017
2017
-
[41]
Deepscaletool: A tool for the accurate estima- tion of technology scaling in the deep-submicron era,
S. Sarangi and B. Baas, “Deepscaletool: A tool for the accurate estima- tion of technology scaling in the deep-submicron era,” inProceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), 2021, pp. 1–5
2021
-
[42]
Token merging for fast stable diffusion,
D. Bolya and J. Hoffman, “Token merging for fast stable diffusion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 4599–4603
2023
-
[43]
arXiv preprint arXiv:2502.01776 (2025)
H. Xi, S. Yang, Y . Zhao, C. Xu, M. Li, X. Li, Y . Lin, H. Cai, J. Zhang, D. Li, J. Chen, I. Stoica, K. Keutzer, and S. Han, “Sparse videogen: Accelerating video diffusion transformers with spatial-temporal sparsity,” 2025. [Online]. Available: https: //arxiv.org/abs/2502.01776
-
[44]
Block Sparse Attention,
J. Guo, H. Tang, S. Yang, Z. Zhang, Z. Liu, and S. Han, “Block Sparse Attention,” https://github.com/mit-han-lab/Block-Sparse-Attention, 2024
2024
-
[45]
Sparch: Efficient architecture for sparse matrix multiplication,
Z. Zhang, H. Wang, S. Han, and W. J. Dally, “Sparch: Efficient architecture for sparse matrix multiplication,” in2020 IEEE Interna- tional Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020, pp. 261–274. 13 Jieon Yoon(Graduate Student Member, IEEE) re- ceived the B.S. degree in Electrical Engineering with a double major in Computer Sci...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.